数据处理方法、数据处理系统、电子设备和可读存储介质
文献发布时间:2023-06-19 19:23:34
技术领域
本申请属于数据处理技术领域,具体涉及一种数据处理方法、数据处理系统、电子设备和可读存储介质。
背景技术
在文本分析中,采用词频分析方法统计词汇的词频,从而通过词频来评估一个词汇对于一个文件的重要程度。但是,相关技术中的词频分析方法,存在数据读取速度慢、由于在磁盘中读写中间结果而降低计算速度等问题。当文本数据出现指数级增长时,不能保证词频统计工作在周期时间内正常完成。
发明内容
本申请实施例的目的是提供一种数据处理方法、数据处理系统、电子设备和可读存储介质,能够解决相关技术中的词频分析方案无法使计算任务正常完成的问题。
第一方面,本申请实施例提供了一种数据处理方法,用于数据处理系统,数据处理系统包括内存模块、调度节点和多个计算节点,该数据处理方法包括:
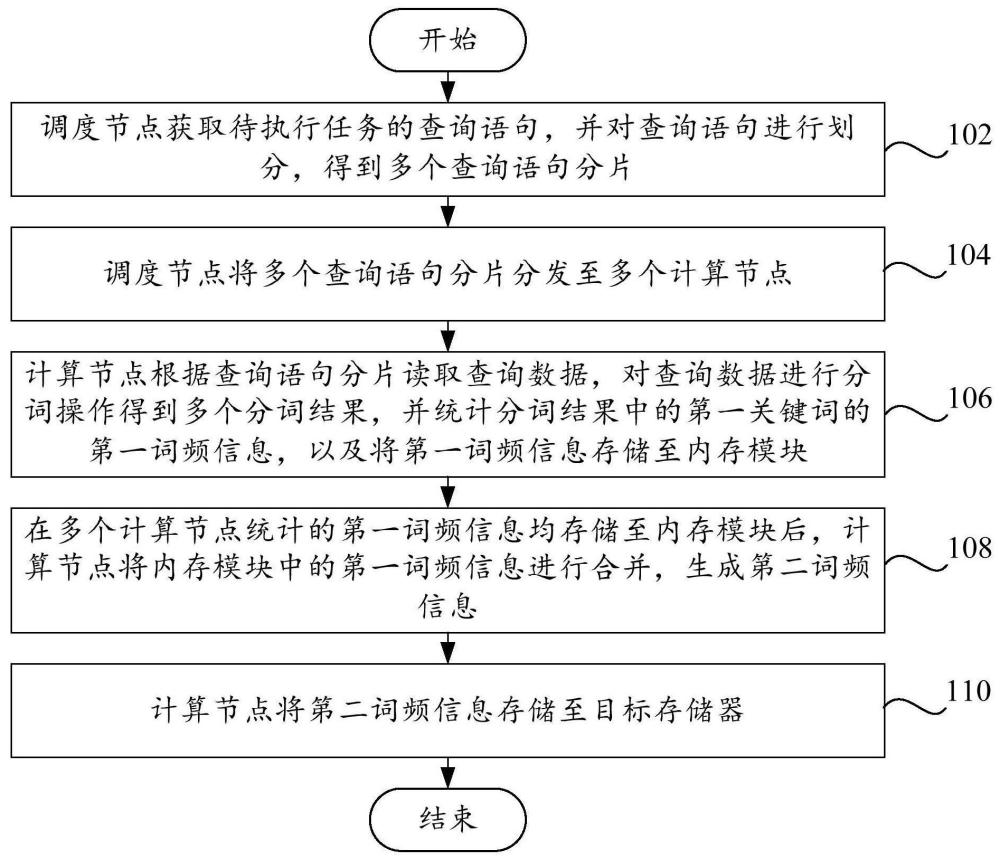
调度节点获取待执行任务的查询语句,并对查询语句进行划分,得到多个查询语句分片;
调度节点将多个查询语句分片分发至多个计算节点;
计算节点根据查询语句分片读取查询数据,对查询数据进行分词操作得到多个分词结果,并统计分词结果中的第一关键词的第一词频信息,以及将第一词频信息存储至内存模块;
在多个计算节点统计的第一词频信息均存储至内存模块后,计算节点将内存模块中的第一词频信息进行合并,生成第二词频信息;
计算节点将第二词频信息存储至目标存储器。
第二方面,本申请实施例提供了一种数据处理系统,包括内存模块、调度节点和多个计算节点;
其中,调度节点用于:获取待执行任务的查询语句,并对查询语句进行划分,得到多个查询语句分片,以及将多个查询语句分片分发至多个计算节点;
计算节点用于:根据查询语句分片读取查询数据,对查询数据进行分词操作得到多个分词结果,统计分词结果中的第一关键词的第一词频信息,并将第一词频信息存储至内存模块,以及在多个计算节点统计的第一词频信息均存储至内存模块后,将内存模块中的第一词频信息进行合并,生成第二词频信息,并将第二词频信息存储至目标存储器。
第三方面,本申请实施例提供了一种电子设备,该电子设备包括处理器、存储器及存储在存储器上并可在处理器上运行的程序或指令,程序或指令被处理器执行时实现如第一方面的方法的步骤。
第四方面,本申请实施例提供了一种可读存储介质,可读存储介质上存储程序或指令,程序或指令被处理器执行时实现如第一方面的方法的步骤。
第五方面,本申请实施例提供了一种芯片,芯片包括处理器和通信接口,通信接口和处理器耦合,处理器用于运行程序或指令,实现如第一方面的方法。
在本申请实施例中,数据处理系统包括内存模块、调度节点、多个计算节点以及客户端,客户端接收用户输入的对待执行任务的查询语句,调度节点获取该查询语句,并将该查询语句进行划分,生成多个查询语句分片。调度节点进而将每一个查询语句分片对应发送至计算节点,利用该计算节点完成数据读取和词频计算的任务。具体地,在该计算节点上,根据查询语句分片读取查询数据,然后根据用户在客户端输入的具体的分词算法对读取到的查询数据进行分词操作,得到多个分词结果,分词结果包括多个关键词,统计分词结果中的第一关键词的第一词频信息,并将第一词频信息存储在内存模块中。需要说明的是,进行分词操作后得到第一关键词计算节点可以为一个或多个,则在该一个或多个计算节点均进行词频统计后,统计到的第一关键词的第一词频信息均被存储至内存模块中。进一步地,将内存模块中存储的第一词频信息进行合并汇总,得到第一关键词的第二词频信息,并将第二词频信息存储至目标存储器(即Mysql)。通过上述方式,一方面,通过查询语句分片的形式读取查询数据,并将查询数据读入不同计算节点,从而提高了数据的读取效率。另一方面,词频统计结果内存化,使得计算节点可以根据关键词远程读取数据,避免词频统计结果写回磁盘造成的时间开销,提高了计算速度。
附图说明
图1是本申请实施例的数据处理方法的流程示意图;
图2是本申请实施例的数据处理系统的示意框图;
图3是本申请实施例的数据处理系统的系统架构图;
图4是本申请实施例的词频计算的逻辑示意图之一;
图5是本申请实施例的词频计算的逻辑示意图之二;
图6是本申请实施例的电子设备的示意框图之一;
图7是本申请实施例的电子设备的示意框图之二。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚地描述,显然,所描述的实施例是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员获得的所有其他实施例,都属于本申请保护的范围。
本申请的说明书和权利要求书中的术语“第一”、“第二”等是用于区别类似的对象,而不用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便本申请的实施例能够以除了在这里图示或描述的那些以外的顺序实施。此外,说明书以及权利要求中“和/或”表示所连接对象的至少其中之一,字符“/”,一般表示前后关联对象是一种“或”的关系。
下面结合附图,通过具体的实施例及其应用场景对本申请实施例提供的数据处理方法、数据处理系统、电子设备和可读存储介质进行详细地说明。
本申请实施例提供一种数据处理方法,用于数据处理系统,数据处理系统包括内存模块、调度节点和多个计算节点,如图1所示,该数据处理方法包括:
步骤102,调度节点获取待执行任务的查询语句,并对查询语句进行划分,得到多个查询语句分片;
步骤104,调度节点将多个查询语句分片分发至多个计算节点;
步骤106,计算节点根据查询语句分片读取查询数据,对查询数据进行分词操作得到多个分词结果,并统计分词结果中的第一关键词的第一词频信息,以及将第一词频信息存储至内存模块;
步骤108,在多个计算节点统计的第一词频信息均存储至内存模块后,计算节点将内存模块中的第一词频信息进行合并,生成第二词频信息;
步骤110,计算节点将第二词频信息存储至目标存储器。
在该实施例中,数据处理系统包括内存模块、调度节点、多个计算节点以及客户端,客户端接收用户输入的对待执行任务的查询语句,调度节点获取该查询语句,并将该查询语句进行划分,生成多个查询语句分片。调度节点进而将每一个查询语句分片对应发送至计算节点,利用该计算节点完成数据读取和词频计算的任务。具体地,在该计算节点上,根据查询语句分片读取查询数据,然后根据用户在客户端输入的具体的分词算法对读取到的查询数据进行分词操作,得到多个分词结果,分词结果包括多个关键词,例如包括Apple、Boy、Cat、Dog,进而统计分词结果中的第一关键词的第一词频信息,例如,第一关键词为Dog,其第一词频信息为6,并将第一词频信息存储在内存模块中。
需要说明的是,进行分词操作后得到第一关键词计算节点可以为一个或多个,则在该一个或多个计算节点均进行词频统计后,统计到的第一关键词的第一词频信息均被存储至内存模块中。
进一步地,将内存模块中存储的第一词频信息进行合并汇总,得到第一关键词的第二词频信息,并将第二词频信息存储至目标存储器(即Mysql),例如,对于第一关键词dog,在第一个计算节点上统计其词频为6,在第二个计算节点上统计其词频为3,则第一关键词dog合并汇总后的词频(即第二词频信息)为9。
通过上述方式,一方面,通过查询语句分片的形式读取查询数据,并将查询数据读入不同计算节点,从而提高了数据的读取效率。另一方面,词频统计结果内存化,使得计算节点可以根据关键词远程读取数据,避免词频统计结果写回磁盘造成的时间开销,提高了计算速度。
本申请实施例通过读取效率、计算速度的提高,能够解决大数据场景下的离线词频分析问题,保障十亿级别文本数据下的离线任务正常完成。
进一步地,在本申请的一个实施例中,对查询语句进行划分,得到多个查询语句分片的步骤,包括:获取多个计算节点的节点数量;根据节点数量以及查询语句对应的查询时间,对查询语句进行划分,得到多个查询语句分片。
在该实施例中,根据当前的计算节点的节点数量,将查询语句按照查询时间段进行分片,进而能够通过查询语句分片的形式读取查询数据,并将查询数据读入不同计算节点,提高数据的读取效率。
进一步地,在本申请的一个实施例中,根据节点数量以及查询语句对应的查询时间段,对查询语句进行划分,得到多个查询语句分片的步骤,包括:按照节点数量,对查询语句对应的查询时间段进行平均划分,从而将查询语句划分为多个查询语句分片;其中,每个计算节点对应的查询语句分片的数量相等。
在该实施例中,根据当前的计算节点的节点数量,将查询语句按照查询时间段进行分片,分片规则为将查询时间段均分切割,即,将总的查询时间范围,按左开右闭的规则,均分为n等分,其中n是节点数量m的倍数,具体倍数可由用户设置。
通过上述按照对查询时间段均分切割的方式将查询语句进行分片,且每个计算节点被分配到的查询语句分片的数量相等,使得每个计算节点被分配到的查询数据量相对平衡,以提高对词频的计算速度。
进一步地,在本申请的一个实施例中,计算节点根据查询语句分片读取查询数据的步骤,包括:计算节点根据查询语句分片,从ClickHouse存储器中读取查询数据。
在该实施例中,引入列式存储器ClickHouse,其具有速度块、多索引等特点,将其作为底层数据存储源。由于查询数据的数据量大,Mysql或ES无法满足快速查询需求,所以将查询数据存储在ClickHouse存储器中,能够保证查询数据的查询速度。
进一步地,在本申请的一个实施例中,将第一词频信息存储至内存模块的步骤,包括:将第一词频信息按照WordSet的形式,存储至内存模块。
在该实施例中,在计算出第一词频信息后,将第一词频信息通过WordSet的形式保存在内存模块中,并且可以被远程拉取到指定的计算节点上,由此,计算的中间结果可以高效地转给下一个计算节点,提高了计算速度。
需要说明的是,WordSet为一个逻辑概念,也即一个HashMap,用于存储词频信息。
进一步地,在本申请的一个实施例中,该数据处理方法还包括:计算节点统计分词结果中的第二关键词在第i-1个查询时间段的第三词频信息以及在第i个查询时间段的第四词频信息,并将第三词频信息和第四词频信息按照预设格式,形成第五词频信息,其中,i为大于或等于2的正整数;计算节点将第五词频信息存储至内存模块;在多个计算节点统计的第五词频信息均存储至内存模块后,计算节点将内存模块中第五词频信息进行合并,生成第六词频信息;计算节点根据第六词频信息,计算第二关键词的词频增长率。
在该实施例中,在每个查询时间段进行第二关键词的词频统计,具体为,在一个查询时间段内进行对查询语句进行分片、对应读取查询数据、将查询数据进行分词操作得到分词结果、计算分词结果中的第二关键词的词频信息的过程。进而将第二关键词在相邻两个查询时间段(即第i-1个查询时间段和第i个查询时间段)中的第三词频信息和第四词频信息按照预设格式“第二关键词:(p:q)”进行记录,即,记录为该第二关键词的第五词频信息,其中,p为该第二关键词在第i-1个查询时间段内的第三词频信息,q为该第二关键词在第i个查询时间段内的第四词频信息,例如Apple:(1:5)表示第二关键词Apple在前一个查询时间段内的词频为1,在当前查询时间段内的词频为5。再将第二关键词的第五词频信息存储在内存模块中。
进一步地,在多个计算节点统计的第五词频信息均存储至内存模块后,将内存模块中的第五词频信息进行合并,生成第六词频信息,第六词频信息包括第二关键词在第i-1个查询时间段的总词频信息和第二关键词在第i个查询时间段的总词频信息。例如,如图5所示,第一个计算节点对应的一个第二关键词Cat的第五词频信息为(4:7),第二个计算节点对应的一个第二关键词Cat的第五词频信息为(3:6),第三个计算节点对应的一个第二关键词Cat的第五词频信息为(2:8),则合并后该第二关键词Cat的第六词频信息为(9:21)。从而根据第i-1个查询时间段的总词频信息和第二关键词在第i个查询时间段的总词频信息,计算第二关键词的词频增长率,也即第二关键词Cat的词频增长率为133%。
需要说明的是,可以根据哈希值或首字母,确定相同的关键词将相同的关键词作为一组,并且每个计算节点可以处理一组或多组的关键词,例如,如图5所示,将首字母相同的关键词作为一组,第一个计算节点的Executor可处理首字母为A的关键词组以及首字母为D的关键词组。
本申请实施例,统计当前时间区间和前一时间区间某个关键词的词频,这样,关键词的前后词频出现次数在计算节点的单个Executor中统计完成,然后再根据前后差值可以计算出词频增长率,无需在得到两个时间区间内的所有词频数据后再计算词频,从而提高了词频增长率计算速度,能够快速地确定出飙升词(即词频增长率较大的关键词)。
需要说明的是,本申请实施例提供的数据处理方法,执行主体可以为数据处理系统,或者,该数据处理系统中的用于执行数据处理方法的控制模块。本申请实施例中以数据处理系统执行数据处理方法为例,说明本申请实施例提供的数据处理系统。
本申请实施例提出一种数据处理系统,如图2所示,该数据处理系统200包括内存模块202、调度节点204和多个计算节点206;
其中,调度节点204用于:获取待执行任务的查询语句,并对查询语句进行划分,得到多个查询语句分片,以及将多个查询语句分片分发至多个计算节点;
计算节点206用于:根据查询语句分片读取查询数据,对查询数据进行分词操作得到多个分词结果,统计分词结果中的第一关键词的第一词频信息,并将第一词频信息存储至内存模块,以及在多个计算节点统计的第一词频信息均存储至内存模块后,将内存模块中的第一词频信息进行合并,生成第二词频信息,并将第二词频信息存储至目标存储器。
在该实施例中,数据处理系统包括内存模块、调度节点、多个计算节点以及客户端,客户端接收用户输入的对待执行任务的查询语句,调度节点获取该查询语句,并将该查询语句进行划分,生成多个查询语句分片。调度节点进而将每一个查询语句分片对应发送至计算节点,利用该计算节点完成数据读取和词频计算的任务。具体地,在该计算节点上,根据查询语句分片读取查询数据,然后根据用户在客户端输入的具体的分词算法对读取到的查询数据进行分词操作,得到多个分词结果,分词结果包括多个关键词,统计分词结果中的第一关键词的第一词频信息,并将第一词频信息存储在内存模块中。需要说明的是,进行分词操作后得到第一关键词计算节点可以为一个或多个,则在该一个或多个计算节点均进行词频统计后,统计到的第一关键词的第一词频信息均被存储至内存模块中。进一步地,将内存模块中存储的第一词频信息进行合并汇总,得到第一关键词的第二词频信息,并将第二词频信息存储至目标存储器(即Mysql)。通过上述方式,一方面,通过查询语句分片的形式读取查询数据,并将查询数据读入不同计算节点,从而提高了数据的读取效率。另一方面,词频统计结果内存化,使得计算节点可以根据关键词远程读取数据,避免词频统计结果写回磁盘造成的时间开销,提高了计算速度。
进一步地,在本申请的一个实施例中,调度节点204,具体用于获取多个计算节点的节点数量,以及根据节点数量以及查询语句对应的查询时间段,对查询语句进行划分,得到多个查询语句分片。
进一步地,在本申请的一个实施例中,调度节点204,具体用于按照节点数量,对查询语句对应的查询时间段进行平均划分,从而将查询语句划分为多个查询语句分片;其中,每个计算节点对应的查询语句分片的数量相等。
进一步地,在本申请的一个实施例中,计算节点206,具体用于根据查询语句分片,从ClickHouse存储器中读取查询数据。
进一步地,在本申请的一个实施例中,计算节点206,具体用于将第一词频信息按照WordSet的形式,存储至内存模块。
进一步地,在本申请的一个实施例中,计算节点206还用于:统计分词结果中的第二关键词在第i-1个查询时间段的第三词频信息以及在第i个查询时间段的第四词频信息,并将第三词频信息和第四词频信息按照预设格式,形成第五词频信息,其中,i为大于或等于2的正整数;将第五词频信息存储至内存模块;将内存模块中第五词频信息进行合并,生成第六词频信息;根据第六词频信息,计算第二关键词的词频增长率。
在本申请的一个具体实施例中,数据处理系统的架构如图3所示,包括客户端程序(Client Program)、调度层、计算层、数据层等几部分。各个部分的功能如下:
(1)客户端程序为计算任务的发起节点。计算任务的主程序在此处启动,且在此处定义需要执行的具体任务内容。
(2)调度层,负责计算任务的管理和调度工作。客户端程序启动程序后,将任务内容提交到调度层,然后由调度层将任务分片并分发至计算层的各个节点。调度层的工作节点采用主备模式,包括一个主节点(Master)和一个从节点(Standby),通过ZooKeeper进行节点主备管理,以防止出现单点故障(Single Point of Failure,SPOF)。
(3)计算层,负责计算任务的具体执行工作。计算层接收到调度层所分发的任务后,在节点中完成数据读取和计算工作。其中,Worker指单个物理计算节点,具体的计算任务在Executor中执行。对于词频计算任务,数据需要在多个Executor之间进行交换,以完成单个词的数量统计,所以Worker之间可以进行数据交互。
(4)数据层,负责数据的存储工作,包括待读取数据(即查询数据)和计算完成后的词频数据。其中,待读取数据由于数据量大,Mysql或ES无法满足快速查询需求,所以将待读取存储在ClickHouse存储器,ClickHouse存储器是一种列式数据库,具有速度快,多索引等特点,统计完成的词频数据存储在Mysql中。
词频计算的过程包括:
(1)客户端程序向调度层提交计算任务,计算任务内容包括:数据查询语句、分词算法、分词规则、最终结果取值范围等。
(2)调度层收到客户端程序提交的计算任务后,根据当前的Executor数量m,将计算任务的数据查询语句按时间分片,分片规则为时间均分切割,即,将总的查询时间范围,按左开右闭的规则,均分为n等分(n是m的倍数,倍数可设置,此设置的作用是使Worker节点得到的数据量相对平衡)。然后将分片后的查询语句分片分发到计算层的Worker节点(每个查询语句分片仅分发到一个Worker节点),并在调度层记录任务分发情况。
(3)如图4所示,Worker节点收到任务后,启动Executor,并从ClickHouse读取数据,然后根据客户端程序所提交的分词算法,对读取到的数据进行分词操作,然后在本节点按词计数,并将计数结果,按WordSet的形式存储在内存中。计数完成后,向调度层上报Map任务完成。
(4)在所有节点完成Map任务后,调度层向Executor下发Reduce任务,指定具有相同Key的WordSet到某一指定的Executor执行合并计数操作,例如,将所有的WordSet1指定到一个Executor中执行合并计数操作、将所有的WordSet2指定到一个Executor中执行合并计数操作、将所有的WordSet3指定到一个Executor中执行合并计数操作。Reduce任务中,各个Executor拉取WordSet Key值相互独立,根据HashValue的方式进行分配,也即按照哈希值进行分配。合并计数完成后,将计算结果汇总后写入Mysql,并告知调度层任务完成,调度层将任务结束的信息反馈给客户端程序。至此,整个计算任务结束。
如图5所示,对于确定飙升词的方案,具体词频计算的过程如下:
(1)在Executor上执行各个分词的数据统计,统计当前时段的词频与前一时段的词频。本申请实施例提出了WordSet对象格式为“KeyWord:(PreWordNum,CurrentWordNum)”。以Apple:(1:5)数据为例,表示Apple单词,在前一时段内出现了1次,当前时段内出现了5次。在Map任务计算完成后,告知调度层Master节点Map任务完成。
(2)当调度层Master节点收到Map任务完成消息后,告知下游Executor可以开始Reduce任务,并划分Executor拉取WordSet的范围区间(按Hash方式划分)。例如,Executor1拉取首字母A和首字母D开头的WordSet,Executor2拉取首字母B和首字母E开头的WordSet,依次划分,确保同一Key值对应的WordSet不会被分散到多个Executor进行Reduce运算,且所有Map结果均会被Shuffle到下一步的计算节点中。
(3)Executor在Reduce任务中统计当前时段和前一时段某个词汇出现的词频,这样,词汇的前后词频出现次数在单个Executor统计完成,Executor根据前后词频差值可以计算出词频增长率,再根据词频增长率确定出飙升词。
本申请实施例从数据存取和计算方式两个方面优化词频分析性能。首先,通过引入列式存储引擎ClickHouse作为底层数据存储源,并在读取数据时,使用数据按时分片思想,将分片数据读入不同节点,以提升数据读取效率。然后,系统引入了分布式的Worker节点,并延续了MapReduce的设计思路,也即,对数据的计算分为Map任务和Reduce任务两类,将任务分发到多个Worker节点,任务的分发和控制由调度层Master节点完成。并且,在Map任务结束后,Map结果不再返回磁盘合并,而是通过WordSet的形式保存在内存,并在Reduce任务中被远程拉取到指定的Worker节点。这样,计算的中间结果可以高效地转给下一个计算步骤,提高计算速度,并兼顾了系统的可扩展性。此外,对于飙升词的计算,提出了基于WordSet的数据Shuffle的方案,使得词频增长率的计算实现了分布式。
本申请实施例中的数据处理系统200可以是装置,也可以是终端中的部件、集成电路或芯片。该装置可以是移动电子设备,也可以为非移动电子设备。示例性的,移动电子设备可以为手机、平板电脑、笔记本电脑、掌上电脑、车载电子设备、可穿戴设备、超级移动个人计算机(Ultra-Mobile Personal Computer,UMPC)、上网本或者个人数字助理(PersonalDigital Assistant,PDA)等,非移动电子设备可以为服务器、网络附属存储器(NetworkAttached Storage,NAS)、个人计算机(Personal Computer,PC)、电视机(Television,TV)、柜员机或者自助机等,本申请实施例不作具体限定。
本申请实施例中的数据处理系统200可以为具有操作系统的装置。该操作系统可以为安卓(Android)操作系统,可以为ios操作系统,还可以为其他可能的操作系统,本申请实施例不作具体限定。
本申请实施例提供的数据处理系统200能够实现图1的数据处理方法实施例中实现的各个过程,为避免重复,这里不再赘述。
可选的,如图6所示,本申请实施例还提供一种电子设备600,包括处理器602,存储器604,存储在存储器604上并可在处理器602上运行的程序或指令,该程序或指令被处理器602执行时实现上述数据处理方法实施例的各个过程,且能达到相同的技术效果,为避免重复,这里不再赘述。
需要注意的是,本申请实施例中的电子设备包括上述的移动电子设备和非移动电子设备。
图7为实现本申请实施例的一种电子设备的硬件结构示意图。
该电子设备700包括但不限于:射频单元702、网络模块704、音频输出单元706、输入单元708、传感器710、显示单元712、用户输入单元714、接口单元716、存储器718、以及处理器720等部件。
本领域技术人员可以理解,电子设备700还可以包括给各个部件供电的电源(比如电池),电源可以通过电源管理系统与处理器720逻辑相连,从而通过电源管理系统实现管理充电、放电、以及功耗管理等功能。图7中示出的电子设备结构并不构成对电子设备的限定,电子设备可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置,在此不再赘述。
其中,处理器720的数据处理系统包括内存模块、调度节点和多个计算节点,其中,调度节点用于:获取待执行任务的查询语句,并对查询语句进行划分,得到多个查询语句分片,以及将多个查询语句分片分发至多个计算节点;计算节点用于:根据查询语句分片读取查询数据,对查询数据进行分词操作得到多个分词结果,统计分词结果中的第一关键词的第一词频信息,并将第一词频信息存储至内存模块,以及在多个计算节点统计的第一词频信息均存储至内存模块后,将内存模块中的第一词频信息进行合并,生成第二词频信息,并将第二词频信息存储至目标存储器。
在该实施例中,数据处理系统包括内存模块、调度节点、多个计算节点以及客户端,客户端接收用户输入的对待执行任务的查询语句,调度节点获取该查询语句,并将该查询语句进行划分,生成多个查询语句分片。调度节点进而将每一个查询语句分片对应发送至计算节点,利用该计算节点完成数据读取和词频计算的任务。具体地,在该计算节点上,根据查询语句分片读取查询数据,然后根据用户在客户端输入的具体的分词算法对读取到的查询数据进行分词操作,得到多个分词结果,分词结果包括多个关键词,统计分词结果中的第一关键词的第一词频信息,并将第一词频信息存储在内存模块中。需要说明的是,进行分词操作后得到第一关键词计算节点可以为一个或多个,则在该一个或多个计算节点均进行词频统计后,统计到的第一关键词的第一词频信息均被存储至内存模块中。进一步地,将内存模块中存储的第一词频信息进行合并汇总,得到第一关键词的第二词频信息,并将第二词频信息存储至目标存储器(即Mysql)。通过上述方式,一方面,通过查询语句分片的形式读取查询数据,并将查询数据读入不同计算节点,从而提高了数据的读取效率。另一方面,词频统计结果内存化,使得计算节点可以根据关键词远程读取数据,避免词频统计结果写回磁盘造成的时间开销,提高了计算速度。
进一步地,在本申请的一个实施例中,调度节点,具体用于获取多个计算节点的节点数量,以及根据节点数量以及查询语句对应的查询时间段,对查询语句进行划分,得到多个查询语句分片。
进一步地,在本申请的一个实施例中,调度节点,具体用于按照节点数量,对查询语句对应的查询时间段进行平均划分,从而将查询语句划分为多个查询语句分片;其中,每个计算节点对应的查询语句分片的数量相等。
进一步地,在本申请的一个实施例中,计算节点,具体用于根据查询语句分片,从ClickHouse存储器中读取查询数据。
进一步地,在本申请的一个实施例中,计算节点,具体用于将第一词频信息按照WordSet的形式,存储至内存模块。
进一步地,在本申请的一个实施例中,计算节点,还用于:统计分词结果中的第二关键词在第i-1个查询时间段的第三词频信息以及在第i个查询时间段的第四词频信息,并将第三词频信息和第四词频信息按照预设格式,形成第五词频信息,其中,i为大于或等于2的正整数;将第五词频信息存储至内存模块;将内存模块中第五词频信息进行合并,生成第六词频信息;根据第六词频信息,计算第二关键词的词频增长率。
应理解的是,本申请实施例中,射频单元702可用于收发信息或收发通话过程中的信号,具体的,接收基站的下行数据或向基站发送上行数据。射频单元702包括但不限于天线、至少一个放大器、收发信机、耦合器、低噪声放大器、双工器等。
网络模块704为用户提供了无线的宽带互联网访问,如帮助用户收发电子邮件、浏览网页和访问流式媒体等。
音频输出单元706可以将射频单元702或网络模块704接收的或者在存储器718中存储的音频数据转换成音频信号并且输出为声音。而且,音频输出单元706还可以提供与电子设备700执行的特定功能相关的音频输出(例如,呼叫信号接收声音、消息接收声音等等)。音频输出单元706包括扬声器、蜂鸣器以及受话器等。
输入单元708用于接收音频或视频信号。输入单元708可以包括图形处理器(Graphics Processing Unit,GPU)7082和麦克风7084,图形处理器7082对在视频捕获模式或图像捕获模式中由图像捕获装置(如摄像头)获得的静态图片或视频的图像数据进行处理。处理后的图像帧可以显示在显示单元712上,或者存储在存储器718(或其它存储介质)中,或者经由射频单元702或网络模块704发送。麦克风7084可以接收声音,并且能够将声音处理为音频数据,处理后的音频数据可以在电话通话模式的情况下转换为可经由射频单元702发送到移动通信基站的格式输出。
电子设备700还包括至少一种传感器710,比如指纹传感器、压力传感器、虹膜传感器、分子传感器、陀螺仪、气压计、湿度计、温度计、红外线传感器、光传感器、运动传感器以及其他传感器。
显示单元712用于显示由用户输入的信息或提供给用户的信息。显示单元712可包括显示面板7122,可以采用液晶显示器、有机发光二极管等形式来配置显示面板7122。
用户输入单元714可用于接收输入的数字或字符信息,以及产生与电子设备的用户设置以及功能控制有关的键信号输入。具体地,用户输入单元714包括触控面板7142以及其他输入设备7144。触控面板7142也称为触摸屏,可收集用户在其上或附近的触摸操作。触控面板7142可包括触摸检测装置和触摸控制器两个部分。其中,触摸检测装置检测用户的触摸方位,并检测触摸操作带来的信号,将信号传送给触摸控制器;触摸控制器从触摸检测装置上接收触摸信息,并将它转换成触点坐标,再送给处理器720,接收处理器720发来的命令并加以执行。其他输入设备7144可以包括但不限于物理键盘、功能键(比如音量控制按键、开关按键等)、轨迹球、鼠标、操作杆,在此不再赘述。
进一步的,触控面板7142可覆盖在显示面板7122上,当触控面板7142检测到在其上或附近的触摸操作后,传送给处理器720以确定触摸事件的类型,随后处理器720根据触摸事件的类型在显示面板7122上提供相应的视觉输出。触控面板7142与显示面板7122可作为两个独立的部件,也可以集成为一个部件。
接口单元716为外部装置与电子设备700连接的接口。例如,外部装置可以包括有线或无线头戴式耳机端口、外部电源(或电池充电器)端口、有线或无线数据端口、存储卡端口、用于连接具有识别模块的装置的端口、音频输入/输出(I/O)端口、视频I/O端口、耳机端口等等。接口单元716可以用于接收来自外部装置的输入(例如,数据信息、电力等等)并且将接收到的输入传输到电子设备700内的一个或多个元件或者可以用于在电子设备700和外部装置之间传输数据。
存储器718可用于存储软件程序以及各种数据。存储器718可主要包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需的应用程序(比如声音播放功能、图像播放功能等)等;存储数据区可存储根据移动终端的使用所创建的数据(比如音频数据、电话本等)等。此外,存储器718可以包括高速随机存取存储器,还可以包括非易失性存储器,例如至少一个磁盘存储器件、闪存器件、或其他易失性固态存储器件。
处理器720通过运行或执行存储在存储器718内的软件程序和/或模块,以及调用存储在存储器718内的数据,执行电子设备700的各种功能和处理数据,从而对电子设备700进行整体监控。处理器720可包括一个或多个处理单元;优选的,处理器720可集成应用处理器和调制解调处理器,其中,应用处理器主要处理操作系统、用户界面和应用程序等,调制解调处理器主要处理无线通信。
本申请实施例还提供一种可读存储介质,可读存储介质上存储有程序或指令,该程序或指令被处理器执行时实现上述数据处理方法实施例的各个过程,且能达到相同的技术效果,为避免重复,这里不再赘述。
其中,处理器为上述实施例中的电子设备中的处理器。可读存储介质,包括计算机可读存储介质,如计算机只读存储器(Read-Only Memory,ROM)、随机存取存储器(RandomAccess Memory,RAM)、磁碟或者光盘等。
本申请实施例另提供了一种芯片,芯片包括处理器和通信接口,通信接口和处理器耦合,处理器用于运行程序或指令,实现上述数据处理方法实施例的各个过程,且能达到相同的技术效果,为避免重复,这里不再赘述。
应理解,本申请实施例提到的芯片还可以称为系统级芯片、系统芯片、芯片系统或片上系统芯片等。
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者装置不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者装置所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括该要素的过程、方法、物品或者装置中还存在另外的相同要素。此外,需要指出的是,本申请实施方式中的方法和装置的范围不限按示出或讨论的顺序来执行功能,还可包括根据所涉及的功能按基本同时的方式或按相反的顺序来执行功能,例如,可以按不同于所描述的次序来执行所描述的方法,并且还可以添加、省去、或组合各种步骤。另外,参照某些示例所描述的特征可在其他示例中被组合。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本申请的技术方案本质上或者说对现有技术做出贡献的部分可以以计算机软件产品的形式体现出来,该计算机软件产品存储在一个存储介质(如ROM/RAM、磁碟、光盘)中,包括若干指令用以使得一台终端(可以是手机,计算机,服务器,或者网络设备等)执行本申请各个实施例所述的方法。
上面结合附图对本申请的实施例进行了描述,但是本申请并不局限于上述的具体实施方式,上述的具体实施方式仅仅是示意性的,而不是限制性的,本领域的普通技术人员在本申请的启示下,在不脱离本申请宗旨和权利要求所保护的范围情况下,还可做出很多形式,均属于本申请的保护之内。