一种智能电网稳定性预测方法
文献发布时间:2024-04-18 19:59:31
技术领域
本发明涉及智能电网技术领域,具体涉及一种智能电网稳定性预测方法。
背景技术
随着5G技术的快速发展和应用,5G赋能的智能电网相关业务迎来全面升级,生产经营效率大幅提升。 然而,在万物互联时代,海量设备的接入也给智能电网带来了严重的负担,智能电网的稳定性成为亟待解决的重要问题。近年来,各种基于机器学习(ML)和深度学习(DL)的方法被应用到智能电网的多个方面,但是多数场景是理想状态,其训练样本充足,不存在类失衡问题,但是在实际的智能电网系统中,不稳定状态的比例远远低于稳定状态,即存在大量的类失衡问题从而使在训练过程中可能会出现过拟合的情况。因为多数状态的样本占总样本的比例过大,少数状态的样本被忽略,分类器更倾向于多数状态。所以类不平衡问题导致分类器性能下降,导致无法正确预测智能电网的状态。
发明内容
1.所要解决的技术问题:
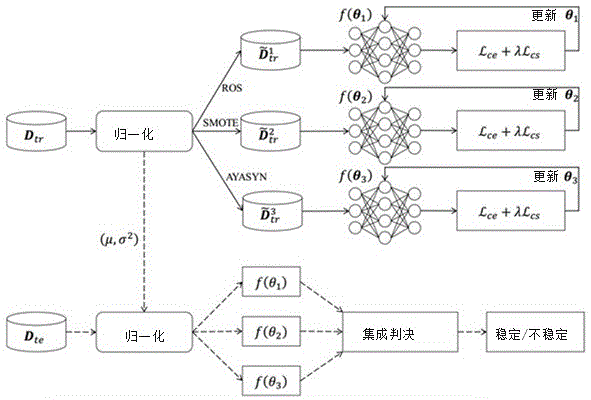
针对上述技术问题,本发明提供一种智能电网稳定性预测方法,本方法包含代价敏感正则化、多重过采样策略和集成学习等多种策略的深度神经网络。通过采用三种不同的过采样策略进行数据增强,这是在数据层面上处理类不平衡的方法;选择一个附加CSR损失函数的四层DNN作为主干进行预测,这是在损失函数层面上解决类不平衡的方法;而集成学习是通过使用多个DNN模型来提高预测性能,这是在学习者层面上解决类不平衡的方法。仿真结果表明,当来自稳定状态的训练样本与来自不稳定状态的训练样本之比为50时,本方法的准确率可以超过91%,并且比传统的基于ML/ dl的方法具有更好的性能。
2.技术方案:
一种智能电网稳定性预测方法,其特征在于:包括以下步骤:
步骤一:获取智能电网的历史电力相关信息,并生成历史智能电网数据集;
步骤二:将预处理后的历史智能电网数据集进行类别不平衡处理;所述类别不平衡处理为将预处理后的样本分别经过随机过采样ROS、合成少数过采样SMOTE和自适应合成过采样ADASYN不平衡处理分别得到经过加强后新的数据集;
步骤三:搭建三个深度神经网络模型,每个深度神经网络模型分别对应于ROS、SMOTE以及ADASYN的加强后的数据集;将步骤二得到的加强后的数据集输入对应的深度网络模型,利用具有代价敏感正则化的交叉熵损失函数计算模型输出的稳定性预测值与实际值之间的误差,从而得到深度神经网络稳定性预测模型;
步骤四:配置深度神经网络稳定性预测模型的集合决策策略;根据构建出的三个深度神经网络稳定性预测模型,得到输入的智能电网的电力相关信息属于当前稳定性状态的概率,选择概率值最大的状态作为待预测的配电网的稳定性。
进一步地,步骤一中历史智能电网数据集为基于多节点电网星形网络拓扑的电力相关信息;基于多节点电网星形网络拓扑中的智能电网参与者包括供应商节点以及与供应商节点相连的多个电力用户节点;其中电力相关信息包括参与者的响应时间、参与者的用电量与供应商的发电量之间的比值、价格弹性比例系数;
步骤一具体包括以下步骤:
S11:基于多节点电网星形网络拓,智能电网参与者具体包括供应商节点以及与之相连的n个电力用户节点;所述参与者的响应时间包括供应商节点的响应时间τ
(1);
则向量X的维数是(n+1)×3;
S12:获取历史智能电网数据集中的电网的稳定性状态,稳定性状态包括两种稳定性状态,即不稳定状态与稳定状态;us表示不稳定状态,s表示稳定状态;则历史智能电网稳定性向量与状态表示为:S
进一步地,步骤二具体包括以下步骤:
S21:对步骤一生成的数据集中进行预处理后按预设的比例将样本分为训练数据集、测试数据集;其中训练数据集表示为
其中预处理为如下式进行归一化处理:
上式中x
(4);
上式中,
分别对应状态不稳定与状态稳定的训练样本数量,由于不平衡状态比较少,则/>
S22:采用随机过采样ROS处理训练数据集,其输出新的训练数据集
S23: 采用合成少数过采样SMOTE处理训练数据其输出新的训练数据集
S23:采用自适应合成过采样ADASYN处理训练数据;计算出每个少数样本需要合成的样本数,输出新的训练数据集
进一步地,步骤三中搭建的深度神经网络模型结构为四个线性层;每个线性层的神经元分别为512、256、128和2个;其前三层均采用整流线性单元ReLU作为激活函数,最后一层以Softmax作为激活函数;且采用具有代价敏感正则化的交叉熵损失函数作为预测模型的总损失函数计算深度神经网络模型稳定性预测值与真实值之间的损失;
其中,计算稳定性预测值与真实值之间的损失的具体过程为:
S31:交叉熵损失函数L
(5)
其中,当稳定性预测正确时,稳定性状态的概率P(y)为1,否则为0;(x,y)~D表示稳定性属性x和对应的状态y都取自样本数据集D;E表示求统计平均;
S32:代价敏感正则化L
(6)
上式中,代价敏感矩阵
S33:基于公式(5)与(6)即能够计算出总损失函数L:
(7)
上式中,λ为预设的加权因子。
进一步地,步骤四中集合决策策略具体如下式:
(8);
上式中,
3.有益效果:
(1)本方案中采用三种不同的过采样策略进行数据增强,这是在数据层面上处理类不平衡的方法;选择一个附加CSR损失函数的四层DNN作为主干进行预测,这是在损失函数层面上解决类不平衡的方法;而集合决策策略是通过使用多个DNN模型来提高预测性能,这是在学习者层面上解决类不平衡的方法。
(2)本文采用三种数据过采样策略和一个基于成本敏感正则化的损失函数来训练三个具有多样性的深度神经网络模型,并采用集成学习算法融合这些深度神经网络模型的预测结果,进一步提高预测性能。
附图说明
图1为本发明的一种智能电网稳定性预测方法的总体框图;
图2为本发明中涉及的分布式多节点星型智能电网系统示意图;
图3为仿真例中性能不同ML/DL稳定性预测方法的性能大小与本方案的对比图。
具体实施方式
下面结合附图对本发明进行具体的说明。
如附图1所示,一种智能电网稳定性预测方法,其特征在于:包括以下步骤:
步骤一:获取智能电网的历史电力相关信息,并生成历史智能电网数据集;
步骤二:将预处理后的历史智能电网数据集进行类别不平衡处理;所述类别不平衡处理为将预处理后的样本分别经过随机过采样ROS、合成少数过采样SMOTE和自适应合成过采样ADASYN不平衡处理分别得到经过加强后新的数据集;
步骤三:搭建三个深度神经网络模型,每个深度神经网络模型分别对应于ROS、SMOTE以及ADASYN的加强后的数据集;将步骤二得到的加强后的数据集输入对应的深度网络模型,利用具有代价敏感正则化的交叉熵损失函数计算模型输出的稳定性预测值与实际值之间的误差,从而得到深度神经网络稳定性预测模型;
步骤四:配置深度神经网络稳定性预测模型的集合决策策略;根据构建出的三个深度神经网络稳定性预测模型,得到输入的智能电网的电力相关信息属于当前稳定性状态的概率,选择概率值最大的状态作为待预测的配电网的稳定性。
进一步地,如附图2所示,步骤一中历史智能电网数据集为基于多节点电网星形网络拓扑的电力相关信息;基于多节点电网星形网络拓扑中的智能电网参与者包括供应商节点以及与供应商节点相连的多个电力用户节点;其中电力相关信息包括参与者的响应时间、参与者的用电量与供应商的发电量之间的比值、价格弹性比例系数;
步骤一具体包括以下步骤:
S11:基于多节点电网星形网络拓,智能电网参与者具体包括供应商节点以及与之相连的n个电力用户节点;所述参与者的响应时间包括供应商节点的响应时间τ
(1);
则向量X的维数是(n+1)×3;
S12:获取历史智能电网数据集中的电网的稳定性状态,稳定性状态包括两种稳定性状态,即不稳定状态与稳定状态;us表示不稳定状态,s表示稳定状态;则历史智能电网稳定性向量与状态表示为:S
进一步地,步骤二具体包括以下步骤:
S21:对步骤一生成的数据集中进行预处理后按预设的比例将样本分为训练数据集、测试数据集;其中训练数据集表示为
其中预处理为如下式进行归一化处理:
上式中x
(4);
上式中,
分别对应状态不稳定与状态稳定的训练样本数量,由于不平衡状态比较少,则/>
S22:采用随机过采样ROS处理训练数据集,其输出新的训练数据集
S23: 采用合成少数过采样SMOTE处理训练数据其输出新的训练数据集
S23:采用自适应合成过采样ADASYN处理训练数据;计算出每个少数样本需要合成的样本数,输出新的训练数据集
进一步地,步骤三中搭建的深度神经网络模型结构为四个线性层;每个线性层的神经元分别为512、256、128和2个;其前三层均采用整流线性单元ReLU作为激活函数,最后一层以Softmax作为激活函数;且采用具有代价敏感正则化的交叉熵损失函数作为预测模型的总损失函数计算深度神经网络模型稳定性预测值与真实值之间的损失;
其中,计算稳定性预测值与真实值之间的损失的具体过程为:
S31:交叉熵损失函数L
(5)
其中,当稳定性预测正确时,稳定性状态的概率P(y)为1,否则为0;(x,y)~D表示稳定性属性x和对应的状态y都取自样本数据集D;E表示求统计平均;
S32:代价敏感正则化L
(6)
上式中,代价敏感矩阵
S33:基于公式(5)与(6)即能够计算出总损失函数L:
(7)
上式中,λ为预设的加权因子。
进一步地,步骤四中集合决策策略具体如下式:
(8);
上式中,
仿真实例:
本仿真例基于pytorch和scikit-learn库,其中采用的DNN结构参数如表1所示。
表1 DNN结构
预设的DNN参数包括:采用10,000个稳定态样本;10,000×ρ个不稳定态样本,ρ为类别不平衡的程度,1/越大,类别不平衡程度越高;训练集与验证集比例为9:1;得到仿真结果,对仿真结果进行如下的性能分析:
一、预测性能:
采用准确度ACC、F1分数和马修斯相关系数MCC三个指标来衡量预测的性能。
上式中TP表示预测为正样本的正样本数;TN表示预测为负样本的正样本数;FP表示预测为正样本的负样本数;FN表示预测为负样本的负样本数。这里,正样本是来自不稳定状态的样本,负样本是来自稳定状态的样本。此外,准确率和F1得分是分类问题的常用指标,后者可以兼顾分类模型的准确率和召回率,而MCC是一个比较平衡的指标,综合考虑了TP、TN、FP和FN, 一般应用于类不平衡问题的分类模型中。上述指标越高,说明方法的性能越好。
对比的不同稳定预测方法包括:支持向量机(SVM)、k近邻(KNN)、逻辑回归(LR)、随机森林算法(RF)、朴素贝叶斯(naive Bayes)、决策树(DT)以及本申请的预测方法(DNN)。如附图3所示,为不同的稳定性预测方法的预测性能指标值-类别不平衡程度对应值。由图中可以看出,本申请的DNN的方法在类平衡条件下(即=1)优于传统的基于ML的方法,其准确率可达97.45%,超过了基于SVM的方法的96.86%,远远超过了其他基于ML的方法。除准确性指标外,基于DNN方法的F1得分和MCC均高于其他方法。
更重要的是,在类不平衡条件下,基于DNN方法比传统的基于ML方法具有更大的优势。随着阶级不平衡程度越来越大,他们的差距也越来越大。特别是,当= 1/50或1/25时,本文提出的基于DNN的方法的准确率超过80%,而这些传统的基于ML方法的准确率远低于80%。同样,当= 1/100时,这些传统ML方法的准确率在54.55% ~ 77.20%之间,而基于DNN方法的准确率仍然可以略高于70%。
二、预测效率:效率也是衡量智能电网稳定性预测方法的另一个指标。表2给出了不同稳定性预测方法的每个样本推断时间。
表2.预测性能和推理时间
可以明显看出,本申请的基于DNN方法的最高可达11.89µs /样本,高于基于DT/LR的方法,与基于RF方法相似,低于基于SVM/KNN的方法。然而,如DT和LR这些低复杂度的方法,具有较差的预测性能,而本申请的基于DNN的方法具有很好的性能和可用推理速度,可以满足实际应用的需要。
三、类不平衡度的不同时,稳定性预测的性能比较:
本方法与基于正则化(CE)的方法和基于过采样的方法进行了比较;基于正则化(CE)的方法和基于过采样这两种方法都是基于DNN作为主干的。基于正则化的比较方法有基于focal loss (FL)方法和基于对抗性训练(AT)的方法,基于过采样方法有基于ROS、SMOTE和ADASYN。具体的稳定性预测的性能如表
与基于CE的方法相比,基于正则化和基于过采样的方法性能都有所提升,精度范围为= 1/100时的9% ~ 11%,=1/50时的1% ~ 3%,= 1/25时的2% ~ 4%。同样,这些方法也提高了F1评分和MCC。然而,与上述方法相比,本申请具有更好的性能和更大的性能增益。当=1/100时,上述方法的准确率仅为80% ~ 82%,而我们提出的方法达到了85%以上的准确率。此外,与这些基于正则化和过采样的方法相比,MCC的增益在0.04左右,F1-score的增益在0.06左右。当为1/50或1/25时,该方法的精度、F1分数和MCC均可超过90%、0.9和0.8,均高于其他方法。以上仿真结果证明了该方法在类不平衡条件下的优越性。
虽然本发明已以较佳实施例公开如上,但它们并不是用来限定本发明的,任何熟习此技艺者,在不脱离本发明之精神和范围内,自当可作各种变化或润饰,因此本发明的保护范围应当以本申请的权利要求保护范围所界定的为准。