一种用于证券化产品报告的关键信息智能提取方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及数据处理技术领域,具体来说是一种用于证券化产品报告的关键信息智能提取方法。
背景技术
随着资产证券化业务的发展,目前我国资产证券化业务的处理工作已逐渐由传统手工方式,转向由线上IT系统进行统一管理。在银行、券商、投资人等各个角色客户的使用证券化系统过程中,由于使用的业务人员很多,每个产品涵盖的基本信息也比较多,且每个业务人员想要维护和测算一个证券化产品之前,均需要先对照产品发行/募集说明书手动录入产品基本信息的一百多个字段到系统中,这是繁琐但极为重要的一个基础步骤。
由于录入指标多,且多个字段间有关联关系,又分别展示在不同菜单的页面,即使精简之后,也还需要涉及9个页面。在未发明智能提取方法之前,仅能依靠人工对照发行说明书逐个搜索对应字段,且需人工判断字段间的逻辑关系后一个个输入到页面,一般对业务非常熟悉的业务人员录完一个产品所有信息至少需要花费1个小时,而且还不能保证录入的准确性;而对于不熟悉业务或者不熟悉系统的业务人员录完一个产品就会花费更多的时间和精力,且极有可能出现录入误差。如果录入有误,再来返回逐个字段检查,便会浪费更多的时间和精力。鉴于之前依靠手工录入的方法稍显笨拙,且对业务人员的时间、精力、细心程度及能力要求较高,如有信息录入错误,极有可能不易察觉,导致后续测算结果有偏差。
因此,开发一个可以智能提取证券化产品披露报告关键信息的工具,能够一次性快速准确地将所有产品信息录入系统,满足业务需求,就显得极为重要且有实用价值。
发明内容
本发明的目的是为了解决现有技术中产品信息分散繁杂、手工录入耗费成本较高的缺陷,提供一种用于证券化产品报告的关键信息智能提取方法来解决上述问题。
为了实现上述目的,本发明的技术方案如下:
一种用于证券化产品报告的关键信息智能提取方法,包括以下步骤:
11)收集总结要提取的关键字段:根据系统录入的产品基本信息,将信息按业务内容进行划分模块,分为:立项基本信息、参与机构、资产池基本信息、日期信息、现金流归集表、支付顺序、交易结构图、基础资产总体信息、基础资产分布信息9个模块,共计68个字段;
12)根据说明书的目录初步定位关键信息所在位置区间:根据目录内容循环匹配模块关键词,首先确定提取的模块信息页码位置,再根据特殊情况进一步针对性处理;
13)Python搜集发行说明书中关键字段的取值:根据每一个模块的关键信息,逐个模块遍历查找所在位置区间的表格或者文本,批量循环匹配所有关键字段的原文信息,并对提取信息进行加工,输出系统所需格式内容;
14)特殊格式的信息处理:对于计算日、兑付日、计息日、持续购买日期描述格式的情况进行特别处理,输出系统所需格式的内容;
15)高亮关键词取值位置:定位到所提取的关键词在原文的位置,将原文描述进行高亮标识,并输出高亮后的文档;
16)输出智能识别结果:将识别的结果放在一个csv文件中进行集中输出,供JAVA开发人员直接调用存入系统库表中,形成jpg格式的交易结构图及基础资产总体信息和基础资产分布信息的csv表格。
所述收集总结要提取的关键字段包括以下步骤:
21)进行信息分类:根据系统中产品信息页面的模块及其展示字段,人工将提取信息归纳分为9大模块68个字段,分别为:立项基本信息、参与机构、资产池基本信息、日期信息、现金流归集表、支付顺序、交易结构图、基础资产总体信息、基础资产分布信息;
22)目录提取:采用机器学习中Tf-idf文本特征提取的方法,即使用sklearn库中的API,feature_extraction.text.TfidfVectorizer来对所有的产品发行说明书中的目录内容进行关键信息提取,综合21)步得到的信息内容,最终整合得到7个主要目录,分别为“参与机构简介”、“交易结构信息”、“现金流分配机制”、“现金流归集表”、“基础资产总体信息”、“日期信息”、“主定义表”;
23)编写入参文件:在所有发行说明书中的对应模块循环提取关键字段的文字描述,并将每个字段的多个描述语按照Python正则规则编写,用顿号分隔,写入入参文件。
所述根据说明书的目录初步定位关键信息所在位置区间包括以下步骤:
31)目录内容正则化:根据22)步中获取的目录内容,对目录下的关键标题按照正则规则编写,将7个目录均用正则规则进行处理;
32)目录识别:根据pdfplumber识别文档的文本信息,根据正则后的关键信息,按照re.compile('目录|第一章|第二章|第三章|\.{10}')、re.compile('F\-')、re.compile('目录|一、|二、|三、|2.1|3.1|\.{10}')规则搜寻匹配目录在文本中的位置,并根据31)中的关键信息来匹配模块对应的页码范围。
所述Python搜集发行说明书中关键字段的取值包括以下步骤:
41)文本/表格信息提取:根据pages[p].extract_tables()循环提取所有表格或者根据pages[p].extract_text()提取文本信息;
42)表格/文本格式清洗对特殊符号、空白、换行符进行清洗,按照行列循环清洗,清洗原理如:re.sub(r'|\n|【|】|s|f|p|c|\(|\)',”,text);
43)关键字段匹配:
使用正则匹配规则循环查询,若查询到内容,则对内容进行清洗整理后,存入结果变量中;
若未查询到信息或者查询信息有误,则该字段结果内容为空;
44)交易结构图处理:使用page.get_pixmap(matrix,alpha=False)将整页转化为图片后再采用cv2.imdecode()对图片切割;
45)现金流归集表、基础资产总体信息均采用表格形式进行提取。
所述特殊格式的信息处理包括以下步骤:
51)日期信息处理:
按照正则规则表达式,日期信息规则描述如下:
rule_0=re.compile(r'每年.{,1}\d{1,2}月\d{1,2}日')
rule_1=re.compile(r'每.{,5}年.{,5}每.{,5}月.{,3}最后一')
rule_2=re.compile(r'每.{,5}年.{,5}每.{,5}月(.*)\d{1,2}日')
rule_3=re.compile(r'每.{,5}年(.*)(\d{1,2}月).{,5}最后一')
rule_4=re.compile(r'每.{,5}年(.*)(\d{1,2}月)(.*)\{1,2}日')
rule_5=re.compile(r'每.{,7}月.{,3}最后一(.*)|所在月的上个月的最后一(.*)')
rule_6=re.compile(r'每.{,7}月.{,8}日|每.{,7}月.{,8}天')
rule_7=re.compile(r'(\d{1,2}月){1,3}.{,3}最后一(.*)')
rule_8=re.compile(r'(\d{1,2}月){1,3}.{,3}\d{1,2}日')
rule_9=re.compile(r'\d{4}年\d{1,2}月\d{1,2}日')
rule_10=re.compile(r'\d{4}-\d{1,2}-\d{1,2}')
rule_11=re.compile(r'\d{4}\/\d{1,2}\/\d{1,2}')
rule_12=re.compile(r'\d{4}\.\d{1,2}\.\d{1,2}')
根据以上规则,匹配出20个日期字段的取值,并对这些取值进一步采用NLP技术进行文本语义理解处理,若为单个确定的日期,如首个计算日,则日期格式最终处理为YYYY年MM月DD日,若为兑付日/计息日/计算日为序列的字段,则处理为:1、4、7、10日、26日形式;
52)支付顺序处理:根据所提取到的所有产品支付顺序描述语,通过机器学习文本特征信息提取的方法,得到所有支付项,并确定支付项词库;然后搭建支付顺序自动识别模型,最终得到每个产品的支付项及其对应的支付顺序。
所述高亮关键词取值位置包括以下步骤:
61)确定原文描述位置:在匹配到正确信息后,输出原文所在页数以及原文描述语到结果变量中,该结果与处理后的匹配结果存在不同的结果变量中;
62)反向匹配原文描述在文档中的位置:调用PyPDF2包中的PdfFileReader()和PdfFileWriter()函数,将反向匹配到原文内容的结果汇总输出,并按识别顺序进行排列;
63)高亮文本:调用fitz模块打开62)步骤的汇总文档并拆分成单页pdf,然后使用add_highlight_annot()函数循环高亮每一页中的每一段关键词对应的原文描述,最后将高亮后的页数转化为pdf文档输出。
有益效果
本发明的一种用于证券化产品报告的关键信息智能提取方法,与现有技术相比将原本耗费大量人力成本且容易出错的手工录入工作,进行灵活智能化提取,仅需要一键导入文件,即可实现快速识别、准确提取并正确展示产品基本信息。本发明一方面帮助业务人员节省更多的时间、精力;另一方面智能提取这项发明使得基础且繁杂的工作变得便捷快速,可以大大提高产品管理的效率。
附图说明
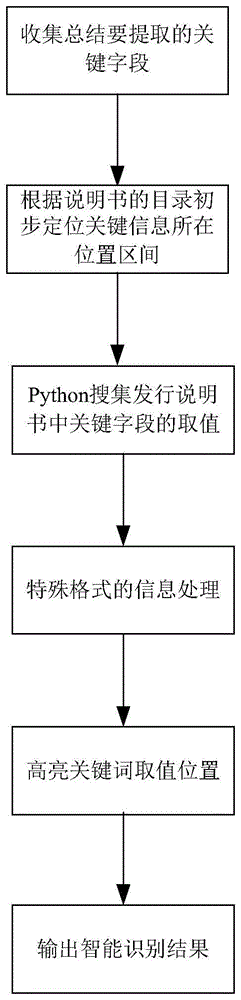
图1为本发明的方法顺序图。
具体实施方式
为使对本发明的结构特征及所达成的功效有更进一步的了解与认识,用以较佳的实施例及附图配合详细的说明,说明如下:
如图1所示,本发明所述的一种用于证券化产品报告的关键信息智能提取方法,包括以下步骤:
第一步,收集总结要提取的关键字段:根据系统录入的产品基本信息,将信息按业务内容进行划分模块,分为:立项基本信息、参与机构、资产池基本信息、日期信息、现金流归集表、支付顺序、交易结构图、基础资产总体信息、基础资产分布信息9个模块,共计68个字段。
(1)进行信息分类:由于产品发行说明书的页数较多,且信息分布较为分散,无法采用全篇内容一次性识别,因此根据系统中产品信息页面的模块及其展示字段,可以人工将提取信息归纳分为9大模块68个字段,分别为:立项基本信息、参与机构、资产池基本信息、日期信息、现金流归集表、支付顺序、交易结构图、基础资产总体信息、基础资产分布信息。
(2)目录提取:由于所有搜集到的产品发行说明书中的目录存在多种格式及描述,因此首先采用机器学习中Tf-idf文本特征提取的方法,也即使用sklearn库中的API,feature_extraction.text.TfidfVectorizer来对所有的产品发行说明书中的目录内容进行关键信息提取,综合第一步得到的信息内容,最终整合得到7个主要目录,分别为“参与机构简介”、“交易结构信息”、“现金流分配机制”、“现金流归集表”、“基础资产总体信息”、“日期信息”、“主定义表”。
(3)编写入参文件:在所有发行说明书中的对应模块循环提取关键字段的文字描述,并将每个字段的多个描述语按照Python正则规则编写,用顿号分隔,写入入参文件。
第二步,根据说明书的目录初步定位关键信息所在位置区间:根据目录内容循环匹配模块关键词,来首先确定需要提取的模块信息大概页码位置,再根据特殊情况进一步针对性处理。
(1)目录内容正则化:根据上一步中获取的目录内容,对目录下的关键标题按照正则规则编写,比如:交易结构信息目录下对应的关键内容,可能是“交易结构信息”、“交易结构示意图”、“交易结构基础”、“交易结构\.{5}”、“交.结构.交.概述”、“交易结构及”、“交易文件”等其中的一种描述。按此规律将7个目录均用正则规则进行处理。
(2)目录识别:根据pdfplumber识别文档的文本信息,根据正则后的关键信息,按照re.compile('目录|第一章|第二章|第三章|\.{10}')、re.compile('F\-')、re.compile('目录|一、|二、|三、|2.1|3.1|\.{10}')等规则搜寻匹配目录在文本中的位置,并根据(1)步中的关键信息来匹配模块对应的页码范围。对于特殊的格式,可以对页码进行适当的增减。
第三步,Python搜集发行说明书中关键字段的取值:根据每一个模块的关键信息,逐个模块遍历查找所在位置区间的表格或者文本,批量循环匹配所有关键字段的原文信息,并对提取信息进行加工,输出系统所需格式内容。
(1)文本/表格信息提取:步骤2中已经确定模块所在位置,则本步骤首先在页码范围内,根据pages[p].extract_tables()循环提取所有表格或者根据pages[p].extract_text()提取文本信息。对于不同的字段,有些通过表格提取更方便,而有些则文本提取更佳。
(2)表格/文本格式清洗:需要对特殊符号、空白、换行符等情况进行清洗,
一般按照行列循环清洗,清洗原理如:re.sub(r'|\n|【|】|s|f|p|c|\(|\)',”,text)。
(3)关键字段匹配:一般过程为:使用正则匹配规则循环查询,若查询到内容,则对内容进行清洗整理后,存入结果变量中;若未查询到信息或者查询信息有误,则该字段结果内容为空。以“兑付日”字段为例,属于日期信息模块,在入参文件中,兑付日的可能描述语有:支付日、兑付日、支付日\t、兑付日/T.{,1}日、支付日/T.{,1}日。调用re.compile()函数,将所有描述语进行正则化,在清洗后的日期信息文本中通过for语句循环遍历所有日期关键词的所有描述语,查询其在文本中的描述,如匹配到“兑付日”的描述语为“每月的26日”,则兑付日匹配成功;如果匹配内容未出现日期、数字等内容或者匹配结果为空,则为无效匹配,结果为空。其余关键词识别过程参考该字段。
(4)交易结构图处理:交易结构图较为特殊,由于有些交易结构图是一张图片,有些不是图片格式,因此要确认交易图的上下限,使用page.get_pixmap(matrix,alpha=False)将整页转化为图片后再采用cv2.imdecode()对图片切割。现金流归集表、基础资产总体信息均采用表格形式进行提取。
第四步,特殊格式的信息处理:对于计算日、兑付日、计息日、持续购买日期等描述格式较多的情况,进行特别处理,输出系统所需格式的内容。
(1)日期信息处理:由于日期信息的描述语格式较多。有些是日期格式,有些则为文字描述。按照正则规则表达式,常见的日期信息规则描述有:
rule_0=re.compile(r'每年.{,1}\d{1,2}月\d{1,2}日')
rule_1=re.compile(r'每.{,5}年.{,5}每.{,5}月.{,3}最后一')
rule_2=re.compile(r'每.{,5}年.{,5}每.{,5}月(.*)\d{1,2}日')
rule_3=re.compile(r'每.{,5}年(.*)(\d{1,2}月).{,5}最后一')
rule_4=re.compile(r'每.{,5}年(.*)(\d{1,2}月)(.*)\{1,2}日')
rule_5=re.compile(r'每.{,7}月.{,3}最后一(.*)|所在月的上个月的最后一(.*)')
rule_6=re.compile(r'每.{,7}月.{,8}日|每.{,7}月.{,8}天')
rule_7=re.compile(r'(\d{1,2}月){1,3}.{,3}最后一(.*)')
rule_8=re.compile(r'(\d{1,2}月){1,3}.{,3}\d{1,2}日')
rule_9=re.compile(r'\d{4}年\d{1,2}月\d{1,2}日')
rule_10=re.compile(r'\d{4}-\d{1,2}-\d{1,2}')
rule_11=re.compile(r'\d{4}\/\d{1,2}\/\d{1,2}')
rule_12=re.compile(r'\d{4}\.\d{1,2}\.\d{1,2}')
根据以上规则,匹配出20个日期字段的取值,并对这些取值进一步采用NLP技术进行文本语义理解处理,若为单个确定的日期,如首个计算日,则日期格式最终处理为YYYY年MM月DD日,若为兑付日/计息日/计算日等为序列的字段,则处理为:1、4、7、10月26日等类似形式。
(2)支付顺序处理:由于支付顺序均为大段文字描述,最终需要提炼出支付项以及对应顺序。因此首先要根据所提取到的所有产品支付顺序描述语,通过机器学习文本特征信息提取的方法,得到所有支付项,并确定支付项词库;然后搭建支付顺序自动识别模型,最终得到每个产品的支付项及其对应的支付顺序。
第五步,高亮关键词取值位置:定位到所提取的关键词在原文的位置,将原文描述进行高亮标识,并输出高亮后的文档。
(1)确定原文描述位置:根据步骤3,在匹配到正确信息后,输出原文所在页数以及原文描述语到结果变量中,该结果与处理后的匹配结果存在不同的结果变量中。
(2)反向匹配原文描述在文档中的位置:调用PyPDF2包中的PdfFileReader()和PdfFileWriter()函数,将反向匹配到原文内容的结果汇总输出,并按识别顺序进行排列。
(3)高亮文本:调用fitz模块打开(2)步骤的汇总文档并拆分成单页pdf,然后使用add_highlight_annot()函数循环高亮每一页中的每一段关键词对应的原文描述。最后将高亮后的页数转化为pdf文档输出。
第六步,输出智能识别结果:将识别的结果放在一个csv文件中进行集中输出,供JAVA开发人员直接调用存入系统库表中,形成jpg格式的交易结构图及基础资产总体信息和基础资产分布信息的csv表格。
以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是本发明的原理,在不脱离本发明精神和范围的前提下本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明的范围内。本发明要求的保护范围由所附的权利要求书及其等同物界定。
- 一种勘察报告文本关键信息提取系统和提取方法
- 产品反馈信息的关键词提取方法及终端设备