一种基于HDFS的数据转换存储方法
文献发布时间:2023-06-19 12:02:28
技术领域
本发明涉及计算机技术领域,具体涉及一种基于HDFS的数据转换存储方法。
背景技术
随着工业互联网的快速发展,工业大数据的存储已成为工业互联网的发展核心。工业大数据是指在工业领域中,围绕典型智能制造模式,从客户需求到销售、订单、计划、研发、设计、工艺、制造、采购、供应、库存、发货和交付、售后服务、运维、报废或回收再制造等整个产品全生命周期各个环节所产生的各类数据及相关技术和应用的总称。工业大数据包括设备运行数据、生产数据、企业运营数据等海量数据源,且数据质量参差不齐,同时工业大数据动辄几十上百T,需要大量的存储空间存储。
目前,工业大数据的存储一般采用HBase数据库、MongoDB数据库和HDFS存储服务器等多种方式,其中的HDFS存储服务器是最常用的之一。HDFS(Hadoop Distributed FileSystem,分布式文件系统)是一个高度容错性的系统,其能够提供高吞吐量的数据访问,非常适合大规模数据集上的应用。例如,公开号为CN110515894A的中国专利就公开了《一种数据格式转换方法、装置、设备及可读存储介质》,该数据格式转换方法应用于HDFS系统,包括:获取用户通过人机交互界面输入的源数据的源路径,以及目的数据的目的路径和目的格式;按照源路径读取源数据,并确定源数据的源格式;从预设的格式转换器中调用与源格式和目的格式匹配的格式转换程序将源数据由源格式转换为目的格式,获得目的数据;所述格式转换器中存储有多种格式转换程序;按照目的路径存储目的数据。
上述现有方案中的数据格式转换方法也是一种基于HDFS的数据转换存储方法,其能够转换数据源的数据格式,使得数据能够通过HDFS存储服务器存储。申请人发现,HDFS存储服务器虽然支持百万规模以上的文件数量,但是其文件一旦创建则无法修改,并且会并发导致海量小文件的产生,使得文件的数据格式难以固定,导致数据的存储效果不好。因此,如何提供一种能够在数据存储前固定文件数据格式的数据转换存储方法是急需解决的技术问题。
发明内容
针对上述现有技术的不足,本发明所要解决的技术问题是:如何提供一种能够在数据存储前固定文件数据格式的基于HDFS的数据转换存储方法,从而能够提升工业大数据的数据存储效果。
为了解决上述技术问题,本发明采用了如下的技术方案:
一种基于HDFS的数据转换存储方法,其配置HDFS存储服务器,并设置HDFS存储服务器存储文件的文件大小;然后将数据源的数据转换成大小与HDFS存储服务器存储文件的文件大小相适应的文件,并将对应的文件存储在HDFS存储服务器中。
优选的,数据转换存储方法包括以下步骤:
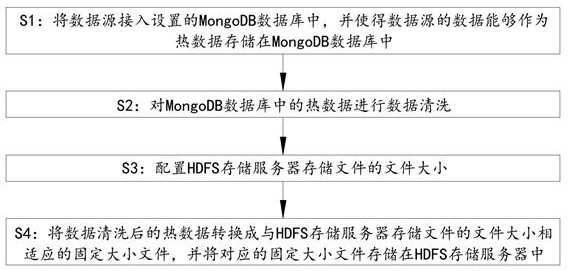
S1:将数据源接入设置的MongoDB数据库中,并使得数据源的数据能够作为热数据存储在MongoDB数据库中;
S2:对MongoDB数据库中的热数据进行数据清洗;
S3:配置HDFS存储服务器存储文件的文件大小;
S4:将数据清洗后的热数据转换成与HDFS存储服务器存储文件的文件大小相适应的固定大小文件,并将对应的固定大小文件存储在HDFS存储服务器中。
优选的,步骤S1中,首先根据数据源的接入方式配置对应的数据源信息;然后给数据源配置对应的MongoDB数据库信息,以使得数据源能够接入对应的MongoDB数据库中。
优选的,步骤S1中,MongoDB数据库信息包括MongoDB数据库的服务器地址、MongoRouter地址、端口和dataBase名称中的任一个或多个。
优选的,步骤S2中,输入数据清洗的正则表达式来对MongoDB数据库中的热数据进行数据清洗。
优选的,步骤S2中,将清洗后的热数据存储在设置的Redis缓存中。
优选的,步骤S3中,根据数据存储的实际情况配置对应的HDFS存储服务器。
优选的,步骤S4中,通过数据合成和数据分割的方式将数据清洗后的热数据转换大小与HDFS存储服务器存储文件的文件大小一致的固定大小文件。
本发明中基于HDFS的数据转换存储方法与现有技术相比,具有如下有益效果:
1、本发明中,预先配置了HDFS存储服务器存储文件的文件大小,使得能够固定HDFS存储服务器中文件的大小,进而能够在数据存储前解决小文件产生的问题,即能够在数据存储前固定文件的数据格式,从而能够提升工业大数据的数据存储效果。
2、本发明中,通过MongoDB数据库实现热数据的数据清洗处理,并对数据清洗处理后的热数据进行转换和存储,这能够提升热数据的数据质量,从而能够提升工业大数据的数据存储质量。
附图说明
为了使发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步的详细描述,其中:
图1为实施例中数据转换存储方法的逻辑框图。
具体实施方式
下面通过具体实施方式进一步详细的说明:
实施例:
本实施例中公开了一种基于HDFS的数据转换存储方法。
如图1所示,一种基于HDFS的数据转换存储方法,其配置HDFS存储服务器,并设置HDFS存储服务器存储文件的文件大小;然后将数据源的数据转换成大小与HDFS存储服务器存储文件的文件大小相适应的文件,并将对应的文件存储在HDFS存储服务器中。具体的,数据转换存储方法包括以下步骤:
S1:将数据源接入设置的MongoDB数据库中,并使得数据源的数据能够作为热数据存储在MongoDB数据库中。
S2:对MongoDB数据库中的热数据进行数据清洗。
S3:配置HDFS存储服务器存储文件的文件大小。具体的,根据数据存储的实际情况配置对应的HDFS存储服务器。
S4:将数据清洗后的热数据转换成与HDFS存储服务器存储文件的文件大小相适应的固定大小文件,并将对应的固定大小文件存储在HDFS存储服务器中。具体的,通过数据合成和数据分割的方式将数据清洗后的热数据转换大小与HDFS存储服务器存储文件的文件大小一致的固定大小文件。
本发明中,预先配置了HDFS存储服务器存储文件的文件大小,使得能够固定HDFS存储服务器中文件的大小,进而能够在数据存储前解决小文件产生的问题,即能够在数据存储前固定文件的数据格式,从而能够提升工业大数据的数据存储效果。其次,本发明通过MongoDB数据库实现热数据的数据清洗处理,并对数据清洗处理后的热数据进行转换和存储,这能够提升热数据的数据质量,从而能够提升工业大数据的数据存储质量。
具体实施过程中,步骤S1中,首先根据数据源的接入方式配置对应的数据源信息;然后给数据源配置对应的MongoDB数据库信息,以使得数据源能够接入对应的MongoDB数据库中。具体的,MongoDB数据库信息包括MongoDB数据库的服务器地址、Mongo Router地址、端口和dataBase名称中的任一个或多个。
本发明中,通过配置数据源信息和MongoDB数据库信息的方式,使得数据源能够更好的接入MongoDB数据库,进而能够保证后续热数据的数据清洗效果,从而能够辅助提升工业大数据的数据质量。
具体实施过程中,步骤S2中,输入数据清洗的正则表达式来对MongoDB数据库中的热数据进行数据清洗。具体的,将清洗后的热数据存储在设置的Redis缓存中。
本发明中,数据清洗处理时无需编写数据清洗算法,而是 直接配置正则表达式即能够完成数据清洗算法配置,这能够提升热数据的数据清洗效率。其次,本发明将清洗后的热数据存储在Redis缓存中,这有利于更好的调用清洗后的热数据进行转换和存储,从而能够辅助 提升工业大数据的数据存储效果。
为了更好的介绍本发明基于HDFS的数据转换存储方法,现在通过如下具体实施过程来做说明:
1)根据数据源的接入方式配置对应的数据源信息。
例1:数据源为危废车设备直接连接,配置的数据源信息包括:设备唯一标识、设备名称、设备MAC地址、设备端口、密钥、设备协议。如危废车运行数据,设备ID:15SKHz5232;设备名称:危废车001;设备MAC地址:08:00:20:0A:8C:6D;设备密钥:6GY*****BYR;设备协议:MQTT。
例2:数据源为各大系统数据存储对应的数据库,配置的数据源信息包括:数据库类型、数据库主机地址、端口、数据库名称、数据库用户名、数据库密码。如数据库类型:Postgre,主机地址:10.10.10.10,端口号:26530;database名称:database1,数据库密码:125***。
2)给数据源配置对应的MongoDB数据库信息。
MongoDB数据库信息包括MongoDB数据库的Mongo Router地址:12.12.12.12,端口:20000;dataBase名称:MongoDB001。
3)对MongoDB数据库中的热数据进行数据清洗。
获取MongoDB数据库中待清洗的热数据,匹配字段信息,针对每个字段或者连续字段信息写入数据正则表达式,如字段非空、字段非0、字段长度有效性。
如获取的设备数据源中一条数据为data={"parameterName":"总里程","parameterCode":"","parameterUnit":"km","parameterMin":1,"parameterMax":300000},其中parameterCode字段存在空值情况,将对象数据转换为字符串数据为"{\"parameterName\":\"总里程\",\"parameterCode\":\"\",\"parameterUnit\":\"km\",\"parameterMin\":1,\"parameterMax\":300000}",则对应的整条数据清洗的正则表达式为^[\s\S]*:\"[\S]+\"{3}[\s\S]*:[\d]+{2}$,即可完成数据过滤正则表达式配置。
4)将清洗后的热数据存储在设置的Redis缓存中,完成数据阶段性清洗。
5)根据数据存储的实际情况配置对应的HDFS存储服务器。
HDFS存储服务器的主机地址namenode:hdfs/127.0.12.3;用户:hdfsuser;HDFS集群访问并发数:10。
6)配置HDFS存储服务器存储文件的文件大小。
如设置HDFS存储服务器存储文件的文件大小为56M,则同步修改HDFS集群中HDFS文件大小为:dfs.namenode.fs-limits.min-block-size=56M。
7)将数据清洗后的热数据转换成与HDFS存储服务器存储文件的文件大小相适应的固定大小文件,并将对应的固定大小文件存储在HDFS存储服务器中,待做数据分析调用以及进行离线数据分析。
以上所述的仅是本发明的实施例,方案中公知的具体结构及特性等常识在此未作过多描述,所属领域普通技术人员知晓申请日或者优先权日之前发明所属技术领域所有的普通技术知识,能够获知该领域中所有的现有技术,并且具有应用该日期之前常规实验手段的能力,所属领域普通技术人员可以在本申请给出的启示下,结合自身能力完善并实施本方案,一些典型的公知结构或者公知方法不应当成为所属领域普通技术人员实施本申请的障碍。应当指出,对于本领域的技术人员来说,在不脱离本发明结构的前提下,还可以作出若干变形和改进,这些也应该视为本发明的保护范围,这些都不会影响本发明实施的效果和专利的实用性。本申请要求的保护范围应当以其权利要求的内容为准,说明书中的具体实施方式等记载可以用于解释权利要求的内容。
- 一种基于HDFS的数据转换存储方法
- 一种基于hdfs存储且用lucene做索引的文件存储方法