一种中文拼写纠错模型
文献发布时间:2023-06-19 11:08:20
技术领域
本发明涉及计算机自然语言处理领域,更具体的说涉及一种端到端的中文拼写纠错模型。
背景技术
中文拼写纠错是一种文本纠错,应用于中文输入法、搜索引擎、聊天机器人、语音助手等智能领域,有很好的应用前景。它帮助汉语学习者更好的理解句子含义,帮助搜索引擎更准确的匹配到主题内容,帮助聊天机器人更准确的获得用户需求并回复最相关的信息。现有的模型没有充分考虑到字或词向量的上下文、依存句法关系和混淆字之间的关系,对此,本文提出一种新颖的端到端的充分考虑到上下文信息、依存句法以及混淆字关系的中文拼写纠错模型。
发明内容
本发明的目的是提供一种中文拼写纠错模型。
本发明解决其技术问题所采用的技术方案如下:
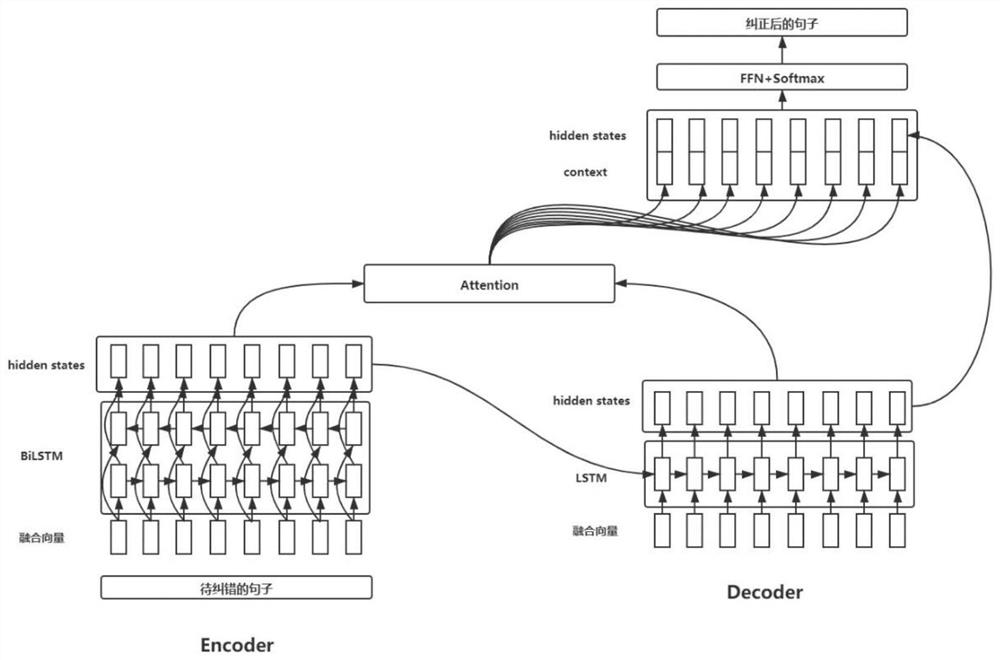
本发明模型是一个输入步长和输出步长一致的编解码模型。将待纠错的句子X笰{x
进一步,所述的混淆字图卷积神经网络具体实现如下:
将现有混淆集中的每一个字当作节点,字与字之间的关系当作边,构造出邻接矩阵A∈R
其中,I是单位矩阵,
通过混淆字图卷积神经网络,捕获混淆字之间相似的信息,将混淆字映射到相同的向量空间。每一层的图卷积公式如下:
其中,H∈R
进一步,所述的依存句法关系图卷积神经网络:
用工具提取句子关系,对输入句子的每个字生成关系向量,以每个字为节点,字与字之间的关系为边,通过依存句法关系图卷积神经网络,提取任意两个字之间的依存句法关系。
每一卷积层中每一个节点的图卷积后提取的依存句法关系向量如下:
其中l指的是第l层卷积层,i指的是当前节点,R是字与字之间的所有关系,
由于不是每个字都有混淆字,因此,如果句子中的字不在混淆集中,就用Bert预训练的上下文字向量表示;否则用混淆字图神经网络提取的混淆字向量表示。混淆字图神经网络输出的是一个R
依存句法关系图卷积神经网络的输出是每一个字的依存句法关系向量
所述编码器是一个双向的长短期记忆网络(LSTM),是循环神经网络的一种。将编码器在最终时间步的隐藏状态作为解码器的初始隐藏状态。解码器是一个单向的LSTM循环神经网络:
其中,
其中W
本发明的有益效果:
本发明充分考虑到字与字之间的上下文关系、依存句法关系和混淆字之间的关系,提出了一种新颖的中文拼写纠错模型。
附图说明
图1为本发明模型结构图
图2为本发明流程图。
具体实施方式
下面结合附图和实施例对本发明作进一步说明。
如图1和图2所示,本发明模型是一个输入步长和输出步长一致的编解码模型。将待纠错的句子X笰{x
进一步,所述的混淆字图卷积神经网络具体实现如下:
将现有混淆集中的每一个字当作节点,字与字之间的关系当作边,构造出邻接矩阵A∈R
其中,I是单位矩阵,
通过混淆字图卷积神经网络,捕获混淆字之间相似的信息,将混淆字映射到相同的向量空间。每一层的图卷积公式如下:
其中,H∈R
进一步,所述的依存句法关系图卷积神经网络:
用工具提取句子关系,对输入句子的每个字生成关系向量,以每个字为节点,字与字之间的关系为边,通过依存句法关系图卷积神经网络,提取任意两个字之间的依存句法关系。
每一卷积层中每一个节点的图卷积后获取的句法关系向量如下:
其中l指的是第l层卷积层,i指的是当前节点,R是字与字之间的所有关系,
由于不是每个字都有混淆字,因此,如果句子中的字不在混淆集中,就用Bert预训练的上下文字向量表示;否则用混淆字图神经网络提取的混淆字向量表示。混淆字图神经网络输出的是一个R
依存句法关系图卷积神经网络的输出是每一个字的依存句法关系向量
所述编码器是一个双向的长短期记忆网络(LSTM),是循环神经网络的一种。将编码器在最终时间步的隐藏状态作为解码器的初始隐藏状态。解码器是一个单向的LSTM循环神经网络:
其中,
其中W
实施例1:
待纠错的句子:遇到逆竟时,我们必须用于面对。
通过混淆字图卷积神经网络输出的混淆字向量矩阵,我们找出待纠错句子中每一个字对应的混淆字向量,如果待纠错字不在混淆集中,我们用Bert预训练的上下文向量表示。
通过工具提取待纠错句子的关系,将每个字对应的关系向量输入依存句法关系图卷积神经网络,获取每个字的依存关系向量。
将待纠错字的混淆字向量或上下文向量和依存关系向量融合起来,E笰{e
纠正后的句子:遇到逆境时,我们必须勇于面对。
- 一种中文拼写纠错模型
- 一种中文拼写纠错方法、装置、计算机设备及存储介质