文档摘要生成方法、装置、存储介质及电子设备
文献发布时间:2023-06-19 12:05:39
技术领域
本公开涉及自然语言处理领域,具体地,涉及一种文档摘要生成方法、装置、存储介质及电子设备。
背景技术
随着互联网产生的文本数据越来越多,文本信息过载问题日益严重,对各类文本进行一个“降维”处理显得非常必要,文本摘要便是其中一个重要的手段。而文档摘要生成是自然语言处理、信息抽取的一项子任务,其目的是从文档文本数据中提取核心内容,并把这些核心内容组装为文档摘要。同时,在项目孵化的过程中存在着大量繁杂的项目文档,利用摘要生成算法提取不同领域的项目文档中的核心内容并组装成文档摘要,可以很大程度上减少人工审阅的工作。
相关技术中的文档摘要生成方案是从原文中获取关键词和关键句组成摘要,虽然在语法、句法上有一定的保证,但是也面临着内容选择错误、连贯性差、灵活性差等问题。还有一种方案是通过转述、同义替换、句子缩写等技术,生成更凝练简洁的摘要,但是也存在着语义理解不充分、摘要语句不通顺、摘要准确度不够高等问题。
发明内容
本公开的目的是提供一种文档摘要生成方法、装置、存储介质及电子设备,以解决上述问题。
为了实现上述目的,本公开第一方面提供一种文档摘要生成方法,包括:
统计所述文本文档的词频数据特征,并获取所述文本文档中的词性特征、以及词的句法依存特征;
将所述词频数据特征、词性特征以及所述词的句法依存特征添加到所述文本文档的词向量特征中,得到目标向量特征;
将所述目标向量特征输入训练完成的深度学习模型中,得到所述深度学习模型输出的文档摘要。
可选地,所述获取所述文本文档中的词性特征、以及词的句法依存特征包括:
基于stanza工具对所述文本文档进行处理,以得到所述stanza工具返回的所述文本文档的单个句子中的每个词的词性特征、以及词的句法依存特征。
可选地,所述深度学习模型的训练包括:
获取训练文档样本,所述训练样本文档包括未标注文本以及标注文本;
根据所述训练文档样本对所述深度学习模型进行半监督的虚拟对抗训练。
可选地,所述根据所述训练文档样本对所述深度学习模型进行半监督的虚拟对抗训练,包括:
统计所述训练文档样本的词频数据样本特征,并获取所述训练文档样本中的词性样本特征、以及词的句法依存样本特征;
将所述词频数据样本特征、词性样本特征以及所述词的句法依存样本特征添加到所述文本文档样本的词向量特征中,得到目标向量样本特征;
对所述目标向量样本特征的数据点进行扰动变换,并通过求取每一次变换后的向量样本特征对应的模型输出与所述目标向量样本特征对应的模型输出之间的KL散度,确定使得所述KL散度最大化的目标扰动量;
将所述目标扰动量作为虚拟对抗扰动,根据所述虚拟对抗扰动以及添加所述虚拟对抗扰动后的向量样本特征,对所述深度学习模型的参数进行更新,使得添加所述虚拟对抗扰动后的向量样本特征对应的模型输出与所述目标向量样本特征对应的模型输出之间的KL散度最小化。
可选地,所述根据所述训练文档样本对所述深度学习模型进行半监督的虚拟对抗训练,还包括:
通过损失函数计算损失值,所述损失函数包括第一损失函数以及第二损失函数,所述第一损失函数用于计算虚拟对抗训练产生的第一损失值,所述第二损失函数模型验证产生的第二损失值;
根据所述第一损失值和所述第二损失值更新所述深度学习模型的参数,使得所述第一损失值和所述第二损失值之和最小化。
本公开第二方面提供一种文档摘要生成装置,所述装置包括:
获取模块,被配置为统计所述文本文档的词频数据特征,并获取所述文本文档中的词性特征、以及词的句法依存特征;
添加模块,被配置为将所述词频数据特征、词性特征以及所述词的句法依存特征添加到所述文本文档的词向量特征中,得到目标向量特征;
输出模块,被配置为将所述目标向量特征输入训练完成的深度学习模型中,得到所述深度学习模型输出的文档摘要。
可选地,所述获取模块还包括:
返回子模块,被配置为基于stanza工具对所述文本文档进行处理,以得到所述stanza工具返回的所述文本文档的单个句子中的每个词的词性特征、以及词的句法依存特征。
可选地,所述深度学习模型的训练包括:
获取训练文档样本,所述训练样本文档包括未标注文本以及标注文本;
根据所述训练文档样本对所述深度学习模型进行半监督的虚拟对抗训练。
本公开第三方面提供一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现本公开第一方面所述方法的步骤。
本公开第四方面提供一种电子设备,包括:
存储器,其上存储有计算机程序;
处理器,用于执行所述存储器中的所述计算机程序,以实现本公开第一方面所述方法的步骤。
通过上述技术方案,至少能够达到以下技术效果:
通过统计所述文本文档的词频数据特征,并获取所述文本文档中的词性特征、以及词的句法依存特征,并将所述词频数据特征、词性特征以及所述词的句法依存特征添加到所述文本文档的词向量特征中,得到目标向量特征最后将所述目标向量特征输入训练完成的深度学习模型中,得到所述深度学习模型输出的文档摘要。这样,通过加入能够体现语义的词频数据特征、词性特征以及所述词的句法依存特征,增强了模型对语义的理解程度,进而提升了文档摘要的通顺性
本公开的其他特征和优点将在随后的具体实施方式部分予以详细说明。
附图说明
附图是用来提供对本公开的进一步理解,并且构成说明书的一部分,与下面的具体实施方式一起用于解释本公开,但并不构成对本公开的限制。在附图中:
图1是根据一示例性实施例示出的一种文档摘要生成方法的流程图。
图2是根据一示例性实施例示出的一种文档摘要生成装置的框图。
图3是根据一示例性实施例示出的一种电子设备的框图。
具体实施方式
以下结合附图对本公开的具体实施方式进行详细说明。应当理解的是,此处所描述的具体实施方式仅用于说明和解释本公开,并不用于限制本公开。
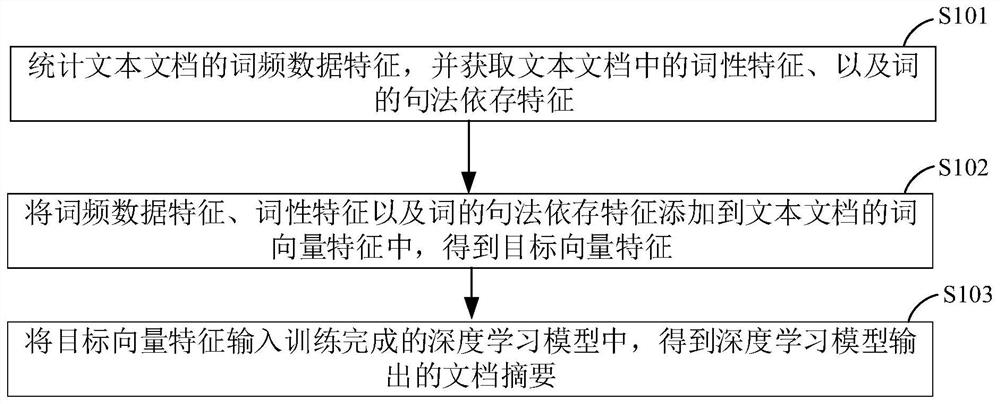
本公开实施例提供一种文档摘要生成的方法,如图1所示,该方法包括:
在步骤S101中,统计文本文档的词频数据特征,并获取文本文档中的词性特征、以及词的句法依存特征。
在步骤S102中,将词频数据特征、词性特征以及词的句法依存特征添加到文本文档的词向量特征中,得到目标向量特征。
在步骤S103中,将目标向量特征输入训练完成的深度学习模型中,得到深度学习模型输出的文档摘要。
示例地,该深度学习模型可以是用CBOW模型并结合摘要的特点来针对词频数据特征、词性特征以及词的句法依存特征等词向量特征进行训练得到的。
采用上述方法,通过统计所述文本文档的词频数据特征,并获取所述文本文档中的词性特征、以及词的句法依存特征,并将所述词频数据特征、词性特征以及所述词的句法依存特征添加到所述文本文档的词向量特征中,得到目标向量特征最后将所述目标向量特征输入训练完成的深度学习模型中,得到所述深度学习模型输出的文档摘要。这样,通过加入能够体现语义的词频数据特征、词性特征以及所述词的句法依存特征,增强了模型对语义的理解程度,进而提升了文档摘要的通顺性,也就是说本公开实施例提供的技术方案能够通过改进词向量的生成方式来充分理解语义并使得生成的摘要语句更加通顺。
在一种可能的实施方式中,所述获取所述文本文档中的词性特征、以及词的句法依存特征包括:
基于stanza工具对所述文本文档进行处理,以得到所述stanza工具返回的所述文本文档的单个句子中的每个词的词性特征、以及词的句法依存特征。
值得说明的是,stanza工具可以针对输入的文本文档返回词性特征和词的句法依存特征。例如,返回的词性特征可以为noun(名词)、verb(动词)、num(数量词)、adjp(形容词短语)等,返回词的句法依存特征可以为nsubj(名词主语)、obj(宾语)、det(冠词)、advcl(状语从句修饰词)等。
在一种可能的实施方式中,所述深度学习模型的训练包括:
获取训练文档样本,所述训练样本文档包括未标注文本以及标注文本;
根据所述训练文档样本对所述深度学习模型进行半监督的虚拟对抗训练。
示例地,通过人工选取的方式获取一批文档样本,对所述文档样本进行摘要标注作为标注文本,另外选取一批文档样本不做任何处理作为未标注文本,将两批文档样本进行混合作为训练文档样本并进行半监督的虚拟对抗训练。
这里,由于对模型的训练使用了半监督的学习方式,能够使得训练完成的深度学习模型具有较强的的泛化能力,即该深度学习模型能很好的适用于整个样本空间。而虚拟对抗训练是一种有效的数据增强技术,不需要先前的领域知识。在虚拟对抗训练中,不使用标签信息,仅使用模型输出生成扰动,产生扰动使得扰动输入的输出不同于原始输入的模型输出。可以减少算法对有效标注样本的依赖。本公开实施例使用虚拟对抗训练,降低了半监督学习对有效标注样本的依赖性,使得对深度学习模型的训练可以采用更多的无标注样本进行半监督训练,提升了深度学习模型的泛化能力。
在一种可能的实施方式中,所述根据所述训练文档样本对所述深度学习模型进行半监督的虚拟对抗训练,包括:
统计所述训练文档样本的词频数据样本特征,并获取所述训练文档样本中的词性样本特征、以及词的句法依存样本特征;
将所述词频数据样本特征、词性样本特征以及所述词的句法依存样本特征添加到所述文本文档样本的词向量特征中,得到目标向量样本特征;
对所述目标向量样本特征的数据点进行扰动变换,并通过求取每一次变换后的向量样本特征对应的模型输出与所述目标向量样本特征对应的模型输出之间的KL散度,确定使得所述KL散度最大化的目标扰动量;
将所述目标扰动量作为虚拟对抗扰动,根据所述虚拟对抗扰动以及添加所述虚拟对抗扰动后的向量样本特征,对所述深度学习模型的参数进行更新,使得添加所述虚拟对抗扰动后的向量样本特征对应的模型输出与所述目标向量样本特征对应的模型输出之间的KL散度最小化。
下面对虚拟对抗训练的基本过程进行说明:首先从输入数据点x开始,通过添加小的扰动r来变换x,其中变换的数据点为T(x)=X+r,将T(x)作为扰动输入,模型对应该扰动输入T(x)的输出应该与非扰动输入的输出不同,且两个输出之间的KL差异应该是最大的,同时确保r的L2范数很小。因此,可以从所有的扰动r中,确定对抗方向上的虚拟对抗扰动r
Δ
其中,x为输入数据点,r为扰动变换后的数据点,θ为模型参数,n为输入数据点的数据标签,计算式(1)用于求取输入数据点x和扰动变换后的数据点r对应的模型输出p(y|x
最后在找到虚拟对抗扰动和变换输入之后,通过更新模型的权重,使得KL散度最小化,这将使模型对不同的扰动具有鲁棒性。具体地,可以通过梯度下降最小化计算式(3)所述的损失函数计算得到的损失值:
在一种可能的实施方式中,所述根据所述训练文档样本对所述深度学习模型进行半监督的虚拟对抗训练,还包括:
通过损失函数计算损失值,所述损失函数包括第一损失函数以及第二损失函数,所述第一损失函数用于计算虚拟对抗训练产生的第一损失值,所述第二损失函数模型验证产生的第二损失值;
根据所述第一损失值和所述第二损失值更新所述深度学习模型的参数,使得所述第一损失值和所述第二损失值之和最小化。
示例地,利用标注文本来建立深度学习网络模型,并通过损失函数计算损失值,求出计算虚拟对抗训练产生的第一损失值和第二损失值,更新深度学习模型的参数联合损失最小化,联合损失最小化min(total_loss),其中,
total_loss=Model_loss+vat_loss (4)
其中,vat_loss可以是上述计算式(3)计算得到的损失值(即所述第一损失值),Model_loss可以是对深度学习模型进行模型验证过程中计算得到的模型损失值(即所述第二损失值)。
图2是根据本公开一示例性实施例示出一种文档摘要生成装置的框图,所述文档摘要生成装置200包括:
获取模块201,用于为统计所述文本文档的词频数据特征,并获取所述文本文档中的词性特征、以及词的句法依存特征;
添加模块202,用于将所述词频数据特征、词性特征以及所述词的句法依存特征添加到所述文本文档的词向量特征中,得到目标向量特征;
编码模块203,用于将所述目标向量特征输入训练完成的深度学习模型中,得到所述深度学习模型输出的文档摘要。
采用上述装置,通过统计所述文本文档的词频数据特征,并获取所述文本文档中的词性特征、以及词的句法依存特征,并将所述词频数据特征、词性特征以及所述词的句法依存特征添加到所述文本文档的词向量特征中,得到目标向量特征最后将所述目标向量特征输入训练完成的深度学习模型中,得到所述深度学习模型输出的文档摘要。这样,通过加入能够体现语义的词频数据特征、词性特征以及所述词的句法依存特征,增强了模型对语义的理解程度,进而提升了文档摘要的通顺性
可选地,所述获取模块具体被配置为基于stanza工具对所述文本文档进行处理,以得到所述stanza工具返回的所述文本文档的单个句子中的每个词的词性特征、以及词的句法依存特征。
可选地,所述深度学习模型的训练包括:
获取训练文档样本,所述训练样本文档包括未标注文本以及标注文本;
根据所述训练文档样本对所述深度学习模型进行半监督的虚拟对抗训练。
可选地,所述根据所述训练文档样本对所述深度学习模型进行半监督的虚拟对抗训练,包括:
统计所述训练文档样本的词频数据样本特征,并获取所述训练文档样本中的词性样本特征、以及词的句法依存样本特征;
将所述词频数据样本特征、词性样本特征以及所述词的句法依存样本特征添加到所述文本文档样本的词向量特征中,得到目标向量样本特征;
对所述目标向量样本特征的数据点进行扰动变换,并通过求取每一次变换后的向量样本特征对应的模型输出与所述目标向量样本特征对应的模型输出之间的KL散度,确定使得所述KL散度最大化的目标扰动量;
将所述目标扰动量作为虚拟对抗扰动,根据所述虚拟对抗扰动以及添加所述虚拟对抗扰动后的向量样本特征,对所述深度学习模型的参数进行更新,使得添加所述虚拟对抗扰动后的向量样本特征对应的模型输出与所述目标向量样本特征对应的模型输出之间的KL散度最小化。
可选地,所述根据所述训练文档样本对所述深度学习模型进行半监督的虚拟对抗训练,还包括:
通过损失函数计算损失值,所述损失函数包括第一损失函数以及第二损失函数,所述第一损失函数用于计算虚拟对抗训练产生的第一损失值,所述第二损失函数模型验证产生的第二损失值;
根据所述第一损失值和所述第二损失值更新所述深度学习模型的参数,使得所述第一损失值和所述第二损失值之和最小化。
关于上述实施例中的装置,其中各个模块执行操作的具体方式已经在有关该方法的实施例中进行了详细描述,此处将不做详细阐述说明。
本公开实施例还提供一种电子设备,包括:
存储器,其上存储有计算机程序;
处理器,用于执行所述存储器中的所述计算机程序,以实现上述方法实施例提供的方法的步骤。
图3是根据一示例性实施例示出的一种电子设备1900的框图。例如,电子设备1900可以被提供为一服务器。参照图3,电子设备1900包括处理器1922,其数量可以为一个或多个,以及存储器1932,用于存储可由处理器1922执行的计算机程序。存储器1932中存储的计算机程序可以包括一个或一个以上的每一个对应于一组指令的模块。此外,处理器1922可以被配置为执行该计算机程序,以执行上述的文档摘要生成方法。
另外,电子设备1900还可以包括电源组件1926和通信组件1950,该电源组件1926可以被配置为执行电子设备1900的电源管理,该通信组件1950可以被配置为实现电子设备1900的通信,例如,有线或无线通信。此外,该电子设备1900还可以包括输入/输出(I/O)接口1958。电子设备1900可以操作基于存储在存储器1932的操作系统,例如WindowsServer
在另一示例性实施例中,本公开实施例还提供一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现上述方法实施例提供的方法的步骤。例如,该计算机可读存储介质可以为上述包括程序指令的存储器1932,上述程序指令可由电子设备1900的处理器1922执行以完成上述的文档摘要生成方法。
在另一示例性实施例中,还提供一种计算机程序产品,该计算机程序产品包含能够由可编程的装置执行的计算机程序,该计算机程序具有当由该可编程的装置执行时用于执行上述的文档摘要生成方法的代码部分。
此外,本公开的各种不同的实施方式之间也可以进行任意组合,只要其不违背本公开的思想,其同样应当视为本公开所公开的内容。
- 文档摘要生成方法、装置、存储介质及电子设备
- 印尼语文档摘要生成方法、装置、存储介质及终端设备