一种基于并联交互架构模型实现多维度特征融合的目标检测方法
文献发布时间:2023-06-19 18:30:43
技术领域
本发明属于计算机视觉中的目标检测领域,具体提出一种基于并联交互架构模型实现特征融合的目标检测方法。
背景技术
目标检测是计算机视觉领域长久以来不可忽视的一项基本任务,它的主要目的是预测图像中实例的位置和类别。作为包括实例分割和目标跟踪在内诸多视觉任务的基础,目标检测在图像视觉领域有着非常重要的研究意义。而随着近年来自动驾驶和工业缺陷检测等实用领域热度的上升,工业界对目标检测的关注也越来越多。目标检测的核心挑战是如何使检测网络从输入特征中充分学习到图像的空间信息和语义信息,以及如何由这些信息精准地定位和分类实例。目标检测器需要强大的特征融合能力和足够的空间敏感度,传统的深度学习检测模型大多基于卷积神经网络(CNN)。CNN利用卷积操作充分融合图像中的局部特征,灵敏的局部空间感知能力使CNN成为最适合目标检测任务的网络之一;但同时CNN具有一定局限性,它在全局空间上的特征融合能力有所欠缺。基于CNN的传统目标检测模型通常根据如何定位物体分为anchor-based和anchor-free;前者利用anchor来预测潜在物体,而后者通常基于中心点检测物体。Anchor-based模型又根据检测步骤可分为one-stage和two-stage;前者的经典模型有YOLO系列、SSD、RetinaNet等,后者则以R-CNN系列作为代表。二阶段的方法第一步先寻找潜在目标区域然后第二步对这些区域计算类别得分,即先定位再分类;而单阶段的方法直接一步生成检测框预测物体的类别和位置。基于CNN的模型主要有两个关键问题:如何对anchor和groundtruth标签分配和怎样使模型从特征中有效地学习到关键语义信息。为了解决这两个问题而设计的模型也具有比较明显的缺点,比如都需要在一定的先验条件下进行人工设计知识,而实际上针对不同的检测方法设计这些先验诸如合适的锚点和阈值是很困难的任务。另一方面,由于卷积核的尺寸限制,CNN的全局特征交互能力较弱。
近年来,随着视觉Transformer(ViT)的出现、DEtectionTRansformer(DETR)及其变体掀起了将Transformer应用于目标检测的热潮。这些新的物体检测范式舍弃了传统的CNN,取而代之的是精心设计的多层编码和解码架构;其中的编码器用来融合特征,而解码器用object query来解耦特征中的丰富语义。与CNN相比,ViT更加强调空间上全局间的语义关联,它通过全局self-attention机制整合全局空间特征。DETR把物体检测看作集合预测的任务。一定数量的object query在训练过程中与groundtruth相匹配。这个过程省去了传统模型的标签分配;而在推理过程中,网络根据object query直接预测对象。此外在定位物体方面,DETR使用positional embedding增强模型的位置感知灵敏度,然而,DETR类探测器存在网络收敛速度慢、算力依赖高等问题。
发明内容
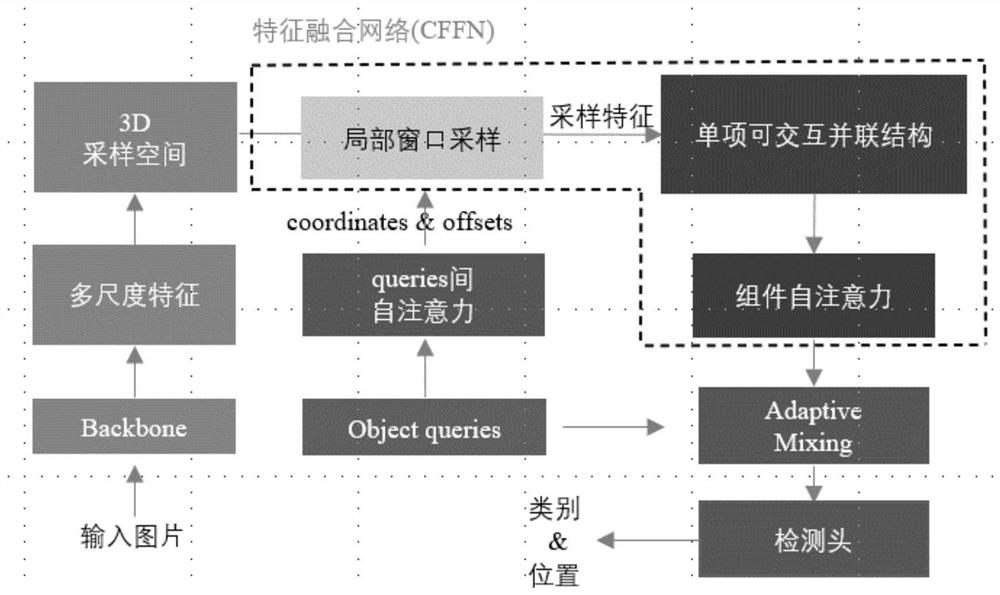
本发明为解决上述问题,结合了深度学习其它领域的最新思想,提出了一种基于并联交互架构模型实现特征融合,旨在为模型提供先进的特征融合能力。首先在特征提取方式方面,本发明引入了不同于传统CNN的3D特征空间窗口采样,充分提取了局部和全局的空间特征;随后本发明提出了多维度特征融合网络CFFN,能够让模型在空间和通道维度深度地融合图像特征,从而更好的让模型学习到语义信息,进而实现更好的检测效果、达到更高的检测精度。
为达到上述目的,本发明提出以下技术方案:一种基于并联交互架构模型实现多维度特征融合的目标检测方法,该方法包括以下步骤:
步骤1:准备模型训练所需COCO2017数据集;在服务器中配置COCO2017数据集,按照要求格式放入训练文件夹;
步骤2:在mmdetection框架下搭建模型,配置训练所需PyTorch深度学习环境;
步骤3:设置好训练超参数,将数据集输入到并联交互架构端到端目标检测模型中进行训练;
步骤4:模型将输入图像送入ResNet50中进行特征提取,输出多尺度特征图feature map,同时由多尺度特征图构建3D特征采样空间;
步骤5:生成一组包含内容向量和位置向量的预测向量object queries。对每个object query而言,object query通过前馈神经网络生成采样偏移,以其位置向量作为初始坐标,结合采样偏移生成模型初始采样点;
步骤6:以初始采样点和其在采样空间上的八个邻点构成一个局部采样窗口,对窗口内的点进行插值,得到窗口特征,接着铺平窗口;
步骤7:得到的特征矩阵送入特征融合网络CFFN,CFFN由一个单向并联交互结构(PSUI)和一个组间自注意力层构成,这层实现对特征在空间和通道维度上的充分融合;
步骤8:充分融合后的特征送入AdaptiveMixing解码层进行特征解耦;
步骤9:解码层的最终输出依次通过两个前馈神经网络FFN分别更新object query的内容向量和位置向量,其内容向量和位置向量再经过两个FFN预测待检测目标的类别与位置;
步骤10:模型训练完毕后,可以验证其精度,也可以用训练好的模型文件根据输入的测试图片生成检测框,检测出测试图片中待检测物体的类别和位置。其中,步骤4中,模型用经典CNN骨干网络ResNet50对输入的图像进行特征预提取,得到四个不同尺度的特征图。若输入的图像维度为
步骤6、如图2所示,在特征采样空间中取来自步骤5中的初始采样点的八个邻点和初始采样点本身构成局部采样窗口,接着对窗口内的采样点进行插值得到采样特征矩阵x∈R
上述公式中,S为局部窗口的尺寸,i为局部窗口内的采样点,Coordinate指采样点坐标,Interpolation则为插值操作。
步骤7中CFFN包含单向可交互并联结构(PSUI)和组间自注意力,其中PSUI由左右两条支路以及连接它们的一条自右向左单向交互网络组成,PSUI的细节如图3所示为:
(1)左边的支路进行窗口间自注意力来实现局部特征融合,窗口间自注意力运算中的V
Q
V
上述公式中,Q
(2)右边的支路先对局部窗口特征矩阵进行维度转换,转换后的矩阵为x∈R
(3)单项交互连接的方向自右向左,右支路的depthwise卷积输出经过交互网络的操作后得到包含通道语义权重的factor,输入给左支路参与左支路中的自注意力运算。
(4)左右支路的最终结果均只在P维度保留初始采样点的特征,则矩阵维度转变为x∈R
步骤7中CFFN包含单向可交互并联结构(PSUI)和组间自注意力,其中组间自注意力的细节为:为了缩减网络消耗运算量,加快网络检测速度和训练速度,在采样时本模型将d
Q
上述公式中Q
在本发明训练过程中,模型从训练输入的初始图片以一组固定个数(N)的objectquery预测出了相同大小的候选框,其中N通常比图像中感兴趣的对象的实际数量大得多,因此使用一个额外的特殊类标签
在本发明整个训练过程中,并联交互架构目标检测模型采用了one-to-one labelassignment的方式,需要将每一个预测框和Bounding box匹配起来,模型用匈牙利算法来在真实对象和预测对象间实现最佳二分匹配,即找到最优匹配方式
上式σ为ground truth和预测框的匹配规则,θN表示可能的匹配方式,y为groundtruth集合,
groundtruth集合y中的每个元素y
本发明训练过程中的损失函数即为上述匹配中所有配对的匈牙利损失:
其中
步骤10中12个epoch完成后,训练好的模型保存为pt文件,可使用训练好的模型文件来验证模型精度和图片。
步骤10所提及到的检测图片具体方法为:
可使用网络加载训练好的模型文件来检测图像中的物体;运行detect代码,设置检测模型为训练完毕的pt文件,输入图片目录设置为待检测图片所在文件夹。开始检测,将待检测数据输入训练好的模型进行图像识别与定位,模型会输出若干个包含图片中潜在物体的位置与类别的预测框。
相对于现有技术,本发明有着以下优点。在方法层面:一是本发明没有用传统的CNN来进一步提取特征,而是以构建3D采样空间随后在其中进行窗口采样的方式获取空间特征,提高特征提取在空间维度上的丰富性同时加强了模型的定位能力;二是本发明为提高特征融合质量,设计了CFFN网络结构来在空间和通道维度上融合提取到的特征,CFFN网络包含了卷积和自注意力操作,不同方法用于不同维度的特征融合,这一设计大大地丰富了语义信息,为提高模型精度做出了贡献;而在应用层面,本发明在实例的12个epoch的训练周期下得到了43.0的AP精度,优于许多检测方法,与此同时本发明舍弃了传统CNN检测网络的先验知识,训练速度也有所提升,进而解决了目标检测任务中收敛速度慢、训练耗时长等难题,提高了目标检测任务的精度和检测速度。
附图说明
图1是本发明网络结构图;
图2是本发明采样局部窗口示意图;
图3是本发明PSUI结构示意图。
具体实施方式
下面结合附图和本发明实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例1:针对目前传统的两阶段目标检测方法,本发明提出一种基于并联交互架构模型实现多维度特征融合的2D图像目标检测方法。
本实施例以COCO2017数据集作为实验数据,借助数据扩增技术,利用基于骨干网络ResNet50、3D特征空间窗口采样方式、特征融合网络CFFN和包含两个前馈网络的检测头的端到端并联交互目标检测模型来实现对物体定位与分类。
步骤1:准备模型训练所需COCO2017数据集;在服务器中配置COCO2017数据集,按照要求格式放入训练文件夹;
步骤1.1、在COCO官网获取公开数据集COCO2017,下载官方划分的训练集和验证集的图片与标注。
步骤1.2、COCO2017数据集由训练集图像和标注文件、验证集图像和标注文件组成,训练集图像、验证集图像和标注分别放置于train2017、val2017以及annotations文件夹内。
步骤2:搭建模型,配置训练所需PyTorch深度学习环境;
步骤2.1、在anaconda中为项目创建虚拟环境,在虚拟环境中安装训练环境所需关键包如pytorch 1.11.0等。训练服务器所用显卡为NVIDIA RTX 3090GPU,操作系统为Ubuntu20.04,CUDA版本为11.3,编译语言为Python 3.8。
步骤2.2、安装配置mmdetection框架和所需mmcv编译包,此外安装训练脚本所需其他依赖包。
步骤3:设置好训练超参数,将数据集输入到并联交互架构端到端目标检测模型中进行训练;
步骤3.1、训练部分超参数为:特征提取backbone为ResNet50,初始学习率为0.000125,batch size为4,epoch个数为12。
步骤4:模型将输入图像送入ResNet50中进行特征提取,输出多尺度特征图feature map,接着由多尺度特征图构建3D特征采样空间;
步骤5:生成一组包含内容向量和位置向量的预测向量object queries。对每个object query而言,object query通过前馈神经网络生成采样偏移,以其位置向量作为初始坐标,结合采样偏移生成模型初始采样点;
步骤6:以初始采样点和其在采样空间的八个邻点构成一个局部采样窗口,对窗口内的点进行插值,得到窗口特征,接着铺平窗口;
步骤7:得到的特征矩阵送入特征融合网络CFFN,CFFN由一个单向并联交互结构(PSUI)和一个组间自注意力层构成,这层实现对特征在空间和通道维度上的充分融合;
步骤8:充分融合后的特征送入Adaptive Mixing解码层进行特征解耦;
步骤9:解码层的最终输出依次通过两个前馈神经网络FFN分别更新object query的内容向量和位置向量,其内容向量和位置向量再经过两个FFN预测待检测目标的类别与位置;
步骤10:模型训练完毕后,可以验证其精度,也可以用训练好的模型文件根据输入的测试图片生成检测框,检测出测试图片中待检测物体的类别和位置。
步骤10.1、12个epoch完成后,训练好的模型保存为pt文件,可使用val.py根据该训练权重对模型进行精度验证,将步骤1中所提及的val2017数据集输入模型,即可评估训练完毕模型的精度。精度指标共有AP、AP
步骤10.2、可使用检测网络加载训练好的模型文件来检测图像中的物体;运行detect代码,设置检测模型为训练完毕的pt文件,输入图片目录设置为待检测图片所在文件夹。上述操作设置完毕即可开始检测,将待检测数据输入训练好的模型进行图像识别与定位,模型会输出若干个包含图片中潜在物体的位置与类别的预测框。
- 一种基于情感维度下的深度情感交互模型的构建方法
- 基于多维度特征融合和模型集成的恶意软件家族分类方法
- 基于CNN的多级特征融合的多类目标检测方法及模型