神经网络加速器及神经网络加速方法、装置
文献发布时间:2024-04-18 19:58:53
技术领域
本发明涉及人工智能(Artificial Intelligence,AI)芯片技术领域,尤其涉及一种神经网络加速器及神经网络加速方法、装置。
背景技术
人工智能领域中,通过神经网络加速器来对神经网络进行加速计算已经得到广泛应用,但是,目前神经网络加速器的设计面临着主要的两个问题,即计算引擎(ProcessingEngine,PE)利用率低和数据带宽低,当数据带宽过低时,不能及时提供输入数据时,PE经常进入空闲状态,导致计算资源的利用率低。因此,如何实现数据带宽与计算资源的平衡是目前业界亟待解决的重要课题。
发明内容
本发明提供一种神经网络加速器及神经网络加速方法、装置,用以解决现有技术中数据带宽与计算资源不平衡的问题,实现数据带宽与计算资源的平衡。
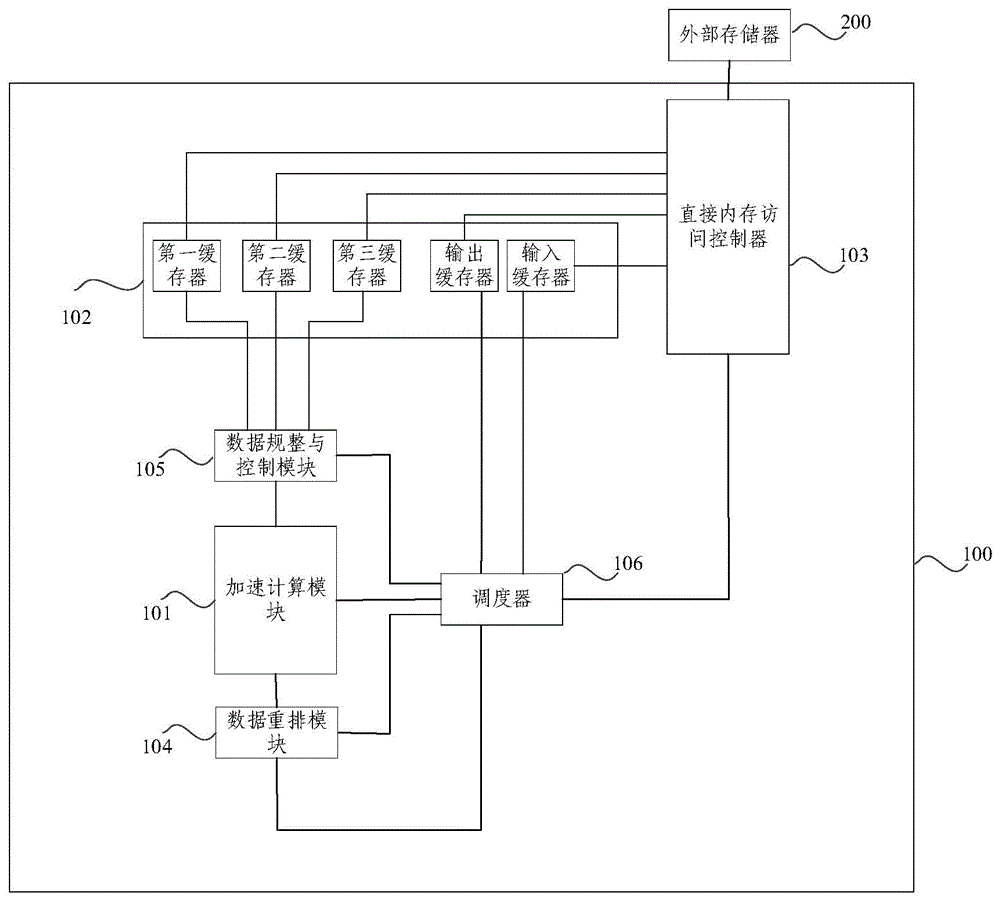
本发明提供一种神经网络加速器,包括:加速计算模块,直接内存访问控制器,数据重排模块以及数据规整与控制模块;所述加速计算模块包括多个计算单元;
所述直接内存访问控制器用于将外部存储器中按照数据排列顺序存储的神经网络当前层加速计算所需的目标数据连续读取并发送给所述数据规整与控制模块,所述目标数据的数据排列顺序是按照如下方式获得的:针对N通道*R行*C列的第一立体结构的目标数据,以所述神经网络当前层加速计算所需的F通道*E行*D列的第二立体结构为单位,按照所述第一立体结构中各个所述第二立体结构的第一排列顺序进行数据存储;针对每个所述第二立体结构,按照所述第二立体结构中所有数据的第二排列顺序进行数据存储;
所述数据规整与控制模块用于根据所述数据规整与控制模块的位宽、所述计算单元的位宽和卷积参数,基于接收的数据生成至少一个目标数据段,将每个所述目标数据段分发到所述加速计算模块中;
所述加速计算模块用于基于至少部分所述计算单元对来自所述数据规整与控制模块的所述目标数据段进行加速计算,并输出所述计算单元的计算结果至所述数据重排模块;
所述数据重排模块用于将各所述计算单元的计算结果按照神经网络下一层的加速计算所需的数据排列顺序合并以作为所述下一层的加速计算的输入。
根据本发明提供的一种神经网络加速器,所述目标数据段的数据长度与所述计算单元的位宽和所述卷积参数相匹配,所述目标数据段的数据长度为第一数据长度;所述数据规整与控制模块具体用于:
缓存所述接收的数据,所述接收的数据的数据长度小于或者等于所述数据规整与控制模块的位宽;
以第二数据长度为单位每次从所述接收的数据中选择一个数据段,作为主数据段,直至所述接收的数据被选择完毕,所述第二数据长度为预先设置的数据长度;
当所述主数据段的数据长度小于所述第一数据长度时,获取第一拼接数据和第二拼接数据,所述第一拼接数据为预设的填充数据或者所述接收的数据中与所述主数据段的起始位置相邻的数据,所述第二拼接数据为预设的填充数据或者所述接收的数据中与所述主数据段的结束位置相邻的数据;将所述第一拼接数据、所述主数据段和所述第二拼接数据拼接,得到所述目标数据段;
当所述主数据段的数据长度等于所述第一数据长度时,将所述主数据段作为所述目标数据段;
将所述目标数据段分发到所述加速计算模块中。
根据本发明提供的一种神经网络加速器,所述数据重排模块,具体用于:
收集各所述计算单元的计算结果并存储到第一组存储空间中的不同存储空间;
按照所述下一层的加速计算所需的数据排列顺序,为第二组存储空间的各存储空间,分别从所述第一组存储空间中选择一个相应的所述计算单元的计算结果进行存储,以得到所述下一层的加速计算所需的数据排列顺序。
根据本发明提供的一种神经网络加速器,所述计算单元包括第一乘积累加模块以及第二乘积累加模块;
所述第一乘积累加模块用于基于来自所述数据规整与控制模块的行方向的L+(x-1)个特征数据以及x个权重数据进行并行乘积累加计算,所述并行乘积累加计算包括按顺序依次选择x个权重数据中的每个权重数据作为当前计算的权重数据W[i],i的取值包括0~x-1,W[i]表示当前计算的权重数据为x个权重数据中第i+1个权重数据,并执行如下计算操作:计算L+(x-1)个特征数据中第i+1个特征数据到第i+L个特征数据分别与W[i]的乘积,并将计算的每个乘积分别累加到对应的第一中间存储器中;其中,x表示卷积核的大小参数;
所述第二乘积累加模块用于基于来自所述数据规整与控制模块的一个通道方向的K个特征数据以及K个权重数据进行串行乘积累加计算,所述串行乘积累加计算包括按顺序依次选择K个权重数据中的每个权重数据作为当前计算的权重数据W[j],j的取值包括0~K-1,W[j]表示当前计算的权重数据为K个权重数据中第j+1个权重数据,并执行如下进行计算操作:计算K个特征数据中第j+1个特征数据与W[j]的乘积,并将计算的乘积累加到第二中间存储器中;
所述计算单元用于采用所述第一乘积累加模块以及所述第二乘积累加模块中与所述当前层的加速计算匹配的一者进行乘积累加计算。
根据本发明提供的一种神经网络加速器,所述目标数据的数据排列顺序的获得方式具体包括:
以所述第二立体结构为单位,对所述第一立体结构的所述目标数据进行分块,得到Z1*Z2*Z3个所述第二立体结构;当所述第一立体结构的部分数据不足以形成所述第二立体结构时,在所述第一立体结构的部分数据的基础上进行数据填充以得到所述第二立体结构;其中,F不大于N,E不大于R,D不大于C,Z1的取值是N与F的比值向上取整,Z2的取值是R与E的比值向上取整,Z3的取值是C与D的比值向上取整;
按照所述第一立体结构对应的扫描方式,从各个所述第二立体结构中依次选择当前需要扫描的所述第二立体结构以得到所述第一排列顺序,并对当前选择的所述第二立体结构执行如下步骤:
按照所述第二立体结构对应的扫描方式扫描所述第二立体结构内的数据进行存储以得到所述第二排列顺序。
根据本发明提供的一种神经网络加速器,所述第一排列顺序是所述目标数据中各所述第二立体结构按照通道方向、行方向和列方向的优先级顺序形成的排列顺序,其中的优先级顺序为以下顺序中的一种:行方向、列方向和通道方向;列方向、行方向和通道方向;通道方向、行方向和列方向;通道方向、列方向和行方向;行方向、通道方向和列方向;列方向、通道方向和行方向;
所述第二排列顺序是所述第二立体结构中各数据按照通道方向、行方向和列方向的优先级顺序形成的排列顺序,其中的优先级顺序为以下顺序中的一种:行方向、列方向和通道方向;列方向、行方向和通道方向;通道方向、行方向和列方向;通道方向、列方向和行方向;行方向、通道方向和列方向;列方向、通道方向和行方向。
根据本发明提供的一种神经网络加速器,还包括调度器;所述调度器分别与所述数据规整与控制模块、所述加速计算模块、所述数据重排模块和所述直接内存访问控制器相连,用于解析指令序列,并根据所述指令序列的解析结果协调所述数据规整与控制模块、所述加速计算模块、所述数据重排模块和所述直接内存访问控制器工作。
根据本发明提供的一种神经网络加速器,所述第二立体结构与神经网络的结构对应;和/或,所述第二立体结构中的数据被读取一次后完成需要参与的所有计算。
本发明还提供一种基于上述任一种所述的神经网络加速器的神经网络加速方法,包括:
直接内存访问控制器将外部存储器中按照数据排列顺序存储的神经网络当前层加速计算所需的目标数据连续读取并发送给数据规整与控制模块;
所述数据规整与控制模块根据所述数据规整与控制模块的位宽、计算单元的位宽和卷积参数,基于接收的数据生成至少一个目标数据段,将每个所述目标数据段分发到加速计算模块中;
所述加速计算模块基于至少部分计算单元对来自所述数据规整与控制模块的所述目标数据段进行加速计算,并输出所述计算单元的计算结果至所述数据重排模块;
所述数据重排模块将各所述计算单元的计算结果按照神经网络下一层的加速计算所需的数据排列顺序合并以作为所述下一层的加速计算的输入。
本发明还提供一种神经网络加速装置,包括外部存储器和如上述任一种所述的神经网络加速器。
本发明提供的神经网络加速器,由于外部存储器中可以对第一立体结构的数据格式的目标数据按照数据排列顺序存储,该数据排列顺序是按照如下方式获得的:针对N通道*R行*C列的第一立体结构的目标数据,以神经网络的加速计算所需的F通道*E行*D列的第二立体结构为单位,按照所述第一立体结构中各个所述第二立体结构的第一排列顺序进行数据存储;针对每个所述第二立体结构,按照所述第二立体结构中所有数据的第二排列顺序进行数据存储。神经网络加速器中的直接内存访问控制器可以将外部存储器中存储的神经网络当前层加速计算所需的目标数据连续读取并发送到数据规整与控制模块中,数据规整与控制模块可以根据所述数据规整与控制模块的位宽、所述计算单元的位宽和卷积参数,基于接收的数据生成至少一个目标数据段,将每个目标数据段分发到所述加速计算模块中,加速计算模块可以基于至少部分所述计算单元对来自所述数据规整与控制模块的各所述目标数据段进行加速计算,并输出各计算单元的计算结果至所述数据重排模块;所述数据重排模块可以将各计算单元的计算结果按照神经网络下一层的加速计算所需的数据排列顺序合并以作为所述下一层的加速计算的输入。如此,将神经网络当前层的数据读取并生成目标数据段,数据带宽最高,神经网络每一层的加速计算都采用合适的数据排列方式,完成数据高效交互,可以大大提升数据带宽能力,充分利用加速计算模块的计算资源,解决计算资源与数据带宽不平衡的问题,提高神经网络加速器整体性能,降低功耗。
附图说明
为了更清楚地说明本发明或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明提供的神经网络加速器的结构示意图之一;
图2是本发明提供的第一立体结构的示意图之一;
图3是本发明提供的第一立体结构和第二立体结构的示意图;
图4是本发明提供的第二立体结构的示意图之一;
图5是本发明提供的第二立体结构的示意图之二;
图6是本发明提供的第二立体结构的示意图之三;
图7是本发明提供的第二立体结构的示意图之四;
图8是本发明提供的第二立体结构的示意图之五;
图9是本发明提供的第二立体结构的示意图之六;
图10是本发明提供的神经网络加速器的结构示意图之二;
图11是本发明提供的神经网络加速器的结构示意图之三;
图12是本发明提供的神经网络加速器的结构示意图之四;
图13是本发明提供的神经网络加速器的结构示意图之五;
图14是本发明提供的神经网络加速器的结构示意图之六;
图15是本发明提供的神经网络加速方法的流程示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合本发明中的附图,对本发明中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
下面结合图1至图14描述本发明的神经网络加速器。
如图1所示,本实施例提供一种神经网络加速器100,包括:加速计算模块101,直接内存访问控制器103、数据重排模块104以及数据规整与控制模块105。加速计算模块101包括多个计算单元。
接内存访问控制器103用于将外部存储器中按照数据排列顺序存储的神经网络当前层加速计算所需的目标数据连续读取并发送给数据规整与控制模块105,目标数据的数据排列顺序是按照如下方式获得的:针对N通道*R行*C列的第一立体结构的目标数据,以神经网络当前层加速计算所需的F通道*E行*D列的第二立体结构为单位,按照第一立体结构中各个第二立体结构的第一排列顺序进行数据存储;针对每个第二立体结构,按照第二立体结构中所有数据的第二排列顺序进行数据存储。
数据规整与控制模块105用于根据数据规整与控制模块的位宽、计算单元的位宽和卷积参数,基于接收的数据生成至少一个目标数据段,将每个目标数据段分发到加速计算模块101中。
加速计算模块101用于基于至少部分计算单元对来自数据规整与控制模块105的目标数据段进行加速计算,并输出计算单元的计算结果至数据重排模块104。
数据重排模块104用于将各计算单元的计算结果按照神经网络下一层的加速计算所需的数据排列顺序合并以作为下一层的加速计算的输入。
本实施例的方案可以应用于图像处理领域,具体涉及人工智能图像处理类芯片技术领域,实现图像处理神经网络的推理加速。其中的目标数据可以是图像数据,示例性的,图像数据可以包括特征图数据,特征图数据中每个像素点的特征数据按一定顺序存储。
其中,数据规整与控制模块的位宽是数据规整与控制模块的接口的位宽。计算单元的位宽是计算单元的接口的位宽。卷积参数是神经网络当前层中的卷积计算的参数,可以包括卷积核的大小参数以及步长等等。
图1中,神经网络加速器100还包括缓存模块102,直接内存访问控制器103、数据重排模块104以及数据规整与控制模块105与缓存模块102相连。基于此,直接内存访问控制器103具体用于将外部存储器200中按照数据排列顺序存储的目标数据连续读取到缓存模块102中。数据规整与控制模块105接收的数据来自缓存模块102。数据重排模块104具体用于将各计算单元的计算结果按照神经网络下一层的加速计算所需的数据排列顺序合并,然后输出至缓存模块102以作为下一层的加速计算的输入。
实际应用中,外部存储器200可以但不限于是双倍速率同步动态随机存储器(Double DataRate Synchronous Dynamic Random Access Memory,DDRSDRAM),可以简称为DDR。神经网络输入层所需要输入的数据,包括特征图数据,可以存储在外部存储器200中。外部存储器200可以按照数据排列顺序进行数据存储。
实际应用中,可以对立体结构X的数据格式来扫描排序,X的数据量大小为N*R*C,如图2所示,N表示通道,R表示行,C表示列,其中,N、R和C均为正整数。X中的某个像素点记为Xn.r.c,表示第n个通道的第r行的第c列像素点。最后一行、最后一列或最后一通道可以通过end标记。
扫描数据时,可以先将一个通道的特征图数据扫描完之后,再扫下一个通道的特征图数据,即先列方向后行方向再通道方向的扫描方式,或者先行方向后列方向再通道方向的扫描方式,称作第一扫描方式。示例性的,按照如下扫描顺序:
第1个通道特征图数据的第1行:X1.1.1,X1.1.2,X1.1.3,……,X1.1.end,第1个通道特征图数据的第2行:X1.2.1,X1.2.2,……,X1.2.end,……,第1个通道特征图数据的最后1行:X1.end.1,X1.end.2,……,X1.end.end,第2个通道特征图数据的第1行:X2.1.1,X2.1.2,X2.1.3,……,X2.1.end,第2个通道特征图数据的第2行:X2.2.1,X2.2.2,……,X2.2.end,……,第2个通道特征图数据的最后1行:X2.end.1,X2.end.2,……,X2.end.end,……,最后1个通道特征图数据的最后1个像素点:Xend.end.end。这种扫描顺序可以理解为特征图优先扫描。需要说明的是,对于一个通道的特征图数据来说,由于按行观察和按列观察,仅仅会影响相应权重数据对应的顺序,因此,对于按特征图优先扫描的方式,既可以先沿行方向扫描再沿列方向扫描,也可以先沿列方向扫描再沿行方向扫描。存储时,可以按照扫描顺序进行数据存储。
或者,扫描数据时,也可以按先通道方向后列方向再行方向的扫描方式,或者,按先通道方向后行方向再列方向的扫描方式,称作第二扫描方式。例如,按照一定顺序先扫描所有通道的第1个像素点,再扫描所有通道的第2个像素点,依次进行扫描所有通道的第3、4、……个像素点,直至扫描完所有像素点,示例性的扫描顺序如下:
所有通道下特征图数据的第1行第1列数据:X1.1.1,X2.1.1,X3.1.1,……,Xend.1.1,所有通道下特征图数据的第1行第2列数据:X1.1.2,X2.1.2,X3.1.2,……,Xend.1.2,……,所有通道下特征图数据的第1行最后1列数据:X1.1.end,X2.1.end,……,Xend.1.end,所有通道下特征图数据的第2行第1列数据:X1.2.1,X2.2.1,……,Xend.2.1,所有通道下特征图数据的第2行第2列数据:X1.2.2,X2.2.2,……,Xend.2.2,……,所有通道下特征图数据的最后1行最后1列数据:X1.end.end,……,Xend.end.end。这种扫描顺序可以理解为通道优先扫描。
或者,扫描数据时,也可以按先列方向后通道方向再行方向的扫描方式,或者,也可以按先行方向后通道方向再列方向的扫描方式,称作第三扫描方式。例如,先扫描第1个通道的第1行像素点数据,再扫描其它通道的第1行像素点数据,接着扫描所有通道第2行像素点数据,直至扫描完所有像素点,示例性的扫描顺序为:
第1个通道下特征图数据的第1行:X1.1.1,X1.1.2,X1.1.3,……,X1.1.end,第2个通道下特征图数据的第1行:X2.1.1,X2.1.2,……,X2.1.end,……,最后1个通道下特征图数据的第1行:Xend.1.1,Xend.1.2,……,Xend.1.end,第1个通道下特征图数据的第2行:X1.2.1,X1.2.2,X1.2.3,……,X1.2.end,第2个通道下特征图数据的第2行:X2.2.1,X2.2.2,……,X2.2.end,……,最后1个通道下特征图数据的最后1行:Xend.end.1,Xend.end.2,……,Xend.end.end。这是一种混合型扫描顺序,即通道方向扫描在行方向和列方向之间进行。
本实施例中,外部存储器200中可以对第一立体结构的数据格式的目标数据按照数据排列顺序存储,该目标数据是获得神经网络输出侧的计算结果所需的全部数据。神经网络加速器100中的直接内存访问控制器103主要用于控制外部存储器200与神经网络加速器100中的缓存模块102的存储空间的数据存取,最大遵循外部存储器200的特性,完成数据高带宽搬运工作。神经网络加速器100中的直接内存访问控制器103可以与外部存储器200相连,将外部存储器200中存储的需要输入的神经网络的目标数据分批连续读取到缓存模块102中。缓存模块102可以是由多个缓存器形成的缓存阵列。缓存阵列中包括用于存储特征图数据的第一缓存器,用于存储权重数据的第二缓存器,用于存储偏置数据的第三缓存器。数据规整与控制模块105分别与第一缓存器、第二缓存器和第三缓存器相连。直接内存访问控制器103分别与第一缓存器、第二缓存器和第三缓存器相连。其中,特征图数据和权重数据是一个乘法中的两个乘数项,第一缓存器和第二缓存器中存储的数据可以互换,例如,也可以是特征图数据存储到第二缓存器,权重数据存储到第一缓存器,这在解决全连接计算时,可提高数据带宽。
目标数据的数据排列顺序是按照如下方式获得的:针对N通道*R行*C列的第一立体结构的目标数据,以神经网络的加速计算所需的F通道*E行*D列的第二立体结构为单位,按照第一立体结构中各个第二立体结构的第一排列顺序进行数据存储;针对每个第二立体结构,按照第二立体结构中所有数据的第二排列顺序进行数据存储。
示例性的,如图3所示,所述目标数据的数据排列顺序的获得方式具体包括:
以所述第二立体结构为单位,对所述第一立体结构的所述目标数据进行分块,得到Z1*Z2*Z3个所述第二立体结构;当所述第一立体结构的部分数据不足以形成所述第二立体结构时,在所述第一立体结构的部分数据的基础上进行数据填充以得到所述第二立体结构;其中,F不大于N,E不大于R,D不大于C,Z1的取值是N与F的比值向上取整,Z2的取值是R与E的比值向上取整,Z3的取值是C与D的比值向上取整;
按照所述第一立体结构对应的扫描方式,从各个所述第二立体结构中依次选择当前需要扫描的所述第二立体结构以得到所述第一排列顺序,并对当前选择的所述第二立体结构执行如下步骤:
按照所述第二立体结构对应的扫描方式扫描所述第二立体结构内的数据进行存储以得到所述第二排列顺序。
其中,D、E、F均为正整数,具体值可以根据实际需要设置。如此,将第一立体结构的数据按第二立体结构进行分块,得到需要的目标数据。
其中,第一排列顺序是目标数据中各第二立体结构按照通道方向、行方向和列方向的优先级顺序形成的排列顺序,其中的优先级顺序为以下顺序中的一种:行方向、列方向和通道方向;列方向、行方向和通道方向;通道方向、行方向和列方向;通道方向、列方向和行方向;行方向、通道方向和列方向;列方向、通道方向和行方向。第二排列顺序是第二立体结构中各数据按照通道方向、行方向和列方向的优先级顺序形成的排列顺序,其中的优先级顺序为以下顺序中的一种:行方向、列方向和通道方向;列方向、行方向和通道方向;通道方向、行方向和列方向;通道方向、列方向和行方向;行方向、通道方向和列方向;列方向、通道方向和行方向。
其中,第二立体结构是通过如下方式获得的:
其中,以所述第二立体结构为单位,对所述第一立体结构的所述目标数据进行分块时,可以采用以下任意数据分块格式进行分块;所述数据分块格式为特征图优先格式、通道优先格式或者混合格式;所述特征图优先格式可以是指根据F的取值为1、D的取值范围为1~C和E的取值范围均为1~R确定所述第二立体结构的格式;所述通道优先格式可以是指根据D和E的取值均为1且F的取值范围为1~N确定第二立体结构的格式;所述混合格式可以是指根据D的取值范围为1~C、F的取值范围为1~N且E的取值为1确定第二立体结构的格式;
按照数据分块格式对第一立体结构进行分块,得到第二立体结构。
按照特征图优先格式对第一立体结构进行分块时,如图4所示,可以按照特征图优先格式对第一立体结构依次进行分割,得到第二立体结构。示例性的,F=1,D=C,E=R,参见图5。对第一立体结构中的各第二立体结构,可以采用上述第一扫描方式进行扫描,得到的数据排列顺序为第一排列顺序。
按照通道优先格式对第一立体结构进行分块时,如图6所示,按照通道优先格式对第一立体结构进行分割,得到第二立体结构。示例性的,F=N,D=1,E=1,参见图7。对第一立体结构中的各第二立体结构,可以采用上述第二扫描方式进行扫描,得到的数据排列顺序为第一排列顺序。
按照混合格式对第一立体结构进行分块时,如图8所示,可以按照混合格式对第一立体结构进行分割,得到第二立体结构。示例性的,当F=N,D=C,E=1,参见图9。对第一立体结构中的各第二立体结构,可以采用上述第三扫描方式进行扫描,得到的数据排列顺序为第一排列顺序。
其中,第二立体结构与神经网络的结构对应;和/或,第二立体结构中的数据被读取一次后完成需要参与的所有计算。不同的神经网络的结构可以采用不同的第二立体结构。从而匹配实际的加速计算需求。实施中,从外部存储器读取的数据可以一次性完成需要参与的所有计算,如此,一次性用尽后无需读取第二次,从而可以进一步提高计算效率。
在每个第二立体结构下,按照第二立体结构中所有数据的第二排列顺序进行数据存储。在第二立体结构内部的各像素点,也可以采用上述第一扫描方式、第二扫描方式或者第三扫描方式进行扫描,得到的数据排列顺序为第二排列顺序。
可见,在第一立体结构中以第二立体结构为颗粒度,采用第一扫描方式、第二扫描方式或者第三扫描方式进行扫描形成第一排列顺序。在第二立体结构中以像素点为颗粒度,也可以采用第一扫描方式、第二扫描方式或者第三扫描方式进行扫描形成第二排列顺序。
数据规整与控制模块可以将外部存储器中通过数据分块格式、第二排列顺序和第一排列顺序得到的目标数据读取到加速计算模块中,加速计算模块中的计算单元可以采用并行乘积累加计算或者串行乘积累加计算进行卷积计算或者全连接计算。在一个时钟周期内,所有的乘法器都进行有效工作,有效工作是指输入的有效的特征数据和权重数据进行乘法计算。在一个时钟周期内,进行有效工作的乘法器的数量为并行度,例如可以并行计算1024个特征图数据与权重数据的乘积,1024个乘法器进行有效工作,则并行度为1024。计算单元的位宽是确定的,一般设为2^a(即2的a次方)bit,所以数据规整与控制模块要对接收的数据生成目标数据段从而将加速计算所需的数据适配到计算单元上,并采取匹配的方式加速计算。
神经网络加速器100中的数据重排模块104可以收集计算单元的计算结果并进行合并,由于当前层的计算结果的输出即为神经网络下一层的输入,可以根据下一层的输入所需的数据排列顺序进行数据合并,然后输出至外部存储器200。如果当前层不是神经网络的最后一层,则需要进行下一层的加速计算,因此,可以将当前层的计算结果作为下一层的加速计算的输入。如果当前层是神经网络的最后一层,将当前层的计算结果作为最终的计算结果输出至外部存储器200。这里,神经网络下一层的输入所需的数据排列顺序可以是采用第一扫描方式、第二扫描方式或者第三扫描方式得到的数据排列顺序。
针对不同神经网络层的结构,可以通过不同的数据排列顺序存储,如此方便数据一次性读取,一次性计算完毕,从而提高数据的有效利用。直接内存访问控制器访问外部存储器时,在连续地址下的访问才能达到最优效率。
如此,将当前层需要输入神经网络的数据读取并生成目标数据段,数据带宽最高,神经网络每一层的加速计算都采用合适的数据排列带宽,读取一次就完成所有计算,完成数据高效交互,可以大大提升数据带宽能力,充分利用加速计算模块的计算资源,解决计算资源与数据带宽不平衡的问题,提高神经网络加速器整体性能,降低功耗。
在示例性实施例中,如图1所示,神经网络加速器100还可以包括调度器106;调度器106分别与数据规整与控制模块105、加速计算模块101、数据重排模块104和直接内存访问控制器103相连,用于解析指令序列,并根据指令序列的解析结果协调数据规整与控制模块105、加速计算模块101、数据重排模块104和直接内存访问控制器103工作;
其中,指令序列可以是利用编译器根据神经网络的结构及数据地址空间划分生成的。权重数据也可以根据特征图计算方式离线重排。
缓存模块102还包括与直接内存访问控制器103相连的输入缓存器和输出缓存器。数据重排模块104可以通过调度器106与输出缓存器相连,将当前层的计算结果通过调度器106输出至输出缓存器并由直接内存访问控制器103写回外部存储器200。调度器106可以通过输入缓存器获取外部存储器200中的指令序列。
本实施例中,神经网络加速器100中设置有调度器106,可以根据指令序列合理调度数据规整与控制模块105、加速计算模块101、数据重排模块104和直接内存访问控制器103,从而提高处理效率。
在示例性实施例中,所述目标数据段的数据长度与所述计算单元的位宽和所述卷积参数相匹配,所述目标数据段的数据长度为第一数据长度,第一数据长度是预先设置的目标数据段的数据长度;所述数据规整与控制模块105具体用于:
缓存所述接收的数据,所述接收的数据的数据长度小于或者等于所述数据规整与控制模块的位宽;
以第二数据长度为单位每次从所述接收的数据中选择一个数据段,作为主数据段,直至所述接收的数据被选择完毕,所述第二数据长度为预先设置的数据长度;
当所述主数据段的数据长度小于所述第一数据长度时,获取第一拼接数据和第二拼接数据,所述第一拼接数据为预设的填充数据或者所述接收的数据中与所述主数据段的起始位置相邻的数据,所述第二拼接数据为预设的填充数据或者所述接收的数据中与所述主数据段的结束位置相邻的数据;将所述第一拼接数据、所述主数据段和所述第二拼接数据拼接,得到所述目标数据段;
当所述主数据段的数据长度等于所述第一数据长度时,将所述主数据段作为所述目标数据段;
将所述目标数据段分发到所述加速计算模块中。
例如,参见图10,数据规整与控制模块105包括数据缓存单元1051、第一数据选择单元1052、中间缓存单元1053、地址生成单元1054、第一拼接选择单元1055、第二拼接选择单元1056、第三拼接选择单元1057和数据输出单元1058;
其中,数据缓存单元1051用于缓存接收的数据;
数据输出单元1058用于生成并输出目标数据段;
地址生成单元用于为第一数据选择单元1052和第一拼接选择单元1055生成对应的数据地址;还用于当主数据段的数据长度小于第一数据长度时,为第一数据选择单元1052和第一拼接选择单元1055生成对应的数据地址的同时,为第二拼接选择单元1056和第三拼接选择单元1057生成对应的数据地址;
第一数据选择单元1052用于根据对应的数据地址,在一个时钟周期中,以第二数据长度为单位从数据缓存单元1051选择一个数据段并存储至中间缓存单元1053;
中间缓存单元1053用于存储填充数据以及来自第一数据选择单元1052的数据段;
第一拼接选择单元1055用于根据对应的数据地址从中间缓存单元1053中选择一个数据段作为主数据段并提供给数据输出单元1058;
第二拼接选择单元1056用于根据对应的数据地址从中间缓存单元1053中选择第一拼接数据并提供给数据输出单元1058;第一拼接数据为填充数据或者中间缓存单元1053中与主数据段的起始位置相邻的数据;
第三拼接选择单元1057用于根据对应的数据地址从中间缓存单元1053中选择第二拼接数据并提供给数据输出单元1058;第二拼接数据为填充数据或者中间缓存单元1053中与主数据段的结束位置相邻的数据。
其中的第一数据选择单元1052、第一拼接选择单元1055、第二拼接选择单元1056和第三拼接选择单元1057可以包括选通器。
数据缓存单元1051可以包括缓存器。中间缓存单元1053可以包括缓存器或者寄存器。
数据长度可以通过数据占用的字节表示。
以第一数据长度为10byte,第二数据长度为8byte举例来说,数据缓存单元1051接收的数据为64byte,第一数据选择单元1052可以通过8个时钟周期分时获取,每个时钟周期获取8byte的数据段并存储到中间缓存单元中,例如中间缓存单元中存储3个8byte的数据段,第一拼接选择单元1055可以获取中间的8byte的数据段作为主数据段提供给数据输出单元1058,第一拼接选择单元1055可以获取主数据段的起始位置相邻的8byte的数据段中1byte的数据提供给数据输出单元1058,第二拼接选择单元1056可以获取主数据段的结束位置相邻的8byte的数据段中1byte的数据提供给数据输出单元1058。数据输出单元1058将来自第二拼接选择单元1056的1byte数据、来自第一拼接选择单元1055的8byte的主数据段和来自第三拼接选择单元1057的1byte数据进行拼接得到10byte的目标数据段,将目标数据段发送给加速计算模块。
本实施例中,数据规整与控制模块可以结合数据规整与控制模块的位宽、计算单元的位宽和卷积参数,生成合适的目标数据段,从而提高资源利用率。
在示例性实施例中,如图11所示,计算单元包括第一乘积累加模块以及第二乘积累加模块;
第一乘积累加模块用于基于来自数据规整与控制模块的行方向的L+(x-1)个特征数据以及x个权重数据进行并行乘积累加计算,并行乘积累加计算包括按顺序依次选择x个权重数据中的每个权重数据作为当前计算的权重数据W[i],i的取值包括0~x-1,W[i]表示当前计算的权重数据为x个权重数据中第i+1个权重数据,并执行如下计算操作:计算L+(x-1)个特征数据中第i+1个特征数据到第i+L个特征数据分别与W[i]的乘积,并将计算的每个乘积分别累加到对应的第一中间存储器中;其中,x表示卷积核的大小参数,例如卷积核的大小为3*3,则x=3;L为正整数,L的具体数值可以根据实际需求设置;示例性的,L的取值为第二数据长度;
第二乘积累加模块用于基于来自数据规整与控制模块的一个通道方向的K个特征数据以及K个权重数据进行串行乘积累加计算,串行乘积累加计算包括按顺序依次选择K个权重数据中的每个权重数据作为当前计算的权重数据W[j],j的取值包括0~K-1,W[j]表示当前计算的权重数据为K个权重数据中第j+1个权重数据,并执行如下进行计算操作:计算K个特征数据中第j+1个特征数据与W[j]的乘积,并将计算的乘积累加到第二中间存储器中;K为正整数,K的具体数值可以根据实际需求设置;示例性的,K的取值为第二数据长度;
计算单元用于采用第一乘积累加模块以及第二乘积累加模块中与当前层的加速计算匹配的一者进行乘积累加计算。
实际应用中,如图12所示,加速计算模块101包括m*h个计算单元(PE),m个PE(图中以PE_1~PE_m示意)组成一个PE簇,图12中示意共h个PE簇,以PE_cluster_1~PE_cluster_h示意不同的PE簇。计算单元可以完成乘积累加计算,激活计算,池化,距离计算,实现矩阵累加,矩阵点乘等。计算单元在乘积累加计算时可根据配置采用第一乘积累加模块和第二乘积累加模块两种乘积累加模块中的一种。
例如加速计算模块中包括8个PE簇且每个PE簇包括8个PE,可以将10byte的目标数据段分发到8个PE簇,得到8个PE簇的计算结果。
以3*3卷积为例,当采用第一乘积累加模块时,数据规整与控制模块105下发L+2个特征数据Feature[L+1:0],为一张特征图一行中的L+2个特征数据。获取3个权重数据W[2:0],则有:
{
For i=0;i<3;i++;
mid_ram[L-1:0]=mid_ram[L-1:0]+Feature[i+L-1:i]*W[i]
}。
其中,mid_ram[L-1:0]表示第一中间存储器中存储的数据,Feature[i+L-1:i]表示第i+1个特征数据到第i+L个特征数据。
示例性的,数据规整与控制模块105下发10byte数据,为一张特征图一行中的10个特征数据Feature[9:0],则有:
{
For i=0;i<3;i++;
mid_ram[7:0]=mid_ram[7:0]+Feature[i+7:i]*W[i]
}。
举例来说,当采用第二乘积累加模块时,数据规整与控制模块105下发K个特征数据Feature[K-1:0],为特征图的一个像素点,通道方向K个特征数据。获取K个权重数据W[K-1:0],则有:
{
For j=0;j mid_ram=mid_ram+Feature[j]*W[j] }。 其中,mid_ram表示第二中间存储器中存储的数据。Feature[j]表示第j+1个特征数据。 示例性的,数据规整与控制模块105下发8个特征数据Feature[7:0],为特征图的一个像素点,通道方向8个特征数据,则有W[7:0],以及: { For j=0;j<8;j++; mid_ram=mid_ram+Feature[j]*W[j] }。 实际应用中,可以将目标数据段分发至计算单元,本实施例中,加速计算模块101中设置有两种乘积累加模块,可以根据需求选择其中一种匹配的乘积累加模块来进行目标数据段的加速计算,按通道优先扫描时可以用串行乘积累加模块计算,按特征图优先扫描时可以用并行乘积累加模块计算,效率更高。 在示例性实施例中,计算单元具体用于: 将输入的权重数据进行缓存; 利用选择器组中的输入选择器选择输入的特征数据进行缓存,或者利用选择器组中的移位控制器控制移位选择器将输入的特征数据移位并利用输入选择器选择移位的特征数据进行缓存; 利用乘法器组中每个乘法器计算对应缓存的特征数据和权重数据的乘积; 利用加器组中的并行累加器分别将每个乘法器的乘积并行累加或者利用加法器组中的串行累加器将所有乘法器的乘积串行累加,得到累加结果并输出。 示例性的,如图13所示,计算单元包括: 结果选择器1010、特征数据选择器组1011、特征寄存器组1012、权重寄存器组1013、乘法器组1014、乘积选择器组1015、第一加法器组1016、第二加法器组1017以及结果寄存器组1018。上述选择器组包括特征数据选择器组1011。 权重寄存器组1013包括P个权重寄存器,P为正整数。权重寄存器用于存储权重数据。图中以P=8示意,因此,包括权重寄存器W0、权重寄存器W1、权重寄存器W2,……,权重寄存器W7。 特征寄存器组1012包括P+x-1个特征寄存器,特征寄存器用于存储特征数据。图中以x=3示意,因此,包括特征寄存器F0、特征寄存器F1、特征寄存器F2,……,特征寄存器F9。 特征数据选择器组1011包括P+x-2个特征数据选择器,P+x-2个特征数据选择器与第1个至第P+x-2个特征寄存器一一对应。第p个特征数据选择器用于将接收的特征数据下发至第p个特征寄存器,此时特征数据选择器为输入选择器,还用于将第p+1个特征寄存器中的特征数据移位至第p个特征寄存器,此时特征数据选择器为移位选择器。图13所示状态下,左侧的特征数据选择器为第1个特征数据选择器。 乘法器组1014包括P个乘法器。P个乘法器与P个权重寄存器一一对应。P个乘法器与第1个至第P个特征寄存器一一对应。第q个乘法器用于计算第q个特征寄存器的特征数据与第q个权重寄存器的权重数据的乘积。q的取值为1~P。 乘积选择器组1015包括P个乘积选择器,P个乘积选择器与P个乘法器一一对应。第q个乘积选择器用于选择输出第q个乘法器的乘积或者输出0。在不需要将已有的累加结果清零的情况下,第q个乘积选择器选择输出第q个乘法器的乘积,在需要将已有的累加结果清零的情况下,第q个乘积选择器选择输出0。 第一加法器组1016包括P个第一加法器和P个清零选择器,P个第一加法器与P个乘积选择器一一对应,P个第一加法器与P个清零选择器一一对应。 结果寄存器组1018包括P个结果寄存器,P个结果寄存器与P个第一加法器一一对应,P个结果寄存器还与P个清零选择器一一对应。 第二加法器组1017包括((1/2)+(1/4)+(1/8)+···+(1/P))*P个第二加法器,第二加法器包括多个层级,第1个层级中第二加法器的数量为P/2,前一个层级中第二加法器的数量是后一个层级中第二加法器的数量的2倍,最后1个层级中第二加法器的数量为1。 第1个层级中每个第二加法器对应P个乘积选择器中的两个乘积选择器以将两个乘积选择器的输出相加。后一个层级中每个第二加法器对应前一个层级中的两个第二加法器以将两个第二加法器的输出相加。 结果选择器1010分别对应最后1个层级中第二加法器、第1个乘积选择器、第1个第一加法器。 最后1个层级中第二加法器将计算结果提供给结果选择器1010。结果选择器1010用于选择最后1个层级中第二加法器的计算结果或者选择第1个乘积选择器的输出,提供给第1个第一加法器。 以上特征数据选择器组1011、特征寄存器组1012、权重寄存器组1013、乘法器组1014、乘积选择器组1015、第一加法器组1016、结果选择器1010以及结果寄存器组1018形成并行乘积累加模块,即第一乘积累加模块,上述并行累加器包括乘积选择器组1015、第一加法器组1016、结果选择器1010以及结果寄存器组1018。采用并行乘积累加模块时,结果选择器1010选择接收第1个乘积选择器的输出提供给第1个第一加法器。第一加法器组1016中,每个清零选择器用于在不需要将已有的累加结果清零的情况下,选择对应的结果寄存器缓存的累加结果输出至对应的第一加法器,在需要将已有的累加结果清零的情况下,选择0输出至对应的第一加法器。每个第一加法器用于将对应的乘积选择器的输出与对应的清零选择器的输出进行累加并将累加结果缓存至对应的结果寄存器。 以上特征数据选择器组1011、特征寄存器组1012、权重寄存器组1013、乘法器组1014、乘积选择器组1015、第二加法器组1017、第1个结果寄存器、第1个清零选择器、第1个第一加法器以及结果选择器1010形成串行乘积累加模块,即第二乘积累加模块。这里,第二乘积累加模块与第一乘积累加模块共用部分结构,当然也可以不共用。上述串行累加器包括乘积选择器组1015、第二加法器组1017、第1个结果寄存器、第1个清零选择器、第1个第一加法器以及结果选择器1010。采用串行乘积累加模块时,结果选择器1010选择接收最后1个层级中第二加法器的计算结果提供给第1个第一加法器。第1个第一加法器用于将最后1个层级中第二加法器的计算结果与第1个清零选择器的输出进行累加并将累加结果缓存至第1个结果寄存器中。从而完成串行乘积累加。 本实施例中,通过特征寄存器的特征数据移位的方式进行乘积累加计算,可以实现多种卷积核的卷积运算,资源利用率更高。 在示例性实施例中,所述数据重排模块,具体用于: 收集各所述计算单元的计算结果并存储到第一组存储空间中的不同存储空间; 按照所述下一层的加速计算所需的数据排列顺序,为第二组存储空间的各存储空间,分别从所述第一组存储空间中选择一个相应的所述计算单元的计算结果进行存储,以得到所述下一层的加速计算所需的数据排列顺序。具体的,可以一次从第一组存储空间中选择一个计算单元的计算结果存储到第二组存储空间中相应的一个存储空间中,也可以一次从第一组存储空间中选择多个计算单元的计算结果存储到第二组存储空间中相应的多个存储空间中,直至完成数据重排,得到下一层的加速计算所需的数据排列顺序。 例如,参见图14,数据重排模块104包括数据收集缓存单元1041、第二数据选择单元1042和数据合并转换单元1043;数据收集缓存单元1041包括多个收集存储单元,以形成第一组存储空间;数据合并转换单元1043包括多个转换存储单元,以形成第二组存储空间; 数据收集缓存单元1041用于收集计算单元的计算结果存储到相应的收集存储单元中,不同的计算单元的计算结果对应不同的收集存储单元; 第二数据选择单元1042用于按照所述下一层的加速计算所需的数据排列顺序,分别为数据合并转换单元1043中每个转换存储单元选择一个相应的收集存储单元中存储的计算单元的计算结果并输出至数据合并转换单元1043;不同的收集存储单元对应选择不同的转换存储单元; 数据合并转换单元1043用于将收集存储单元中存储的计算单元的计算结果存储到相应的转换存储单元,并将各转换存储单元中存储的计算单元的计算结果合并输出。 其中的收集存储单元和转换存储单元可以是存储器。 本实施例中,通过将收集存储单元存储的计算结果的顺序,通过转换存储单元进行转换,快速实现了数据重排,得到下一层的加速计算所需的数据排列顺序。 下面基于图13所示的结构,以具体的神经网络举例说明。 示例性的,神经网络为VGG16网络,神经网络当前层加速计算所需的目标数据的数据排列方式采用第一扫描方式得到,而神经网络下一层所需的数据排列方式则采用第二扫描方式得到。基于此,数据规整与控制模块可将64byte(具体设计时DDR的接口位宽为64byte)特征数据分时获取,每个时钟周期获取8byte特征数据,并通过拼接获得10byte特征数据以广播至加速计算模块的8*64个计算单元中,计算单元通过移位的方式进行乘积累加计算,得到512byte的计算结果,数据重排模块收集512byte的计算结果后合并转换成采用第二扫描方式的数据排列顺序,得到8个64byte的计算结果。 当神经网络当前层加速计算所需的目标数据的数据排列方式采用第二扫描方式得到,而神经网络下一层所需的数据排列方式仍然采用第二扫描方式得到时,数据规整与控制模块可将64byte特征数据分时获取,每个时钟周期获取8byte特征数据以广播至加速计算模块的计算单元中,计算单元不进行移位,每个计算单元内部结果压缩成一个,按顺序得到共8个8byte的计算结果,数据重排模块等待收集共64byte的计算结果时,转换成采用第二扫描方式的数据排列顺序的64byte的计算结果。 示例性的,神经网络为MobileNetV2网络,神经网络当前层加速计算所需的目标数据的数据排列方式采用第二扫描方式得到,而神经网络下一层所需的数据排列方式则采用第三扫描方式得到。基于此,数据规整与控制模块可将64byte特征数据分时获取,每个时钟周期获取8byte特征数据以广播至加速计算模块的计算单元中,计算单元不进行移位,每个计算单元内部结果压缩成一个,按顺序得到共8个8byte共64byte的计算结果,数据重排模块等待收集共8个64byte的计算结果时,合并转换成采用第三扫描方式的数据排列顺序的计算结果。 当神经网络当前层加速计算所需的目标数据的数据排列方式采用第三扫描方式得到,而神经网络下一层所需的数据排列方式仍然采用第二扫描方式得到时,数据规整与控制模块可将64byte特征数据分时获取,每个时钟周期获取8byte特征数据,并通过拼接获得10byte特征数据以广播至加速计算模块的计算单元中,计算单元通过移位的方式进行乘积累加计算,得到64byte的计算结果,待数据重排模块收集8个64byte共512byte的计算结果后合并转换成采用第二扫描方式的数据排列顺序。 下面对本发明提供的神经网络加速方法进行描述,下文描述的神经网络加速方法与上文描述的神经网络加速装置可相互对应参照。 如图15所示,本实施例提供一种基于上述任一实施例所提供的神经网络加速器100的神经网络加速方法,包括: 步骤1501、直接内存访问控制器将外部存储器中按照数据排列顺序存储的神经网络当前层加速计算所需的目标数据连续读取并发送给数据规整与控制模块。 步骤1502、所述数据规整与控制模块根据所述数据规整与控制模块的位宽、计算单元的位宽和卷积参数,基于接收的数据生成至少一个目标数据段,将每个所述目标数据段分发到加速计算模块中。 步骤1503、所述加速计算模块基于至少部分计算单元对来自所述数据规整与控制模块的所述目标数据段进行加速计算,并输出所述计算单元的计算结果至所述数据重排模块。 步骤1504、所述数据重排模块将各所述计算单元的计算结果按照神经网络下一层的加速计算所需的数据排列顺序合并以作为所述下一层的加速计算的输入。 在示例性实施例中,所述目标数据段的数据长度与所述计算单元的位宽和所述卷积参数相匹配,所述目标数据段的数据长度为第一数据长度;所述数据规整与控制模块缓存所述接收的数据,所述接收的数据的数据长度小于或者等于所述数据规整与控制模块的位宽; 以第二数据长度为单位每次从所述接收的数据中选择一个数据段,作为主数据段,直至所述接收的数据被选择完毕,所述第二数据长度为预先设置的数据长度; 当所述主数据段的数据长度小于所述第一数据长度时,获取第一拼接数据和第二拼接数据,所述第一拼接数据为预设的填充数据或者所述接收的数据中与所述主数据段的起始位置相邻的数据,所述第二拼接数据为预设的填充数据或者所述接收的数据中与所述主数据段的结束位置相邻的数据;将所述第一拼接数据、所述主数据段和所述第二拼接数据拼接,得到所述目标数据段; 当所述主数据段的数据长度等于所述第一数据长度时,将所述主数据段作为所述目标数据段; 将所述目标数据段分发到所述加速计算模块中。 在示例性实施例中,所述数据重排模块收集各所述计算单元的计算结果并存储到第一组存储空间中的不同存储空间; 按照所述下一层的加速计算所需的数据排列顺序,为第二组存储空间的各存储空间,分别从所述第一组存储空间中选择一个相应的所述计算单元的计算结果进行存储,以得到所述下一层的加速计算所需的数据排列顺序。 在示例性实施例中,所述数据规整与控制模块包括数据缓存单元、第一数据选择单元、中间缓存单元、地址生成单元、第一拼接选择单元、第二拼接选择单元、第三拼接选择单元和数据输出单元; 其中,所述数据缓存单元缓存所述接收的数据; 所述数据输出单元生成并输出所述目标数据段; 其中,所述地址生成单元为所述第一数据选择单元和所述第一拼接选择单元生成对应的数据地址;当所述主数据段的数据长度小于所述第一数据长度时,为所述第一数据选择单元和所述第一拼接选择单元生成对应的数据地址的同时,为所述第二拼接选择单元和所述第三拼接选择单元生成对应的数据地址; 所述第一数据选择单元根据对应的数据地址,在一个时钟周期中,以第二数据长度为单位从所述数据缓存单元选择一个数据段并存储至所述中间缓存单元; 所述中间缓存单元存储填充数据以及来自所述数据选择单元的数据段; 所述第一拼接选择单元根据对应的数据地址从所述中间缓存单元中选择一个数据段作为所述主数据段并提供给所述数据输出单元; 所述第二拼接选择单元根据对应的数据地址从所述中间缓存单元中选择所述第一拼接数据并提供给所述数据输出单元;所述第一拼接数据为所述填充数据或者所述中间缓存单元中与所述主数据段的起始位置相邻的数据; 所述第三拼接选择单元根据对应的数据地址从所述中间缓存单元中选择所述第二拼接数据并提供给所述数据输出单元;所述第二拼接数据为所述填充数据或者所述中间缓存单元中与所述主数据段的结束位置相邻的数据。 在示例性实施例中,所述数据重排模块包括数据收集缓存单元、第二数据选择单元和数据合并转换单元;所述数据收集存储单元包括多个收集存储单元,以形成第一组存储空间;所述数据合并转换单元包括多个转换存储单元,以形成第二组存储空间; 所述数据收集缓存单元收集所述计算单元的计算结果存储到相应的所述收集存储单元中,不同的所述计算单元的计算结果对应不同的所述收集存储单元; 所述第二数据选择单元按照所述下一层的加速计算所需的数据排列顺序,分别为数据合并转换单元中每个转换存储单元选择一个相应的收集存储单元中存储的计算单元的计算结果并输出至数据合并转换单元;不同的收集存储单元对应选择不同的转换存储单元; 所述数据合并转换单元将所述收集存储单元中存储的所述计算单元的计算结果存储到相应的所述转换存储单元,并将各所述转换存储单元中存储的所述计算单元的计算结果合并输出。 在示例性实施例中,所述计算单元包括第一乘积累加模块以及第二乘积累加模块; 所述第一乘积累加模块基于来自所述数据规整与控制模块的行方向的L+(x-1)个特征数据以及x个权重数据进行并行乘积累加计算,所述并行乘积累加计算包括按顺序依次选择x个权重数据中的每个权重数据作为当前计算的权重数据W[i],i的取值包括0~x-1,W[i]表示当前计算的权重数据为x个权重数据中第i+1个权重数据,并执行如下计算操作:计算L+(x-1)个特征数据中第i+1个特征数据到第i+L个特征数据分别与W[i]的乘积,并将计算的每个乘积分别累加到对应的第一中间存储器中;其中,x表示卷积核的大小参数; 所述第二乘积累加模块基于来自所述数据规整与控制模块的一个通道方向的K个特征数据以及K个权重数据进行串行乘积累加计算,所述串行乘积累加计算包括按顺序依次选择K个权重数据中的每个权重数据作为当前计算的权重数据W[j],j的取值包括0~K-1,W[j]表示当前计算的权重数据为K个权重数据中第j+1个权重数据,并执行如下进行计算操作:计算K个特征数据中第j+1个特征数据与W[j]的乘积,并将计算的乘积累加到第二中间存储器中; 所述计算单元采用所述第一乘积累加模块以及所述第二乘积累加模块中与所述当前层的加速计算匹配的一者进行乘积累加计算。 在示例性实施例中,所述目标数据的数据排列顺序的获得方式具体包括: 以所述第二立体结构为单位,对所述第一立体结构的所述目标数据进行分块,得到Z1*Z2*Z3个所述第二立体结构;当所述第一立体结构的部分数据不足以形成所述第二立体结构时,在所述第一立体结构的部分数据的基础上进行数据填充以得到所述第二立体结构;其中,F不大于N,E不大于R,D不大于C,Z1的取值是N与F的比值向上取整,Z2的取值是R与E的比值向上取整,Z3的取值是C与D的比值向上取整; 按照所述第一立体结构对应的扫描方式,从各个所述第二立体结构中依次选择当前需要扫描的所述第二立体结构以得到所述第一排列顺序,并对当前选择的所述第二立体结构执行如下步骤: 按照所述第二立体结构对应的扫描方式扫描所述第二立体结构内的数据进行存储以得到所述第二排列顺序。 在示例性实施例中,所述第一排列顺序是所述目标数据中各所述第二立体结构按照通道方向、行方向和列方向的优先级顺序形成的排列顺序,其中的优先级顺序为以下顺序中的一种:行方向、列方向和通道方向;列方向、行方向和通道方向;通道方向、行方向和列方向;通道方向、列方向和行方向;行方向、通道方向和列方向;列方向、通道方向和行方向; 所述第二排列顺序是所述第二立体结构中各数据按照通道方向、行方向和列方向的优先级顺序形成的排列顺序,其中的优先级顺序为以下顺序中的一种:行方向、列方向和通道方向;列方向、行方向和通道方向;通道方向、行方向和列方向;通道方向、列方向和行方向;行方向、通道方向和列方向;列方向、通道方向和行方向。 在示例性实施例中,调度器根据所述指令序列的解析结果协调所述数据规整与控制模块、所述加速计算模块、所述数据重排模块和所述直接内存访问控制器工作。 在示例性实施例中,所述第二立体结构与神经网络的结构对应;和/或,所述第二立体结构中的数据被读取一次后完成需要参与的所有计算。 下面对本发明提供的神经网络加速装置进行描述,下文描述的神经网络加速装置与上文描述的神经网络加速器可相互对应参照。 本发明还提供一种神经网络加速装置,包括外部存储器200和上述任一实施例所提供的神经网络加速器100。 以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性的劳动的情况下,即可以理解并实施。 通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到各实施方式可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件。基于这样的理解,上述技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在计算机可读存储介质中,如ROM/RAM、磁碟、光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行各个实施例或者实施例的某些部分所述的方法。 最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。