一种涉诈短文本识别方法
文献发布时间:2023-06-19 11:45:49
技术领域
本发明涉及机器学习技术领域,更具体地,涉及一种涉诈短文本识别方法。
背景技术
随着电信网络诈骗案件的持续高发,作为犯罪分子传播诈骗信息重要形式之一的短文本(如短信、微博、网页评论等),引起了监管部门、运营商、研究人员越来越多的关注。目前较多的研究工作主要针对如何识别诈骗短信,主要采用神经网络相关技术对涉诈短文本中的攻击手法进行识别,而针对短文本内容的具体涉诈类别关注较少。
如公开号为CN109982272A(公开日2019-07-05)提出的一种诈骗短信识别方法,提出利用短信识别神经网络的不同分支对短信中不同类型的特征字段进行处理,基于神经网络的正向传播,得到短信识别预测结果。该技术考虑了多种特征字段,针对文本信息的特征字段采用对其词向量进行LSTM编码后通过全连接层输出识别结果,没有考虑对文本信息的过滤及涉诈类别的分类,因此存在识别准确率低的缺陷。
发明内容
本发明为解决上述现有技术所述的没有考虑对文本信息的过滤及涉诈类别的分类导致存在识别准确率和效率低的问题,提供一种涉诈短文本识别方法。
为解决上述技术问题,本发明的技术方案如下:
一种涉诈短文本识别方法,包括以下步骤:
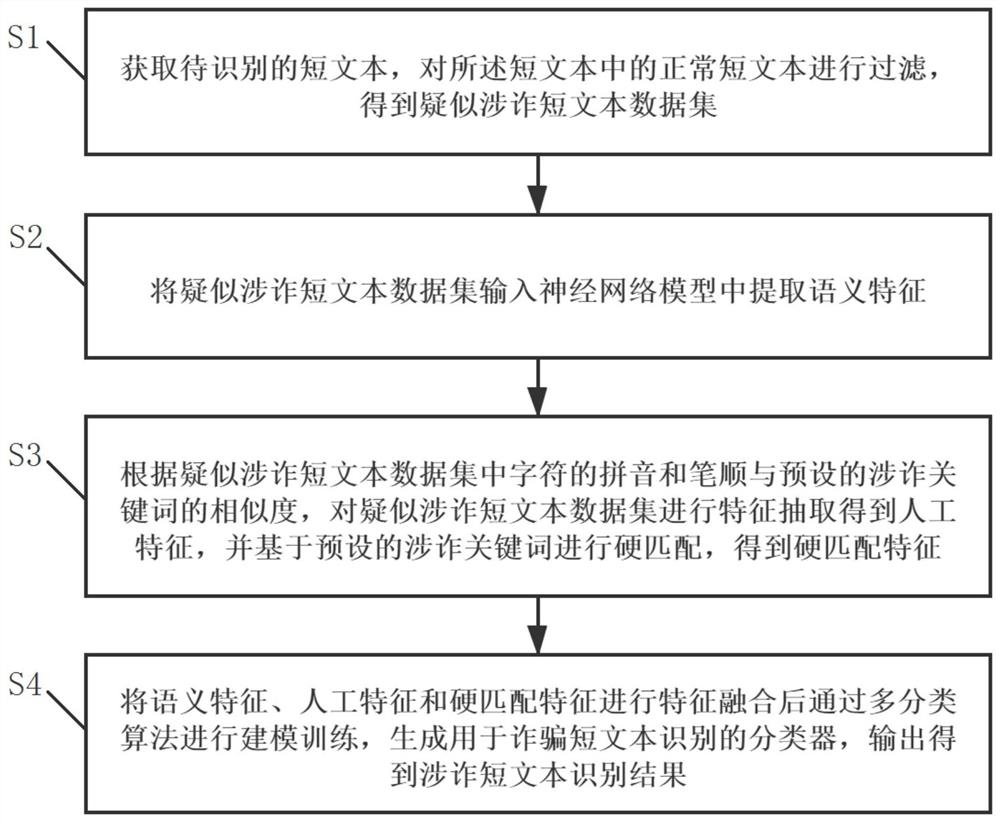
S1:获取待识别的短文本,对所述短文本中的正常短文本进行过滤,得到疑似涉诈短文本数据集;
S2:将所述疑似涉诈短文本数据集输入神经网络模型中提取语义特征;
S3:根据所述疑似涉诈短文本数据集中字符的拼音和笔顺与预设的涉诈关键词的相似度对所述疑似涉诈短文本数据集进行特征抽取得到人工特征,并基于预设的涉诈关键词进行硬匹配,得到硬匹配特征;
S4:将所述语义特征、人工特征和硬匹配特征进行特征融合后通过多分类算法进行建模训练,生成用于诈骗短文本识别的分类器,输出得到涉诈短文本识别结果。
作为优选方案,所述短文本包括常见中文字符、非常见中文字符、数字字符、英文字符、其他字符;其中,所述常见中文字符包括现代汉语言字典中最常用的3500个字符;所述非常见中文字符包括所述常见中文字符以外的中文字符;所述数字字符包括数字0~9;所述英文字符包括小写英文字母a~z和大写英文字母A~Z;所述其他字符包括不属于所述常见中文字符、非常见中文字符、数字字符、英文字符的字符。
作为优选方案,所述S1步骤中,对所述短文本中x的正常短文本进行过滤的步骤包括:对所述短文本x进行字符计数统计,根据短文本x中各类型字符的个数进行判断:当所述非常见中文字符个数C
作为优选方案,所述S1步骤中还包括以下步骤:
定义2个指示函数l
则得到疑似涉诈短文本数据集表示为:
cls
式中,cls
作为优选方案,所述S2步骤中,采用Bert-wmm模型提取语义特征,其中,将所述模型第一个字符的输出向量作为所述短文本的语义特征。
作为优选方案,根据所述疑似涉诈短文本数据集中字符的拼音和笔顺与预设的涉诈关键词的相似度对所述疑似涉诈短文本数据集进行特征抽取的步骤包括:
S31:预设涉诈关键词集合keywordsA={ka
S32:对所述疑似涉诈短文本数据集进行分析,判断所述短文本中是否存在分割攻击手法,若是,则对分割词进行组合得到纠正后的短文本;若否,则直接进行S33步骤;
S33:从所述涉诈关键词集合中选取第一个关键词中的第一个字符作为当前判定的关键词字符,以及从所述短文本中选取第一个短文本字符作为当前判定的短文本字符进行比较:
1)判断当前短文本字符与关键词字符的拼音是否相同,若是,则执行步骤3);若否,则执行步骤2);
2)判断当前短文本字符与关键词字符的笔顺相似度是否大于预设的相似度阈值,若是,则执行步骤3);若否,则执行步骤4);
3)判断当前关键词字符是否为当前关键词中的最后一个关键词字符,若是,则输出表示该关键词存在短文本中的特征向量,并执行步骤4);若否,则将当前关键词中下一关键词字符作为当前判定的关键词字符,将所述短文本中下一短文本字符作为当前判定的短文本字符,并跳转执行步骤1);
4)判断当前短文本字符是否为所述短文本中的最后一个短文本字符,若是,则输出表示该关键词不存在短文本中的特征向量,并执行步骤5);若否,则将所述短文本中下一短文本字符作为当前判定的短文本字符,将当前关键词中第一个关键词字符作为当前判定的关键词字符,并跳转执行步骤1);
5)判断当前关键词是否为所述涉诈关键词集合中的最后一个关键词,若是,则执行S34步骤;若否,则从所述涉诈关键词集合中选取下一个关键词中的第一个字符作为当前判定的关键词字符,从所述短文本中选取第一个短文本字符作为当前判定的短文本字符,并跳转执行步骤1);
S34:将输出的特征向量整合为抽取得到的人工特征f
作为优选方案,所述步骤S33中,判断当前短文本字符与关键词字符的笔顺相似度的步骤包括:对字符的笔画进行编码得到笔顺编码串,其中,横笔画编码为1,竖笔画编码为2,撇笔画编码为3,捺笔画编码为4,折笔画编码为5;将当前短文本字符与关键词字符对比,对连续相同的笔顺编码串中的编码数进行统计,并计算其与关键词字符的笔顺编码总数相同的比例,得到当前短文本字符的笔顺相似度。
作为优选方案,基于预设的涉诈关键词进行硬匹配的步骤包括:预设硬匹配关键词集合keywordsB={kb
作为优选方案,所述S4步骤中,将所述语义特征f
V(x)=f
则通过多分类算法进行建模训练,其表达公式如下:
cls
式中,cls
作为优选方案,所述S4步骤中采用支持向量机作为多分类算法、决策树分类算法或K最近邻分类算法进行建模。
与现有技术相比,本发明技术方案的有益效果是:本发明针对不同涉诈类别采用不同的识别手段,包括对正常短文本的快速过滤,以及对涉诈短文本的细粒度区分,基于深度模型的语义特征、关键词的拼音和笔顺的人工特征,以及关键词的硬匹配人工特征,其组合得到的特征向量能够有效识别涉诈短文本的类别,提高识别准确率和识别效率,且可适用于大部分多分类算法,具有较强的鲁棒性。
附图说明
图1为本发明的涉诈短文本识别方法的流程图。
图2为实施例的对涉诈短文本数据集进行特征抽取的流程图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;
对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
下面结合附图和实施例对本发明的技术方案做进一步的说明。
实施例
本实施例提出一种涉诈短文本识别方法,如图1所示,为本实施例的涉诈短文本识别方法的流程图。
本实施例提出的涉诈短文本识别方法中,包括以下步骤:
步骤1:获取待识别的短文本,对所述短文本中的正常短文本进行过滤,得到疑似涉诈短文本数据集。
本实施例中,将短文本中的字符进行分类,包括常见中文字符、非常见中文字符、数字字符、英文字符、其他字符。其中,所述常见中文字符包括现代汉语言字典中最常用的3500个字符;所述非常见中文字符包括所述常见中文字符以外的中文字符;所述数字字符包括数字0~9;所述英文字符包括小写英文字母a~z和大写英文字母A~Z;所述其他字符包括不属于上述四种类别的字符。
则本步骤中,对所述短文本中x的正常短文本进行过滤的步骤包括:
对所述短文本x进行字符计数统计,根据短文本x中各类型字符的个数进行判断:
当所述非常见中文字符个数C
否则,将所述短文本判别为正常短文本,并进行过滤。
上述步骤可以用以下表达公式表示:
定义2个指示函数l
则得到疑似涉诈短文本数据集表示为:
cls
式中,cls
步骤2:将所述疑似涉诈短文本数据集输入神经网络模型中提取语义特征。
本实施例中采用Bert-wmm模型提取语义特征,其中,将所述模型第一个字符的输出向量作为所述短文本的语义特征。本实施例中语义特征的维度数可通过修改Bert-wmm模型的参数实现自定义。
步骤3:根据所述疑似涉诈短文本数据集中字符的拼音和笔顺与预设的涉诈关键词的相似度对所述疑似涉诈短文本数据集进行特征抽取得到人工特征,并基于预设的涉诈关键词进行硬匹配,得到硬匹配特征。
本步骤中,如图2所示,根据所述疑似涉诈短文本数据集中字符的拼音和笔顺与预设的涉诈关键词的相似度对所述疑似涉诈短文本数据集进行特征抽取的步骤包括:
S31:预设涉诈关键词集合keywordsA={ka
S32:对所述疑似涉诈短文本数据集进行分析,判断所述短文本中是否存在分割攻击手法,若是,则对分割词进行组合得到纠正后的短文本;若否,则直接进行S33步骤;
S33:从所述涉诈关键词集合中选取第一个关键词中的第一个字符作为当前判定的关键词字符,以及从所述短文本中选取第一个短文本字符作为当前判定的短文本字符进行比较:
1)判断当前短文本字符与关键词字符的拼音是否相同,若是,则执行步骤3);若否,则执行步骤2);
2)判断当前短文本字符与关键词字符的笔顺相似度是否大于预设的相似度阈值,若是,则执行步骤3);若否,则执行步骤4);
3)判断当前关键词字符是否为当前关键词中的最后一个关键词字符,若是,则输出表示该关键词存在短文本中的特征向量“1”,并执行步骤4);若否,则将当前关键词中下一关键词字符作为当前判定的关键词字符,将所述短文本中下一短文本字符作为当前判定的短文本字符,并跳转执行步骤1);
4)判断当前短文本字符是否为所述短文本中的最后一个短文本字符,若是,则输出表示该关键词不存在短文本中的特征向量“0”,并执行步骤5);若否,则将所述短文本中下一短文本字符作为当前判定的短文本字符,将当前关键词中第一个关键词字符作为当前判定的关键词字符,并跳转执行步骤1);
5)判断当前关键词是否为所述涉诈关键词集合中的最后一个关键词,若是,则执行S34步骤;若否,则从所述涉诈关键词集合中选取下一个关键词中的第一个字符作为当前判定的关键词字符,从所述短文本中选取第一个短文本字符作为当前判定的短文本字符,并跳转执行步骤1);
S34:将输出的特征向量整合为抽取得到的人工特征f
其中,S33步骤中判断当前短文本字符与关键词字符的笔顺相似度的步骤包括:对字符的笔画进行编码得到笔顺编码串,其中,横笔画编码为1,竖笔画编码为2,撇笔画编码为3,捺笔画编码为4,折笔画编码为5;将当前短文本字符与关键词字符对比,对连续相同的笔顺编码串中的编码数进行统计,并计算其与关键词字符的笔顺编码总数相同的比例,得到当前短文本字符的笔顺相似度。
在一具体实施过程中,当前短文本字符“徽”经过编码得到笔顺编码串为“33225215542343134”,而关键词字符“微”经过编码得到笔顺编码串为“3322521353134”,其中相同笔顺字符串为“3322521”以及“3134”,因此当前短文本字符与关键词字符的笔顺相似度为(7+4)/13≈0.846。
本步骤主要针对涉诈手段类型进行判断,包括分割攻击手法(如:将赌博分割为贝者博)、同音攻击手法(如:将微信转换为威信)、相近字攻击手法(如:将出力转换为出
进一步的,基于预设的涉诈关键词进行硬匹配,得到硬匹配特征的步骤包括:
预设硬匹配关键词集合keywordsB={kb
本步骤旨在针对无法用拼音、笔顺相似度判断识别的字符特征进行识别,如将数字“0”替换为“o”、“。”等非中文字符或其他字符。本实施例中的硬匹配关键词集合keywordsB={kb
步骤4:将所述语义特征、人工特征和硬匹配特征进行特征融合后通过多分类算法进行建模训练,生成用于诈骗短文本识别的分类器,输出得到涉诈短文本识别结果。
本步骤将所述语义特征f
V(x)=f
则通过多分类算法进行建模训练,其表达公式如下:
cls
式中,cls
本实施例中采用支持向量机作为多分类算法进行建模。在另一实施例中,多分类算法可采用决策树分类算法、K最近邻分类算法。
本实施例中,通过对神经网络模型的参数进行调整,以及对关键词集合keywordsA、keywordsB中的关键词进行调整,能够输出具体的诈骗短文本类别,如刷单诈骗、兼职诈骗等。
在一具体实施过程中,如下表1所示,为诈骗短文本及各算法识别结果。
表1诈骗短文本及各算法识别结果
其中,GROUND TRUTH为样本的真实标签,TFC为本实施例提出的涉诈短文本识别方法,JWE为Yu J等提出的一种文本识别方法(Yu J,Xun J,Hao X,et al.Joint Embeddingsof Chinese Words,Characters,and Fine-grained Subcharacter Components[C]//Conference on Empirical Methods in Natural Language Processing.2017.),cw2vec为一种新的汉字嵌入学习方法(cw2vec:Learning Chinese Word Embeddings withStroke n-gram Information),PyCor+Bert为一个中文错误字符纠错软件配合bert神经网络。由上表可知,本实施例提出的涉诈短文本识别方法与其他现有算法相比的准确率更高。
进一步的,将本实施例提出的涉诈短文本识别方法与现有的识别算法进行对比实验,如下表2所示。
表2不同算法的识别结果
本实施例采用JWE、cw2vec等算法,以及采用BERT-wwm神经网络模型、结合STAGE1指示函数过滤的BERT-wwm神经网络模型、结合PyCor软件和BERT-wwm神经网络模型等,另外TFC without Stage1为采用本实施例提出的涉诈短文本识别方法TFC且没有经指示函数过滤的算法,采用上述算法分别对两个不同的数据集DATASET1和DATASET2进行文本识别,并计算F1-score和识别准确率Accuracy。根据上表可知,本实施例提出的涉诈短文本识别方法与其他算法相比,其在不同的数据集下的准确率及F1-score更高。
本实施例提出的涉诈短文本识别方法考虑了涉诈短文本中的攻击手法以及短文本具体涉诈类别,针对不同涉诈类别采用不同的识别手段,包括对正常短文本的快速过滤,以及对涉诈短文本的细粒度区分,基于深度模型的语义特征、关键词的拼音和笔顺的人工特征,以及关键词的硬匹配特征,其组合得到的特征向量能够有效识别涉诈短文本的类别,提高识别准确率,且可适用于大部分多分类算法,具有较强的鲁棒性。对运营商等拥有海量短文本数据处理需求的机构而言,本实施例能大幅减少计算资源开销,有效降低计算成本,提高识别效率。
附图中描述位置关系的用语仅用于示例性说明,不能理解为对本专利的限制;
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 一种涉诈短文本识别方法
- 一种涉诈识别方法和装置