通过张量网络框架实现变分量子本征求解器算法
文献发布时间:2023-06-19 13:26:15
技术领域
本发明大体上涉及量子计算领域,尤其涉及用于执行混合量子经典计算以实现变分量子本征求解器(Variational Quantum Eigensolver,VQE)算法的技术。
背景技术
利用量子力学现象运行并加速的可编程设备已经有多种类型,通常可以称为量子增强计算器和量子模拟器。这些设备可以用于计算和信息处理任务,其中求解某一系统的哈密顿量(Hamiltonian)的本征值的任务特别令人感兴趣。
VQE算法正是为了求解这些任务而开发的。它是一种混合量子经典算法,可以通过在经典计算设备和量子计算设备之间分配计算操作来优化感兴趣的标量函数(scalarfunction),也称为目标函数(objective function)。具体地,量子计算设备用于准备参数化量子态(也称为拟设状态),并根据目标函数测量参数化量子态,而经典计算设备负责更新拟设状态的参数,以最小化拟设状态的能量期望,从而找到基态能量或期望激发态能量或拟设状态能量。
上述最小化能量期望可以通过一阶和二阶优化技术实现,这两种技术分别以使用目标函数的一阶和二阶偏导数为基础。更具体地,一阶优化技术使用梯度信息来构建经典优化回路中的下一次迭代,而二阶优化技术使用海森(Hessian)矩阵根据优化轨迹计算经典优化回路中的下一次迭代。
然而,拟设状态的结构有时无法准确计算目标函数的一阶偏导数。在这种情况下,一阶偏导数通过有限差分近似。虽然最小化的准确性可以通过二阶优化技术(即目标函数的二阶偏导数)提高,但计算成本比较高。最重要的是,一阶和二阶优化技术在计算目标函数的每个偏导数时都需要改变拟设状态的结构。
发明内容
本发明内容简单介绍了一系列概念,在具体实施方式中会进一步描述这些概念。本发明内容的目的不在于识别本发明的关键特征或必要特征,也不在于限制本发明的范围。
本发明的一个目的是提供一种技术方案,能够准确计算目标函数的任意阶偏导数而不必改变拟设状态结构。本发明的另一个目的是通过使用这些准确计算到的目标函数的偏导数提高VQE算法的效率。
上述目的通过所附权利要求书中的独立权利要求的特征实现。其它实施例和示例在从属权利要求、具体实施方式和附图中是显而易见的。
根据第一方面,提供了一种量子计算设备。所述量子计算设备包括至少一个量子处理单元(quantum processing unit,QPU)和耦合到所述至少一个QPU的存储器。所述存储器用于存储可执行指令,当由所述至少一个QPU执行时,所述可执行指令使得所述至少一个QPU执行以下步骤:
(i)将至少一个量子比特初始化到初始状态;
(ii)接收指示哈密顿量的用户输入;
(iii)通过将酉算子应用于所述至少一个量子比特,为所述初始状态定义拟设状态,
其中,所述酉算子包括至少一个变分参数并由张量网络表示;
(iv)根据所述拟设状态和所述哈密顿量估算目标函数;
(v)通过将所述酉算子中的所述至少一个变分参数位移一个阈值,估算所述目标函数的感兴趣阶的至少一个偏导数;
(vi)将所述估算出的目标函数和所述估算出的所述目标函数的感兴趣阶的至少一个偏导数提供给经典计算设备。
通过使用所述酉算子的张量网络表示,可以构建所述拟设状态,所述拟设状态可以准确计算所述目标函数的任意阶偏导数,即不必对这些偏导数使用任何近似值。此外,这些偏导数是由所述量子计算设备本身计算的,无需改变所述拟设状态的结构,即只需要将所述酉算子中的一个或多个对应变分参数位移某个阈值。
在所述第一方面的一个实施例中,所述至少一个QPU还用于:从所述计算设备接收所述酉算子中的所述至少一个变分参数的一份更新;根据所述更新改变所述酉算子中的所述至少一个变分参数;重复操作(iii)至(vi)。本实施例可以使所述量子计算设备在VQE算法中的使用效率更高,目的是求解所述拟设状态的最小能量期望。
在所述第一方面的一个实施例中,所述张量网络被实现为树形张量网络或棋盘张量网络。本实施例可以使所述量子计算设备在使用上更加灵活。
在所述第一方面的一个实施例中,所述哈密顿量是根据泡利算子的乘积定义的。所述哈密顿量的泡利算子分解可以简化操作(iii)至(v)的执行。
在所述第一方面的一个实施例中,所述至少一个量子比特包括多个量子比特,所述酉算子包括分别应用于所述多个量子比特中的对应两个量子比特的子酉算子的乘积。在本实施例中,所述张量网络可以包括一组互连构建块,每个构建块表示所述子酉算子中的一个。通过这样做,可以简化操作(v)的执行。
在所述第一方面的一个实施例中,所述至少一个QPU还用于通过使用哈达玛测试执行操作(v)。本实施例可以进一步简化操作(v)的执行。
在所述第一方面的一个实施例中,所述至少一个QPU还用于:估算操作(v)中的所述目标函数的二阶偏导数;将所述二阶偏导数作为海森矩阵提供给操作(vi)中的所述计算设备。本实施例可以使得二阶优化技术用于所述目标函数上。
在所述第一方面的一个实施例中,所述酉算子包括一组指数,每个指数包括所述至少一个变分参数中的一个,所述阈值等于π/2。通过这样做,可以进一步简化操作(v)的执行。
根据第二方面,提供了一种经典计算设备。所述经典计算设备包括至少一个处理单元和耦合到所述至少一个处理单元的存储器。所述存储器用于存储可执行指令,当由所述至少处理单元执行时,所述可执行指令使得所述至少一个处理单元执行以下步骤:
(vii)从根据所述第一方面的量子计算设备接收所述估算出的目标函数和所述估算出的所述目标函数的感兴趣阶的至少一个偏导数;
(viii)根据所述估算出的目标函数和所述估算出的所述目标函数的感兴趣阶的至少一个偏导数,准备所述酉算子中的所述至少一个变分参数的一份更新;
(ix)将所述酉算子中的所述至少一个变分参数的所述更新提供给根据所述第一方面的量子计算设备,从而使得所述量子计算设备重复操作(iii)至(vi);
(x)重复操作(vii)至(ix),直到满足预定义的结束条件;
(xi)当满足所述预定义的结束条件时,将所述酉算子中的所述至少一个变分参数的一份最后更新以及所述拟设状态和所述哈密顿量的本征值一起提供给用户,其中,所述拟设状态和所述哈密顿量的所述本征值对应于所述酉算子中的所述至少一个变分参数的所述最后更新。
通过使用所述目标函数和所述目标函数的感兴趣阶的一个或多个偏导数,这两者都是根据所述酉算子的张量网络表示确定的,可以提高最小化所述目标函数的效率,即最小化所述VQE算法中的所述拟设状态的能量期望。
在所述第二方面的一个实施例中,所述至少一个处理单元还用于通过使用监督式或非监督式机器学习技术执行操作(vii)至(x)。本实施例可以提高执行操作(vii)至(x)的效率。
在所述第二方面的一个实施例中,所述预定义的结束条件包括以下至少一种条件:提供了所述估算出的目标函数的最小值,预定义的计时器超时,提供了预定义的重复计数。本实施例可以通过合理权衡计算成本和所述目标函数的期望最小值,使根据所述第二方面的计算设备在使用中更加灵活。
在所述第二方面的一个实施例中,所述至少一个处理单元还用于通过使用梯度下降法、牛顿迭代法(Newton's method)或置信域方法(trust-region method)执行操作(vii)至(x)。本实施例可以通过使根据所述第二方面的计算设备可以根据特定应用选择哪一种所述方法,使所述计算设备在使用中更加灵活。
在所述第二方面的一个实施例中,响应于所述至少一个处理单元接收所述估算出的感兴趣阶的至少一个偏导数作为所述海森矩阵,所述至少一个处理单元还用于通过使用基于海森的精确置信域方法执行操作(vii)至(x)。本实施例可以使得二阶优化技术用于所述VQE算法中的所述目标函数上。
根据第三方面,提供了一种计算装置。所述计算装置包括根据所述第一方面的量子计算设备和根据所述第二方面的经典计算设备。这可以使得操作(iii)至(v)表示的量子计算和由操作(vii)至(ix)表示的经典(非量子)计算在单芯片上执行。在操作过程中,这个单芯片可以被冷却到适用于至少部分地在根据所述第二方面的经典计算设备的组件内实现(量子计算通常需要的)超导性的温度,从而减少其中的散热量。此外,根据制造材料,根据所述第二方面的经典计算设备的组件在这种低温下(相比于室温)可以消耗更少的功率且产生更少的废热。
根据第四方面,提供了一种用户界面。所述用户界面包括输入单元和显示单元。所述输入单元通信地耦合到根据所述第一方面的量子计算设备,并且用于接收用户输入并将其提供给所述至少一个QPU。所述显示单元通信地耦合到根据所述第二方面的经典计算设备,并且用于将所述酉算子中的所述至少一个变分参数的所述最后更新以及所述拟设状态和所述哈密顿量的所述本征值一起接收并显示。借助于这种用户界面,即使用户没有量子计算经验,也可以通过简单地输入所述哈密顿量的期望形式轻松获得上述结果。因此,所述用户界面甚至可以由公众用户使用。
根据第四方面,提供了一种计算方法。所述计算方法包括以下由至少一个量子处理单元(quantum processing unit,QPU)待执行的步骤:
(i)将至少一个量子比特初始化到初始状态;
(ii)接收指示哈密顿量的用户输入;
(iii)通过将酉算子应用于所述至少一个量子比特,为所述初始状态定义拟设状态,其中,所述酉算子包括至少一个变分参数并由张量网络表示;
(iv)根据所述拟设状态和所述哈密顿量估算目标函数;
(v)通过将所述酉算子中的所述至少一个变分参数位移一个阈值,估算所述目标函数的感兴趣阶的至少一个偏导数;
(vi)将所述估算出的目标函数和所述估算出的所述目标函数的感兴趣阶的至少一个偏导数提供给计算设备。
通过使用所述酉算子的张量网络表示,可以构建所述拟设状态,所述拟设状态可以准确计算所述目标函数的任意阶偏导数,即不必对这些偏导数使用任何近似值。此外,这些偏导数是由所述量子计算设备本身计算的,无需改变所述拟设状态的结构,即只需要将所述酉算子中的一个或多个对应变分参数位移某个阈值。
在所述第五方面的一个实施例中,所述方法还可以包括以下由至少一个处理单元待执行的步骤(如果需要经典优化回路):
(vii)从所述至少一个QPU接收所述估算出的目标函数和所述估算出的所述目标函数的感兴趣阶的至少一个偏导数;
(viii)根据所述估算出的目标函数和所述估算出的所述目标函数的感兴趣阶的至少一个偏导数,准备所述酉算子中的所述至少一个变分参数的一份更新;
(ix)将所述更新提供给所述至少一个QPU,从而使得所述至少一个QPU重复操作(iii)至(vi);
(x)重复操作(vii)至(ix),直到满足预定义的结束条件;
(xi)当满足所述预定义的结束条件时,将所述酉算子中的所述至少一个变分参数的一份最后更新以及所述拟设状态和所述哈密顿量的本征值一起提供给用户,其中,所述拟设状态和所述哈密顿量的所述本征值对应于所述酉算子中的所述至少一个变分参数的所述最后更新。
通过使用所述目标函数和所述目标函数的感兴趣阶的一个或多个偏导数,这两者都是根据所述酉算子的张量网络表示确定的,可以提高最小化所述目标函数的效率,即最小化所述VQE算法中的所述拟设状态的能量期望。
根据第六方面,提供了一种计算机可读存储介质。所述计算机可读存储介质存储计算机代码,当由至少一个量子处理单元(quantum processing unit,QPU)或至少一个处理器执行时,所述计算机代码使得所述至少一个QPU或所述至少一个处理器执行根据所述第五方面的方法。这可以简化根据所述第五方面的方法在任何混合量子经典计算设备(例如,根据所述第三方面的计算装置)中的实现。
在阅读以下具体实施方式并查看附图后,本发明的其它特征和优点将是显而易见的。
附图说明
下面结合附图说明本发明的本质。
图1示出了用于估算目标函数的每个项的典型量子电路;
图2示出了用于实现哈达玛测试的典型量子电路。
图3A和图3B示出了两个不同的可能张量网络:树形张量网络(图3A)和棋盘(checkerboard)张量网络(图3B),其中,每个张量网络都应用于量子比特的初始状态。
图4为一个示例性实施例提供的量子计算设备的方框图。
图5为一个示例性实施例提供的用于操作图4所示的量子计算设备的方法的流程图。
图6为在总共有4个量子比特(处于初始状态)的情况下如何根据张量网络框架分解酉算子的说明图。
图7为如何可以根据张量网络框架进一步分解酉算子的每个双量子比特子算子的说明图。
图8为如何可以根据张量网络框架进一步分解酉算子的每个双量比特子算子的另一说明图。
图9为一个示例性实施例提供的经典计算设备的方框图。
图10为一个示例性实施例提供的用于操作图9所示的计算设备的方法的流程图。
图11为一个示例性实施例提供的混合量子经典计算装置的方框图。
图12为一个示例性实施例提供的用于操作图11所示的装置的方法的流程图。
图13为一个示例性实施例提供的用户界面的方框图。
图14示出了通过使用拟设状态的三层棋盘张量网络获取4量子比特伊辛哈密顿量的VQE算法的模拟结果。
具体实施方式
参考附图进一步详细描述了本发明的各种实施例。但是,本发明可能以许多其它形式体现,而且不应解释为限于在以下描述中论述的任何特定结构或功能。相反,提供这些实施例是为了详细且完整地描述本发明。
根据具体实施方式,对本领域技术人员显而易见的是,本发明的范围包括本文公开的任何实施例,无论该实施例是独立实现的还是与本发明的任何其它实施例共同实现的。例如,本文公开的设备和方法可以通过使用本文提供的任意数量的实施例来实现。此外,应当理解,本发明的任何实施例都可以使用所附权利要求书中提出的一个或多个元件来实现。
本文中使用的“示例性”一词的含义是“用作说明”。除非另有说明,否则本文描述为“示例性”的任何实施例不应解释为优选的或具有优于其它实施例的优点。
根据本文公开的实施例,量子计算设备,也称为量子计算机,可以涉及直接使用叠加(superposition)和纠缠(entanglement)等量子力学现象来求解所需计算任务的任何计算设备。这样的量子计算设备的现有实现示例包括陷俘(trapped)离子量子计算机、基于可扩展半导体的量子计算机、基于量子点(quantum dot-based)的量子计算机、谐振子(harmonic oscillator)量子计算机、基于腔量子电动力学(quantum electrodynamics,QED)的量子计算机、光量子计算机、基于杂聚物(heteropolymer-based)的量子计算机、簇态(cluster-state)量子计算机、带有任意子(anyon)的量子计算机、基于半导体自旋的量子计算机等。
本文公开的实施例中使用的量子处理单元(quantum processing unit,QPU),也称为量子处理器或量子芯片,可以涉及包括多个以某种方式互连的量子比特的物理(预制)芯片。在这个意义上,QPU充当量子信息存储设备。QPU是量子计算设备的基本组件,还包括QPU、控制电子设备和许多其它组件的外壳。对于本领域技术人员来说显而易见的是,QPU可以适当地用于量子计算设备的上述或其它实现示例中的任一个中。
根据本文公开的实施例,量子比特可以指量子计算设备的基本信息单元。量子比特包含在QPU中,并推广了经典数字比特的概念。更具体地,经典信息存储设备可以对通常标记为“0”和“1”的两个不连续态进行编码。这两个不连续(比特)态物理上表示为经典信息存储设备的两个不同可区分物理状态,例如,磁场、电流或电压的方向或幅度,其中,对每个比特状态进行编码的物理量遵循经典物理学定律。类似地,每个量子比特还包括两个不连续的物理状态,它们也可以标记为“0”和“1”。但是,这两个不连续(量子比特)态物理上表示为量子信息存储设备(例如,上述QPU)的两个不同可区分物理状态,例如,磁场、电流或电压的方向或幅度,其中,对每个量子比特状态进行编码的物理量遵循量子物理学定律。如果存储这些状态的物理量遵循量子力学,则QPU还可以处于“0”和“1”的叠加之中。换句话说,量子比特可以同时存在于“0”和“1”状态之中,因此可以用于同时在这两种状态下执行计算。一般而言,N个量子比特可以处于2N个状态的叠加之中。量子算法利用这种叠加特性来加快一些计算。
在量子算法之中,变分量子本征求解器(Variational Quantum Eigensolver,VQE)算法是目前特别令人感兴趣的算法。该算法表示一种混合量子经典算法,可以用于求解(通常是大的)矩阵H的本征值。当VQE算法用于(物理、化学、材料科学、物流、药物开发等的)量子模拟中时,矩阵H是某一系统的哈密顿量(Hamiltonian)。在VQE算法中,量子子程序在经典优化回路内部运行。VQE算法的量子子程序相当于根据变分参数集准备一种状态,并使用该状态对目标函数及其某阶的一个或多个偏导数执行一系列所需测量。这种参数化状态也称为拟设状态。VQE算法的经典优化回路使用测量/估算到的目标函数及其一个或多个偏导数来迭代地更新变分参数集,直到获得目标函数的最小值,或者换句话说,获得拟设状态的最小能量期望。
举个简单的例子,即在需要求解哈密顿量H的最小本征值E
其中,|ψ(θ)>是拟设状态,
<ψ(θ)|H|ψ(θ)>=E
现在将哈密顿量H分解为泡利(Pauli)算子的乘积:
其中,
其中,
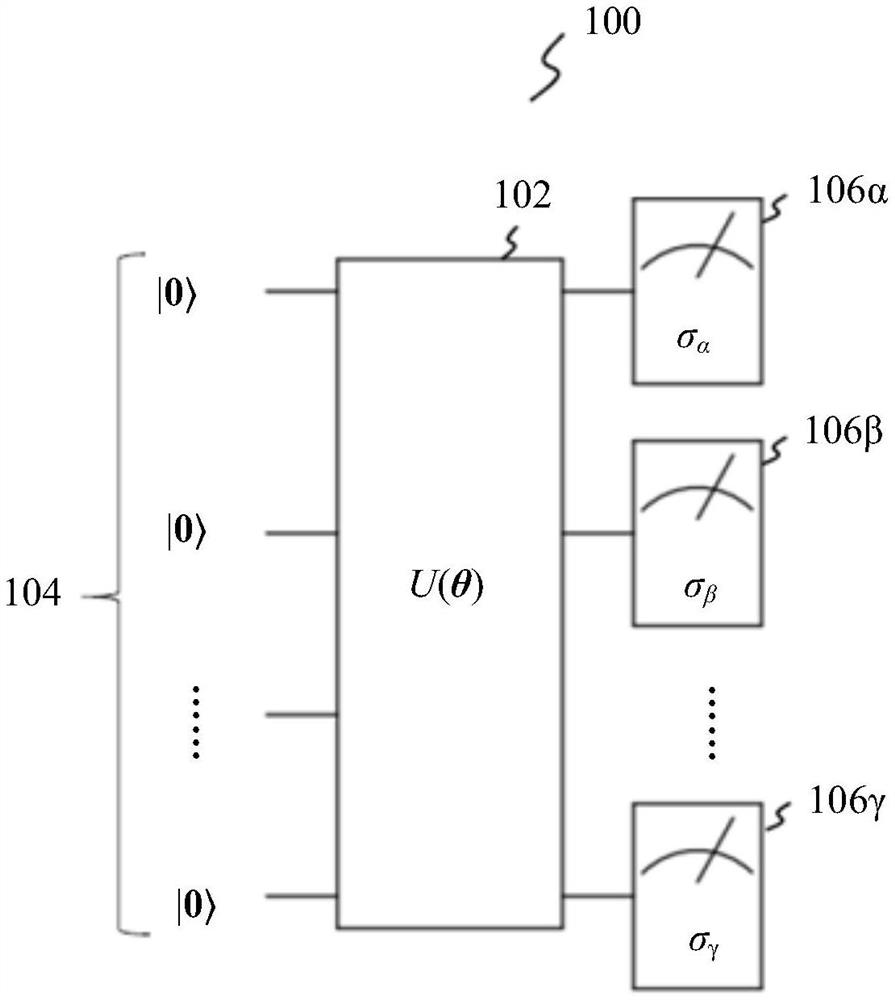
图1示出了用于估算目标函数F(θ)的每个项的典型量子电路100。在某种意义上,量子电路100可以认为是等式(2)的图形表示。如图1所示,量子电路100涉及将酉算子U(θ)102应用于初始状态102的量子比特|0>,以获得构成目标函数F(θ)的所有项的相应估算结果或测量结果106α、106β……106γ。每次更新变分参数的集合θ时,都使用量子电路100。
为了最小化目标函数F(θ)的期望值,可以使用现有的一阶和二阶优化技术。更具体地,一阶优化技术使用梯度下降法,并且需要知道目标函数F(θ)的一阶偏导数。如果目标函数F(θ)由以下等式给出:
F(θ)=<ψ(θ)|H|ψ(θ)>,
则目标函数相对于某一θ
其中,
二阶优化技术需要知道由以下等式给出的海森(Hessian)矩阵H:
如上所示,海森矩阵H由目标函数F(θ)的二阶偏导数组成,二阶偏导数通常可以写成如下:
图2示出了用于估算根据等式(3)定义的一阶偏导数和根据等式(4)定义的二阶偏导数的典型量子电路200。量子电路200事实上实现了哈达玛(Hadamard)测试,因此它也可以称为哈达玛量子电路。量子电路200包括两个哈达玛门H202和204以及控制门B 206。控制门B 206可以根据等式(3)或等式(4)定义。例如,如果使用的是一阶优化技术,则控制门B可以根据以下等式定义:
量子电路200可以通过使用辅助量子比特210测量目标量子比特208的
其中,
然而,通过使用量子电路200等计算目标函数的一阶和二阶偏导数通常可能比较复杂且计算成本高。此外,由VQE算法的量子子程序准备的拟设状态有时无法准确计算目标函数的一阶偏导数,因此一阶偏导数通过有限差分近似。最重要的是,一阶和二阶优化技术在计算目标函数的每个偏导数时都需要改变拟设状态的结构。
本文公开的示例性实施例提供了一种可以减少甚至消除上述现有技术特有的缺点的技术方案。具体地,本文公开的技术方案以在量子计算设备中使用张量网络框架来实现VQE算法的量子子程序为基础。借助于这种张量网络框架,所述量子计算设备通过简单地将酉算子U(θ)中的一个或多个变分参数位移一个阈值,能够准确(没有近似)估算目标函数F(θ)的一个或多个任意阶偏导数。所述位移无论如何都不会改变拟设状态本身的结构,所述阈值取决于所述酉算子U(θ)的类型,而所述酉算子取决于特定应用(待求解的计算任务)。此外,通过使用这些准确估算出的目标函数F(θ)的偏导数还可以提高实现所述VQE算法的经典优化回路的效率。
根据本文公开的示例性实施例,张量网络,也称为张量图,可以涉及具有根据网络模式连接的索引的张量集合。每个张量可以通过图形用一个块表示,因此整个张量网络是连接块组成的阵列。酉算子用于表示为张量网络,使得每个块包括所述酉算子中的至少一个变分参数。通过这样做,可以将相对于θ
图3A和图3B示出了两种不同的可能张量网络:树形张量网络302和棋盘(checkerboard)张量网络304,其中,每个张量网络都应用于量子比特的初始状态306。树形张量网络302和棋盘张量网络304在本领域是众所周知的,因此不再赘述。还需要说明的是,本发明不限于这些张量网络,本文公开的实施例中还可以使用张量网络的任何其它模式,例如,矩阵乘积态(matrix product state,MPS)、多尺度纠缠重整化拟设(multi-scaleentanglement renormalization ansatz,MERA)、投影纠缠对态(projected entangled-pair state,PEPS),取决于特定应用。
图4为一个示例性实施例提供的量子计算设备400的方框图。量子计算设备400包括QPU 402和存储器404。存储器404存储可执行指令406。当由QPU 402执行时,可执行指令406使得QPU 402接收用户输入408,并根据哈密顿量(类似于根据等式(1)定义的哈密顿量H),通过后面描述的操作估算目标函数410(类似于上文论述的目标函数F(θ))和目标函数410的感兴趣阶的至少一个偏导数412。用户输入408包括所述哈密顿量的所需形式。需要说明的是,图4所示的构成量子计算设备400的构造元件的数量、设置和互连并不旨在限制本发明,而只是用于提供如何在量子计算设备400内实现构造元件的总体想法。例如,如果量子计算设备400被实现为单独设备,则还可以包括收发模块(未示出),用于:执行将目标函数410和感兴趣阶的至少一个偏导数412发送到任何其它一个或多个计算设备以供进一步处理以及从其它一个或多个计算设备接收反馈而需要的不同操作。
QPU 402可以包括单个量子处理器或两个以上量子处理器。QPU 402还可以采用超导量子处理器的形式。超导量子处理器可以包括多个量子比特和多个超导耦合设备,这些超导耦合设备可用于选择性地耦合每对量子比特。超导耦合设备的示例可以包括射频超导量子干涉组件(radio frequency Superconducting quantum Interference Device,rf-SQUID)和直流SQUID(dc-SQUID),它们都通过磁通量将量子比特耦合在一起。一般而言,SQUID包括被一个约瑟夫逊(Josephson)结(rf-SQUID)或两个约瑟夫逊结(dc-SQUID)中断的超导回路。耦合设备可以同时具有铁磁耦合和反铁磁耦合,取决于耦合设备在互连拓扑中的使用方式。在磁通耦合的情况下,铁磁耦合表示平行磁通量在能量上是有利的,反铁磁耦合表示反平行磁通量在能量上是有利的。可选地,基于电荷的耦合设备可以用于QPU 402中。
存储器404可以被实现为用于现代电子计算机中的经典非易失性或易失性存储器。例如,非易失性存储器可以包括只读存储器(Read-Only Memory,ROM)、铁电式随机存取存储器(Random-Access Memory,RAM)、可编程ROM(Programmable ROM,PROM)、电可擦除PROM(Electrically Erasable PROM,EEPROM)、固态硬盘(solid state drive,SSD)、闪存、磁盘存储器(例如,硬盘和磁带)、光盘存储器(例如,CD、DVD和蓝光光盘)等。易失性存储器的示例包括动态RAM、同步DRAM(Synchronous DRAM,SDRAM)、双倍数据速率SDRAM(DoubleData Rate SDRAM,DDR SDRAM)、静态RAM等。
存储在存储器404中的可执行指令406可以用作计算机可执行代码,其使得QPU402执行本发明的各方面。用于执行本发明各方面的操作或步骤的计算机可执行代码可以用Java、C++等一种或多种编程语言的任意组合编写。在一些示例中,计算机可执行代码可以是高级语言的形式或预编译的形式,并由解释器(也预先存储在存储器404中)实时(onthe fly)生成。
图5为一个示例性实施例提供的用于操作量子计算设备400的方法500的流程图。方法500中的每个步骤都是由QPU 402执行的。方法500开始于步骤S502:QPU 402将至少一个量子比特初始化到初始状态。例如,所述初始状态可以是易于准备的状态,例如,由多个0表示,如图1所示的初始状态104。但是,所述初始状态的任何其它结构也是可能的,并且可以根据特定应用使用。接下来,方法500继续进行到步骤S504:QPU 402接收指示所需哈密顿量(Hamiltonian)的用户输入408。所述哈密顿量的形式可以取决于通过使用VQE算法待研究的量子系统,相应地取决于量子计算设备400。在一个示例性实施例中,所述哈密顿量可以表示为泡利(Pauli)算子的乘积,类似于根据上面的等式(1)定义的哈密顿量H。此外,方法500继续进行到步骤S506:QPU 402通过将酉算子应用于所述至少一个量子比特,为所述初始状态定义拟设状态。所述酉算子包括至少一个变分参数并由张量网络(类似于图3A和图3B分别示出的张量网络302和304中的任一个)表示。之后,方法500继续进行到步骤S508:QPU 402根据所述拟设状态和所述哈密顿量,测量或估算目标函数410,然后继续进行到步骤S510:QPU 402通过将所述酉算子中的所述至少一个变分参数位移一个阈值,测量或估算所述目标函数的感兴趣阶的至少一个偏导数412。如上所述,所述位移无论如何都不会改变所述拟设状态本身的结构。方法500结束于步骤S512:QPU 402将所述估算出的目标函数410和所述估算出的所述目标函数的感兴趣阶的至少一个偏导数412提供给经典计算设备。所述经典计算设备实现VQE算法的经典优化回路,稍后将对此进行论述。
需要说明的是,所述经典计算设备还可以简称为计算设备。因此,每次提到“计算设备”都应解释为与所述经典计算设备有关。每当涉及所述量子计算设备时,就会提及所述量子计算设备而不使用任何缩略形式。鉴于此,当读者看到术语“量子计算设备”和“计算设备”时,不会感到困惑。
回到量子计算设备400,在一个可能的示例性实施例中,QPU 402还可以用于从所述计算设备接收所述酉算子中的所述至少一个变分参数的一份更新。然后,QPU 402可以用于根据所述更新改变所述酉算子中的所述至少一个变分参数,之后重复方法500的步骤S506至S512。这样可以使量子计算设备400可以在VQE算法的经典优化回路中的使用效率更高。同时,需要注意的是,可能存在执行方法500的S506至S512一次就足以实现所述目标函数的最小期望值的情况(例如,当在方法500的步骤S502中准备的所述初始状态非常接近所需拟设状态时),在这种情况下,就不需要迭代更新所述酉算子中的所述至少一个变分参数。
在一个示例性实施例中,所述至少一个量子比特包括多个量子比特,所述酉算子包括分别应用于所述多个量子比特中的对应两个量子比特的子酉算子的乘积。在本实施例中,所述张量网络包括一组互连构建块,每个构建块表示所述子酉算子中的一个。
现在举一个例子说明上述具有子酉算子的实施例。首先,假设所述酉算子称为全量子比特算子,每个子酉算子称为双量子比特子算子。然后,可以将所述全量子比特算子分解如下:
其中,U(θ)是所述全量子比特算子,
图6为在总共有4个量子比特(处于初始状态)的情况下如何根据张量网络框架分解U(θ)的说明图600。具体地,说明图600示出了由4量子比特的三层棋盘张量网络604表示的4量子比特算子U(θ)602。鉴于棋盘张量网络604,可以将4量子比特算子U(θ)602写成以下形式:
图7为如何可以根据张量网络框架进一步分解每个双量子比特子算子
其中,指数表示泡利-X门704和706、泡利-Z门710和712以及伊辛(ZZ)耦合门708的旋转,
……
因此,例如,相对于
其中,
因此,使用符号
具体地,二阶导数看起来是
鉴于上面的示例,可以看出,取目标函数410的任意阶偏导数的操作简化为简单地将酉算子中的对应一个或多个变分参数位移阈值π/2。同时,需要注意的是,本发明并不限于该阈值,而且一些其它实施例可以需要其它阈值,具体取决于要使用的酉算子的类型,尤其是其张量网络表示。
图8为如何可以根据张量网络框架进一步分解每个双量子比特子算子
棋盘张量网络802比棋盘张量网络702灵活,因为棋盘张量网络802可以准备任一双量子拟设状态。同时,棋盘张量网络802涉及多使用两个参数(即7对比5),因此不适合处理伊辛哈密顿量。
通常,双量子比特子算子的张量网络表示可以根据所需哈密顿量选择(类似于上文针对伊辛哈密顿量所做的那样)。例如,如果所需哈密顿量是包括YY个项的伊辛哈密顿量,则有必要使用伊辛(YY)耦合门代替伊辛(ZZ)耦合门708。
在一个示例性实施例中,QPU 402可以用于在方法500的步骤S510中估算目标函数410的二阶偏导数412。之后,QPU 420还可以用于在方法500的步骤S512中将二阶偏导数412作为海森矩阵H提供给计算设备。海森矩阵H还可以用于二阶优化技术中。
图9为一个示例性实施例提供的计算设备900的方框图。设备900包括处理单元902和存储器904。存储器904存储可执行指令906。当由处理单元902执行时,可执行指令906使得处理单元902从量子计算设备400(即QPU 402)接收估算出的目标函数410和估算出的感兴趣阶的至少一个偏导数412,并将它们用于VQE算法的经典优化回路中,稍后对此进行描述。需要说明的是,图9所示的构成计算设备900的构造元件的数量、设置和互连并不旨在限制本发明,而只是用于提供如何在计算设备900内实现构造元件的总体想法。例如,如果计算设备900被实现为单独的设备,则还可以包括收发模块(未示出),用于与量子计算设备400的收发模块和/或任何其它设备进行通信,具体取决于特定应用。
处理单元902可以被实现为中央处理单元(central processing unit,CPU)、通用处理器、专用处理器、微控制器、微处理器、专用集成电路(application specificintegrated circuit,ASIC)、现场可编程门阵列(field programmable gate array,FPGA)、数字信号处理器(digital signal processor,DSP)、复杂可编程逻辑器件等。还需要说明的是,处理单元902可以被实现为上述一个或多个的任意组合。例如,处理单元可以是两个以上微处理器的组合。
存储器904和可执行指令906分别可以通过与量子计算设备400中的存储器404和可执行指令406相同或类似的方式实现。
图10为一个示例性实施例提供的用于操作计算设备900的方法1000的流程图。方法1000的每个步骤都是由处理单元902执行的。方法1000开始于步骤S1002:处理单元902从量子计算设备400接收估算出的目标函数410和估算出的目标函数410的感兴趣阶的至少一个偏导数412。然后,方法1000继续进行到步骤S1004:处理单元902使用估算出的目标函数410和估算出的目标函数410的感兴趣阶的至少一个偏导数412,准备酉算子中的至少一个变分参数的一份更新。接下来,处理单元902在步骤S1006中将所述酉算子中的所述至少一个变分参数的所述更新提供给量子计算设备400。之后,方法1000继续进行到步骤S1008:使得处理单元902重复步骤S1002至S1006,直到满足预定义的结束条件。所述预定义的结束条件可以包括以下至少一种条件:提供了估算出的目标函数410的最小值,预定义的计时器超时,提供了预定义的重复计数。方法1000结束于步骤S1010:处理单元902确定满足所述预定义的结束条件,并且作为响应,将所述酉算子中的所述至少一个变分参数的一份最后更新908以及拟设状态910和所述哈密顿量的本征值912一起提供给用户。拟设状态910和所述哈密顿量的本征值912对应于所述酉算子中的所述至少一个变分参数的最后更新908。
在一个示例性实施例中,处理单元902还可以用于通过使用监督式或非监督式机器学习技术执行方法1000的步骤S1002至S1008。所述监督式或非监督式机器学习技术可以基于神经网络、决策树、线性回归、逻辑回归、随机森林、梯度提高树算法、支持向量机(Support Vector Machine,SVM)等。
在一个示例性实施例中,处理单元902还可以用于通过使用梯度下降法、牛顿迭代法(Newton's method)或置信域方法(trust-region method)执行方法1000的步骤S1002至S1008。所述置信域方法可以简化为基于海森的精确置信域方法,前提是处理单元902接收估算出的感兴趣阶的至少一个偏导数412作为海森矩阵H。
图11为一个示例性实施例提供的混合量子经典计算装置1100的方框图。装置1100包括量子计算设备400和计算设备900,它们用于相互通信(如双向箭头所示)。量子计算设备400和计算设备900可以放置在单芯片上的装置1100内。在装置1100的操作过程中,这个单芯片可以被冷却到适用于至少部分地在计算设备900的组件内实现(量子计算通常需要的)超导性的温度,从而减少其中的散热量。此外,根据制造材料,计算设备900的组件在这种低温下(相比于室温)可以消耗更少的功率且产生更少的废热。
图12为一个示例性实施例提供的用于操作装置1100的方法1200的流程图。如图所示,方法1200包括两个步骤:1202和1204。具体地,步骤1202由量子计算设备400(即QPU402)执行,以实现方法500的步骤S502至S512,而步骤1204由计算设备900(即处理单元902)执行,以实现方法1000的步骤S1002至S1010。为了使图12不复杂,方法500的一些步骤被组合为一个步骤。
图13为一个示例性实施例提供的用户界面1300的方框图。用户界面1300包括输入单元1302和显示单元1304。输入单元1302通信地耦合到量子计算设备400,并且用于接收用户输入408并将其提供给至少一个QPU 402。显示单元1304通信地耦合到计算设备900,并且用于将酉算子中的至少一个变分参数的最后更新908以及拟设状态910和哈密顿量的本征值912一起接收并显示。用户界面1300可以根据软件、固件、硬件或其任意组合实现。在一个示例中,用户界面1300可以被实现为网站提供并在网页浏览器中显示给用户的网页。在另一个示例中,用户界面1300可以被实现为安装在用户移动设备上的应用程序,其中的输入单元1302和显示单元1304分别用于与量子计算设备400和计算设备900进行无线通信。在又一个可能的示例中,用户界面1300是装置1100的一部分,因此,输入单元1302和显示单元1304分别可以用于与量子计算设备400和计算设备900执行有线通信。无论用户界面1300如何实现,即使用户没有量子计算经验,也可以通过简单地输入哈密顿量的期望形式轻松获得上述结果。因此,用户界面1300甚至可以由公众用户使用。
图14示出了通过使用拟设状态的三层棋盘张量网络获取4量子比特伊辛哈密顿量的VQE算法的模拟结果。更具体地,该绘图示出了伊辛哈密顿量的近似本征值(基态能量)与用于三种不同优化(换句话说,最小化)方法的目标函数估算次数之间的依赖关系。三种优化方法即Nelder-Mead方法(参见点曲线)、Broyden-Fletcher-Goldfarb-Shanno(BFGS)方法(参见虚曲线)和基于海森的精确置信域方法(参见实曲线)。同时,插图示出了伊辛哈密顿量的相同本征值与针对BFGS方法和基于海森的精确置信域方法在VQE中进行的迭代次数之间的依赖关系。从绘图和插图可以看出,与其它优化方法相比,基于海森的精确置信域方法在迭代方面表现出更好的性能,并且可以提供更准确的基态能量值。
需要说明的是,方法500、方法1000、方法1200的每个步骤或操作或者步骤或操作的任意组合可以通过硬件、固件和/或软件等各种模块来实现。例如,上述步骤或操作中的一个或多个可以由处理器可执行指令、数据结构、程序模块和其它合适的数据表示来体现。此外,体现上述步骤或操作的可执行指令可以存储在对应的数据载体上,并由QPU 402和处理单元902执行。这种数据载体可以实现为计算机可读存储介质,配置为可由所述至少一个处理器读取以执行计算机可执行指令。这种计算机可读存储介质可以包括易失性介质和非易失性介质、可移动介质和不可移动介质。作为示例而非限制,计算机可读介质包括以任何适合存储信息的方法或技术实现的介质。更详细地,计算机可读介质的实际示例包括但不限于信息传递介质、RAM、ROM、EEPROM、闪存或其它存储器技术、CD-ROM、数字多功能光盘(digital versatile disc,DVD)、全息介质或其它光盘存储器、磁带、磁带盒、磁盘存储器和其它磁存储设备。
虽然本文描述了本发明的示例性实施例,但需要说明的是,在不偏离由所附权利要求书所定义的法律保护范围的情况下,可以在本发明的实施例中进行任何各种更改和修改。在所附权利要求书中,词语“包括”不排除其它元素或操作,“一”不排除多个。在互不相同的从属权利要求中详述某些措施并不表示这些措施的组合无法有利使用。
- 通过张量网络框架实现变分量子本征求解器算法
- 量子本征求解器的实现方法、装置及电子设备