一种可配置的自然语言转sql的方法及系统
文献发布时间:2023-06-19 09:51:02
技术领域
本发明涉及一种语言处理技术,尤其是一种可配置的自然语言转sql的方法及系统。
背景技术
目前机器自然语言转sql方法只能支持简单的select F(A) from B where C D E这种结构,其中A是希望查询的表结果字段;F是对这个表字段进行的函数操作,比如sum、count等;B是查询的表名;C是条件中的字段名称;E是条件中字段对应的取值;D是条件中字段与值的关系,比如大于、小于。
这种结构中的要素提取算法一般有两大类:一是通过关键词、正则表达式的匹配,确定A~F的取值;二是通过机器学习算法,对训练样本进行训练,因为A~F要素的取值位于一个有限的可选范围内,因此这种算法其实就是一个有监督的分类学习,A~F要素各自形成了一个独立的分类模型。
而这种模式的弊端主要有如下两点:1、sql结构固定,无法进行聚合、表关联等高级sql的生成;2、适用的数据库与业务场景单一,如果数据库里面新增了一个表,或者表新增了一个字段,就需要重新进行训练。
发明内容
发明目的:提供一种可配置的自然语言转sql的方法,以解决上述问题。
技术方案:一种可配置的自然语言转sql的方法,其特征在于包括如下步骤:
步骤1、构建sql结构对问题文本进行预处理;
步骤2、通过语义成分匹配进行聚合条件的判别;
步骤3、利用时间要素提取文本时间周期;
步骤4、通过条件要素提取时间要素以外的条件。
根据本发明的一个方面,所述步骤1中所述sql结构确定首先,对问题文本进行预处理,去除不重要的词,并对一些表达进行词汇的转换,然后,通过语义成分的匹配,确定sql的模板;
所述对问题文本进行预处理的过程步骤如下:
步骤11、对输入的文本进行分段、分句处理,将文本分解为短的句子,基于语义的预处理流程的第一步与传统预处理流程是相同的;
步骤12、对分段、分句后的文本进行分词处理,对分词结果加以分析,判断是否存在切分歧义,若存在,则利用语义知识库对初步分词结果进行切分歧义的消歧处理;
步骤13、对分词结果进行词性标注及词处理,利用语义知识库的语义信息和相关规则消除兼类词的词性歧义,提高词性标注的准确率;
步骤14、对分词后的结果进行停用词处理及未登录词的识别;
步骤15、利用之前所得到的结果进行概念空间的映射,并将概念相同的词合并成同一个词,选择符合的特征选择运算方法,对待提取特征的文本提取特征词;
步骤16、形成文本的语义向量。
根据本发明的一个方面,所述步骤2中所述聚合条件判别通过语义成分匹配判断确定sql模板中需要的聚合条件要素,后台以db_aggregative、db_aggregative_value、db_aggregative_dict、db_aggregative_graph、db_aggregative_limit五张表确定匹配流程;所述db_aggregative为聚合条件主表,当问题文本与表中的语义成分匹配成功,系统将通过这条规则的id在四个子表中进行具体信息的获取;所述db_aggregative_value记录了每一个聚合类型在不同的数据库和数据表中,对应的聚合列名、聚合操作、排序字段;所述db_aggregative_dict存储了聚合列的映射字典,用来对聚合过后的列字段进行翻译转换,以生成符合要求的语言回答;所述db_aggregative_graph表根据聚合类型判断是否以图表的形式呈现最终答案;所述db_aggregative_limit表根据聚合条件以及补充语义成分,确定对返回的结果保留前多少条记录;
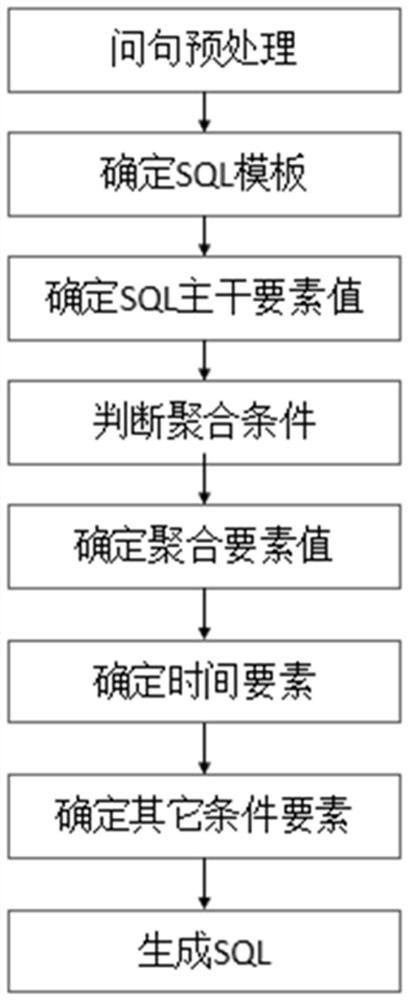
所述sql由自然语言转换得出,其转换过程如下:
步骤21、对文本进行预处理;
步骤22、确定SQL模块;
步骤23、确定SQL主干要素值;
步骤24、判断聚合条件;
步骤25、确定聚合要素值;
步骤26、确定时间要素;
步骤27、确定其它时间要素;
步骤28、生成sql。
根据本发明的一个方面,所述步骤3中所述时间要素提取从文本中获取时间相关的描述,确定时间周期的开头和结束,映射成标准形式的时间格式,通过db_condition_time表进行语义成分的匹配。
根据本发明的一个方面,所述步骤4中所述条件要素提取根据文本、数据表获取where关键字后面时间要素以外的其它条件,依赖db_condition、db_condition_dict、db_condition_sql三张表;所述db_condition为条件要素提取的主表,记录了各个数据源及数据表下的各个待匹配的语义成分信息。
根据本发明的一个方面,一种可配置的自然语言转sql的系统,其特征在于,包括如下模块:
用于构建sql结构对问题文本进行预处理的处理模块;
用于通过语义成分匹配进行聚合条件的判别的诊断模块;
用于利用时间要素提取文本时间周期的时间模块;
用于通过文本获取时间要素以外条件的条件提取模块。
根据本发明的一个方面,所述处理模块首先,对问题文本进行预处理,去除不重要的词,并对一些表达进行词汇的转换,然后,通过语义成分的匹配,确定sql的模板;
所述对问题文本进行预处理的过程步骤如下:
步骤11、对输入的文本进行分段、分句处理,将文本分解为短的句子,基于语义的预处理流程的第一步与传统预处理流程是相同的;
步骤12、对分段、分句后的文本进行分词处理,对分词结果加以分析,判断是否存在切分歧义,若存在,则利用语义知识库对初步分词结果进行切分歧义的消歧处理;
步骤13、对分词结果进行词性标注及词处理,利用语义知识库的语义信息和相关规则消除兼类词的词性歧义,提高词性标注的准确率;
步骤14、对分词后的结果进行停用词处理及未登录词的识别;
步骤15、利用之前所得到的结果进行概念空间的映射,并将概念相同的词合并成同一个词,选择符合的特征选择运算方法,对待提取特征的文本提取特征词;
步骤16、形成文本的语义向量表示模型。
根据本发明的一个方面,所述诊断模块通过语义成分匹配判断确定sql模板中需要的聚合条件要素,后台以db_aggregative、db_aggregative_value、db_aggregative_dict、db_aggregative_graph、db_aggregative_limit五张表确定匹配流程;所述db_aggregative为聚合条件主表,当问题文本与表中的语义成分匹配成功,系统将通过这条规则的id在四个子表中进行具体信息的获取;所述db_aggregative_value记录了每一个聚合类型在不同的数据库和数据表中,对应的聚合列名、聚合操作、排序字段;所述db_aggregative_dict存储了聚合列的映射字典,用来对聚合过后的列字段进行翻译转换,以生成符合要求的语言回答;所述db_aggregative_graph表根据聚合类型判断是否以图表的形式呈现最终答案;所述db_aggregative_limit表根据聚合条件以及补充语义成分,确定对返回的结果保留前多少条记录。
根据本发明的一个方面,所述时间模块从文本中获取时间相关的描述,确定时间周期的开头和结束,映射成标准形式的时间格式,通过db_condition_time表进行语义成分的匹配。
根据本发明的一个方面,所述条件提取模块根据文本、数据表获取where关键字后面时间要素以外的其它条件,依赖db_condition、db_condition_dict、db_condition_sql三张表;所述db_condition为条件要素提取的主表,记录了各个数据源及数据表下的各个待匹配的语义成分信息。
有益效果:本发明设计一种可配置的自然语言转sql的方法及系统,1、SQL每个环节的确定都是通过语义成分的匹配完成的,而语义成分匹配方案完全基于数据表进行记录存储,可以做到自由地配置,当有新增的数据源或者数据表时,可以快速地进行调整;
2、所有的SQL模板也是存储在数据表中,通过占位符的形式对需要填充的要素进行标记,因此可以自由地定义sql模板,提升适用的业务范围;
3、语义成分匹配方案基于词汇、正则以及词性,不依赖复杂的算法模型,响应快速,且维护简单;
通过自然语言交互方式实现数据查询分析需求,强大灵活的配置能力为复杂的业务逻辑提供了及时全面的支撑,当有新的数据接入或是新的提问方法时,系统可以进行快速的调整,同时,基于语义成分匹配的sql模板填充方式,确保了系统能够精准、全面地获取到问题文本中的语义信息,产生高质量的回答。
附图说明
图1是本发明的自然语言转sql流程图。
具体实施方式
在该实施例中,一种可配置的自然语言转sql的方法,其特征在于包括如下步骤:
步骤1、构建sql结构对问题文本进行预处理;
步骤2、通过语义成分匹配进行聚合条件的判别;
步骤3、利用时间要素提取文本时间周期;
步骤4、通过条件要素提取时间要素以外的条件。
在进一步的实施例中,所述步骤1中所述sql结构确定首先,对问题文本进行预处理,去除不重要的词,并对一些表达进行词汇的转换,然后,通过语义成分的匹配,确定sql的模板;
所述对问题文本进行预处理的过程步骤如下:
步骤11、对输入的文本进行分段、分句处理,将文本分解为短的句子,基于语义的预处理流程的第一步与传统预处理流程是相同的;
步骤12、对分段、分句后的文本进行分词处理,对分词结果加以分析,判断是否存在切分歧义,若存在,则利用语义知识库对初步分词结果进行切分歧义的消歧处理;
步骤13、对分词结果进行词性标注及词处理,利用语义知识库的语义信息和相关规则消除兼类词的词性歧义,提高词性标注的准确率;
步骤14、对分词后的结果进行停用词处理及未登录词的识别;
步骤15、利用之前所得到的结果进行概念空间的映射,并将概念相同的词合并成同一个词,选择符合的特征选择运算方法,对待提取特征的文本提取特征词;
步骤16、形成文本的语义向量。
在进一步的实施例中,所述步骤2中所述聚合条件判别通过语义成分匹配判断确定sql模板中需要的聚合条件要素,后台以db_aggregative、db_aggregative_value、db_aggregative_dict、db_aggregative_graph、db_aggregative_limit五张表确定匹配流程;所述db_aggregative为聚合条件主表,当问题文本与表中的语义成分匹配成功,系统将通过这条规则的id在四个子表中进行具体信息的获取;所述db_aggregative_value记录了每一个聚合类型在不同的数据库和数据表中,对应的聚合列名、聚合操作、排序字段;所述db_aggregative_dict存储了聚合列的映射字典,用来对聚合过后的列字段进行翻译转换,以生成符合要求的语言回答;所述db_aggregative_graph表根据聚合类型判断是否以图表的形式呈现最终答案;所述db_aggregative_limit表根据聚合条件以及补充语义成分,确定对返回的结果保留前多少条记录;
所述sql由自然语言转换得出,其转换过程如下:
步骤21、对文本进行预处理;
步骤22、确定SQL模块;
步骤23、确定SQL主干要素值;
步骤24、判断聚合条件;
步骤25、确定聚合要素值;
步骤26、确定时间要素;
步骤27、确定其它时间要素;
步骤28、生成sql。
在进一步的实施例中,所述步骤3中所述时间要素提取从文本中获取时间相关的描述,确定时间周期的开头和结束,映射成标准形式的时间格式,通过db_condition_time表进行语义成分的匹配。
在进一步的实施例中,所述步骤4中所述条件要素提取根据文本、数据表获取where关键字后面时间要素以外的其它条件,依赖db_condition、db_condition_dict、db_condition_sql三张表;所述db_condition为条件要素提取的主表,记录了各个数据源及数据表下的各个待匹配的语义成分信息。
在进一步的实施例中,一种可配置的自然语言转sql的系统,其特征在于,包括如下模块:
用于构建sql结构对问题文本进行预处理的处理模块;所述处理模块首先,对问题文本进行预处理,去除不重要的词,并对一些表达进行词汇的转换,然后,通过语义成分的匹配,确定sql的模板;系统的后台通过db_prehandle、db_structure、db_structure_case三张表进行维护;所述db_prehandle为文本预处理表,通过两个字段key和value存储了需要对文本进行替换的字词;
所述db_structure为sql模板表,每一个模板确定了查询sql的基本框架,格式如“select {sqlPhrase1} from {table1} where 1=1 {condition1} {timeCondition1_1}{groupColumn1}{sort}”;
所述db_structure_case为通过语义成分匹配sql模板的主表,其中structure_id字段为语义成分对应的sql模板id,其余各个字段记录了数据库、表名、关联字段、嵌套字段等sql主干要素信息,这些信息与sql模板结构一同确定;
所述对问题文本进行预处理的过程步骤如下:
步骤11、对输入的文本进行分段、分句处理,将文本分解为短的句子,基于语义的预处理流程的第一步与传统预处理流程是相同的;
步骤12、对分段、分句后的文本进行分词处理,对分词结果加以分析,判断是否存在切分歧义,若存在,则利用语义知识库对初步分词结果进行切分歧义的消歧处理;
步骤13、对分词结果进行词性标注及词处理,利用语义知识库的语义信息和相关规则消除兼类词的词性歧义,提高词性标注的准确率;
步骤14、对分词后的结果进行停用词处理及未登录词的识别;
步骤15、利用之前所得到的结果进行概念空间的映射,并将概念相同的词合并成同一个词,选择符合的特征选择运算方法,对待提取特征的文本提取特征词;
步骤16、形成文本的语义向量表示模型;
用于通过语义成分匹配进行聚合条件的判别的诊断模块;所述诊断模块通过语义成分匹配判断确定sql模板中需要的聚合条件要素,后台以db_aggregative、db_aggregative_value、db_aggregative_dict、db_aggregative_graph、db_aggregative_limit五张表确定匹配流程;所述db_aggregative为聚合条件主表,当问题文本与表中的语义成分匹配成功,系统将通过这条规则的id在四个子表中进行具体信息的获取;所述db_aggregative_value记录了每一个聚合类型在不同的数据库和数据表中,对应的聚合列名、聚合操作例如count/sum/avg等函数、排序字段;所述db_aggregative_dict存储了聚合列的映射字典,用来对聚合过后的列字段进行翻译转换,以生成符合要求的语言回答;所述db_aggregative_graph表根据聚合类型判断是否以图表的形式呈现最终答案;所述db_aggregative_limit表根据聚合条件以及补充语义成分,确定对返回的结果保留前多少条记录;
用于利用时间要素提取文本时间周期的时间模块;所述时间模块从文本中获取时间相关的描述,确定时间周期的开头和结束,映射成标准形式的时间格式,通过db_condition_time表进行语义成分的匹配;所述语义成要素匹配是各个sql要素确认的手段,每一条语义成分由核心表达、共现词、排除词、词性、替代词构成,在数据库中由words、regex、co_words、exclusive_words、nature几个字段进行存储,所述核心表达由词或者正则表达式构成,是语义匹配的核心;所述共现词是指满足核心条件时,所必要同时出现的词;所述排除词是指满足核心条件时,如果出现了,那么匹配不成功;所述词性是指核心条件满足时还必须符合某种词性,后台由hanlp对问题进行分词以及词性标注;所述替代词是指匹配成功后,核心条件转换成sql中要素时需要过滤掉的词;
所述文本对时间的描述归纳为两种形式:a.直接阐述了确切的时间点,例如“2019年3月到8月”;b.描述与现在时刻的远近关系,例如“近三天”,针对第一类表述,数据库中的六个结果字段直接记录了规范化的年月日数字表述,例如“2019年”,与正则表达式”20[0-2][0-9]年“匹配成功,那么year1字段取值为2019;针对第二类表述,在数据库中以java函数模板的形式进行存储,例如“近三天”在表中,与“[近|(过去)][0-9]+[天|日]”匹配成功,而其对应的day1字段为“getPastDay({value})”,其中getPastDay表示调用java程序中getPastDay这一函数,{value}表示正则表达式匹配到的value,即为3;Java后台代码读取到这一表达时,会自动调用函数,返回三天前的日期时刻;时间要素提取还依赖db_condition_time_table表,这个表中定义了每个数据源的每个表中的时间字段;
用于通过文本获取时间要素以外条件的条件提取模块;所述条件提取模块根据文本、数据表获取where关键字后面时间要素以外的其它条件,依赖db_condition、db_condition_dict、db_condition_sql三张表;所述db_condition为条件要素提取的主表,记录了各个数据源及数据表下的各个待匹配的语义成分信息;除此之外,在每一行的数据表中,sql字段为条件要素的模板id例如db_condition_sql的外键,例如“ and id ={value}”,而value字段为模板中填充的{value}值;dict字段为db_condition_dict的字典id,表示一个批量匹配的字典,当语义成分中核心表述的种类过多时,可以用一个外键关联的字典来替代。
总之,本发明具有以下优点:通过各部分关键语义要素匹配,确定SQL模板、聚合条件要素、时间要素以及其他条件要素,生成准确的SQL语句,各部分的关键语义要素构成内部互斥的语义簇,通过数据库中的结构化表格进行维护,可以自由地进行配置。
另外需要说明的是,在上述具体实施方式中所描述的各个具体技术特征,在不矛盾的情况下,可以通过任何合适的方式进行组合,为了避免不必要的重复,本发明对各种可能的组合方式不再另行说明。
- 一种可配置的自然语言转sql的方法及系统
- 一种基于中间语法树的多轮自然语言转SQL方法