一种目标去除背景恢复方法、装置和电子设备
文献发布时间:2023-06-19 18:29:06
技术领域
本发明涉及计算机视觉领域,尤其涉及一种目标去除背景恢复方法、装置和电子设备。
背景技术
在计算机视觉图像处理领域,深度神经网络可以训练出效果较好的实例分割模型,可以将图像中将目标按照像素级从图像中分割出来。并且随着近几年自监督学习以及注意力机制和vison transformer在计算机视觉领域的爆火,基于编解码器结构提取图像特征从而进行图像预测的技术也有很好的效果。
目标去除背景恢复技术对于场景修复、环境影响评估和城市制图等许多应用都是必不可少的,不需要的物体(如行人、骑手、植被和车辆)经常遮挡场景,阻碍了重要的任务。此外也可以有助于摄影师,景点游客等拍照后自动去除杂物,还原自然景貌。然而目前已有的相关技术仍存在很多问题。
以往的方法可以找到近似的最近邻来匹配图像斑块。以及一些基于传统的图像处理方法对像素进行还原,如通过复制进行绘制:这些方法试图显式地从周围环境填补缺失区域。
中国专利申请CN201610526248与CN201910222252公开了一种目标去除方法不是基于深度学习的方法,而是传统的像素差值,以及使用opencv库里的一些传统算法进行恢复,效果显然不好。
随着基于学习的图像绘制方法的兴起,例如,“Image inpainting based on deeplearning:A review”Displays,vol.69,Sep.2021,Art.no.102028,doi:10/gkqdtt.这篇文章中的绘制结果相比于基于传统的图像处理方法恢复出的图像效果更好而且更加具有智能的因素。现有的基于深度学习的方法可分为三类:
无监督学习的一个例子是一种上下文复制方法,例如,“Improvements tocontext based self-supervised learming,"in Proc.IEEE/CVFConf.Comput.Vis.PatternRecognit,Jun.2018,pp.9339-9348.这篇文章使用周围的图像信息来预测内容的丢失,但在处理复杂的场景时,图像复制往往会失败。
通过建模进行内部绘制:这些方法使用大型外部数据库,以数据驱动的方式想象缺失的像素。例如,“Context encoders:Feature learning by inpainting,"inProc.IEEE Conf.Comput.Vis.Pattern Recognit.(CVPR),Jun.2016,pp.2536 -2544.这篇文章试图学习模拟训练图像的分布,并假设被相似背景包围的区域可能具有类似的内容这些方法可以有效地找到与所需预测图像具有足够视觉相似性的样本图像,但在数据库中没有类似的例子时,它们很容易失败。
结合两者:第三类方法试图结合两者,以克服复制方法或建模方法的局限性。这些方法不仅学会了以数据驱动的方式构建图像分布,而且它们还被设计为显式地从背景区域中借用补丁或特征。但是,当训练数据集和处理后的图像的内容不匹配时,生成的图像质量并不令人满意。
例如,“Automatic Object Removal With Obstructed Facades CompletionUsing Semantic Segmentation and Generative Adversarial Inpainting”IEEEACCESS,2021,9.这篇文章通过自定义数据集,并采用GAN模型进行图像预测,效果相对前几种方法更好。但是需要单独根据特定场景自制数据集并且模型采用端到端训练需要groundtruth所有改模型效果之所以好也有过度拟合训练数据的原因,不宜迁移到别的场景应用。
因此现有技术需要一种更智能化目标去除以及背景恢复的方法来解决传统图像处理里方法中无法准确还原图像的问题,并且需要一种适用场景可拓展的图像预测自监督模型学习方法可以让模型可以在已有的大规模数据集上进行自监督训练来解决人工订制数据集带来的高昂成本以及适用场景不可拓展的问题。
发明内容
本方案针对上文提出的问题和需求,提出一种目标去除背景恢复方法、装置和电子设备,由于采取了如下技术特征而能够实现上述技术目的,并带来其他多项技术效果。
本发明的一个目的在于提出一种目标去除背景恢复方法,包括如下步骤:
S10模型搭建与训练:搭建MaskRCNN实例分割模型与MAE模型,有监督训练MaskRCNN实例分割模型,在COCO数据集上自监督训练MAE模型,其中,训练时采用高比例随机掩码;
S20模型推理:包括如下步骤:
统一两个串接式模型推理阶段的数据尺寸;
将图片中实例分割出的目标打上可以在预测模型中识别的标记;
将图片经过实例分割模型得到分割出目标的结果图;
将分割出的像素级目标转换成patch级;
通过patch级实例分割图片得到预测模型所需的mask;
将patch级实例分割的图片与mask一并送入预测模型,根据mask将训练阶段的随机掩码改成固定掩码实例分割出的patch块;
将去掉实例分割出的patch块的图片数据送入预测模型的编码器得到处理后的特征图;
将预测模型编码器部分得到的特征图输入预测模型解码器部分还原图片;
S30结果测试:包括如下步骤:
在固定掩码测试中,首先测试图片经过MaskRCNN实例分割模型后得到分割后的图片,然后将实例分割后的图片进行固定掩码,最后送入经过自监督训练好的MAE模型进行图片预测mask区域的还原得到最终目标去除背景恢复后的图片。
在本发明的一个示例中,在步骤S10模型搭建与训练中,有监督训练MaskRCNN实例分割模型包括如下步骤:
将输入图片送入到特征提取网络得到特征图;
对特征图的每一个像素位置设定固定个数的ROI;
将ROI区域送入RPN网络进行二分类(前景和背景)以及坐标回归,以获得精炼后的ROI区域;
对上个步骤中获得的ROI区域执行ROIAlign操作,即先将原图和特征图的像素级对应起来;
将特征图和固定的特征对应起来;
对这些ROI区域进行多类别分类,候选框回归和引入FCN生成Mask,完成分割任务。
在本发明的一个示例中,在步骤S10模型搭建与训练中,自监督训练MAE模型包括如下步骤:
将图像划分成patches:(B,C,H,W)->(B,N,PxPxC);
对各个patch进行卷积操作,生成token,并加入位置信息:(B,N,PxPxC)->(B,N,dim);
根据预设的掩码比例,使用服从均匀分布的随机采样策略采样一部分送给编码器部分,另一部分mask;
将编码器编码后的特征与加入位置信息后的mask特征按照原先在patch形态时对应的次序拼在一起,然后输入给解码器;
解码器解码后取出mask对应的部分送入到全连接层,对mask得patch块的像素值进行预测,最后将预测结果与mask的patch块进行比较,计算MSE loss。
本发明的另一个目的在于提出一种目标去除背景恢复装置,包括:
模型搭建与训练模块,配置为搭建MaskRCNN实例分割模型与MAE模型,有监督训练MaskRCNN实例分割模型,在COCO数据集上自监督训练MAE模型,其中,训练时采用高比例随机掩码;
模型推理模块,配置为统一两个串接式模型推理阶段的数据尺寸,将图片中实例分割出的目标打上可以在预测模型中识别的标记,将图片经过实例分割模型得到分割出目标的结果图,将分割出的像素级目标转换成patch级,通过patch级实例分割图片得到预测模型所需的mask,将patch级实例分割的图片与mask一并送入预测模型,根据mask将训练阶段的随机掩码改成固定掩码实例分割出的patch块,将去掉实例分割出的patch块的图片数据送入预测模型的编码器得到处理后的特征图,将预测模型编码器部分得到的特征图输入预测模型解码器部分还原图片;
结果测试模块,配置为在固定掩码测试中,首先测试图片经过MaskRCNN实例分割模型后得到分割后的图片,然后将实例分割后的图片进行固定掩码,最后送入经过自监督训练好的MAE模型进行图片预测mask区域的还原得到最终目标去除背景恢复后的图片。
在本发明的一个示例中,模型搭建与训练模块包括:MaskRCNN实例分割模型训练单元,其配置为将输入图片送入到特征提取网络得到特征图,对特征图的每一个像素位置设定固定个数的ROI;将ROI区域送入RPN网络进行二分类(前景和背景)以及坐标回归,以获得精炼后的ROI区域;对上个步骤中获得的ROI区域执行论文提出的ROIAlign操作,即先将原图和特征图的像素级对应起来,将特征图和固定的特征对应起来,对这些ROI区域进行多类别分类,候选框回归和引入FCN生成Mask,完成分割任务。
在本发明的一个示例中,模型搭建与训练模块包括:MAE模型训练单元,其配置为将图像划分成patches:(B,C,H,W)->(B,N,PxPxC),对各个patch进行卷积操作,生成token,并加入位置信息:(B,N,PxPxC)->(B,N,dim),根据预设的掩码比例,使用服从均匀分布的随机采样策略采样一部分送给编码器部分,另一部分mask;将编码器编码后的特征与加入位置信息后的mask特征按照原先在patch形态时对应的次序拼在一起,然后输入给解码器,解码器解码后取出mask对应的部分送入到全连接层,对mask得patch块的像素值进行预测,最后将预测结果与mask的patch块进行比较,计算MSE loss。
本发明的再一个目的在于提出一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器运行时执行上述所述的方法的步骤。
本发明的又一个目的在于提出一种电子设备,所述电子设备包括存储器,处理器以及一个或者一个以上的程序,其中所述一个或者一个以上的程序存储于所述存储器中,且经配置以由所述处理器执行上述所述的方法的步骤。
根据本发明实施例上述第一方面至第四方面提供的方案中,本发明利用深度卷积神经网络的算法,该方案以有效去除图片中存在的各类目标,并在去除后恢复出该区域背景信息为研究对象,通过分阶段训练得到两个卷积神经网络,基于MaskRcnn实例分割模型的目标去除网络与基于MAE自监督学习模型的背景恢复网络,分阶段式先分割再预测串接构成最终的目标去除背景恢复模型。与现有技术相比,这种方法能够准确还原图像,恢复效果更好,并且无需专门针对各类场景人工订制训练数据集,大大降低成本,具有更好的适用场景可拓展性。
下文中将结合附图对实施本发明的最优实施例进行更加详尽的描述,以便能容易理解本发明的特征和优点。
附图说明
为了更清楚地说明本发明实施例的技术方案,下文中将对本发明实施例的附图进行简单介绍。其中,附图仅仅用于展示本发明的一些实施例,而非将本发明的全部实施例限制于此。
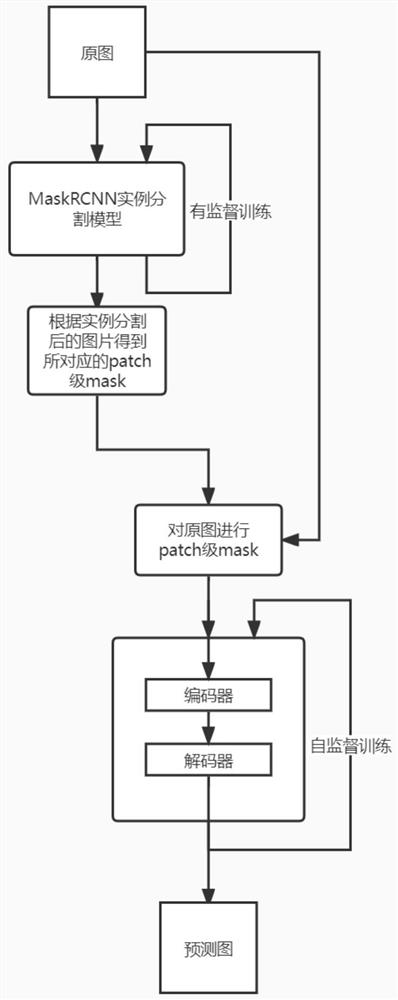
图1为根据本发明实施例的目标去除背景恢复方法的流程图;
图2为根据本发明实施例的目标去除的网络结构图;
图3为根据本发明实施例的背景恢复的网络结构图;
图4为根据本发明实施例的测试图片;
图5为根据本发明实施例的训练阶段随机掩码75%的图片;
图6为根据本发明实施例的训练阶段随机掩码75%的图片恢复的结果;
图7为根据本发明实施例的经过实例分割后的测试图片;
图8为根据本发明实施例的固定Mask目标后图片;
图9为根据本发明实施例的固定Mask目标后图片恢复的结果。
具体实施方式
为了使得本发明的技术方案的目的、技术方案和优点更加清楚,下文中将结合本发明具体实施例的附图,对本发明实施例的技术方案进行清楚、完整地描述。附图中相同的附图标记代表相同部件。需要说明的是,所描述的实施例是本发明的一部分实施例,而不是全部的实施例。基于所描述的本发明的实施例,本领域普通技术人员在无需创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
除非另作定义,此处使用的技术术语或者科学术语应当为本发明所属领域内具有一般技能的人士所理解的通常意义。本发明专利申请说明书以及权利要求书中使用的“第一”、“第二”以及类似的词语并不表示任何顺序、数量或者重要性,而只是用来区分不同的组成部分。同样,“一个”或者“一”等类似词语也不必然表示数量限制。“包括”或者“包含”等类似的词语意指出现该词前面的元件或物件涵盖出现在该词后面列举的元件或者物件及其等同,而不排除其他元件或者物件。“连接”或者“相连”等类似的词语并非限定于物理的或者机械的连接,而是可以包括电性的连接,不管是直接的还是间接的。“上”、“下”、“左”、“右”等仅用于表示相对位置关系,当被描述对象的绝对位置改变后,则该相对位置关系也可能相应地改变。
根据本发明第一方面的一种目标去除背景恢复方法,如图1至图3所示,包括如下步骤:
S10模型搭建与训练:搭建MaskRCNN实例分割模型与MAE模型,有监督训练MaskRCNN实例分割模型,在COCO数据集上自监督训练MAE模型,其中,训练时采用高比例随机掩码;
其中,在步骤S10模型搭建与训练中,有监督训练MaskRCNN实例分割模型包括如下步骤:
将输入图片送入到特征提取网络得到特征图;
对特征图的每一个像素位置设定固定个数的ROI;
将ROI区域送入RPN网络进行二分类(前景和背景)以及坐标回归,以获得精炼后的ROI区域;
对上个步骤中获得的ROI区域执行ROIAlign操作,即先将原图和特征图(featuremap)的像素级(pixel)对应起来;
将特征图和固定的特征(feature)对应起来;
对这些ROI区域进行多类别分类,候选框回归和引入FCN生成Mask,完成分割任务。
其中,在步骤S10模型搭建与训练中,自监督训练MAE模型包括如下步骤:
将图像划分成patches:(B,C,H,W)->(B,N,PxPxC);
对各个patch进行卷积操作,生成token,并加入位置信息:(B,N,PxPxC)->(B,N,dim);
根据预设的掩码比例,使用服从均匀分布的随机采样策略采样一部分送给编码器部分,另一部分mask;
将编码器编码后的特征与加入位置信息后的mask特征按照原先在patch形态时对应的次序拼在一起,然后输入给解码器;
解码器解码后取出mask对应的部分送入到全连接层,对mask得patch块的像素值进行预测,最后将预测结果与mask的patch块进行比较,计算MSE loss;
具体地,沿袭ViT的做法,将图像分成一块块16x16大小的不重叠的patch块,然后使用服从均匀分布的采样策略对这些patches随机采样一部分,同时mask掉余下的另一部分。被mask掉的patches占所有patches的大部分,它们不会输入到编码器。
编码器仅处理未被mask的patches。编码器本身可以是ViT,关于如何将图像划分成patch,使用ViT时的的做法是:先将图像从(B,C,H,W)reshape成(B,N,PxPxC),其中N和P分别为patch数量和patch大小,也就是将3通道的图像转换成N个维度大小为PxPxC的向量;然后,通过线性映射全连接层,将其嵌入到指定的维度空间大小,记为'dim'(从PxPxCproject到dim),转换成为token(B,N,dim);最后再加上位置嵌入,从而为各个patch添加位置信息。位置嵌入是所有图像共享的、可学习的,数据形状(shape)与每张图的token相对应,即:(N,dim)。
解码器不仅需要处理经过编码器编码的未被masked的tokens,还需要处理masktokens。mask token是可学习的、所有masked patch都共享的1个向量。这里对于masktoken也需要加入位置信息。位置编码(postion emebdding)是每个masked patch对应1个,数据形状是(N',dim),其中N'是masked patch的数量。
模型整体预训练任务的目标是重建像素值,并且是masked patch的像素值,也就是仅对mask掉的部分计算loss,loss选用MSE。在解码器解码后的所有token中取出masktoken,将这些mask tokens送入全连接层,将输出通道映射到1个patch的像素数量(PxPxC),也就是输出的数据形状是:(B,N',PxPxC),其中的每个值就代表预测的像素值。最后,以之前mask掉的patch的像素值作为target,与预测结果计算MSE loss。
S20模型推理:包括如下步骤:
统一两个串接式模型推理阶段的数据尺寸;
将图片中实例分割出的目标打上可以在预测模型中识别的标记;
将图片经过实例分割模型得到分割出目标的结果图;
将分割出的像素级目标转换成patch级;
通过patch级实例分割图片得到预测模型所需的mask;
将patch级实例分割的图片与mask一并送入预测模型,根据mask将训练阶段的随机掩码改成固定掩码实例分割出的patch块;
将去掉实例分割出的patch块的图片数据送入预测模型的编码器得到处理后的特征图;
将预测模型编码器部分得到的特征图输入预测模型解码器部分还原图片;
也就是说,先统一分割与预测模型的输入数据尺寸以便要处理的图片在经过实例分割模型后可以直接串连式送入预测模型进行预测阶段的模型推理。具体为由于图片预测部分的模型训练数据都为224×224的大小,所以在MaskRCNN模型推理阶段先将任意尺寸大小图片先resize成224×224大小的图片以统一分割模型与预测模型的输入数据尺寸。
将经过实例分割后得到目标的图片在目标所在像素点上打上标记以便后续送入预测模型中后可以快速的准确的定位图片所需预测的部分。具体为将经过MaskRCNN实例分割后得到的带有检测框以及其他与目标像素无关的数据去除,并且将语义分割出的像素点的RGB三通道像素值全部设置为统一的数值这里全部设置为0。
将实例分割后并在分割出的目标所在像素值上打上标记的目标转换为适用于vision transformer处理的patch级。具体为将224×224的待处理图片划分为14×14个patch,每个patch里有16×16个像素点,遍历图片中所有像素点,当该像素点RGB三通道都为0时便是实例分割出的目标所在像素点,找到该像素点所在patch块并且令该patch块中所有像素点的像素值RGB三通道全部为零。这样便实现了将分割出的像素级目标转换成patch级。
将通过patch级实例分割图片得到vison transformer预测模型所需的mask。具体为定义一个数据维度为(1,196)的mask并且将所有值全部赋值为0,196便代表14×14个patch块。将所需处理的数据维度为(224,224,3)的图片reshape为与mask在patch维度相对应的(1,196,768)的数据格式,其中224为原图片长宽所具有的像素点,3为RGB三通道,196为vison transformer所需处理的patch的个数,768为一个patch中像素点的个数。在得到(1,196,768)的数据格式的数据后便可以在patch级上进行判断,遍历这196个patch,当一个patch中768个像素点的RGB三通道像素值全部为0时,便令mask对应位置上的值赋值为1,从而得到预测模型所需的mask。
将patch级实例分割的图片与mask一并送入预测模型,根据mask将训练阶段的随机掩码改成固定掩码实例分割出的patch块。具体为先将图片进行归一化与标准化处理,并且reshape成(1,3,224,224),将其与(1,196)的mask送入模型的编码器部分。在编码器部分先将(1,3,224,224)的输入图片数据经过一个卷积得到(1,196,1024)的数据并与初始化模型权重中的位置编码信息相加。定义一个ids_keep用来存放根据判断mask后没有没被掩码的patch所对应的下标,并且根据ids_keep计算得到用作解码器(decoder)部分图像还原的ids_restore。然后根据ids_keep从图像数据中取出的没有被掩码的patch送入编码器(encoder)进行预测模型编码器部分的推理从而实现模型推理阶段固定掩码的设计。
将去掉实例分割出的patch块的图片数据送入预测模型的编码器得到visiontransformer处理后的特征图。具体为将去掉被mask标记的patch块后的(1,x,1024)的图像数据,x为没有被mask标记也就是被保留的patch图像数据与cls_token也就是原模型中的分类头进行concat操作,将此数据送入由vision transformer块堆叠的神经网络中进行编码器部分的前向推理,最终得到经过预测模型编码器部分处理后的特征图。
将预测模型编码器部分得到的特征图输入预测模型解码器部分还原图片。具体为将从预测模型编码器部分得到的特征图再进行一次卷积将图片数据的最后一个维度由1024卷积到512,在图片数据后加上被掩码的patch块的个数个的随机数据。然后根据编码器部分得到的ids_restore将该图片数据还原成(1,196,512)的数据格式,最后送入解码器部分的vision transformer块进行图片还原从而得到最终的输出。
S30结果测试:包括如下步骤:
在固定掩码测试中,首先测试图片经过MaskRCNN实例分割模型后得到分割后的图片,然后将实例分割后的图片进行固定掩码,最后送入经过自监督训练好的MAE模型进行图片预测mask区域的还原得到最终目标去除背景恢复后的图片;
也就是说,首先将测试图片如图4所示,输入经过随机掩码训练后的MAE模型,在经过随机掩码后的图片如图5所示,可以看到其中有一大部分patch块被mask掉。将没随机掩码后的测试图片送入MAE得到预测图片输出如图6所示,可以看到MAE模型对随机高比例掩码后的图片还原的效果很好。再看固定掩码测试,首先测试图片经过MaskRCNN实例分割模型后得到如图7所示分割后的图片,黑色像素区域代表被实例分割出的目标区域。然后将实例分割后的图片进行固定掩码得到如图8所示,可以看到带有被实例分割出像素点的patch都被mask掉了。最后送入经过自监督训练好的MAE模型进行图片预测mask区域的还原得到如图9所示结果,可以看到目标与道路接触的patch部分被还原成了道路的背景颜色,而与湖水相接触的patch则被还原成了与湖水相同的背景颜色。
根据本发明第二方面的一种目标去除背景恢复装置,包括:
模型搭建与训练模块,配置为搭建MaskRCNN实例分割模型与MAE模型,有监督训练MaskRCNN实例分割模型,在COCO数据集上自监督训练MAE模型,其中,训练时采用高比例随机掩码;
模型推理模块,配置为统一两个串接式模型推理阶段的数据尺寸,将图片中实例分割出的目标打上可以在预测模型中识别的标记,将图片经过实例分割模型得到分割出目标的结果图,将分割出的像素级目标转换成patch级,通过patch级实例分割图片得到预测模型所需的mask,将patch级实例分割的图片与mask一并送入预测模型,根据mask将训练阶段的随机掩码改成固定掩码实例分割出的patch块,将去掉实例分割出的patch块的图片数据送入预测模型的编码器得到处理后的特征图,将预测模型编码器部分得到的特征图输入预测模型解码器部分还原图片;
结果测试模块,配置为在固定掩码测试中,首先测试图片经过MaskRCNN实例分割模型后得到分割后的图片,然后将实例分割后的图片进行固定掩码,最后送入经过自监督训练好的MAE模型进行图片预测mask区域的还原得到最终目标去除背景恢复后的图片。
在本发明的一个示例中,模型搭建与训练模块包括:MaskRCNN实例分割模型训练单元,其配置为将输入图片送入到特征提取网络得到特征图,对特征图的每一个像素位置设定固定个数的ROI;将ROI区域送入RPN网络进行二分类(前景和背景)以及坐标回归,以获得精炼后的ROI区域;对上个步骤中获得的ROI区域执行论文提出的ROIAlign操作,即先将原图和特征图的像素级对应起来,将特征图和固定的特征对应起来,对这些ROI区域进行多类别分类,候选框回归和引入FCN生成Mask,完成分割任务。
在本发明的一个示例中,模型搭建与训练模块包括:MAE模型训练单元,其配置为将图像划分成patches:(B,C,H,W)->(B,N,PxPxC),对各个patch进行卷积操作,生成token,并加入位置信息:(B,N,PxPxC)->(B,N,dim),根据预设的掩码比例,使用服从均匀分布的随机采样策略采样一部分送给编码器部分,另一部分mask;将编码器编码后的特征与加入位置信息后的mask特征按照原先在patch形态时对应的次序拼在一起,然后输入给解码器,解码器解码后取出mask对应的部分送入到全连接层,对mask得patch块的像素值进行预测,最后将预测结果与mask的patch块进行比较,计算MSE loss。
根据本发明第三方面的一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器运行时执行上述所述的方法的步骤。
根据本发明第四方面的一种电子设备,所述电子设备包括存储器,处理器以及一个或者一个以上的程序,其中所述一个或者一个以上的程序存储于所述存储器中,且经配置以由所述处理器执行上述所述的方法的步骤。
根据本发明实施例上述第一方面至第四方面提供的方案中,本发明利用深度卷积神经网络的算法,该方案以有效去除图片中存在的各类目标,并在去除后恢复出该区域背景信息为研究对象,通过分阶段训练得到两个卷积神经网络,基于MaskRcnn实例分割模型的目标去除网络与基于MAE自监督学习模型的背景恢复网络,分阶段式先分割再预测串接构成最终的目标去除背景恢复模型。与现有技术相比,这种方法能够准确还原图像,恢复效果更好,并且无需专门针对各类场景人工订制训练数据集,大大降低成本,具有更好的适用场景可拓展性。
上文中参照优选的实施例详细描述了本发明所提出的目标去除背景恢复方法、装置和电子设备的示范性实施方式,然而本领域技术人员可理解的是,在不背离本发明理念的前提下,可以对上述具体实施例做出多种变型和改型,且可以对本发明提出的各种技术特征、结构进行多种组合,而不超出本发明的保护范围,本发明的保护范围由所附的权利要求确定。
- 一种运动目标确定方法、装置及电子设备
- 一种动目标检测方法、装置、电子设备及存储介质
- 一种电子设备的输入方法、输入装置及电子设备
- 一种电子设备、双屏电子设备的控制方法及装置
- 数据库同步恢复方法、装置、计算机可读存储介质和电子设备
- 一种定点监控运动目标场景的去除背景的方法及装置
- 一种目标检测网络构建和目标检测方法、装置及电子设备