基于人口分布的环境风险评估方法、装置及计算机设备
文献发布时间:2023-06-19 12:19:35
技术领域
本申请涉及信息处理领域,尤其涉及到一种基于人口分布的环境风险评估方法、装置及计算机设备。
背景技术
人口增长、庞大的人口数量引发了对土地资源、能源资源、矿产资源等的过度消耗,同时还造成了严重的环境污染及生态破坏等问题。随着全国各地雾霾持续爆发,公众对包括PM
目前,人口污染暴露风险普遍采用空气质量监测站点的污染物浓度指标来进行评价。然而,由于污染物的空间分布和人口的空间分布并不一致,直接使用污染物的浓度来代替人们的实际暴露水平可能会出现误差。比如,有些地区污染物浓度很高,但可能只有少量人口居住,造成的人口污染暴露可能很小,而有些地区污染物浓度可能并不异常突出,但暴露在其中的人口很多,因而受害人数更多,造成的健康负担反而更为巨大。因此,亟需科学考虑人口分布对空气污染的敏感度,综合考虑空气污染物分布和人口分布的影响,探索以人为本的城市空气污染暴露风险评价方法。
发明内容
有鉴于此,本申请提供了一种基于人口分布的环境风险评估方法、装置及计算机设备,可以解决目前环境风险评估不准确、不合理的技术问题。
根据本申请的一个方面,提供了一种基于人口分布的环境风险评估方法,该方法包括:
获取预设区域内的区域样本数据,并利用所述区域样本数据训练人口分布预测模型;
提取目标区域内的第一特征数据,并将所述第一特征数据输入训练完成的人口分布预测模型中,获取第二特征数据对应的预测结果,所述第一特征数据至少包括夜间灯光数据,归一化植被指数,数据高程模型数据,坡度、兴趣点及保险数据,所述第二特征数据包括人口分布数据;
确定所述目标区域内的污染物浓度数据,并对所述人口分布数据以及所述污染物浓度数据进行数据叠加分析,得到环境风险评估结果。
根据本申请的另一个方面,提供了一种基于人口分布的环境风险评估装置,该装置包括:
训练模块,用于获取预设区域内的区域样本数据,并利用所述区域样本数据训练人口分布预测模型;
获取模块,用于提取目标区域内的第一特征数据,并将所述第一特征数据输入训练完成的人口分布预测模型中,获取第二特征数据对应的预测结果,所述第一特征数据至少包括夜间灯光数据,归一化植被指数,数据高程模型数据,坡度、兴趣点及保险数据,所述第二特征数据包括人口分布数据;
分析模块,用于确定所述目标区域内的污染物浓度数据,并对所述人口分布数据以及所述污染物浓度数据进行数据叠加分析,得到环境风险评估结果。
根据本申请的又一个方面,提供了一种存储介质,其上存储有计算机程序,所述程序被处理器执行时实现上述基于人口分布的环境风险评估方法。
根据本申请的再一个方面,提供了一种计算机设备,包括存储介质、处理器及存储在存储介质上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述基于人口分布的环境风险评估方法。
借由上述技术方案,本申请提供的一种基于人口分布的环境风险评估方法、装置及计算机设备,与目前环境风险评估的方式相比,本申请可首先利用区域样本数据训练人口分布预测模型,进而利用人口分布预测模型基于目标区域内各个维度的第一特征数据,精细化确定出第二特征数据对应的预测结果,即人口分布数据;进而将目标区域内的污染物浓度数据与人口分布数据进行数据叠加分析,进一步得到环境风险评估结果。通过本申请中的方式,可将空气污染物分布数据和人口分布数据相结合进行人口污染暴露风险的空间化评估。相比于以往直接使用污染物浓度来评估实际暴露水平的方式,在本申请中,考虑了人口因素在空气污染暴露风险评价中的主体作用,通过进行人口分布数据以及污染物浓度数据的数据叠加分析,可提升空气污染暴露风险评价的合理性以及准确性。
附图说明
此处所说明的附图用来提供对本申请的进一步理解,构成本申请的一部分,本申请的示意性实施例及其说明用于解释本申请,并不构成对本地申请的不当限定。在附图中:
图1示出了本申请实施例提供的一种基于人口分布的环境风险评估方法的流程示意图;
图2示出了本申请实施例提供的另一种基于人口分布的环境风险评估方法的流程示意图;
图3示出了本申请实施例提供的一种基于人口分布的环境风险评估装置的结构示意图;
图4示出了本申请实施例提供的另一种基于人口分布的环境风险评估装置的结构示意图。
具体实施方式
下文将参考附图并结合实施例来详细说明本申请。需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互结合。
针对目前环境风险评估不准确、不合理的技术问题,本申请提供了一种基于人口分布的环境风险评估方法,如图1所示,该方法包括:
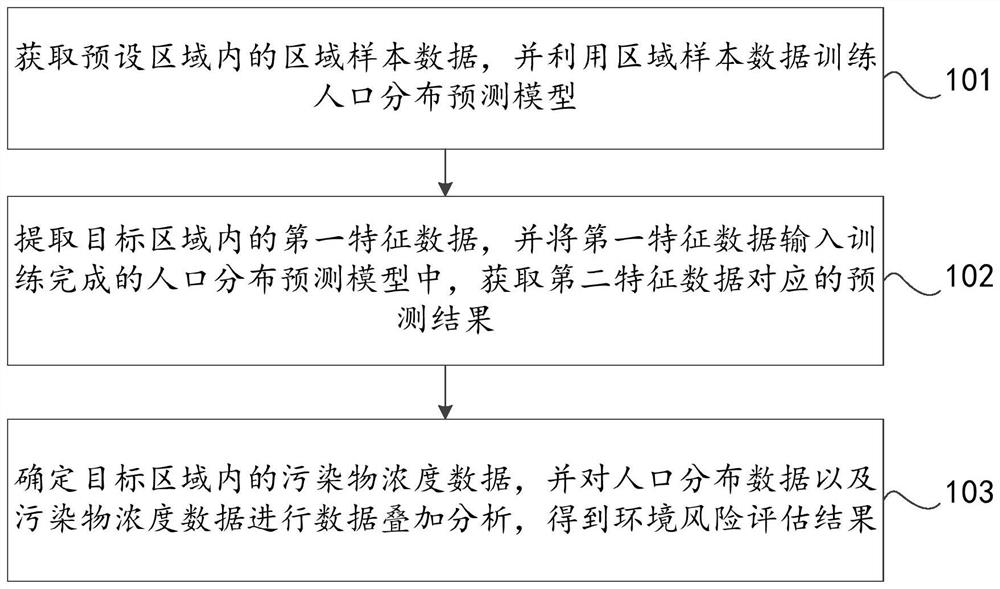
101、获取预设区域内的区域样本数据,并利用区域样本数据训练人口分布预测模型。
其中,预设区域为已确定精准人口分布数据的地理区域,区域样本数据为携带有模型输入特征(夜间灯光数据,归一化植被指数,数据高程模型数据,坡度、兴趣点、保险数据),以及模型输出特征(人口分布数据)的区域特征信息。在本申请中,可利用区域样本数据训练人口分布预测模型,以使人口分布预测模型能够根据模型输入特征精准输出与模型输出特征匹配的特征数据。具体可采用随机森林构建人口精细化分布模型,通过在模型中引入夜间灯光数据,归一化植被指数,数据高程模型数据,坡度、兴趣点及保险数据为自变量,以区县普查人口数据为因变量,利用机器学习与GIS相结合的方法,精确评估每个自变量对模型的贡献,最终输出最佳人口空间分布结果,实现高精度高分辨率的人口分布数据的预测。
其中,随机森林模型指的是利用多棵树对样本进行训练并预测的一种分类器,该分类器可以输入大量变量,快速学习后输出高准确度的分类或回归结果,同时评估变量的重要性,不会产生过拟合的问题。随机森林以其上述优点非常适合用于人口数据的空间化,可快速学习变量因子与人口数据之间的关系并给出变量因子的重要性评价。相对于传统的回归模拟的方法,人口随机森林模型可避免过度拟合,且可识别容忍异常值及噪声,同时可以在不显著提高运算量的情况下显著提高预测精度,使得高精度高分辨的栅格人口空间分布研究成为可能。
102、提取目标区域内的第一特征数据,并将第一特征数据输入训练完成的人口分布预测模型中,获取第二特征数据对应的预测结果。
其中,该目标区域可以为用户预设的区域、预设的城市或预设的国家等,例如,该目标区域可以为北京、上海、深圳或广东等城市;第一特征数据至少包括夜间灯光数据,归一化植被指数,数据高程模型数据,坡度、兴趣点及保险数据,第二特征数据包括人口分布数据。
具体的,夜间灯光数据(Nighttime Lights,NTL)为灯光指数,可使用基于新一代的夜间灯光数据的NTL产品进行获取,该数据具有较高的空间分辨率及辐射范围,能够识别微弱灯光源,可用于大气、陆表过程和人类活动等方面的研究;归一化植被指数表示植被的覆盖程度,为通过波段运算归一化处理成的0~1之内的数值,数值越接近于1,表示植被覆盖率越高,归一化植被指数具体可来源于联合国环境规划署;数字高程模型数据可通过地理国情监测云平台获取;坡度数据为高于海平面的数值,为空间上的数据,可由数字高程模型数据计算得出;兴趣点数据为建筑物标识信息,如医院、商场、学校、超市等,可通过应用编程接口获取;保险数据为通过hive数据库选取出的对应年份带经纬度的出险保单数据。
103、确定目标区域内的污染物浓度数据,并对人口分布数据以及污染物浓度数据进行数据叠加分析,得到环境风险评估结果。
在具体的应用场景中,污染物可包括一氧化碳(CO)、氮氧化物(NOx)、碳氢化合物(H空气污染物C)、硫氧化物和颗粒物(PM)等,在本实施例中,所研究的污染物具体可为PM
通过本实施例中基于人口分布的环境风险评估方法,可首先利用区域样本数据训练人口分布预测模型,进而利用人口分布预测模型基于目标区域内各个维度的第一特征数据,精细化确定出第二特征数据对应的预测结果,即人口分布数据;进而将目标区域内的污染物浓度数据与人口分布数据进行数据叠加分析,进一步得到环境风险评估结果。通过本申请中的方式,可将空气污染物分布数据和人口分布数据相结合进行人口污染暴露风险的空间化评估。相比于以往直接使用污染物浓度来评估实际暴露水平的方式,在本申请中,考虑了人口因素在空气污染暴露风险评价中的主体作用,通过进行人口分布数据以及污染物浓度数据的数据叠加分析,可提升空气污染暴露风险评价的合理性以及准确性。
进一步的,作为上述实施例具体实施方式的细化和扩展,为了完整说明本实施例中的具体实施过程,提供了另一种基于人口分布的环境风险评估方法,如图2所示,该方法包括:
201、获取预设区域内的区域样本数据,并利用区域样本数据训练人口分布预测模型。
对于本实施例,实施例步骤201具体可以包括:将预设区域划分为栅格属性一致的多个第一栅格单元;提取各个第一栅格单元内的第一特征数据以及第二特征数据;将第一特征数据确定为人口分布预测模型的输入特征,将第二特征数据确定为人口分布预测模型的输出特征,训练人口分布预测模型;基于交叉验证算法对人口分布预测模型进行训练评估,获取评估结果;若根据评估结果计算的训练误差小于预设阈值,则判定人口分布预测模型训练完成。其中,第一特征数据至少包括夜间灯光数据,归一化植被指数,数据高程模型数据,坡度、兴趣点及保险数据,第二特征数据至少包括人口分布数据。
具体的,为了结果最优及分辨率最大化,本申请将第一栅格单元大小定为500m×500m。栅格属性具体可包括分辨率、栅格行列号、坐标系统等,具体可通过利用地理信息系统平台对第一栅格单元中的栅格数据进行投影、掩膜、重采样等步骤预处理至统一栅格属性。其中,地理信息系统平台具体具体可为ARCGIS系统平台,ARCGIS作为世界领先的地理信息系统构建和应用平台,是一个全面的系统,用户可用其来收集、组织、管理、分析、交流和发布地理信息。
相应的,在将夜间灯光数据,归一化植被指数,数据高程模型数据,坡度、兴趣点、保险数据确定为人口分布预测模型的输入特征,将人口分布数据确定为人口分布预测模型的输出特征,训练人口分布预测模型时,可利用R语言实现,利用随机森林算法,构建人口随机森林精细化分布模型,综合考虑运算性能和模型精度,设定ntree=500,mtry=2,通过模型训练,得到预测结果。进而可对预测结果进行分区权重分布调整,获得该研究区域对应年份的500m×500m格点的人口空间分布。具体的,可将相同的栅格层定位到拟合的射频模型中,计算每个500m×500m网格区域的分布权重,将研究区的人口根据这些权重进行空间化分解,利用分区人口密度制图将人口最终分配在网格中,计算公式如下:
式中,w
最后可通过人口随机森林模型变量解释度(The percentage of variablesexplained,缩写为%Var explained)和均方误差增量(The percentage of increment ofmean square error,缩写为%IncMSE)等数据判断模型精度以及各自变量的贡献,利用随机森林机器学习方法建立确证模型,并采用10折交叉验证对人口分布预测模型进行评估,其主要思想是将数据随机分为10个子样本,每次取一个样本作为验证数据,取余下的9个样本作为训练数据,模型构建后作用于验证数据上,计算出当前错误率,如此往复。通过对估算结果与统计结果进行线性回归以及误差分析,获得回归方程R2以及误差范围。采用决定系数(R2)及相对误差(RMSE)作为评价指标,R2表示预测人口与普查人口之间的拟合精度,相对误差可反映预测的可信程度,公式如下:
式中,R2为决定系数,RMSE为相对误差,n为统计的总格点数,pop
在具体的应用场景中,若基于交叉验证结果显示R2和RMSE值均大于各自的预设阈值,则可判定人口精细化分布模型通过训练,并进一步确定夜间灯光数据、数字高程模型数据、归一化植被指数、坡度、兴趣点、保险数据6个自变量数据各自对应的目标权重值,6个自变量数据对应的目标权重值加和为1,目标权重值的大小用于用于反映该变量因子对人口密度的预测影响程度。
202、提取目标区域内的第一特征数据,并将第一特征数据输入训练完成的人口分布预测模型中,获取第二特征数据对应的预测结果。
对于本实施例,在获取到目标区域后,首先也需要对目标区域进行栅格化分,具体可将目标区域划分为栅格属性一致的多个第二栅格单元,第二栅格单元与第一栅格单元处理方式相同,第二栅格单元大小同样也定为500m×500m,栅格属性具体可包括分辨率、栅格行列号、坐标系统等,具体可通过利用地理信息系统平台对第二栅格单元中的栅格数据进行投影、掩膜、重采样等步骤预处理至统一栅格属性。进而可实时获取各个第二栅格单元内的夜间灯光数据、数字高程模型数据、归一化植被指数、坡度、兴趣点、保险数据,并将上述6个自变量数据输入训练完成的人口分布预测模型中,利用人口分布预测模型输出该第二栅格单元内的人口分布数据,进而通过分区密度制图对预测结果进行修正,得到网格化的人口分布结果。
其中,分区密度制图法是按照随机森林得到的每个网格的人口占一个行政区的所有网格的总人口的比例重新分配每个网格的人口数,计算公式如下:
式中,P
在具体的应用场景中,在提取目标区域内的第一特征数据时,实施例步骤202具体可以包括:按照预设栅格划分规则,将目标区域划分为栅格属性一致的多个第二栅格单元;提取各个第二栅格单元内的第一特征数据,第一特征数据至少包括夜间灯光数据,归一化植被指数,数据高程模型数据,坡度、兴趣点及保险数据。相应的,在将第一特征数据输入训练完成的人口分布预测模型中,获取第二特征数据对应的预测结果时,实施例步骤202具体可以包括:在训练完成的人口分布预测模型中提取各个第一特征数据对应的目标权重值;将第一特征数据输入训练完成的人口分布预测模型中,基于目标权重值计算得到第二特征数据对应的预测结果;通过分区密度制图对预测结果进行修正,得到人口分布数据。
203、利用地理信息系统平台从全球浓度数据中掩膜提取各个第二栅格单元内的污染物浓度数据。
对于本实施例,可利用地理信息系统平台从全球浓度数据中掩膜提取各个第二栅格单元内的PM
204、基于第一计算公式以及人口分布数据、污染物浓度数据计算各个第二栅格单元内的人口暴露强度。
其中,第一计算公式的特征描述为:
E
式中,E
对于本实施例,在确定出各个第二栅格单元内的人口暴露强度后,还可进一步基于各个栅格内的PM
205、基于第二计算公式以及人口分布数据、污染物浓度数据、目标区域内的总人口数计算目标区域内的人口加权暴露强度。
对于本实施例,还可通过采用基于人口加权的PM
式中,E为目标区域(地区/省/城市)的人口加权暴露强度,C
206、根据人口分布数据以及污染物浓度数据生成人口污染暴露风险分区图。
其中,人口污染暴露风险分区图中存储有目标区域中各个第二栅格单元对应的空气污染暴露风险指标。
对于本实施例,通过将人口分布数据和污染物分布数据进行数据叠加分析,能有效的考虑人口因素在空气污染暴露风险评价中的主体作用,弥补现有污染物浓度指标忽视人口分布的缺陷,进一步提升空气污染暴露风险评价的合理性。
相应的,在具体的应用场景中,实施例步骤206具体可以包括:对人口分布数据以及污染物浓度数据进行无量纲归一化处理,得到无量纲数据;根据无量纲数据对目标区域进行人口密度第一分级和污染度浓度第一分级,得到人口密度等级表和污染度等级表;根据人口密度等级表和污染度等级表对无量纲数据进行人口密度第二分级和污染度浓度第二分级,得到人口密度分级图和污染物浓度分级图;将人口密度分级图和污染物浓度分级图转换为栅格数据,并将栅格数据中的污染物浓度参数叠加至人口密度参数中,以生成人口污染暴露风险分区图。
其中,该污染度等级表中PM
优选的,在将上述人口暴露风险数据映射至高风险、次高风险、中风险、次低风险、低风险等五类,以得到该空气污染暴露风险分区图时,该空气污染暴露风险分区图中存储有目标区域中各个区域对应的污染暴露风险指标,从而能直观反映各空间单元的空气污染暴露风险。
相应的,在对人口分布数据以及污染物浓度数据进行无量纲归一化处理,得到无量纲数据时,实施例步骤206具体可以包括:计算目标区域中各个第二栅格单元的平均污染物浓度和平均人口密度;将人口空间分布数据除以平均人口密度,将污染物分布数据除以平均污染物浓度,得到无量纲数据。通过对人口数据与污染物浓度数据进行无量纲归一化处理,以及进行风险分级,可避免暴露风险出现“高低两级”的非正常集聚现象,可直观展现评价目标区域的污染暴露风险,识别关键风险区域。
借由上述基于人口分布的环境风险评估方法,可首先利用区域样本数据训练人口分布预测模型,进而利用人口分布预测模型基于目标区域内各个维度的第一特征数据,精细化确定出第二特征数据对应的预测结果,即人口分布数据;进而将目标区域内的污染物浓度数据与人口分布数据进行数据叠加分析,进一步得到环境风险评估结果。通过本申请中的方式,可将空气污染物分布数据和人口分布数据相结合进行人口污染暴露风险的空间化评估。相比于以往直接使用污染物浓度来评估实际暴露水平的方式,在本申请中,考虑了人口因素在空气污染暴露风险评价中的主体作用,通过进行人口分布数据以及污染物浓度数据的数据叠加分析,可提升空气污染暴露风险评价的合理性以及准确性。
进一步的,作为图1和图2所示方法的具体实现,本申请实施例提供了一种基于人口分布的环境风险评估装置,如图3所示,该装置包括:训练模块31、获取模块32、分析模块33;
训练模块31,可用于获取预设区域内的区域样本数据,并利用区域样本数据训练人口分布预测模型;
获取模块32,可用于提取目标区域内的第一特征数据,并将第一特征数据输入训练完成的人口分布预测模型中,获取第二特征数据对应的预测结果,第一特征数据至少包括夜间灯光数据,归一化植被指数,数据高程模型数据,坡度、兴趣点及保险数据,第二特征数据包括人口分布数据;
分析模块33,可用于确定目标区域内的污染物浓度数据,并对人口分布数据以及污染物浓度数据进行数据叠加分析,得到环境风险评估结果。
在具体的应用场景中,为了基于预设区域内的区域样本数据训练得到人口分布预测模型,如图4所示,训练模块31,具体可包括:第一划分单元311、第一提取单元312、训练单元313、评估单元314、判断单元315;
第一划分单元311,可用于将预设区域划分为栅格属性一致的多个第一栅格单元;
第一提取单元312,可用于提取各个第一栅格单元内的第一特征数据以及第二特征数据;
训练单元313,可用于将第一特征数据确定为人口分布预测模型的输入特征,将第二特征数据确定为人口分布预测模型的输出特征,训练人口分布预测模型;
评估单元314,可用于基于交叉验证算法对人口分布预测模型进行训练评估,获取评估结果;
判断单元315,可用于若根据评估结果计算的训练误差小于预设阈值,则判定人口分布预测模型训练完成。
在具体的应用场景中,为了提取得到目标区域内的第一特征数据,如图4所示,获取模块32,具体可包括:第二划分单元321、第二提取单元322;
第二划分单元321,可用于按照预设栅格划分规则,将目标区域划分为栅格属性一致的多个第二栅格单元;
第二提取单元322,可用于提取各个第二栅格单元内的第一特征数据,第一特征数据至少包括夜间灯光数据,归一化植被指数,数据高程模型数据,坡度、兴趣点及保险数据。
相应的,为了通过将第一特征数据输入训练完成的人口分布预测模型中,获取得到第二特征数据对应的预测结果,如图4所示,获取模块32,具体可包括:第三提取单元323、输入单元324、修正单元325;
第三提取单元323,可用于在训练完成的人口分布预测模型中提取各个第一特征数据对应的目标权重值;
输入单元324,可用于将第一特征数据输入训练完成的人口分布预测模型中,基于目标权重值计算得到第二特征数据对应的预测结果;
修正单元325,可用于通过分区密度制图对预测结果进行修正,得到人口分布数据。
在具体的应用场景中,在通过对人口分布数据以及污染物浓度数据进行数据叠加分析,得到环境风险评估结果时,如图4所示,分析模块33,具体可包括:第四提取单元331、第一计算单元332、第二计算单元333、生成单元334;
第四提取单元331,可用于利用地理信息系统平台从全球浓度数据中掩膜提取各个第二栅格单元内的污染物浓度数据;
第一计算单元332,可用于基于第一计算公式以及人口分布数据、污染物浓度数据计算各个第二栅格单元内的人口暴露强度;
第二计算单元333,可用于基于第二计算公式以及人口分布数据、污染物浓度数据、目标区域内的总人口数计算目标区域内的人口加权暴露强度;
生成单元334,可用于根据人口分布数据以及污染物浓度数据生成人口污染暴露风险分区图。
相应的,在根据人口分布数据以及污染物浓度数据生成人口污染暴露风险分区图时,生成单元334,具体可用于对人口分布数据以及污染物浓度数据进行无量纲归一化处理,得到无量纲数据;根据无量纲数据对目标区域进行人口密度第一分级和污染度浓度第一分级,得到人口密度等级表和污染度等级表;根据人口密度等级表和污染度等级表对无量纲数据进行人口密度第二分级和污染度浓度第二分级,得到人口密度分级图和污染物浓度分级图;将人口密度分级图和污染物浓度分级图转换为栅格数据,并将栅格数据中的污染物浓度参数叠加至人口密度参数中,以生成人口污染暴露风险分区图。
在具体的应用场景中,在对人口分布数据以及污染物浓度数据进行无量纲归一化处理,得到无量纲数据时,生成单元334,具体可用于计算目标区域中各个第二栅格单元的平均污染物浓度和平均人口密度;将人口空间分布数据除以平均人口密度,将污染物分布数据除以平均污染物浓度,得到无量纲数据。
需要说明的是,本实施例提供的一种基于人口分布的环境风险评估装置所涉及各功能单元的其他相应描述,可以参考图1至图2的对应描述,在此不再赘述。
基于上述如图1至图2所示方法,相应的,本实施例还提供了一种存储介质,其上存储有计算机可读指令,该可读指令被处理器执行时实现上述如图1至图2所示的基于人口分布的环境风险评估方法。
基于这样的理解,本申请的技术方案可以以软件产品的形式体现出来,该软件产品可以存储在一个存储介质(可以是CD-ROM,U盘,移动硬盘等)中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本申请中的各个实施场景,以实现上述如图1至图2所示的基于人口分布的环境风险评估方法。
基于上述如图1至图2所示的方法和图3、图4所示的虚拟装置实施例,为了实现上述目的,本实施例还提供了一种计算机设备,该计算机设备包括存储介质和处理器;存储介质,用于存储计算机程序;处理器,用于执行计算机程序以实现上述如图1至图2所示的基于人口分布的环境风险评估方法。
可选的,该计算机设备还可以包括用户接口、网络接口、摄像头、射频(RadioFrequency,RF)电路,传感器、音频电路、WI-FI模块等等。用户接口可以包括显示屏(Display)、输入单元比如键盘(Keyboard)等,可选用户接口还可以包括USB接口、读卡器接口等。网络接口可选的可以包括标准的有线接口、无线接口(如WI-FI接口)等。
本领域技术人员可以理解,本实施例提供的一种计算机设备结构并不构成对该实体设备的限定,可以包括更多或更少的部件,或者组合某些部件,或者不同的部件布置。
存储介质中还可以包括操作系统、网络通信模块。操作系统是管理上述计算机设备硬件和软件资源的程序,支持信息处理程序以及其它软件和/或程序的运行。网络通信模块用于实现存储介质内部各组件之间的通信,以及与信息处理实体设备中其它硬件和软件之间通信。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到本申请可以借助软件加必要的通用硬件平台的方式来实现,也可以通过硬件实现。
通过应用本申请的技术方案,与目前基于人口分布的环境风险评估的方式相比,本申请可首先利用区域样本数据训练人口分布预测模型,进而利用人口分布预测模型基于目标区域内各个维度的第一特征数据,精细化确定出第二特征数据对应的预测结果,即人口分布数据;进而将目标区域内的污染物浓度数据与人口分布数据进行数据叠加分析,进一步得到环境风险评估结果。通过本申请中的方式,可将空气污染物分布数据和人口分布数据相结合进行人口污染暴露风险的空间化评估。相比于以往直接使用污染物浓度来评估实际暴露水平的方式,在本申请中,考虑了人口因素在空气污染暴露风险评价中的主体作用,通过进行人口分布数据以及污染物浓度数据的数据叠加分析,可提升空气污染暴露风险评价的合理性以及准确性。
本领域技术人员可以理解附图只是一个优选实施场景的示意图,附图中的模块或流程并不一定是实施本申请所必须的。本领域技术人员可以理解实施场景中的装置中的模块可以按照实施场景描述进行分布于实施场景的装置中,也可以进行相应变化位于不同于本实施场景的一个或多个装置中。上述实施场景的模块可以合并为一个模块,也可以进一步拆分成多个子模块。
上述本申请序号仅仅为了描述,不代表实施场景的优劣。以上公开的仅为本申请的几个具体实施场景,但是,本申请并非局限于此,任何本领域的技术人员能思之的变化都应落入本申请的保护范围。
- 基于人口分布的环境风险评估方法、装置及计算机设备
- 基于状态的任务成功率快速评估方法、装置及计算机设备