一种基于采样数据的空间机器人最优阻抗学习方法
文献发布时间:2023-06-19 18:46:07
技术领域
本发明属于空间机器人智能柔顺控制领域,具体涉及一种基于采样数据的空间机器人最优阻抗学习方法。
背景技术
空间机器人能够协助或替代航天员完成较多危险的在轨操作任务,如空间站的装配与维修、卫星的释放与回收、空间碎片的捕获与拖曳等,极大地拓展了人类在宇宙中的活动能力与探索范围,具有广阔的应用前景。世界上各航天大国已经开展了大量的在轨验证研究,如加拿大的航天飞机机械臂系统(Shuttle Remote Manipulator System,SRMS)、国际空间站机械臂系统(Mobile Servicing System,MSS)、欧洲机械臂系统(EuropeanRobotic Arm,ERA)以及日本的ETS-VII机械臂系统和实验舱远程操作系统(JEMRMS)、美国轨道快车(Orbital Express)计划、中国空间站机械臂系统等。
在轨操作期间,空间机器人将不可避免地与目标产生接触,一旦接触力过大或失控将严重威胁整个航天器系统的安全,造成不可估量的经济损失。因此,研究空间机器人与目标的安全交互技术,是在轨操作任务的核心,对各国空间技术的发展具有重要的意义。为实现安全交互的目标,通常采用阻抗控制方法对外力作出响应以顺应接触环境。但传统阻抗参数固定的方法无法适应复杂多变的操作任务,这要求阻抗参数能够根据不同交互环境进行自我调节。实现变阻抗控制的常用方法包括自适应控制(CN112372637A)、迭代学习控制(CN113043266A)等,但传统自适应控制方法无法保证最优交互性能,而迭代学习控制则需要机器人重复操作训练。
强化学习作为一种智能算法,能够从最优控制的角度处理系统模型部分已知、模型完全未知等问题,已经在不同领域得到了发展与应用。在处理阻抗控制问题时,强化学习算法能够在交互模型未知情况下,通过历史采样数据学习得到最优阻抗参数,避免了传统固定阻抗参数、迭代学习方法需要多次选择或实验的问题,且能够保证交互过程的最优性。现有基于强化学习的最优自适应阻抗控制技术(X.Liu,S.S.Ge,F.Zhao,and X.Mei,“Optimized Interaction Control for Robot Manipulator Interacting WithFlexible Environment,”IEEE/ASME Transactions on Mechatronics,vol.26,no.6,pp.2888-2898,2021;X.Liu,S.S.Ge,F.Zhao,and X.Mei,“Optimized ImpedanceAdaptation of Robot Manipulator Interacting With Unknown Environment,”IEEETransactions on Control Systems Technology,vol.29,no.1,pp.411-419,2021)均基于离散化的交互模型设计,但真实系统中的交互模型均为连续系统,模型的离散化将不可避免地影响学习精度。此外,基于连续系统设计的强化学习算法涉及积分与导数问题,相比于离散学习算法具有更大的理论挑战。因此本发明针对连续交互系统,考虑末端速度可测与不可测两种工况,设计了基于采样数据的无模型强化学习阻抗控制方法,实现空间机器人与目标间的安全、智能及最优交互,为增强空间机器人在轨操作的智能自主水平提供了理论基础和技术支撑。
发明内容
为解决上述技术问题,考虑空间机器人复杂多样的在轨操作任务,针对现有控制方法需要重复实验、依赖全状态测量、无法满足最优交互性能等问题,本发明提供一种基于采样数据的空间机器人最优阻抗学习方法。该方法基于阻抗控制、状态重构技术和基于异策略的积分强化学习算法发展而来,能够在末端速度不可测、交互模型完全未知的情况下,利用采样数据自主学习阻抗控制参数并保证最优交互性能,可用于空间机器人在轨操作过程的最优阻抗控制。
为达到上述目的,本发明采用的技术方案为:
一种基于采样数据的空间机器人最优阻抗学习方法,针对交互模型完全未知、末端速度不可测的空间机器人系统的最优阻抗控制问题;首先,基于凯恩方程建立包含末端交互力的多自由度空间机器人动力学模型,利用质量-弹簧-阻尼器对交互模型进行近似描述;其次,根据控制目标设计交互性能函数,将最优阻抗控制问题转换为特殊的线性二次型跟踪(LQT)问题;然后,假设末端位置、速度可测,设计基于全状态反馈的异策略无模型积分强化学习方法求解最优阻抗参数;最后,针对末端速度信息缺失的情形,利用状态重构技术设计基于历史数据反馈的异策略无模型积分强化学习算法,实现最优阻抗控制。具体实施步骤如下:
(1)基于凯恩方程建立包含末端交互力的多自由度空间机器人动力学模型,利用质量-弹簧-阻尼器对交互模型进行近似描述;
利用凯恩方程建立包含末端交互力的多自由度空间机器人动力学模型如下:
其中,q表示空间机器人系统的广义坐标,
末端交互力F
式中,M
阻抗控制器的表达式为:
式中,M
将交互模型与阻抗控制器相加,得到阻抗交互系统表达式如下:
其中,x
取状态变量
其中,
其中,y表示系统的输出向量,当速度与末端位置均可测时,输出矩阵C表示为
(2)根据控制目标设计交互性能函数,将最优阻抗控制问题转换为一种特殊的线性二次型跟踪(LQT)问题;
假设末端期望轨迹x
式中,
将性能函数设置为以下含折扣因子的形式:
V(y(t),x
其中,Q
然后构造增广系统的状态为Ξ=[ξ
从而性能函数改写为:
V(Ξ(t))=∫
其中,Q=[0,I,-I]
最优控制器表示为u
当增广系统不存在Gx
(3)假设末端位置、速度可测,设计基于全状态反馈的异策略无模型积分强化学习方法求解最优阻抗参数;
若阻抗交互系统末端位置、速度可测量,为了学习最优阻抗参数,基于全状态反馈的异策略无模型积分强化学习算法如下:
a)初始化:给定一个初始稳定的控制策略u
b)求解核矩阵P
其中,Δt表示系统采样周期;第i时刻Q
c)收敛条件:判断迭代停止条件||P
(4)针对末端速度信息缺失的情形,利用状态重构技术设计基于历史数据反馈的异策略无模型积分强化学习算法;
若阻抗交互系统末端位置可测、速度不可测量,则其增广系统的全状态信息Ξ通过历史输入输出数据重构,表达式为:
其中,
其中,U
将重构状态表达式应用至第三步中设计的基于全状态反馈的异策略无模型积分强化学习算法,则得到基于历史数据反馈的异策略无模型积分强化学习算法如下:
a)初始化:给定一个初始稳定的控制策略u
b)求解核矩阵
其中,第i时刻的核矩阵
c)收敛条件:判断迭代停止条件
本发明与现有技术相比的优点在于:
1)本发明针对末端位置、速度可测的交互系统,所设计的算法通过单次数据采样自主学习最优阻抗参数,在模型完全未知情况下能够实现最优交互控制;
2)本发明针对末端速度不可测的交互系统,利用不依赖于控制器表达式的状态重构技术对现有积分强化学习方法进行了改进,克服了探索噪声对重构精度的影响;改进的算法被应用于模型完全未知的最优阻抗学习控制;
3)本发明涉及的阻抗学习算法均针对连续时间系统设计,并考虑了环境位置的影响,更接近于真实系统;可用于空间机器人在轨操作过程的智能、安全交互控制。
附图说明
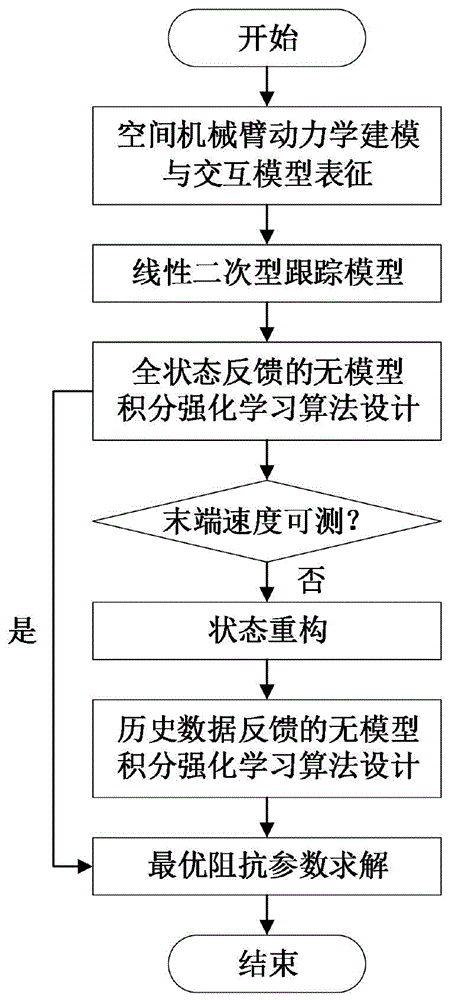
图1为本发明的一种基于采样数据的空间机器人最优阻抗学习方法的流程框图;
图2为空间机器人及交互模型示意图;
图3为两种工况下近似最优增益和理论最优增益的末端位置响应曲线;
图4为两种工况下近似最优增益和理论最优增益的交互力响应曲线。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
如图1所示,本发明的一种基于采样数据的空间机器人最优阻抗学习方法具体实现步骤如下:
第一步,针对图2所示的空间机器人系统,基于凯恩方程建立包含末端交互力的多自由度空间机器人动力学模型,并利用质量-弹簧-阻尼器对交互模型进行近似描述;
利用凯恩方程建立包含末端交互力的多自由度空间机器人动力学模型如下:
其中,q表示空间机器人系统的广义坐标,
在实施过程中,采用空间六自由度机械臂系统进行仿真实验,系统参数如下所示:
其中,“#”处基体的长度实际上应该是臂杆1与基体的连接点在基体中的位置矢量,为[-10.88;-2.45;0.93]m。
末端交互力F
式中,M
阻抗控制器的表达式为:
式中,M
将交互模型与阻抗控制器相加,得到阻抗交互系统表达式如下:
其中,x
取状态变量
其中,
其中,y表示系统的输出向量,当速度与末端位置均可测时,输出矩阵C表示为
第二步,根据控制目标设计交互性能函数,将最优阻抗控制问题转换为一种特殊的线性二次型跟踪(LQT)问题;
假设末端期望轨迹x
式中,
将性能函数设置为以下含折扣因子的形式:
V(y(t),x
其中,t表示当前时间;对称权重矩阵取为Q
然后构造增广系统的状态为Ξ=[ξ
从而性能函数改写为:
V(Ξ(t))=∫
其中,Q=[0,I,-I]
最优控制器表示为u
当增广系统不存在Gx
第三步,假设末端位置、速度可测,设计基于全状态反馈的异策略无模型积分强化学习方法求解最优阻抗参数;
若阻抗交互系统末端位置、速度可测量,为了学习最优阻抗参数,基于全状态反馈的异策略无模型积分强化学习算法如下:
a)初始化:给定一个初始稳定的控制策略u
b)求解核矩阵P
其中,Δt表示系统采样周期;第i时刻Q
c)收敛条件:判断迭代停止条件||P
第四步,针对末端速度信息缺失的情形,利用状态重构技术设计基于历史数据反馈的异策略无模型积分强化学习算法;
若阻抗交互系统末端位置可测、速度不可测量,则其增广系统的全状态信息Ξ通过历史输入输出数据重构,表达式为:
其中,
其中,U
将重构状态表达式应用至第三步中设计的基于全状态反馈的异策略无模型积分强化学习算法,则得到基于历史数据反馈的异策略无模型积分强化学习算法如下:
a)初始化:给定一个初始稳定的控制策略u
b)求解核矩阵
其中,第i时刻的核矩阵
c)收敛条件:判断迭代停止条件
仿真步长/采样周期设置为Δt=5ms,用于恢复状态信息的采样数据点数量N=2,为了满足满秩条件,搜集数据用的初始控制策略需设置探索噪声u
当末端速度、位置均可测量时,可将第三步中的学习算法应用于阻抗控制,得到末端位置和交互力响应曲线如图3和图4所示。其中A1
当末端速度不可测、位置可测量时,可将第四步中的学习算法应用于阻抗控制,得到末端位置和交互力响应曲线如图3和图4所示。其中A2
根据图3和图4可知,在末端速度可测/不可测时,两种算法的近似最优解和理论最优解得到的阻抗控制响应曲线几乎完全重合,误差在可接受范围内;第四步设计的算法与第三步设计的算法得到的响应曲线仅在过渡阶段略有区别,在达到稳定时,力/位置曲线几乎完全重合,误差在可接受范围内。这验证了本发明设计方法的有效性。
本发明说明书中未作详细描述的内容属于本领域专业技术人员公知的现有技术。本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。