一种序列到子序列的非侵入式负荷识别方法、装置及存储介质
文献发布时间:2024-04-18 20:01:23
技术领域
本发明属于非侵入式负荷识别领域,尤其是涉及一种序列到子序列的非侵入式负荷识别方法、装置及存储介质。
背景技术
非侵入式负载监测(NILM)是一种利用家庭总信号来推断电器消耗模式的技术。非侵入式负载监测领域的数据类型按照频率可以被分类为高频数据和低频数据。高频数据的频率通常在kHz或MHz范围,主要为电流信号和电压信号,而低频数据以秒为单位,主要为功率信号。针对低频数据,深度学习已成为目前的主流的方法。
基于深度学习的NILM可以根据输入和输出序列的长度被分为三类:序列到序列(seq2seq),序列到点(seq2point),和序列到子序列(seq2subseq),如图1所示。图1中,从左到右边依次是seq2seq,即用一段时间总功率分解相同的同样一段时间某种用电器的消耗功率。seq2point,用一段总功率分解中间的一点时间某种用电器的消耗功率。seq2subsuq,用一段总功率分解中间的一小段时间某种用电器的消耗功率。
公开号为CN113762355A的中国专利文献公开了一种基于非侵入式负荷分解的用户异常用电行为检测方法,采用序列到序列翻译模型进行负荷分解;公开号为CN113970667A的中国专利文献公开了一种基于预测窗口中间一小段序列的非侵入式负荷监测方法,通过训练序列到点网络只对滑动窗口的中间一小段序列进行预测输出来提高非侵入式负荷监测问题的可识别性和效率
现有的技术缺点主要有:
(1)目前,大部分识别方法对每个用电器都需要使用单独的模型进行识别。当识别新的用电器时,必须重新训练新的模型,这大大增加了训练的成本和复杂性。
(2)现有的序列到序列模型在处理输出序列两端的依赖关系时表现不佳。而序列到点模型由于仅输出一个点,预测效率低下。
(3)现有的基于注意力机制的模型,其计算和内存复杂度均为o(L
(4)现有的非侵入式负荷分解方法常常忽视了时间信息的重要性。
发明内容
本发明提供了一种序列到子序列的非侵入式负荷识别方法、装置及存储介质,通过预训练的权重,可以很快的进行微调模型,减少训练时间,提高识别效率。
一种序列到子序列的非侵入式负荷识别方法,包括以下步骤:
(1)利用公开数据集获取多栋房屋的电力消耗数据,数据处理后得到每栋房屋的总功率消耗时序数据流和对应的相同时间戳下的每个电器的功率消耗数据流;
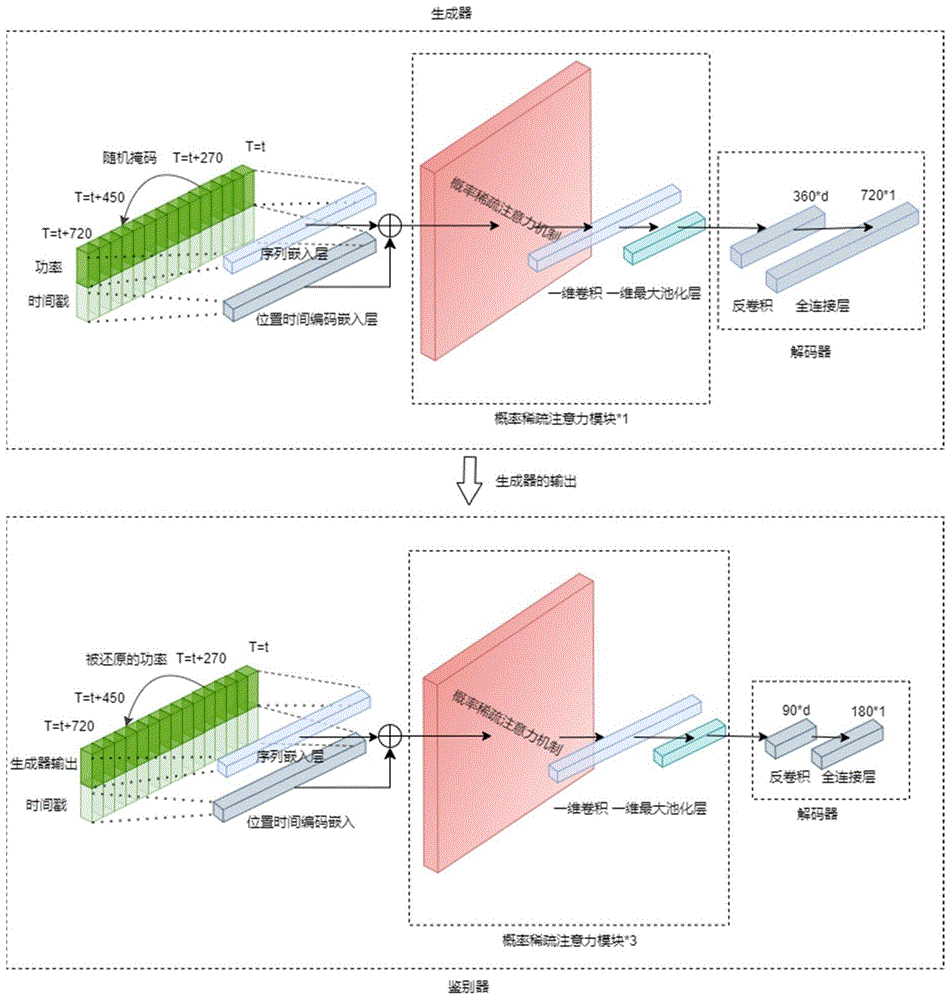
(2)构建非侵入式负荷识别模型,所述的非侵入式负荷识别模型包含生成器和鉴别器;
(3)利用训练集对非侵入式负荷识别模型进行训练,包括预训练阶段和监督学习阶段;
(3-1)预训练阶段:
本阶段只需每栋房屋的总功率消耗时序数据;其中,每栋房屋的电力消耗数据是以时序方式排列的数据流,在获得每个房屋的总功率消耗时序数据流后,整合生成一个连续的数据流;对每栋房屋的数据执行6秒的重采样,对缺失的数据执行向前填充,随后对总功率消耗时序数据进行归一化;获取每栋房屋的总功率消耗时序数据及其对应的时间戳之后,以720为长度、30为步长,对连续的数据流进行切分,从而生成预训练的数据集;
预训练过程:预训练的模型分成生成器和鉴别器。
生成器接受时间戳和被掩码的功率时序数据作为输入;掩码规则是:在总功率消耗时序数据的270至450这180个单位长度范围内,按照设定规则进行掩码处理,生成器的目标是尽力恢复这些被掩码的数据。
鉴别器输入是生成器的输出和时间戳;鉴别器的任务是鉴别生成器的输出数据哪部分是经过还原的;
预训练的过程迫使模型理解整个功率时序数据之间的相互依赖性,并无需依赖特定的用电器标签数据。
(3-2)监督学习过程:
本阶段需要每栋房屋的总功率消耗时序数据和对应想要分解的用电器的功率标签;对每栋房屋的数据执行6秒的重采样,对缺失的数据执行向前填充,随后对功率时序数据进行归一化;获取每栋房屋的总功率消耗时序数据及其对应的时间戳之后,然后总功率消耗时序数据以720为长度,目标用电器180为长度,并以30为步长,对数据流进行切分,从而生成监督训练的数据集;总功率中间180时间段的时间戳刚好对应上用电器相同时间戳的标签;
监督学习过程,丢弃生成器,用预训练时的鉴别器的权重对模型进行初始化;鉴别器的输入是被掩码的总功率消耗时序数据,同样的在数据的270到450这180个单位长度按设定规则进行掩码处理;输出是对应的想要识别的用电器;
(4)在应用过程中,将待识别房屋的总功率消耗时序数据输入训练好的非侵入式负荷识别模型中,得到目标电器的功率消耗数据,从而达到非侵入式监控单个用电器用电量的目的。
步骤(1)中,每栋房屋的总功率消耗数据和对应的每个电器的功率消耗数据均包含时间戳和功率数据。
步骤(2)中,非侵入式负荷识别模型中,生成器和鉴别器的组成均包含位置时间编码模块和概率稀疏注意力模块;
在生成器中,时间戳经过位置时间编码模块之后输出的张量A的形状,张量A包含局部位置信息和时间信息;被掩码的功率数据经过一维卷积(序列嵌入层)后的张量B的形状;张量A和张量B相加,再输入概率稀疏注意力模块;
在鉴别器中,时间戳经过时间编码模块之后输出的张量A'的形状,张量A'包含局部位置信息和时间信息;被还原的功率数据经过一维的卷积(序列嵌入层)后的张量B'形状;张量A'和张量B'相加,再输入概率稀疏注意力模块;
其中,张量的形状表示为(batch,len,d),batch表示批次的大小,也就是一次处理的数据数量,len表示每个序列的长度,d表示每个数据点的维度。
步骤(3)中,按照设定规则进行掩码处理具体为:
在这180长度的序列中,25%的位置的功率被随机选取并被掩码;被掩码的部分有80%的概率被设置为-1,10%的概率被设为[0,1)区间内的随机浮点数,剩余的10%保持原状。
预训练阶段,生成器的任务是恢复被掩码的数据,鉴别器的任务是识别出生成器所恢复的数据;
生成器的损失函数仅基于被掩码的位置进行计算,是均方误差MSE(Mean SquaredError)损失函数和KL散度损失函数(Kullback-Leibler散度损失函数)的总和;鉴别器使用二元交叉熵损失函数,用x表示掩码位置的输入,
预训练阶段,总的损失函数为生成器和鉴别器的损失函数之和。
监督学习阶段,损失函数表示为:
其中,T表示被掩码的时间序列长度,
一种序列到子序列的非侵入式负荷识别装置,包括存储器和一个或多个处理器,所述存储器中存储有可执行代码,所述一个或多个处理器执行所述可执行代码时,用于实现上述序列到子序列的非侵入式负荷识别方法。
一种计算机可读存储介质,其上存储有程序,该程序被处理器执行时,实现上述序列到子序列的非侵入式负荷识别方法。
与现有技术相比,本发明具有以下有益效果:
(1)本发明预训练,再进行监督学习的过程,解决了现有的非侵入式负荷识别方法存在训练时间过长且训练成本过高的问题。
(2)本发明序列到子序列的设计方式,解决了基于序列到序列模型在捕捉输出序列两端的依赖关系上存在的困难,以及序列到点模型预测效率低下的问题。
(3)本发明概率稀疏注意力模块,缓解了基于注意力机制的模型带来的计算复杂度和内存复杂度过高的问题。
(4)本发明位置时间编码模块,解决了模型在处理过程中缺少对时间信息考虑的问题。
附图说明
图1为序列到序列、序列到点、序列到子序列的非侵入式负载监测示意图;
图2为本发明中预训练阶段和监督学习阶段的模型示意图;
图3为监督学习阶段的总功率中间180时间段的时间戳对应用电器标签示意图。
具体实施方式
下面结合附图和实施例对本发明做进一步详细描述,需要指出的是,以下所述实施例旨在便于对本发明的理解,而对其不起任何限定作用。
一种序列到子序列的非侵入式负荷识别方法,包括以下步骤:
1、准备数据集
准备UK_DALE数据集:https://jack-kelly.com/data/。UK_DALE数据集记录了五栋房屋的电力消耗情况。在每栋房屋中,每隔六秒钟记录一次整栋房屋的总功率消耗情况(aggregate)以及单独的每个电器的功率消耗(individual)情况。
如下表1所示,为aggregate部分数据样例,表中,第1列数据为时间戳,第2列数据为功率。
表1
如下表2所示,为Individual(kettle水壶为例)部分数据样例,表中,第1列数据为时间戳,第2列数据为功率。
表2
2、模型结构/训练模型
首先介绍相关的深度学习模块
(1)序列嵌入层
Embedding(x)=Conv1d(x)
Conv1d表示一维卷积,用1维的卷积对其数据嵌入。在生成器中,输入x是被掩码的功率时序数,在鉴别器中,输入生成器的输出数据。序列嵌入层的输出会与位置时间编码模块的输出相加,输入到概率稀疏注意力模块。
(2)位置时间编码模块
时间编码:
在获取时间戳后,从中提取小时信息(一天中的第几小时)、周信息(一周中的第几天)、月信息(一年中的第几个月)以及天信息(一年中的第几天)。然后,将每种信息映射到(-0.5到0.5)的区间,形成形状为(1,4)的张量。这个信息先输入一维的卷积神经网络
位置编码:
若t是某个token在序列中的实际位置(例如第一个token为1,第二个token为2...),
其中,
(3)概率稀疏注意力模块
概率稀疏注意力模块包含概率稀疏注意力机制和自注意力蒸馏。
概率稀疏注意力:
原始的自注意力机制如下:
其中
自注意力机制具有潜在的稀疏特性。概率稀疏注意力如下
其中度量为:
概率稀疏自注意力:每个键仅关注于u个占主导的查询,
自注意力蒸馏,:
X
其中,j表示第j层,j+1表示第j+1层,[.]
(4)反卷积输出层
Out(X)=Tanh(Deconv(X)W
X表示概率稀疏注意力模块的输出,Deconv是反卷积网络,w
如图2所示,构建的非侵入式负荷识别模型包含生成器和鉴别器。利用训练集对非侵入式负荷识别模型进行训练,包括预训练阶段和监督学习阶段。
预训练阶段,只需要使用聚合的总功率特征。设定了下列输入和输出配置。在预训练过程中,只利用所有房屋的aggregate。首先整合这些aggregate,生成一个连续的数据流。然后,对其执行归一化处理,使用的公式是:(x–均值)/标准差。紧接着,以720为长度、30为步长,对该数据流进行切分。生成器的输入是形如(batch,720)的aggregate和其相应的时间戳。
生成器的输入是一个长度为720的功率时间序列信号。在这个序列中,介于270至450之间(总长度为180)的功率部分将根据以下规则进行掩码处理:在这180长度的序列中,25%的位置的功率被随机选取并被掩码。被掩码的部分有80%的概率被设置为-1,10%的概率被设为[0,1)区间内的随机浮点数,剩余的10%保持原状。鉴别器的输出是一个长度为180的数据序列,其目标是识别出那些被掩码处理过的数据部分。这个阶段会训练出一个通用的鉴别器的权重。
生成器的损失函数仅基于被掩码的位置进行计算,是均方误差MSE(Mean SquaredError)损失函数和KL散度损失函数(Kullback-Leibler散度损失函数)的总和;鉴别器使用二元交叉熵损失函数。用x表示掩码位置的输入,
预训练阶段,总的损失函数为生成器和鉴别器的损失函数之和。
监督学习阶段,生成器被丢弃,鉴别器被微调训练。用预训练的鉴别器的权重对其进行初始化。此时鉴别器的输入是aggregate的数据,同样的在数据的270到450这180个单位长度中,会按照同样的掩码规则进行处理。输出是对应的想要识别的用电器,如图3所示。以水壶(kettle)为例,当模型想要识别kettle,就用kettle的标签去训练。
损失函数可以表示为:
式中,T表示被掩码的时间序列长度,
本发明主要应用非侵入式负荷监控(识别)领域。从aggregate的数据中对目标的用电器进行能源分解,从而达到非侵入式监控单个用电器用电量的目的。预训练的目的是可以降低训练成本。在非侵入式负荷监控(识别)领域,目前主流的方法是一个模型识别一种用电器,通过预训练的权重,能很快的进行微调模型。
基于同样的发明原理,本实施例提供了一种序列到子序列的非侵入式负荷识别装置,包括存储器和一个或多个处理器,存储器中存储有可执行代码,一个或多个处理器执行所述可执行代码时,用于实现上述序列到子序列的非侵入式负荷识别方法。
基于同样的发明原理,本实施例提供了一种计算机可读存储介质,其上存储有程序,该程序被处理器执行时,实现上述序列到子序列的非侵入式负荷识别方法。
以上所述的实施例对本发明的技术方案和有益效果进行了详细说明,应理解的是以上所述仅为本发明的具体实施例,并不用于限制本发明,凡在本发明的原则范围内所做的任何修改、补充和等同替换,均应包含在本发明的保护范围之内。
- 电子设备的显示控制方法、装置、电子设备和存储介质
- 电子设备控制方法及装置、电子设备及存储介质
- 一种浴室加热装置和用于控制浴室加热装置的方法、设备、电子设备及计算机可读存储介质
- 一种智能控制方法、智能控制装置、电子设备和存储介质
- 控制方法、控制装置、计算机可读存储介质和电子设备
- 一种高分子防水卷材的废料回收装置及方法
- 刹车器防抱死控制方法、装置、电子设备及可读存储介质