一种基于时序卷积网络的简答题智能评阅算法
文献发布时间:2024-04-18 19:58:26
技术领域
本发明涉及自然语言处理技术领域,特别是涉及一种基于时序卷积网络的简答题智能评阅方法。
背景技术
主观题自动评阅是指借助于计算机和有关科学技术辅助人工完成对主观题作答内容的评分,提高阅卷效率,避免因主观因素导致的评分偏差,增加阅卷的公平公正性。一直以来,主观题自动评阅都是自然语言处理领域的一个热点及难点问题。付鹏斌等人提出了结合学科同义词与词向量的相似度评分算法,通过提取学科知识信息建立词典,并利用Word2vec模型训练词向量来构建语料库,基于词性提出了一种关键词提取和分配算法,以此计算语句相似度。但该方法根据不同的学科需要构建不同的词典和语料库,否则会出现准确度计算不高的问题;Yoon Kim等人提出TextCNN,利用多个不同大小的卷积核提取文本关键信息,再使用最大池化策略和全连接层提取特征,对文本特征具有一定的抽取能力,但其卷积和池化操作会丢失文本序列中的词汇顺序和位置信息等内容;Graves等人在LSTM的基础上提出了双向长短时记忆网络Bi-LSTM,其具有长时记忆的功能,可以更好地捕捉双向的语义依赖,能够提取一定的文本特征,但依然有局限性,无法实现对文本进行并行处理,也无法获得文本的深层语义信息;Shaojie Bai等人提出时序卷积网络TCN,时序卷积网络使用空洞卷积使其能够获取文本序列的全局信息,具有更灵活的感受野,并且设置了残差结构,使时序卷积网络更加具有泛化能力。尽管上述方法在简答题评阅中已经取得了一定的效果,但仍存在无法获取深层语义信息,泛化能力不强,评阅性能低等问题。
当前主观题评阅面临的挑战主要是简答题的评阅任务,简答题要求答题人对特定的知识点进行简要阐述,内容精简且上下文之间有很强的逻辑关系,这对评阅方法提取文本深层语义的能力有较高要求。为了有效解决简答题的自动评阅,要求能够对文本语义深层理解的问题。因此应当设计一个专门的模型用于简答题智能评阅,以有效提高模型评阅的性能。
发明内容
本发明的目的是针对现有技术中存在的技术缺陷,而提供一种基于时序卷积网络的简答题智能评阅模型。
本发明的另一个目的是,提供一种基于时序卷积网络的简答题智能评阅方法。
为实现本发明的目的所采用的技术方案是:
一种基于时序卷积网络的简答题智能评阅模型,包括特征编码层BERT模型、特征增强层模型、输出分类层模型,其中:
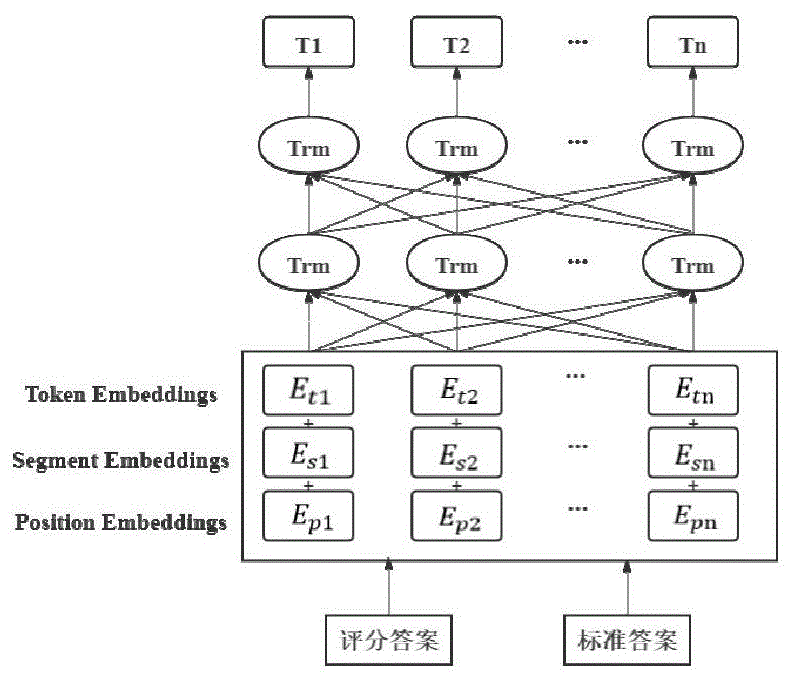
所述特征编码层BERT模型,将文本映射为含有文本结构特征的词向量序列,并根据单词上下文对单词进行编码以获得语义信息。首先,使用Google的预训练BERT词向量文件,将预处理后的评分答案和参考答案映射成高维的单词向量,段落向量和位置向量3种特征向量序列,其次,BERT将3种向量结合成一个特征向量序列S并对其进行编码,最后,将特征向量序列进行编码操作以获得文本的语义特征。
所述特征增强层模型,在特征提取层的基础上建立特征增强层,实现捕获深层语义特征的全局关系。特征增强层时序卷积网络TCN是一种特殊的一维卷积神经网络,相比于传统的LSTM等循环神经网络,可以有效捕获全局语义特征,记住更长的历史信息。时序卷积网络TCN采用膨胀卷积,一方面可以保证模型的输入与输出维度相同,另一面可以确保层与层之间具有因果关系,不会遗漏历史信息。
所述输出分类层模型,输出层的功能是整合深层语义特征并输出模型的预测得分。输出层由2个全连接网络组成,网络之间使用tanh作为激活函数连接。第1层全连接网络中每个节点与输出特征Y的所有节点连接,用于整合提取的特征;第2层全连接网络的输出由Softmax函数转换为各个分数类别的概率,概率最大的得分分类作为预测得分q(x)。
在上述技术方案中,预处理后的评分答案和参考答案映射成高维的单词向量,段落向量和位置向量3种特征向量序列,分别表示为:
E
其中,|len|表示序列最大长度,D表示向量维度,单词向量E
在上述技术方案中,BERT将3种向量结合成一个特征向量序列S并对其进行编码,计算方法可表示为:
S=E
其中,S∈R
在上述技术方案中,对于一维输入序列M∈R
其中,d表示膨胀因子,k表示卷积核大小。
在上述技术方案中,使用交叉熵损失函数作为模型的损失函数计算目标得分p(x)和预测得分q(x)之间的差距。
在上述技术方案中,交叉熵损失可由以下公式计算:
其中,p(x)为目标得分,q(x)预测得分。
本发明的另一方面,还包括一种基于时序卷积网络的简答题智能评阅方法,包括以下步骤:
步骤1,对评分答案和参考答案进行编码,在建立二者之间内在联系的同时提取深层次文本语义特征;
步骤2,将步骤1提取到的文本语义特征,使用时序卷积网络TCN模型捕获全局的语义关系;
步骤3,使用多个全连接网络对步骤2捕获的全局语义特征进行整合,输出模型的评分结果。
与现有技术相比,本发明的有益效果是:
1.本文发明使用Google的预训练语言模型BERT,捕获不同层级不同深度的特征,能够在预训练时获取句间关系并提供给下游较深的特征与涉及到句间关系的判断。
2.本文发明使用BERT使用多层Transformer的编码器结构Trm作为模型架构对特征进行编码,为了加快运算和收敛速度,解决梯度消失问题,Encoder使用Self-Attention和残差连接实现对文本的语义提取。
3.本发明使用交叉熵损失函数作为模型的损失函数计算目标得分p(x)和预测得分之间q(x)的差距,以进一步提高评阅准确率。
附图说明
图1为BERT结构;
图2为Trm结构;
图3为时序卷积网络TCN结构。
具体实施方式
以下结合具体实施例对本发明作进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
实施例1
本发明提出了一种基于时序卷积网络的简答题智能评阅方法。使用BERT编码结构有效利用单词的浅层文本特征和深层语义信息。
针对简答题评分任务,本文构建了一种基于时序卷积网络TCN并结合预训练语言模型BERT的简答题评阅模型(SA-TCN)。
首先,模型使用预训练语言模型BERT构成的特征编码层将经过预处理的评分答案和参考答案映射为高维特征向量,并结合为一个向量序列,然后对向量化的序列进行编码以获得评分答案和参考答案的语义特征。为了进一步对获取到的语义特征进行增强,使用特征增强层中的时序卷积网络TCN模型捕获全局的语义关系。最后,使用多个全连接网络对全局语义特征进行整合,输出模型的评分结果。模型的目标是计算出每一个分数类别的概率,并以概率最大的分数类别作为预测评分。
特征编码层BERT
为了有效利用单词的浅层文本特征和深层语义信息,特征编码层使用BERT将文本映射为含有文本结构特征的词向量序列,并根据单词上下文对单词进行编码以获得语义信息。研究表明预训练语言模型BERT在多种自然语言处理下游任务的性能优于GPT、ELMO等单向语言模型。相比于GPT等模型,BERT能够考虑到每个单词的上下文语境,实现深层双向的特征提取。
首先,使用Google的预训练BERT词向量文件,将预处理后的评分答案和参考答案映射成高维的单词向量,段落向量和位置向量3种特征向量序列,分别表示为E
S=E
最后,将特征向量序列S∈R
为了加快运算和收敛速度,解决梯度消失问题,Encoder使用Self-Attention和残差连接实现对文本的语义提取。每一层Encoder包括Self-Attention和前向反馈网络FFN两个子层,子层之间使用残差连接和层归一化操作进行连接。
对于输入序列X∈R
Sub1(X)=L_Norm(X+attention(X))(2)
Sub2(X)=L_Norm(X+FFN(X))(3)
Encoder(X)=Sub2(Sub1(X)))(4)
其中,L_Norm表示层归一化操作。
BERT中每一层Trm的输出S′都会被作为下一层Trm的输入S,计算方法如下:
S′=Trm(S)(5)
最后一层Trm的输出作为BERT编码后获得的深层语义特征T∈R
特征增强层
为了进一步增强语义特征,本文在特征提取层的基础上建立特征增强层,实现捕获深层语义特征的全局关系。
特征增强层时序卷积网络TCN是一种特殊的一维卷积神经网络,相比于传统的LSTM等循环神经网络,可以有效捕获全局语义特征,记住更长的历史信息。时序卷积网络TCN采用膨胀卷积,一方面可以保证模型的输入与输出维度相同,另一面可以确保层与层之间具有因果关系,不会遗漏历史信息。
对于一维输入序列M∈R
其中,d表示膨胀因子,k表示卷积核大小。时序卷积网络TCN还加入了归一化、残差连接、dropout等方法来提高模型精度,并将时序卷积网络TCN的输出特征Y作为增强特征传入下一层。
输出分类层与损失函数
输出层的功能是整合深层语义特征并输出模型的预测得分。输出层由2个全连接网络组成,网络之间使用tanh作为激活函数连接。第1层全连接网络中每个节点与输出特征Y的所有节点连接,用于整合提取的特征;第2层全连接网络的输出由Softmax函数转换为各个分数类别的概率,概率最大的得分分类作为预测得分q(x)。
本文使用交叉熵损失函数作为模型的损失函数计算目标得分p(x)和预测得分之间q(x)的差距,损失函数公式(7)所示。
本实施例中,模型的目标是计算出每一个分数类别的概率,并以概率最大的分数类别作为预测评分。
实施例2
一种基于时序卷积网络的简答题智能评阅方法,包括以下步骤:
步骤1,对评分答案和参考答案进行编码,在建立二者之间内在联系的同时提取深层次文本语义特征;
步骤2,将步骤1提取到的文本语义特征,使用时序卷积网络TCN模型捕获全局的语义关系;
步骤3,使用多个全连接网络对步骤2捕获的全局语义特征进行整合,输出模型的评分结果。
再进行进一步的应用,通过基于时序卷积网络的简答题智能评阅算法构建一个简答题智能评阅系统。将写好的简答题答案传入简答题智能评阅系统,由后台终端的时序卷积网络的简答题智能评阅算法进行检测分析。
以上所述仅是本发明的优选实施方式,应当指出的是,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 一种基于时序卷积网络算法的空气质量预测方法
- 基于注意力机制时序卷积网络算法的危重症死亡预测方法