一种用于公钥密码算法加速的协处理器
文献发布时间:2023-06-19 18:37:28
技术领域
本发明属于数字逻辑电路技术领域,更具体地,涉及一种用于公钥密码算法加速的协处理器。
背景技术
公钥密码算法具有信息的加密、解密、数字签名和签名验证等功能,且具备公钥和私钥两套不同的密钥,使其在安全性上强于对称密码算法。随着信息安全风险的不断上升,密钥的长度也在不断加长,随之而来的是公钥算法的计算量在快速变大。使用编程手段来实现公钥密码算法不仅容易遭受外来攻击,而且计算效率低下,因此,使用专门的计算单元加速特定算法成为了主流优化思想。
当前主流的公钥密码算法主要包括RSA、ECC以及SM2这三种算法。目前,业界普遍要求兼容2048、3072甚至4096位长度的RSA,ECC和SM2则涉及到椭圆曲线域的兼容性。当前ECC广泛使用的有限域是素数域和二元域,SM2基于ECC之上,要求必须同时兼容这两种域中的椭圆曲线问题计算,同时规定密钥长度为256/257位。国内外在公钥算法加速器设计上的成果众多,但是在兼容性的取舍、密钥长度的限定和算法的硬件实现上都不尽相同。
传统公钥密码加速器存在以下不足点:能加速的公钥密码算法通常是单一的,在当前多种公钥密码算法混合使用的场合,其很难发挥出最大的加速效果;支持的RSA密钥长度短,不符合目前的安全性需求;对ECC/SM2算法的运算域支持不完备,只支持素数域和二元扩域其中一个运算域;支持的ECC/SM2算法的椭圆曲线长度较短,难以满足当下以及未来的需求。
发明内容
针对现有技术的缺陷和改进需求,本发明提供了一种用于公钥密码算法加速的协处理器,其目的在于解决传统加速器支持的算法单一、支持的密钥长度低和运算域不齐全的问题。
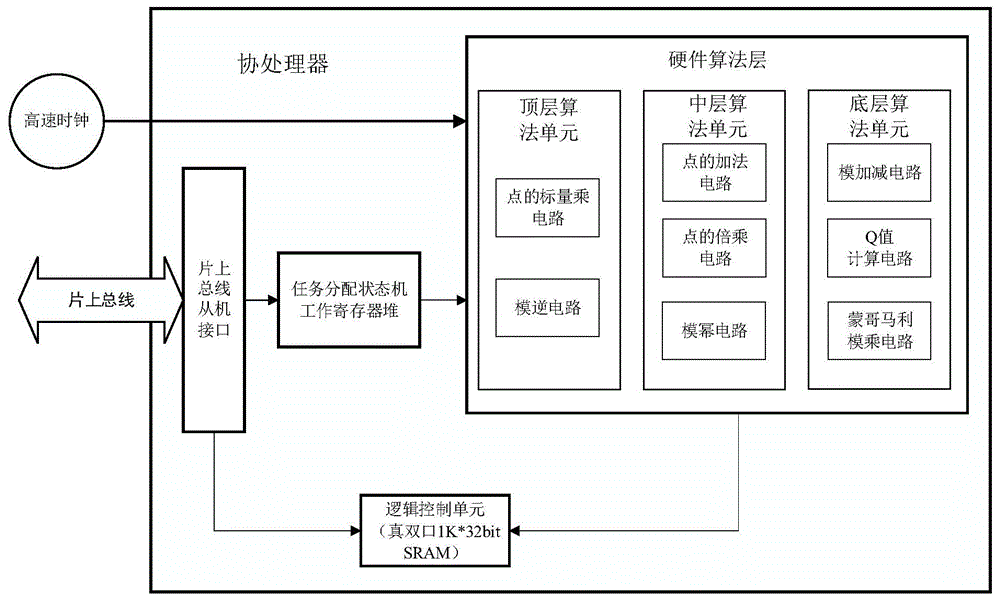
为实现上述目的,本发明提供了一种用于公钥密码算法加速的协处理器,包括:底层算法单元,包括模加减电路、Q值计算电路和蒙哥马利模乘电路;中层算法单元,包括点的加法电路、点的倍乘电路和模幂电路,可调用所述底层算法单元;顶层算法单元,包括模逆电路和点的标量乘电路,可调用所述中层算法单元和所述底层算法单元;逻辑控制单元,用于根据操作命令控制所述底层算法单元、所述中层算法单元和所述顶层算法单元,以实现4096位及以下任意长度的RSA算法中模幂操作、SM2算法中椭圆曲线的多倍点操作以及ECC算法中椭圆曲线的多倍点操作。
更进一步地,第一乘数A、第二乘数B和模数N分别按照32位一组分为w+1个元素后输入所述蒙哥马利模乘电路,所述蒙哥马利模乘电路用于:S1,计算第一参数T:T=(A
更进一步地,所述蒙哥马利模乘电路包括计算单元,所述计算单元包括:第一Wallace树形双域流水线乘法器,用于计算A
更进一步地,所述计算单元的数量为一个或多个,当所述计算单元的数量为多个时,多个所述计算单元按照顺序依次执行一轮所述S1-S7。
更进一步地,所述第一Wallace树形双域流水线乘法器和所述第二Wallace树形双域流水线乘法器为32比特宽度的三级流水线乘法器;所述第一双域加法器、所述第二双域加法器、所述第三双域加法器和所述第四双域加法器为64比特宽度的双域行波加法器。
更进一步地,所述Q值计算电路用于计算预计算参数Q,预计算参数Q满足:
其中,N
更进一步地,所述模加减电路可被所述点的加法电路和所述点的倍乘电路调用;所述Q值计算电路可被所述操作命令调用;所述蒙哥马利模乘电路可被所述操作命令、所述点的加法电路、所述点的倍乘电路和所述模幂电路调用;所述点的加法电路和所述点的倍乘电路可被点的标量乘电路调用;所述模幂电路可被所述操作命令和所述模逆电路调用;所述模逆电路被所述操作命令和所述点的标量乘电路调用;所述点的标量乘电路被所述操作命令调用。
更进一步地,素数域中,所述点的加法电路和所述点的倍乘电路在雅可比-仿射混合坐标系中分别进行点的加法运算和点的倍乘运算;二元扩域中,所述点的加法电路和所述点的倍乘电路在洛佩兹达哈卜-仿射混合坐标系中分别进行点的加法运算和点的倍乘运算。
更进一步地,所述模逆电路采用费马小定理算法实现双域模逆运算,最大模数比特宽度为4096位。
总体而言,通过本发明所构思的以上技术方案,能够取得以下有益效果:
(1)通过对RSA、ECC和SM2算法的分析,将所有需要硬件实现的数学算法划分为底层算法、中层算法和顶层算法,并将所有算法单元整合成协处理器,其支持4096位及以下的RSA模幂运算、SM2所需的256/257位双域椭圆曲线点乘计算、ECC不高于384位的双域椭圆曲线点乘计算以及双域模乘、模逆运算,兼容性好;
(2)资源消耗可定制,通过改变蒙哥马利模乘电路中并行计算单元的数量,可以在电路的计算速度、面积、功耗之间做平衡,满足多种不同场合的需求。
附图说明
图1为本发明实施例提供的用于公钥密码算法加速的协处理器的架构示意图;
图2为本发明实施例提供的蒙哥马利模乘电路的结构示意图;
图3为本发明实施例提供的计算单元的一轮执行过程的示意图;
图4为本发明实施例提供的计算单元的结构示意图;
图5为本发明实施例提供的蒙哥马利模乘电路的数据流示意图;
图6为本发明实施例提供的协处理器应用场景示意图;
图7为本发明实施例提供的测试256位素数域椭圆曲线点乘的结果;
图8为本发明实施例提供的测试257位二元扩域椭圆曲线点乘的结果;
图9为本发明实施例提供的计算4096位RSA私钥运算的结果;
图10为本发明实施例提供的计算素数域和二元扩域模逆运算的结果。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
在本发明中,本发明及附图中的术语“第一”、“第二”等(如果存在)是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。
图1为本发明实施例提供的用于公钥密码算法加速的协处理器的架构示意图。参阅图1,结合图2-图10,对本实施例中用于公钥密码算法加速的协处理器进行详细说明。
参阅图1,用于公钥密码算法加速的协处理器包括:底层算法单元、中层算法单元、顶层算法单元、和逻辑控制单元。
底层算法单元包括模加减电路、Q值计算电路和蒙哥马利模乘电路。中层算法单元包括点的加法电路、点的倍乘电路和模幂电路,可调用底层算法单元。顶层算法单元包括模逆电路和点的标量乘电路,可调用中层算法单元和底层算法单元。
逻辑控制单元根据操作命令控制底层算法单元、中层算法单元和顶层算法单元,以实现4096位及以下任意长度的RSA算法中模幂操作、SM2算法中椭圆曲线的多倍点操作以及ECC算法中椭圆曲线的多倍点操作。
进一步地,根据本发明的实施例,模加减电路可被点的加法电路和点的倍乘电路调用;Q值计算电路可被操作命令调用;蒙哥马利模乘电路可被操作命令、点的加法电路、点的倍乘电路和模幂电路调用;点的加法电路和点的倍乘电路可被点的标量乘电路调用;模幂电路可被操作命令和模逆电路调用;模逆电路被操作命令和点的标量乘电路调用;点的标量乘电路被操作命令调用。
用于公钥密码算法加速的协处理器(以下简称为协处理器)可以对RSA公钥密码算法的加密、解密等操作进行加速。RSA公钥密码算法的加密和解密原理如下:
(1)密钥的生成
(1.1)随机选取两个不同的大素数p和q,计算模数N=p×q。由欧拉函数可知,与N互素且不大于N的整数个数为
(1.2)选取一个公钥K
(1.3)计算满足(K
(2)加密方法
对于明文比特串P,其满足条件P
(3)解密方法 对于密文比特串,将其进行分割处理后,某组密文为C,则其解密过程为:
协处理器能计算上述算法中的 协处理器能对ECC公钥密码算法的加密和解密操作进行加速,典型的素数域ECC公钥密码算法的加解密原理如下: (1)密钥的生成 (1.1)选择一个素数域GF(P)和一条定义在素数域上的椭圆曲线E (1.2)随机生成一大数k,要求k大于1且小于n,计算点的标量乘P=kG。随机数k为私钥,P=kG为公钥部分。 (2)加密方法 对于明文序列(M C 由此,得到密文序列(C (3)解密方法 得到密文序列(C (x,y)=kC 协处理器能计算上述算法中的C 协处理器能对SM2公钥密码算法的加密和解密操作进行加速,其加解密原理如下: (1)密钥的生成 (1.1)从素数域GF(P)和二元域GF(2 (1.2)选取基点G,要求G的阶n接近#GF(P)或#GF(2 (2)加密方法 假设有一长度为klen的明文串M需要加密,其具体加密过程为:随机生成一数k∈[1,n-1],计算C (3)解密方法 假设有一密文C=(C 协处理器能计算上述算法中的素数域256位椭圆曲线的点乘操作和二元扩域257位椭圆曲线的点乘操作。 本实施例中,通过对RSA、ECC和SM2算法的分析,将所有需要硬件实现的数学算法划分为底层算法、中层算法和顶层算法,并将所有算法单元整合成协处理器,其支持4096位及以下的RSA模幂运算、SM2所需的256/257位双域椭圆曲线点乘计算、ECC不高于384位的双域椭圆曲线点乘计算以及双域模乘、模逆运算。 本实施例中,第一乘数A、第二乘数B和模数N分别按照32位一组分为w+1个元素后输入蒙哥马利模乘电路,输入蒙哥马利模乘电路的第一乘数A、第二乘数B和模数N为: A={A B={B N={N 蒙哥马利模乘电路的输入还包括:预计算参数Q、R=2 S=MontMul(A,B,R,N)=(ABR 根据本发明的实施例,蒙哥马利模乘电路用于执行操作S1-操作S8,如图3所示。其中,第一参数T、第二参数U、S的初始值均为0。 操作S1,计算第一参数T: T=(A 其中,i的初始值为0,A 操作S2,计算第二参数U: U=(Q×T)&(0xFFFF_FFFF) 其中,Q为预计算参数 操作S3,计算第三参数Z: Z=S 其中,D为初始值为0的第四参数,N 操作S4,更新第四参数D: D=Z>>32 操作S5,更新第三参数Z: Z=S 其中,j的初始值为1,S 操作S6,更新S S D=Z>>32 操作S7,对j进行加一处理,重复执行操作S5-操作S6,直至j=w+1。 操作S8,对i进行加一处理,重复执行操作S1-操作S7,直至i=w。 根据本发明的实施例,蒙哥马利模乘电路包括计算单元(Calculation unit,CU)。参阅图4,计算单元包括:第一Wallace树形双域流水线乘法器、第二Wallace树形双域流水线乘法器、第一双域加法器、第二双域加法器、第二双域加法器和第四双域加法器。计算单元还包括计算参数寄存器、操作数延时寄存器堆、计算结果延时寄存器堆和控制状态机等。 第一Wallace树形双域流水线乘法器的输入端连接内部计算参数寄存器和/或计算单元取到的操作数,输出端连接第一双域加法器和第三双域加法器的输入端以及内部计算参数寄存器。第一双域加法器的输入端和输出端还均连接到内部计算参数寄存器。 第二Wallace树形双域流水线乘法器的输入端连接内部计算参数寄存器和计算单元取到的操作数,输出端连接第三双域加法器的输入端。第三双域加法器的输出端连接到第四双域加法器的输入端。 第二双域加法器的输入端连接到内部计算参数寄存器,输出端连接到第四双域加法器的输入端。第四双域加法器的输出端连接到计算结果延时寄存器堆。 计算参数寄存器包含了存储中间参数A 第一Wallace树形双域流水线乘法器用于计算A 第一双域加法器用于根据A 第四双域加法器,用于将S 根据本发明的实施例,第一Wallace树形双域流水线乘法器和第二Wallace树形双域流水线乘法器为32比特宽度的三级流水线乘法器;第一双域加法器、第二双域加法器、第三双域加法器和第四双域加法器为64比特宽度的双域行波加法器。 参阅图2,蒙哥马利模乘电路还包括CU主控电路和FIFO。CU主控电路用于从SRAM中取得需要的操作数,并送给计算单元。FIFO为同步FIFO,用于暂存一次计算过程中最终的迭代结果S。每个计算单元的功能为执行一次32位字的高基蒙哥马利算法的外部循环;CU主控电路的功能为控制整个模乘计算的过程,包括取操作数、送操作数、判断计算结束等。 根据本发明的实施例,计算单元的数量为一个或多个。当计算单元的数量为多个时,多个计算单元按照顺序依次执行一轮操作S1-操作S7。以图5中示出的蒙哥马利模乘电路中计算单元的数量为5个为例,CU主控电路从SRAM中取得A 通过利用多个(如5个)计算单元构成模乘电路,使得计算单元主控仅需取B和N一次,即可完成上述算法中操作2的多轮(如5轮)for循环,大大减少了模乘运算消耗的时间。 根据本发明的实施例,Q值计算电路用于计算预计算参数Q,预计算参数Q满足:
其中,N 根据本发明的实施例,素数域中,点的加法电路和点的倍乘电路在雅可比-仿射混合坐标系中分别进行点的加法运算和点的倍乘运算;二元扩域中,点的加法电路和点的倍乘电路在洛佩兹达哈卜-仿射混合坐标系中分别进行点的加法运算和点的倍乘运算。 根据本发明的实施例,模逆电路采用费马小定理算法实现双域模逆运算,最大模数比特宽度为4096位。 本实施例中,蒙哥马利模乘电路用于计算素数域和二元扩域的大数模乘;模加减电路用于计算素数域和二元扩域的大数模加减,并且能够在不求补码的条件下完成有限域中的加减法运算;点的加法电路用于计算素数域和二元扩域椭圆曲线上的两点的相加;点的倍乘电路用于计算素数域和二元扩域椭圆曲线上的某点的双倍点;模幂电路用于计算素数域和二元扩域的大数的模幂,优选使用R-L扫描快速幂算法实现;点的标量乘电路用于计算素数域和二元扩域椭圆曲线点的多倍点问题,优选使用L-R扫描法调用点的加法和点的倍乘算法实现;模逆电路用于计算素数域和二元扩域中的元素的逆元素。 参阅图1,本实施例中,协处理器还包括片上总线从机接口。片上总线从机接口用于输入操作数、计算参数和操作命令,输出计算结果和标志信号。协处理器和处理器通过片上总线从机接口进行数据传输。处理器向协处理器写入计算参数后,再向协处理器对应工作寄存器写指令,使能计算,在计算完成后,从协处理器中预设的存储区域取回计算结果。 参阅图6,示出了协处理器的应用场景,PC机通过JTAG连接到FPGA开发板,烧录FPGA电路固件和处理器执行的程序;处理器的片上总线接口先连接到总线互联器的从接口上,配置总线上的主从设备均为一个,总线互联器上的主接口连接到外围总线转换器上,进而连接到协处理器的片上总线从接口,协处理器的高速时钟由片上总线时钟经锁相环倍频得到。协处理器内部的SRAM和FIFO使用FPGA上的资源实现。 本实施例中,令处理器执行一段包含了测试的输入参数和对应的调用协处理器的驱动函数,处理器通过执行测试程序,将相应数据通过片上总线送入协处理器中运算,运算完毕后取出放在自身的内存空间中,并按顺序打印到串口上,上位机通过监听串口上的数据得到最终的计算结果,和标准用例进行比对。素数域256位椭圆曲线点乘的测试用例如表1所示。协处理器计算素数域256位椭圆曲线点乘的测试结果如图7所示。 表1
二元扩域257位椭圆曲线点乘的测试用例如表2所示,协处理器计算二元扩域257位椭圆曲线点乘的测试结果如图8所示。 表2
4096位RSA私钥运算的测试用例如表3所示,协处理器计算4096位RSA私钥运算的结果如图9所示。 表3
素数域和二元扩域模逆运算的测试用例如表4所示,协处理器计算素数域和二元扩域模逆运算的结果如图10所示,图中左侧为素数域模逆运算结果,右侧为二元扩域模逆运算结果。 表4
结合以上测试,本实施例中的协处理器,工作在100MHz的高速时钟和25MHz的APB总线时钟下时,执行一次素数域256位椭圆曲线的点乘运算耗时约30ms,执行一次二元扩域257位椭圆曲线的点乘运算耗时约21.4ms,执行一次4096位RSA私钥运算耗时约744.4ms,执行一次4096位公钥运算耗时约5.8ms,具有极快的处理速度。 本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。