模型构建方法及装置和混凝土抗压强度预测方法及装置
文献发布时间:2023-06-19 11:49:09
技术领域
本申请涉及混凝土强度测定技术,尤其与一种模型构建方法及装置和混凝土抗压强度预测方法及装置有关。
背景技术
混凝土的质量控制与评价是水利、土木工程中的重要技术问题,而其中混凝土的抗压强度是衡量混凝土特点及性能的重要指标。
目前,混凝土抗压强度常用的检测方法包括1h促凝压蒸法、神经网络预测法、灰色理论预测法、新拌混凝土现场检测法和超声回弹综合法等。
其中,灰色理论与目前的神经网络方法虽然都可以根据特征参数实现及时评估,但是其精度与原始数据库及算法合理性有关,波动可能较大;1h促凝压蒸法与新拌混凝土现场检测法由于需要预先制备试样,需要一定的时间,并且1h促凝压蒸法采用砂浆快硬强度推测混凝土强度,没有考虑级配中石子的作用、石子与水泥砂浆的界面结构与尺寸效应,其精度不足,新拌混凝土现场检测法,受测仪器局限性和检测环境的影响,存在精度问题;超声回弹综合法中制备的试件结构完成成形并具有一定的强度,才能进行检测,所需时间最长,且该方法也同样受检测仪器局限性和检测环境的影响,存在精度问题。
以上方法均难以在短时间内获得高精度的强度预测效果。
发明内容
为解决现有技术不足,本申请提供一种模型构建方法及装置和混凝土抗压强度预测方法及装置,可以在短时间内高效准确对混凝土抗压强度进行预测,既可以应用于人工砂混凝土,也可以应用于普通混凝土。
根据本申请实施例的一个方面,提供了一种模型构建方法,包括:建立关于立方体混凝土抗压强度影响因素的数据库;对数据库内的数据进行预处理;通过自适应神经模糊推理系统构建预测模型;利用预处理的数据对预测模型进行训练,得到预测训练模型;所述预测训练模型,用于混凝土抗压强度预测。
进一步地,所述影响因素包括:水泥抗压强度、水泥抗拉强度、混凝土养护龄期、粗骨料最大粒径、石粉掺量、沙子的细度模数、水粘合剂比、水灰比、水的质量、含砂率、坍落度中一种或多种。
进一步地,对数据库内的数据进行预处理,包括:将数据库中的n个样本的原始数据按行排列组成样本矩阵;获取样本矩阵的标准化矩阵;获取标准化矩阵的相关系数矩阵;获取相关系数矩阵的单位特征向量;通过单位特征向量将标准化矩阵中标准化分量转换为主成分;对各个主成分进行加权求和,权数为每个主成分的方差贡献率。
进一步地,对数据库内的数据进行预处理,包括:
将数据库中的n个样本的原始数据x
对样本矩阵X通过如下的标准变换,获得标准化矩阵Z:
其中,
获取标准化矩阵Z的相关系数矩阵R,通过以下公式:
其中,
获取相关系数矩阵R的单位特征向量,通过以下方式:
解相关系数矩阵R的特征方程|R-λI
通过
对每个λ
通过单位特征向量将标准化矩阵中标准化分量转换为主成分,采用如下方式:
通过
对m个主成分进行加权求和,即得最终评价值,权数为每个主成分的方差贡献率。
进一步地,所述自适应神经模糊推理系统的推理规则为:
如果u
如果u
如果u
如果u
其中,u
进一步地,所述自适应神经模糊推理系统的结构包括五层,O
第一层,用于将输入的预处理的数据模糊化,本层的每个结点i是一个有结点函数的自适应结点,其输出为:
式中,
第二层,用于实现前提部分的模糊集的运算,本层的每个结点i均为固定结点,输出是为所有输入数据的代数积,如下:
式中,w
第三层,用于将各条规则的激励强度归一化,本层的每个结点i均为固定结点,输出为:
式中,
第四层,用于计算出每条规则的输出,本层的每个结点i是一个有结点函数的自适应结点,如下:
第五层,用于以所有传来数据之和作为总输出,本层的的每个结点i为一个固定结点,如下:
进一步,对预测模型进行训练采用教与学优化算法进行,教学阶段使用如下的教学函数:
Diff=r
X′
其中,r
学习阶段使用如下的学习函数:
X″
X″
根据本申请实施例的另一个方面,还提供了一种模型构建装置,包括:数据库单元,用于建立关于立方体混凝土抗压强度影响因素的数据库;预处理单元,用于对数据库内的数据进行预处理;构建单元,用于通过自适应神经模糊推理系统构建预测模型;训练单元,用于利用预处理的数据对预测模型进行训练,得到预测训练模型;所述预测训练模型,用于混凝土抗压强度预测。
根据本申请实施例的另一个方面,还提供了一种混凝土抗压强度预测方法,包括:获取待测混凝土的抗压强度主要影响因素;将所述抗压强度主要影响因素输入所述模型构建方法获得的预测训练模型中,利用所述预测训练模型对待测混泥土抗压强度进行预测。
进一步,所述待测混凝土的抗压强度主要影响因素,是通过对待测混凝土的水泥抗压强度、水泥抗拉强度、混凝土养护龄期、粗骨料最大粒径、石粉掺量、沙子的细度模数、水粘合剂比、水灰比、水的质量、含砂率、坍落度中一种或多种进行主成分分析获得。
进一步,所述主成分分析,包括:对待测混凝土的水泥抗压强度、水泥抗拉强度、混凝土养护龄期、粗骨料最大粒径、石粉掺量、沙子的细度模数、水粘合剂比、水灰比、水的质量、含砂率、坍落度中一种或多种的数据集合进行排列以获取样本矩阵;获取样本矩阵的标准化矩阵;获取标准化矩阵的相关系数矩阵;获得相关系数矩阵的单位特征向量;通过单位特征向量将标准化矩阵中标准化分量转换为主成分;对各个主成分进行加权求和,权数为每个主成分的方差贡献率。
进一步,单位特征向量为以下方程组的解:Rb=λ
根据本申请实施例的另一个方面,还提供了一种混凝土抗压强度预测装置,包括:输入单元,用于获取待测混凝土的抗压强度主要影响因素;预测单元,用于将所述抗压强度主要影响因素输入到所述模型构建方法获得的预测训练模型中,利用所述预测训练模型对待测混泥土抗压强度进行预测。
本申请的有益效果在于:
1、本申请的一般影响因素综合考虑了影响混凝土强度的多种因素,包括针对人工砂混凝土的石粉掺量;既可以应用于人工砂混凝土,也可以应用于普通混凝土。
2、本申请先基于原始数据库分析影响混凝土强度的主要因素,再在主要因素与混凝土抗压强度之间建立评估系统模型;提供了评估结果的合理性与准确性。
3、本申请通过运用主成分分析法、人工神经网络、模糊推理系统和教与学优化算法等数学理论,综合了神经网络和教与学优化算法的学习机制和模糊系统的推理能力,同时也避免了输入变量过多导致的计算困难。
4、本申请是基于数据库和数学统计的混凝土强度预测方法,是一种具有及时性的方法;其次,在相关数学统计方法的合理选择与发展上保证了预测结果的准确性。
附图说明
本文描述的附图只是为了说明所选实施例,而不是所有可能的实施方案,更不是意图限制本申请的范围。
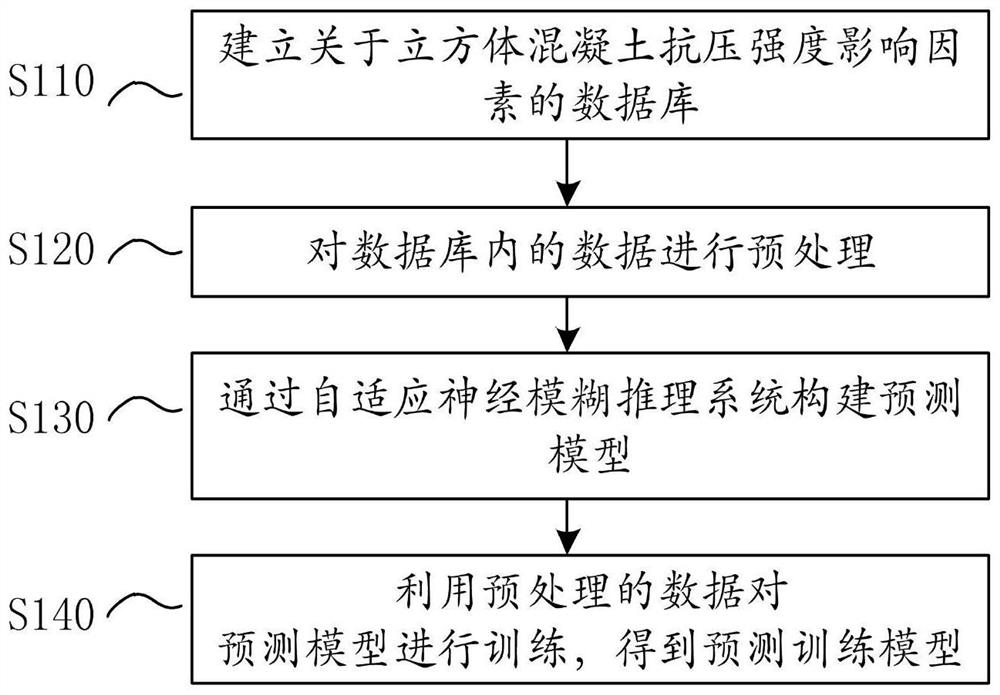
图1示出了本申请实施例的模型构建方法流程图。
图2示出了本申请实施例的预处理流程图。
图3示出了本申请实施例的自适应神经模糊推理系统结构示意图。
图4示出了本申请实施例的模型构建装置结构示意图。
图5示出了本申请实施例的混凝土抗压强度预测方法流程图。
图6示出了本申请实施例的获取待测混凝土的抗压强度主要影响因素的流程图。
图7示出了本申请实施例的进行普通混凝土或人工砂混凝土抗压强度预测方法整体流程架构图。
图8示出了本申请实施例的混凝土抗压强度预测装置结构示意图。
图9示出了测试组样本的预测抗压强度与实际抗压强度的相关性结果。
具体实施方式
为了使本技术领域的人员更好地理解本申请方案,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分的实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本申请保护的范围。
本申请实施例在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行,并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
实施例一
图1是本申请实施例的模型构建方法流程图,如图1所示,该方法包括如下步骤:
S110、建立关于立方体混凝土抗压强度影响因素的数据库。本实例的数据库从现有文献中收集,总共286个样本。
其中,影响因素包括:水泥抗压强度、水泥抗拉强度、混凝土养护龄期、粗骨料最大粒径、石粉掺量、沙子的细度模数、水粘合剂比、水灰比、水的质量、含砂率、坍落度共11个。
以上述指标作为模型的定量输入值,立方体混凝土抗压强度作为模型的定量输出值。
S120、对数据库内的数据进行预处理。
为评估问题输入过多时空间压缩的可行性,防止过度训练、降低数据中的噪声及获得主要影响特征,可对输入数据先进行如下的预处理,如图2所示:
S121、将数据库中的n个样本的原始数据x
S122、对样本矩阵X通过如下的标准变换,转换为标准化矩阵Z:
其中,
S123、获取标准化矩阵Z的相关系数矩阵R,如下:
其中,
S124、获取相关系数矩阵R的单位特征向量,具体如下:
解相关系数矩阵R的特征方程|R-λI
通过
对每个λ
S125、将标准化的指标转换为主成分,具体如下:
通过
S126、对m个主成分进行综合评价,具体如下:
对m个主成分进行加权求和,即得最终评价值,权数为每个主成分的方差贡献率。
S130、通过自适应神经模糊推理系统构建预测模型。
通过如附图3所示的5层自适应神经模糊推理系统构建预测模型,以主成分分析法获得的m个主成分作为输入特征参数,经过模糊推理,得到一个总输出O
其中,推理规则可设置如下:
如果u
其中,u
以两个输入数据为例,则其推理规则为:
规则1:如果U
规则2:如果U
规则3:如果U
规则4:如果U
设置自适应神经模糊推理的系统的结构为5层,如下:
第1层为模糊化层,其可将输入特征模糊化,并输出对应模糊集的隶属度。该层的每个结点i是一个有结点函数的自适应结点。
其输出为:
其中,
进一步的,隶属函数可选择任意合适的参数化来隶属函数,如选择如下的高斯函数:
其中,c
第2层用于实现对前提部分的模糊集的运算。该层中的每个结点都为固定结点,其输出是所有输入数据的代数积。每个结点的输出表示一条规则的激励强度,其设置如下:
其中,w
第3层用于将各条规则的激励强度归一化,该层中的结点也为固定结点,其输出设置如下:
其中,
第4层用于获得每条规则的输出,该层的每个结点i是一个有结点函数的自适应结点。其输出设置如下:
第5层,该层的单结点是一个固定结点,其计算所有传来信号之和作为总输出,如下:
其中O
S140、利用预处理的数据对预测模型进行训练,得到预测训练模型。
训练可选择教与学优化算法,步骤如下:
S141:对参数进行初始化并定义班级里的学员数量。其中,班级表示种群中所有个体的集合,其中每一个个体表示班级里的学员。
S142:进入教学阶段,即向全局最优解学习。教师的主要目标是根据每个学生的能力来提高这门课的平均成绩,其中X
Diff=r
x′
其中,r
S143:进入学习阶段,即个体之间互相学习。对于每一个个体,通过分析与其他个体之间的差异进行学习调整,使得不会过早向全局最优点方向聚焦,从而保证了算法在搜索空间的全局探索能力。具体设置如下:
X″
X″
其中,r
本实施例中的预测训练模型为本申请上述实施例的模型构建方法得到的预测训练模型。
实施例二
本申请实施例还提供了一种模型构建装置,用于执行本申请实例一的模型构建方法,如图4所示,该构建装置包括:数据库单元、预处理单元、构建单元、训练单元。
数据库单元,用于建立关于立方体混凝土抗压强度影响因素的数据库。
其中,影响因素包括:水泥抗压强度、水泥抗拉强度、混凝土养护龄期、粗骨料最大粒径、石粉掺量、沙子的细度模数、水粘合剂比、水灰比、水的质量、含砂率、坍落度中一种或多种。以上述指标作为待构建的模型的定量输入值,立方体混凝土抗压强度作为待构建的模型的定量输出值。
预处理单元,用于对数据库内的数据进行预处理。
具体的,预处理单元,用于执行如实施例一中的S121~S126以完成预处理。
构建单元,通过自适应神经模糊推理系统构建预测模型。
具体的,构建单元用于通过如图3所示的5层自适应神经模糊推理系统构建预测模型,以主成分分析法获得的m个主成分作为输入特征参数,经过模糊推理,得到一个总输出O
其中,所述自适应神经模糊推理系统,推理规则可设置如下:
如果u
其中,u
以两个输入数据为例,则其推理规则为:
规则1:如果U
规则2:如果U
规则3:如果U
规则4:如果U
设置自适应神经模糊推理的系统的结构为5层,如下:
第1层为模糊化层,其可将输入特征模糊化,并输出对应模糊集的隶属度。该层的每个结点i是一个有结点函数的自适应结点。
其输出为:
其中,
进一步的,隶属函数可选择任意合适的参数化来隶属函数,如选择如下的高斯函数:
其中,c
第2层用于实现对前提部分的模糊集的运算。该层中的每个结点都为固定结点,其输出是所有输入数据的代数积。每个结点的输出表示一条规则的激励强度,其设置如下:
其中,w
第3层用于将各条规则的激励强度归一化,该层中的结点也为固定结点,其输出设置如下:
其中,
第4层用于获得每条规则的输出,该层的每个结点i是一个有结点函数的自适应结点。其输出设置如下:
第5层,该层的单结点是一个固定结点,其计算所有传来信号之和作为总输出,如下:
其中O
训练单元,用于利用预处理的数据对预测模型进行训练,得到预测训练模型。
具体的,训练单元用于通过教与学优化算法对预测模型进行训练,具体用于执行如实施例一中的S141~S143。
实施例三
本申请实施例还提供了一种混凝土抗压强度预测方法,该预测方法用于通过本申请实施例一的模型构建方法得到的预测训练模型来预测混凝土抗压强度。
本实例的数据库从现有文献中收集,总共286个样本,如实施例一。输出为人工砂混凝土的抗压强度。
如图5所示,本实例混凝土抗压强度预测方法包括步骤:
S210、获取待测混凝土的抗压强度主要影响因素。
其中,待测混凝土的抗压强度主要影响因素,是通过对待测混凝土的水泥抗压强度、水泥抗拉强度、混凝土养护龄期、粗骨料最大粒径、石粉掺量、沙子的细度模数、水粘合剂比、水灰比、水的质量、含砂率、坍落度中共11种进行主成分分析获得。
所述主成分分析,如图6所示,包括如下步骤:
S211、对待测混凝土的水泥抗压强度、水泥抗拉强度、混凝土养护龄期、粗骨料最大粒径、石粉掺量、沙子的细度模数、水粘合剂比、水灰比、水的质量、含砂率、坍落度中共11种的数据集合进行排列以获取样本矩阵;
S212、获取样本矩阵的标准化矩阵,该步骤的详细过程参考本申请实施例一的S122执行。
S213、获取标准化矩阵的相关系数矩阵,该步骤的详细过程参考本申请实施例一的S123执行。
S214、获得相关系数矩阵的单位特征向量,该步骤的详细过程参考本申请实施例一的S124执行。
S215、通过单位特征向量将标准化矩阵中标准化分量转换为主成分,该步骤的详细过程参考本申请实施例一的S125执行。
S216、对各个主成分进行加权求和,权数为每个主成分的方差贡献率。
S220、将所述抗压强度主要影响因素输入到本申请实施例一的模型构建方法得到的预测训练模型中,利用所述预测训练模型对待测混泥土抗压强度进行预测。
如图7所示,为利用本申请实例一构建的预测训练模型,进行普通混凝土或人工砂混凝土抗压强度预测方法的流程架构图。
通过本申请对实施例进行训练,并与独立的人工神经网络方法做对比,归纳本申请在预测混凝土强度上的优势。
图9为测试组样本的预测抗压强度与实际抗压强度的相关性结果。测试组样本的相关性数据点的拟合曲线与曲线“y=x”十分贴近,说明本申请在预测抗压强度上的准确性与适用性。
表1不同方法预测能力的比较
如表1所示,本申请实施例在预测抗压强度上准确性上更进一步,提高了预测人工砂混凝土强度能力,是更好的方法。
实施例四
本申请实施例还提供了一种混凝土抗压强度预测装置,该装置用于执行实施例三的混凝土抗压强度预测方法,如图8所示,包括输入单元和预测单元。
输入单元,用于获取待测混凝土的抗压强度主要影响因素。
其中,待测混凝土的抗压强度主要影响因素,是通过对待测混凝土的水泥抗压强度、水泥抗拉强度、混凝土养护龄期、粗骨料最大粒径、石粉掺量、沙子的细度模数、水粘合剂比、水灰比、水的质量、含砂率、坍落度中一种或多种进行主成分分析获得。
输入单元用于参照本申请实施例三的主成分分析步骤获得的待测混凝土的抗压强度主要影响因素。
预测单元,用于将所述抗压强度主要影响因素输入到本申请实施例一的模型构建方法得到的预测训练模型中,利用所述预测训练模型对待测混泥土抗压强度进行预测。
以上仅为本申请的优选实施例,并不表示是唯一的或是限制本申请。本领域技术人员应理解,在不脱离本申请的范围情况下,对本申请进行的各种改变或同等替换,均属于本申请保护的范围。
- 模型构建方法及装置和混凝土抗压强度预测方法及装置
- 模型构建方法、软件缺陷预测方法、装置以及电子装置