基于蜂群学习的交通拥堵预测方法、系统、设备及介质
文献发布时间:2024-04-18 19:58:26
技术领域
本发明涉及蜂群学习技术领域,特别是涉及一种基于蜂群学习的交通拥堵预测方法、系统、设备及介质。
背景技术
现在的车辆都配备了车载传感器,能够实时收集各种交通数据,如交通流量、车速和路况等,可以使用这些数据进行交通预测模型训练,实现后续交通拥堵预测。然而,传统的集中式机器学习方法在处理大规模数据时面临着一些挑战。首先,集中式机器学习需要将所有的原始数据收集到中心服务器进行训练和模型合并,这可能涉及大量的数据传输和存储需求,而且可能涉及到隐私和安全的问题。此外,一些数据拥有者可能不愿意共享其敏感数据,限制了集中式机器方法的可行性。其次,集中式机器方法无法适应分布式环境中的数据变化和异构性。在分布式环境中,不同参与方节点的数据分布、数量和质量可能存在差异,导致集中式模型难以适应不同数据特点和变化。
为了克服这些问题,蜂群学习应运而生。蜂群学习是一种去中心化的机器学习框架,利用边缘计算和点对点网络技术,在保护隐私数据的同时,实现了安全的模型合并和参数共享。它通过区块链技术确保网络的可信性,并提供了更高级别的数据安全和防护能力,使得参与者能够安全地合作进行机器学习任务,它允许在保护数据隐私的同时,对分散在不同地点的数据进行模型训练和更新。在蜂群学习中,参与方节点(如设备、传感器或边缘节点)在本地进行模型训练,使用本地数据进行学习。然后,通过点对点网络和边缘计算技术,参与方节点之间共享模型参数,实现模型的合并和聚合。相比于集中式机器方法,蜂群学习具有以下优势:
1、数据隐私保护:蜂群学习通过本地化的学习和参数共享,避免了原始数据的集中共享。参与方节点只需共享部分模型参数,而无需共享原始数据,从而保护了数据的隐私和安全。
2、高效的通信和计算:蜂群学习通过点对点网络和边缘计算,减少了数据传输和计算的开销。参与方节点在本地进行模型训练,只共享模型参数,从而减少了通信量和计算负载。
3、自适应模型聚合:蜂群学习允许参与方节点根据其权重自适应地进行模型聚合。
但是上述传感器测量的数据直接与驾驶员和车辆的隐私相关,所以他们是非常敏感的,所以在进行交通模型训练时要保证这些数据的隐私,确保驾驶员和车辆的隐私的保护,同时实现更好的交通管理和驾驶体验。
但是因为蜂群学习存在以下缺点:
1、可扩展性:蜂群学习需要参与方节点之间的密集通信和协作,随着参与方节点数量的增加,系统的复杂性和管理难度也会增加。这可能对系统的可扩展性提出挑战,特别是在动态环境中,参与方节点的加入和退出可能会导致网络的不稳定。
2、数据异质性:在蜂群学习中,不同参与方节点的数据分布、规模和质量可能存在差异,这可能导致模型的偏倚或不准确。
3、安全和隐私风险:蜂群学习涉及参与方节点之间的模型参数共享和通信,这可能引入安全和隐私风险,未经适当保护的共享参数可能会受到恶意方的攻击,导致信息泄露或模型篡改的风险。
这些缺点会导致利用现有蜂群学习在进行数据处理和交通预测模型训练过程中的隐私和安全受到威胁。
发明内容
本发明的目的是提供一种基于蜂群学习的交通拥堵预测方法、系统、设备及介质,可提高在进行数据处理和交通预测模型训练过程中的隐私性和安全性。
为实现上述目的,本发明提供了如下方案:
一种基于蜂群学习的交通拥堵预测方法,包括:
以车辆作为蜂群网络中的参与方节点,根据所述蜂群网络中各所述参与方节点的交通数据集的大小,确定各所述参与方节点本地模型的鲁棒性值;所述交通数据集的大小为所述交通数据集中数据量的总数;
在当前聚合轮数下,根据上一聚合轮数下各所述参与方节点的本地数据可信度以及各所述参与方节点本地模型的鲁棒性值,得到当前聚合轮数下各所述参与方节点的本地数据可信度;
根据当前聚合轮数下的机器学习评价指标,得到当前聚合轮数下各所述参与方节点本地模型的可信度;所述机器学习评价指标包括:真正例、假正例和假反例;
根据上一聚合轮数下各所述参与方节点的本地数据可信度、上一聚合轮数下各所述参与方节点本地模型的可信度以及上一聚合轮数下各所述参与方节点在各所述参与方节点对应的交通数据集的损失函数,得到当前聚合轮数下各所述参与方节点的本地模型训练评估权重;
采用本地化差分隐私技术对当前聚合轮数的局部模型的模型参数进行加噪得到当前聚合轮数下的加噪局部模型;
根据当前聚合轮数的局部模型、当前聚合轮数下各所述参与方节点的本地模型训练评估权重以及当前聚合轮数下的加噪局部模型,得到下一聚合轮数下的局部模型;
判断当前聚合轮数是否达到设定聚合轮数,得到第一判断结果;
若所述第一判断结果为是,则确定下一聚合轮数下的局部模型为交通预测模型,所述交通预测模型用于预测交通拥堵情况;
若所述第一判断结果为否,则更新聚合轮数,进入下次聚合。
可选的,根据所述蜂群网络中各所述参与方节点的交通数据集的大小,确定各所述参与方节点本地模型的鲁棒性值,具体包括:
对于任意一个参与方节点N
可选的,根据上一聚合轮数下各所述参与方节点的本地数据可信度以及各所述参与方节点本地模型的鲁棒性值,得到当前聚合轮数下各所述参与方节点的本地数据可信度,具体包括:
对于任意一个参与方节点N
可选的,根据当前聚合轮数下的机器学习评价指标,得到当前聚合轮数下各所述参与方节点本地模型的可信度,具体包括:
对于任意一个参与方节点N
可选的,根据上一聚合轮数下各所述参与方节点的本地数据可信度、上一聚合轮数下各所述参与方节点本地模型的可信度以及上一聚合轮数下各所述参与方节点在各所述参与方节点对应的交通数据集的损失函数,得到当前聚合轮数下各所述参与方节点的本地模型训练评估权重,具体包括:
对于任意一个参与方节点N
计算第i次聚合轮数下参与方节点N
可选的,根据当前聚合轮数的局部模型、当前聚合轮数下各所述参与方节点的本地模型训练评估权重以及当前聚合轮数下的加噪局部模型,得到下一聚合轮数下的局部模型,具体包括:
根据公式
一种基于蜂群学习的交通拥堵预测系统,包括:
鲁棒性值计算模块,以车辆作为蜂群网络中的参与方节点,根据所述蜂群网络中各所述参与方节点的交通数据集的大小,确定各所述参与方节点本地模型的鲁棒性值;所述交通数据集的大小为所述交通数据集中数据量的总数;
本地数据可信度计算模块,用于在当前聚合轮数下,根据上一聚合轮数下各所述参与方节点的本地数据可信度以及各所述参与方节点本地模型的鲁棒性值,得到当前聚合轮数下各所述参与方节点的本地数据可信度;
本地模型可信度计算模块,用于根据当前聚合轮数下的机器学习评价指标,得到当前聚合轮数下各所述参与方节点本地模型的可信度;所述机器学习评价指标包括:真正例、假正例和假反例;
本地模型训练评估权重计算模块,用于根据上一聚合轮数下各所述参与方节点的本地数据可信度、上一聚合轮数下各所述参与方节点本地模型的可信度以及上一聚合轮数下各所述参与方节点在各所述参与方节点对应的交通数据集的损失函数,得到当前聚合轮数下各所述参与方节点的本地模型训练评估权重;
本地化差分隐私模块,用于采用本地化差分隐私技术对当前聚合轮数的局部模型的模型参数进行加噪得到当前聚合轮数下的加噪局部模型;
局部模型更新模块,用于根据当前聚合轮数的局部模型、当前聚合轮数下各所述参与方节点的本地模型训练评估权重以及当前聚合轮数下的加噪局部模型,得到下一聚合轮数下的局部模型;
判断模块,用于判断当前聚合轮数是否达到设定聚合轮数,得到第一判断结果;
交通预测模型确定模块,用于若所述第一判断结果为是,则确定下一聚合轮数下的局部模型为交通预测模型,所述交通预测模型用于预测交通拥堵情况;
迭代模块,用于若所述第一判断结果为否,则更新聚合轮数,进入下次聚合。
可选的,所述鲁棒性值计算模块,具体包括:
鲁棒性值计算单元,用于对于任意一个参与方节点N
一种电子设备,包括:
存储器和处理器,所述存储器用于存储计算机程序,所述处理器运行所述计算机程序以使所述电子设备执行根据上述所述的基于蜂群学习的交通拥堵预测方法。
一种计算机可读存储介质,其存储有计算机程序,所述计算机程序被处理器执行时实现上述所述的基于蜂群学习的交通拥堵预测方法。
根据本发明提供的具体实施例,本发明公开了以下技术效果:
以车辆作为蜂群网络中的参与方节点,根据蜂群网络中各参与方节点的交通数据集的大小,确定各参与方节点本地模型的鲁棒性值;在当前聚合轮数下,根据上一聚合轮数下各参与方节点的本地数据可信度以及各参与方节点本地模型的鲁棒性值,得到当前聚合轮数下各参与方节点的本地数据可信度;根据当前聚合轮数下的机器学习评价指标,得到当前聚合轮数下各参与方节点本地模型的可信度;根据上一聚合轮数下各参与方节点的本地数据可信度、上一聚合轮数下各参与方节点本地模型的可信度以及上一聚合轮数下各参与方节点在各参与方节点对应的交通数据集的损失函数,得到当前聚合轮数下各参与方节点的本地模型训练评估权重;采用本地化差分隐私技术对当前聚合轮数的局部模型的模型参数进行加噪得到当前聚合轮数下的加噪局部模型;根据当前聚合轮数的局部模型、当前聚合轮数下各参与方节点的本地模型训练评估权重以及当前聚合轮数下的加噪局部模型,得到下一聚合轮数下的局部模型;判断当前聚合轮数是否达到设定聚合轮数,得到第一判断结果;若第一判断结果为是,则确定下一聚合轮数下的局部模型为交通预测模型,交通预测模型用于预测交通拥堵情况;若第一判断结果为否,则更新聚合轮数,进入下次聚合,本发明采用本地化差分隐私技术对当前聚合轮数的局部模型的模型参数进行加噪保护中间参数的隐私,可提高在进行数据处理和交通预测模型训练过程中的隐私性和安全性。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例提供的基于蜂群学习的交通拥堵预测方法的流程图;
图2为本发明实施例提供的基于蜂群学习的交通拥堵预测方法执行流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
本发明提供的基于蜂群学习的交通拥堵预测方法(1)在系统初始阶段,每个参与方节点都需要通过区块链智能合约注册。这个过程可以确保每个参与方节点身份的合法性,每个蜂群学习的参与方节点都被明确定义,只有被合法授权的参与方节点才能执行事务。每个参与方节点记录来自智能合约的信息,例如获取模型并在满足同步条件后立即执行本地训练。参与方节点注册区块链智能合约后不用上传本地数据,只需要上传本地数据摘要(数据类型、数据格式、数据大小等)到区块链记录。随后系统为参与方节点分发唯一标识ID。
(2)事务请求处理阶段,参与方节点向系统发送事务请求,如请求最新全局模型进行新一轮本地训练。事务请求记录在区块链上。对每个参与方节点的发起的事务进行审计,事务信息打包成块,并广播到全网进行验证,验证后添加到区块链系统中。
(3)蜂群学习阶段。Swarm应用程序编程API接口在节点之间进行参数交换,并在新一轮培训之前进行合并更新新模型。在最后一轮参数共享和聚合后,框架将检查是否达到了停止标准,如果达到该标准,则停止,否则返回继续培训。模型更新的过程中,采用本地化差分隐私对中间参数添加噪声来确保中间参数的隐私安全。系统根据本地模型训练质量以及可信度构成聚合权重进行自适应聚合。
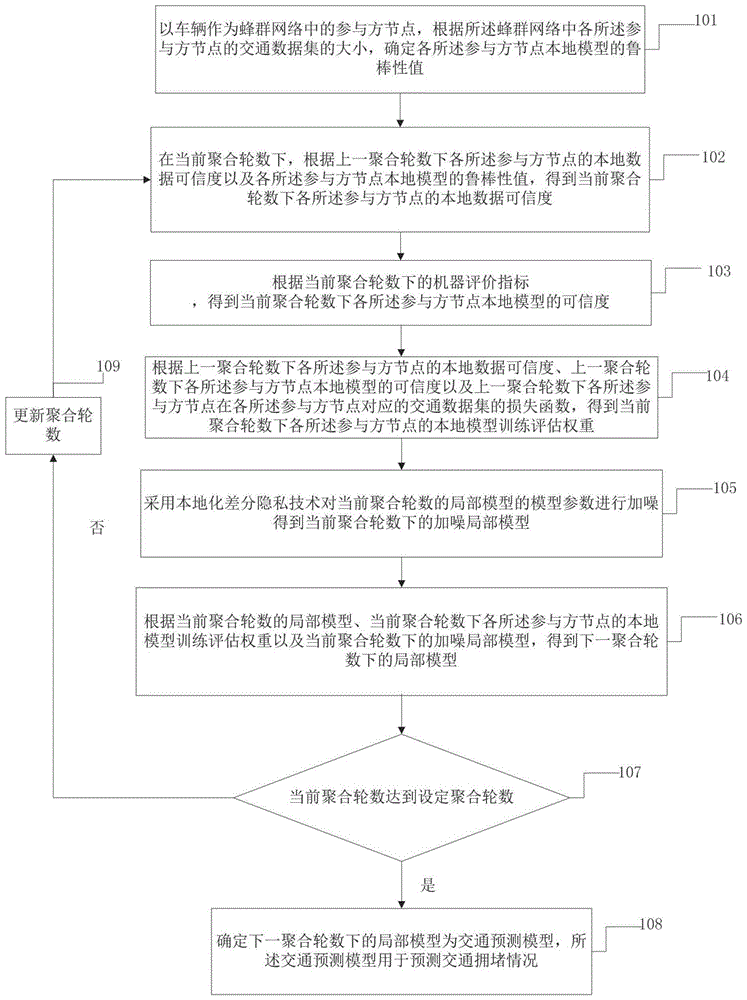
如图1所示,本发明实施例提供了一种基于蜂群学习的交通拥堵预测方法,包括:
步骤101:以车辆作为蜂群网络中的参与方节点,根据所述蜂群网络中各所述参与方节点的交通数据集的大小,确定各所述参与方节点本地模型的鲁棒性值。交通数据集指的是车辆传感器收集的交通数据,包含来自不同车辆或交通设备的数据,例如车辆传感器收集的车速、加速度、位置信息、交通信号灯状态、交通流量等。大小指的是这些数据的数据量的多少。这些数据将用于蜂群学习过程中各个车辆的本地训练。在SL中,训练过程中的数据集越大,模型的鲁棒性越好,所以,如果每个车辆的本地数据集足够丰富和多样化,蜂群学习算法将有更多机会学习到更全面和准确的交通模式和特征,从而提高模型的鲁棒性。因此,在蜂群网络SN的全局模型聚合时,在更大数据集上训练的模型可以被赋予更高的权重。
步骤102:在当前聚合轮数下,根据上一聚合轮数下各所述参与方节点的本地数据可信度以及各所述参与方节点本地模型的鲁棒性值,得到当前聚合轮数下各所述参与方节点的本地数据可信度。
步骤103:根据当前聚合轮数下的机器学习评价指标,得到当前聚合轮数下各所述参与方节点本地模型的可信度;所述机器学习评价指标包括:真正例、假正例和假反例。
步骤104:根据上一聚合轮数下各所述参与方节点的本地数据可信度、上一聚合轮数下各所述参与方节点本地模型的可信度以及上一聚合轮数下各所述参与方节点在各所述参与方节点对应的交通数据集的损失函数,得到当前聚合轮数下各所述参与方节点的本地模型训练评估权重。
步骤105:采用本地化差分隐私技术对当前聚合轮数的局部模型的模型参数进行加噪得到当前聚合轮数下的加噪局部模型。
步骤106:根据当前聚合轮数的局部模型、当前聚合轮数下各所述参与方节点的本地模型训练评估权重以及当前聚合轮数下的加噪局部模型,得到下一聚合轮数下的局部模型。
步骤107:判断当前聚合轮数是否达到设定聚合轮数,得到第一判断结果。
步骤108:若所述第一判断结果为是,则确定下一聚合轮数下的局部模型为交通预测模型,所述交通预测模型用于预测交通拥堵情况。
步骤109:若所述第一判断结果为否,则更新聚合轮数,进入下次聚合。
在实际应用中,交通预测模型可以用来进行:
1.交通拥堵预测:交通预测模型可以根据车辆传感器收集的交通数据,预测城市不同区域的交通流量和拥堵状况,这样的预测可以帮助驾驶员避开拥堵路段,提高交通效率,减少通勤时间。
2.路线优化:基于交通预测模型的预测结果,智能交通系统可以为驾驶员提供更优化的行车路线,这些路线将考虑交通流量、拥堵情况和预计的行车时间,帮助驾驶员选择最快捷的路径。
3.燃油效率优化:交通预测模型可以分析驾驶行为和车辆状况,提供燃油消耗的优化建议,帮助车主节约燃料成本并降低环境影响。
4.城市规划和交通管理:通过分析交通预测模型的数据,城市规划者和交通管理部门可以更好地了解交通需求和流动性,为城市规划和交通政策制定提供决策支持。
在实际应用中,再根据所述蜂群网络中各所述参与方节点的交通数据集的大小,确定各所述参与方节点本地模型的鲁棒性值之前还包括:
对各参与方节点进行智能合约注册得到各参与方节点的标识,后续根据标识确定各参与方是否可以执行模型训练步骤。
在实际应用中,根据所述蜂群网络中各所述参与方节点的交通数据集的大小,确定各所述参与方节点本地模型的鲁棒性值,具体包括:
对于任意一个参与方节点N
在实际应用中,根据上一聚合轮数下各所述参与方节点的本地数据可信度以及各所述参与方节点本地模型的鲁棒性值,得到当前聚合轮数下各所述参与方节点的本地数据可信度,具体包括:
对于任意一个参与方节点N
在实际应用中,根据当前聚合轮数下的机器学习评价指标,得到当前聚合轮数下各所述参与方节点本地模型的可信度,具体包括:
对于任意一个参与方节点N
在实际应用中,根据上一聚合轮数下各所述参与方节点的本地数据可信度、上一聚合轮数下各所述参与方节点本地模型的可信度以及上一聚合轮数下各所述参与方节点在各所述参与方节点对应的交通数据集的损失函数,得到当前聚合轮数下各所述参与方节点的本地模型训练评估权重,具体包括:
对于任意一个参与方节点N
在实际应用中,根据当前聚合轮数的局部模型、当前聚合轮数下各所述参与方节点的本地模型训练评估权重以及当前聚合轮数下的加噪局部模型,得到下一聚合轮数下的局部模型,具体包括:
根据公式
在实际应用中,采用本地化差分隐私技术对当前聚合轮数的局部模型的模型参数进行加噪得到当前聚合轮数下的加噪局部模型,具体为:采用本地化差分隐私技术根据公式
本发明有以下技术效果:
1.对于整个模型聚合添加的隐私预算成本,它可以拆分为每轮隐私预算添加之和,每次模型迭代满足ε-差分隐私,设总迭代轮次为T,总隐私预算为ε,则每轮迭代添加的隐私预算ε
2.为了确保蜂群学习的安全和可信性,本发明采用了区块链技术。区块链提供了去中心化的共识机制,确保参与方节点之间的交互是可信的,并防止潜在的欺诈行为。本发明通过区块链智能合约注册的方式,确保参与方节点的身份合法性和网络的可信性,通过区块链技术验证参与方节点的身份,并确保只有被合法授权的参与方节点才能执行事务,增强系统的安全性和抵御投毒攻击(投毒攻击(Poisoning Attack)是一种针对机器学习模型的安全威胁,旨在通过操纵或篡改训练数据,使得模型在推理或预测阶段产生错误的结果或被攻击者控制)的能力,防止恶意方通过恶意数据或操纵模型参数来破坏合作学习的结果,因此,本发明可以克服传统方法的局限性,并提供更高效、安全和隐私保护的机器学习任务协作方案。
3.本发明可以确保模型训练过程中的准确性和可信度,保护中间参数的隐私,确保参与方节点身份的合法性,以及防范投毒攻击的风险。
4.本发明使参与方节点能够根据其权重自适应地进行模型聚合,根据参与方节点的可信度和模型质量来动态调整权重,根据其权重自适应地进行模型聚合,以更好地反映不同参与方节点的贡献和数据特点。
5.差分隐私(Differential Privacy)是一种隐私保护技术,旨在在保护个体隐私的同时,允许对数据进行有限的、统计上意义的分析和推断。差分隐私的核心思想是通过在数据中引入适量的噪声,使得敏感个体的信息无法被准确推断出来。差分隐私通过在数据发布或查询过程中添加噪声,提供了一种数学保证,即使在攻击者具有除个体数据之外的背景知识和强大计算能力的情况下,也无法对特定个体的隐私信息进行准确的推断。拉普拉斯分布是一种特殊形式的指数分布,以为位置参数,以为尺度参数,其概率分布函数关于对称,并达到最大值。拉普拉斯机制通过向查询结果中添加噪声,使得原本确定的查询结果变成服从拉普拉斯分布的结果,若攻击者不能区分两个相邻节点查询结果的概率分布,就达到了差分隐私目的。本发明采用了本地化差分隐私技术,进行中间参数隐私保护,通过添加拉普拉斯噪声来保护中间参数的隐私,在共享模型参数时保护个体数据的隐私,防止恶意方通过参数推断敏感信息。
如图2所示,上述方法的具体执行流程包括:
步骤1:参与方节点用户注册智能合约,系统为参与方节点分发唯一标识ID。
步骤2:参与方节点向系统发送训练请求。
步骤3:系统批准训练请求后,参与方节点进行模型训练。
步骤4:根据公式(2)计算第i轮训练的本地数据可信度C
步骤5:根据公式(3)计算第i轮训练的模型可信度A
步骤6:根据公式(4)计算第i轮训练的参与方节点训练评估权重W
步骤7:根据公式(6),为中间参数加入拉普拉斯噪声Lap(),其中ε为隐私预算,隐私预算越小,隐私保护程度越高,该值可由用户自行定义。根据公式(5)进行自适应模型聚合并更新模型M(i)得到M(i+1)。
步骤8:如果模型达到停止条件或者聚合轮数达到最大轮则输出模型M(i+1),否则将重复步骤3~8,继续下一轮模型训练。
本发明还提供了一种实施例来证明上述方法可以抵御投毒攻击以及满足ε-差分隐私:
(1)可以抵御投毒攻击
假设参与方节点N
若N
现在,我们将比较N
化简如下:
根据指数函数的性质,且在i轮中的数据可信度和模型可信度由上轮决定,我们有:
即:
因为模型损失的增量ΔL
也就是说,被投毒攻击的参与方节点N
(2)满足ε-差分隐私
本地差分隐私方法满足ε-差分隐私,记为算法L,本发明记为算法A。
设S为算法L所有可能的输出范围集合,t为任意A输出范围中的一个,给定两个相邻的数据集D和D',二者相互之间至多有一条数据不同,即|DΔD'|≤1,有:
L()是本地差分隐私方法,概率Pr{*}由其里边的算法的控制,反映了隐私被披露的风险。A()为拉普拉斯噪声后的自适应蜂群学习模型聚合算法。隐私预算参数,ε表示隐私保护程度,因此加拉普拉斯噪声后的自适应蜂群学习模型聚合算法满足ε-差分隐私。
针对上述方法本发明实施例提供了一种基于蜂群学习的交通拥堵预测系统,包括:
鲁棒性值计算模块,以车辆作为蜂群网络中的参与方节点,根据所述蜂群网络中各所述参与方节点的交通数据集的大小,确定各所述参与方节点本地模型的鲁棒性值。
本地数据可信度计算模块,用于在当前聚合轮数下,根据上一聚合轮数下各所述参与方节点的本地数据可信度以及各所述参与方节点本地模型的鲁棒性值,得到当前聚合轮数下各所述参与方节点的本地数据可信度。
本地模型可信度计算模块,用于根据当前聚合轮数下的机器学习评价指标,得到当前聚合轮数下各所述参与方节点本地模型的可信度;所述机器学习评价指标包括:真正例、假正例和假反例。
本地模型训练评估权重计算模块,用于根据上一聚合轮数下各所述参与方节点的本地数据可信度、上一聚合轮数下各所述参与方节点本地模型的可信度以及上一聚合轮数下各所述参与方节点在各所述参与方节点对应的交通数据集的损失函数,得到当前聚合轮数下各所述参与方节点的本地模型训练评估权重。
本地化差分隐私模块,用于采用本地化差分隐私技术对当前聚合轮数的局部模型的模型参数进行加噪得到当前聚合轮数下的加噪局部模型。
局部模型更新模块,用于根据当前聚合轮数的局部模型、当前聚合轮数下各所述参与方节点的本地模型训练评估权重以及当前聚合轮数下的加噪局部模型,得到下一聚合轮数下的局部模型。
判断模块,用于判断当前聚合轮数是否达到设定聚合轮数,得到第一判断结果。
交通预测模型确定模块,用于若所述第一判断结果为是,则确定下一聚合轮数下的局部模型为交通预测模型,所述交通预测模型用于预测交通拥堵情况。
迭代模块,用于若所述第一判断结果为否,则更新聚合轮数,进入下次聚合。
在实际应用中,所述鲁棒性值计算模块,具体包括:
鲁棒性值计算单元,用于对于任意一个参与方节点N
本发明实施例还提供了一种电子设备,包括:
存储器和处理器,所述存储器用于存储计算机程序,所述处理器运行所述计算机程序以使所述电子设备执行根据上述所述的基于蜂群学习的交通拥堵预测方法。
本发明实施例还提供了一种计算机可读存储介质,其存储有计算机程序,所述计算机程序被处理器执行时实现上述所述的基于蜂群学习的交通拥堵预测方法。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的系统而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
- 一种基于机器学习预测内存故障的方法,设备及可读存储介质
- 一种基于交通拥堵传播模型的交通拥堵预测方法及系统
- 一种基于交通拥堵传播模型的交通拥堵预测方法及系统