基于随机梯度下降算法的高铁接触网目标的检测方法
文献发布时间:2023-06-19 19:07:35
技术领域
本申请涉及高铁技术领域,涉及对高铁接触网检测图像处理技术,尤其涉及一种基于随机梯度下降算法的高铁接触网目标的检测方法。
背景技术
接触网是电气化铁路牵引供电系统的重要组成部分,是架设在轨道上方为电力机车提供牵引电能的供电线路,承担高铁电气系统重要的电力传输任务。如果接触网出现故障,会对高铁的安全运营造成非常严重的影响,轻则大面积晚点,重则对人民生命财产造成大量损失,所以各铁路路局对接触网故障的预防和检修一直不遗余力地投入,而且不断在检测技术上进行技术改造。能够大量采集检测数据的高铁检修车辆的广泛使用,逐步替代了人工巡视的巡检方式。
使用专用设备采集数据,带来的问题是检测得到的数据量海量增加。因此,例如发明专利申请202011031247.1基于AI算法的高铁接触网设备巡检方法及系统,其中提出了采用了AI算法对这些巡检图片数据进行处理,降低工作人员的工作量,提高检测工作的实时性,同时提升了故障检测的准确率。
然而对于使用AI算法对接触网进行巡检检测图像的处理过程中,随着数据集的增大,计算复杂度过高,导致模型训练过程异常缓慢。如果提高检修频率,那么所需处理的数据量更会成倍增加。因此,在保证检测准确性的前提下,提高检测效率是必须要考虑的问题。使用随机梯度下降算法可以在一定程度上降低计算成本与内存消耗,但是由于在随机采样的过程中积累了梯度方差,所以其收敛速度很慢,无法直接用于接触网巡检的检测图像处理,需要对随机梯度下降算法进行调整。
同时,对于高铁接触网检测,检修车辆获取的图像信息中,通过研究故障原因,可以发现其中具有多种故障类型,例如承力索断股、承力索烧伤、承力索互磨、电力连接线脱落、电力连接线散股等。而且,随着高铁接触网检修内容的改进,未来还可能增加新的故障检测内容。因此,对于高铁接触网检测,需要使用专用数据库提供训练集与测试集样本,该专用数据库中包含的数据均为过往检测工作中所积累的真实图像数据,这些图像数据均已进行人工标注。
公开于本申请背景技术部分的信息仅仅旨在加深对本申请的一般背景技术的理解,而不应当被视为承认或以任何形式暗示该信息构成已为本领域技术人员所公知的现有技术。
发明内容
针对现有技术中存在的不足,本申请的一个或多个实施例提供了一种基于随机梯度下降算法的高铁接触网目标的检测方法,有效提高了高铁接触网检测图像的故障识别效率和识别准确度。
基于随机梯度下降算法的高铁接触网目标的检测方法,包括如下步骤:
步骤S1、从高铁接触网故障检测图像数据库中按待检测的故障类型提取图像数据;
步骤S2、对提取的所述图像数据进行预处理,得到预处理数据;
步骤S3、根据改进的随机梯度下降算法建立的深度网络模型对所述预处理数据进行特征提取;
所述改进的随机梯度下降算法中,先使用梯度下降快的学习率参数,再使用通用的随机梯度下降学习率参数进行计算;
步骤S4,利用提取的特征对接收的高铁接触网检测图像进行分析。
在一种可选的实施方式中,步骤S3所述改进的随机梯度下降算法中,具体计算过程如下:
输入值:
1)初始化,k,
2)
3)
4)
5)进行判断,如果k>1,且参数条件满足
在一种可选的实施方式中,步骤S1中,步骤S1中,提取图像数据是按照高铁接触网目标同样的检测位置进行故障类型选取,例如选取承力索位置的一种或多种故障,或电力连接线位置的一种或多种故障。
在一种可选的实施方式中,步骤S2中,对提取图像数据进行预处理,包括得到预设尺寸的图像;进一步的,预设尺寸的图像大小为256×256,或128×128,或64×64像素等尺寸。
在一种可选的实施方式中,在步骤S2与步骤S3中间增加步骤S2.5、使用K均值聚类算法对预处理后的图像进行聚类;
优选的,K均值聚类算法的运算步骤如下:
给定的数据集合X包含了q个对象
第1步,初始化c个聚类中心
第2步,计算每个对象到每个聚类中心的欧氏距离,计算方法为
第3步,重新计算确定每个类簇的中心,
第4步,重复第2步、第3步,直至类簇的中心保持稳定不再发生变化。
在一种可选的实施方式中,步骤S4为在线实时传送高铁接触网检测图像,通过无线或有线方式传输到计算设备上进行图像处理。
在一种可选的实施方式中,计算设备为终端或者服务器,或者同时使用终端与服务器。
在一种可选的实施方式中,增加步骤S5,在检测发现故障后,发送故障位置信息和故障类型信息给维修站点。
本发明采用以上技术方案与现有技术相比,具有以下技术效果:
(1)采用专用的高铁接触网故障检测图像数据库,提高了检测准确率;
(2)高铁接触网故障检测图像数据库中的故障类型分类基于实际检测需求,当具有新的故障种类和检测需求时,可以添加新的故障种类图像数据,扩展检测范围;
(3)使用改进的随机梯度下降算法,有针对性地提高高铁接触网故障检测的准确度和检测效率,避免了通用随机梯度下降算法的低效,也没有出现学习率震荡和无法收敛的情况;
(4)增加K均值聚类算法,提高了检测效率;
(5)找到了更加适用于高铁接触网故障检测的人工智能算法,满足高铁巡检的自动化、实时性、高准确度要求。
附图说明
图1是本发明高铁接触网故障检测的流程图;
图2是使用通用随机梯度下降算法的损失曲线图;
图3是本发明使用改进的随机梯度下降算法的损失曲线图。
具体实施方式
为使本申请实施例的目的、技术方案和优点更加清楚,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
下面以具体的实施例对本申请的技术方案进行详细说明。下面这几个具体的实施例可以相互结合,对于相同或相似的概念或过程可能在某些实施例不再赘述。
可以理解的是,本实施例的该基于改进的随机梯度价下降算法的图像识别方法及装置可以是在终端上执行的,也可以是在服务器上执行,还可以由终端和服务器共同执行的。以上举例不应理解为对本申请的限制。
实施例1
随着高铁接触网目标进行故障检测对于检测效率与检测准确度的高标准要求,和检测图像数据量的成倍增长,需要对进行检测数据处理的人工智能算法进行改进。本申请实施例提供一种基于随机梯度下降算法的高铁接触网目标的检测方法。
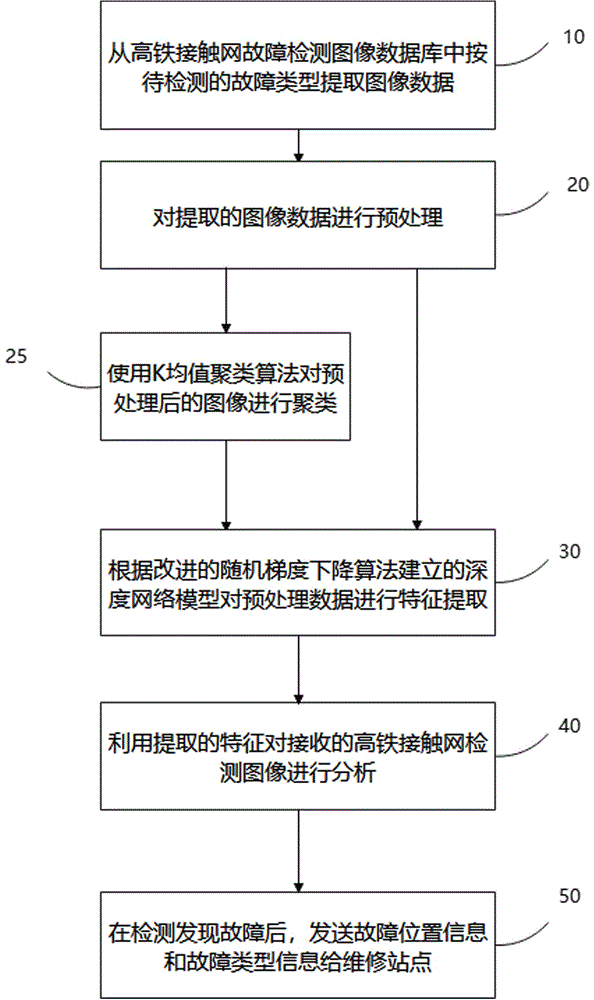
图1是本发明高铁接触网故障检测的流程图,如图1所示,所述方法包括:
步骤S1、从高铁接触网故障检测图像数据库中按待检测的故障类型提取图像数据(10);
步骤S2、对提取的所述图像数据进行预处理,得到预处理数据(20);
步骤S2.5、使用K均值聚类算法对预处理后的图像进行聚类(25);
步骤S3、根据改进的随机梯度下降算法建立的深度网络模型对预处理数据进行特征提取(30);
步骤S4、利用提取的特征对接收的高铁接触网检测图像进行分析(40)。
步骤S5、在检测发现故障后,发送故障位置信息和故障类型信息给维修站点(50)。
其中,步骤S3改进的随机梯度下降算法中,具体计算过程如下:
输入值:
1)初始化,k,
2)
3)
4)
5)进行判断,如果k>1,且参数条件满足
步骤S1中,提取图像数据是按照高铁接触网目标同样的检测位置进行故障类型选取,选取检测位置为承力索,故障类型为承力索断股。
步骤S2中,对提取图像数据进行预处理,得到预设尺寸大小为256×256的图像。
步骤S2.5中,使用K均值聚类算法对预处理后的图像进行聚类;
K均值聚类算法的运算步骤如下:
给定的数据集合X包含了q个对象
第1步,初始化c个聚类中心
第2步,计算每个对象到每个聚类中心的欧氏距离,计算方法为
第3步,重新计算确定每个类簇的中心,
第4步,重复第2步、第3步,直至类簇的中心保持稳定不再发生变化。
在使用K均值聚类算法进行聚类后,直接使用通用随机梯度下降算法对高铁接触网故障检测图像数据库中的测试图像进行缺陷识别,达到94.8%的识别准确率,检测速度达到的每秒帧数(Frame Per Second,FPS)12FPS左右。图2是使用通用随机梯度下降算法的损失曲线图。
通过对高铁接触网故障检测图像数据库中的测试图像进行缺陷识别,达到98.9%的识别率。检测速度为21FPS左右。图3是使用改进的随机梯度下降算法的损失曲线图。
实施例2
在不使用K均值聚类算法进行聚类的情况下进行缺陷检测。具体过程为:
步骤S1、从高铁接触网故障检测图像数据库中按待检测的故障类型提取图像数据(10);
步骤S2、对提取的所述图像数据进行预处理,得到预处理数据(20);
步骤S3、根据改进的随机梯度下降算法建立的深度网络模型对预处理数据进行特征提取(30);
步骤S4、利用提取的特征对接收的高铁接触网检测图像进行分析(40)。
步骤S5、在检测发现故障后,发送故障位置信息和故障类型信息给维修站点(50)。
其中,步骤S3改进的随机梯度下降算法中,具体计算过程如下:
输入值:
1)初始化,k,
2)
3)
4)
5)进行判断,如果k>1,且参数条件满足
步骤S1中,提取图像数据是按照高铁接触网目标同样的检测位置进行故障类型选取,选取检测位置为承力索,故障类型为承力索断股。
步骤S2中,对提取图像数据进行预处理,得到预设尺寸大小为256×256的图像。
通过对高铁接触网故障检测图像数据库中的测试图像进行缺陷识别,达到98.5%的识别准确率。检测速度为18FPS左右。可见,不使用K均值聚类算法进行聚类会降低识别准确率与检测速度,但是仍然可以得到较为满意的检测结果。
注意,除非另有直接说明,否则本说明书(包含任何所附权利要求、摘要和附图)中所揭示的所有特征皆可由用于达到相同、等效或类似目的的可替代特征来替换。因此,除非另有明确说明,否则所公开的每一个特征仅是一组等效或类似特征的一个示例。在使用到的情况下,进一步地、较优地、更进一步地和更优地是在前述实施例基础上进行另一实施例阐述得简单起头,该进一步地、较优地、更进一步地或更优地后带的内容与前述实施例的结合作为另一实施例的完整构成。在同一实施例后带的若干个进一步地、较优地、更进一步地或更优的设置之间可任意组合的组成又一实施例。
本领域的技术人员应理解,上述描述及附图中所示的本发明的实施例只作为举例而并不限制本发明。本发明的目的已经完整并有效地实现。本发明的功能及结构原理已在实施例中展示和说明,在没有背离所述原理下,本发明的实施方式可以有任何变形或修改。
最后应说明的是:以上各实施例仅用以说明本申请的技术方案,而非对其限制;尽管参照前述各实施例对本申请进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本申请各实施例技术方案的范围。