一种数据盘点方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明具体涉及数据盘点技术领域,具体是一种数据盘点方法。
背景技术
随着数据的重要性日益显著,数据管理成为激发组织数据要素活力、加速数据价值释的关键。数据散落在各个系统、数据结构、数据类型、存储形式、敏感级别、重要程度各不相同,整体看起来就像是一团乱麻,如何盘点理出头绪并不容易。当前主流的数据盘点方法分为:面向IT资源管理模式、面向数据主题模式、面向业务事项模式。
面向IT资源管理模式:数据目录按照企业各应用系统分布、数据流转图进行数据资产梳理并进行分类,IT资源视角有利于IT管理,方便科技部门人员进行数据质量分析、数据应用、规范化开发管理等工作;面向数据主题模式:基于数据仓库的整合主题模型,以及各业务条线的分析报表和分析需求,规划了数据标准体系(分为基础类、分析类和专有类三大类),覆盖当前主要的高价值数据资源项;面向业务事项模式:按部门业务事项(权力事项清单、责任事项清单)逐项梳理和编制,将各部门特有的信息按部门进行分类。
面向IT资源管理模式、面向数据主题模式、面向业务事项模式三种盘点方式可以满足不同的场景的业务需求但也存在一定的缺陷,例如:
面向IT资源模式的缺点在于梳理物理表结构,业务部门较难理解,且受版本和厂商影响大;缺少业务参与,业务环节和数据的关系较难掌握,难认责以及梳理结果对数据整合、数据分析、数据共享和开放的贡献不明显,价值较难体现;
面向数据主题模式的缺点在于不面向业务,较难被业务理解;采用3NF设计,子表多,效率较低;数据质量、数据安全等相关数据治理的认责工作较难开展;数据共享开放较难;
面向业务事项模式的缺点在于存在数据冗余和受业务事项变化的影响。
因此,传统的数据盘点方法存在盘点过程中处理数据量大、处理成本高、处理周期长,盘点结果维护更新困难、业务部门较难理解、难以发现高价值数据等问题,不利于数据价值的发挥。
发明内容
本发明的目的在于提供一种数据盘点方法,以解决上述背景技术中提出的传统的数据盘点方法存在盘点过程中处理数据量大、处理成本高、处理周期长,盘点结果维护更新困难、业务部门较难理解、难以发现高价值数据等问题,不利于数据价值的发挥的问题。
为实现上述目的,本发明提供如下技术方案:
一种数据盘点方法,包括以下步骤:
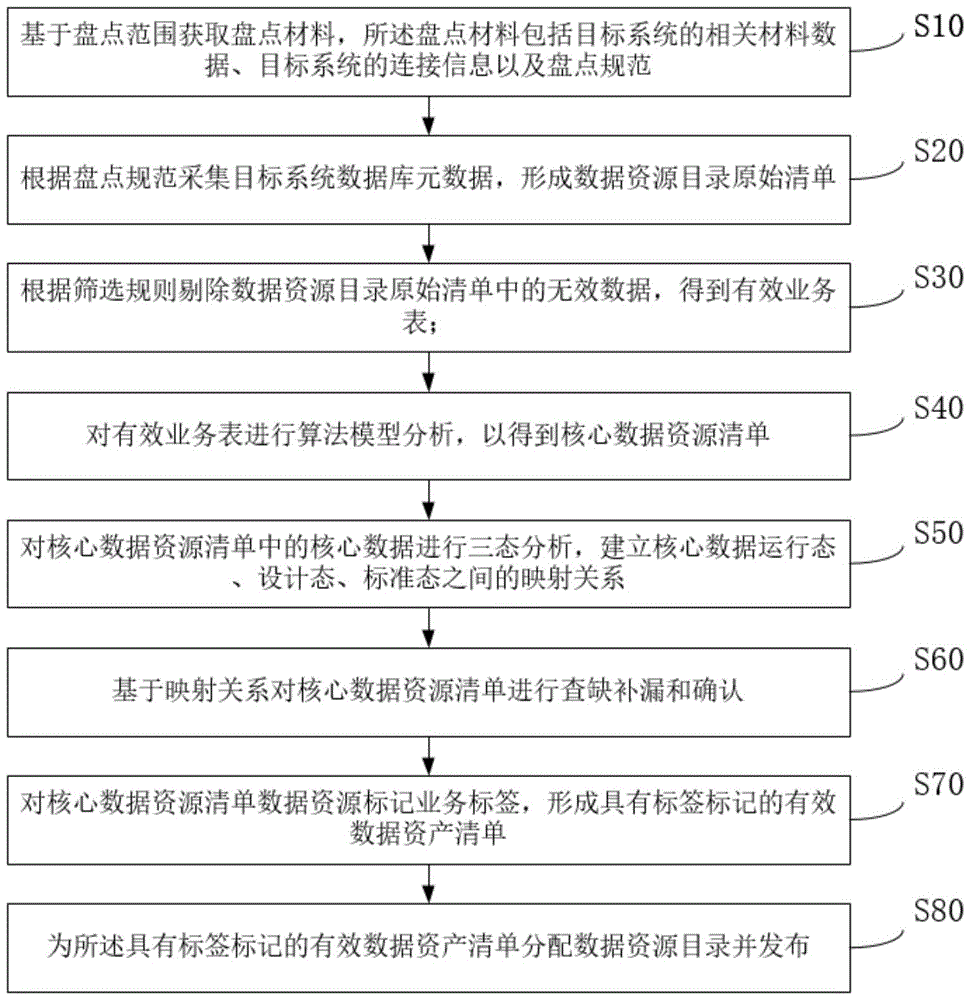
S10、基于盘点范围获取盘点材料,所述盘点材料包括目标系统的相关材料数据、目标系统的连接信息以及盘点规范;
S20、根据盘点规范采集目标系统数据库元数据,形成数据资源目录原始清单,步骤S20中,采集目标系统数据库元数据的方法为:采用JAVA原生开发,支持关系型数据库与非关系型数据库元数据的抽取与识别;元数据采集任务支持手动,定时触发,以及对任务进行暂停、续采、取消操作,自动分表,解决现有采集器,面对数据量大,运行慢,卡住等问题;
S30、根据筛选规则剔除数据资源目录原始清单中的无效数据,得到有效业务表;
S40、对有效业务表进行算法模型分析,以得到核心数据资源清单;
S50、对核心数据资源清单中的核心数据进行三态分析,建立核心数据运行态、设计态、标准态之间的映射关系;
S60、基于映射关系对核心数据资源清单进行查缺补漏和确认,步骤S60中,进行查缺补漏的方法包括对数据资源的技术属性、业务属性和管理属性在内的相关内容进行补录,完善内容包含诸如管理部门、业务描述、备注信息、更新时间等;
进一步的,查缺补漏还包括对数据项的相关信息进行补充和规范,主要完善内容为数据项名称、数据项备注、相关约束条件、计量单位等;
S70、对核心数据资源清单数据资源标记业务标签,形成具有标签标记的有效数据资产清单;
S80、为所述具有标签标记的有效数据资产清单分配数据资源目录并发布。
作为本发明进一步的方案:所述目标系统的相关材料数据包括目标系统的ETL抽取脚本文件、报表脚本文件、全量运行态数据字典、系统功能规格说明书、需求方案、设计文档、用户手册及接口文档,所述目标系统的连接信息包括目标系统的IP地址信息、用户名、密码和数据库名;所述盘点规范包括系统填写模板及填写要求、数据表模板及要求和数据项模板及要求。
作为本发明再进一步的方案:步骤S30中,所述筛选规则包括:通用筛选规则、部分通用筛选规则和个性筛选规则,其中:
(1)通用筛选规则包括空表、备份表、僵尸表、单字段表、系统用户下的系统表筛选;(2)部分通用筛选规则包括垃圾表;(3)个性筛选规则包括临时表和系统配置表。
作为本发明再进一步的方案:步骤S40中,所述核心数据资源清单还包括有对日志文件进行算法模型分析得到的核心数据,所述日志文件包括目标系统的操作日志以及数据库日志。
作为本发明再进一步的方案:对有效业务表进行算法模型分析的方法为:对有效业务表中的数据进行实体消岐和相似度分析,设置阈值,将匹配上的数据作为核心数据;对日志文件进行算法模型分析的方法为:对数据库日志、操作日志进行核心数据识别,以得到核心数据。
作为本发明再进一步的方案:步骤S50中,建立核心数据运行态与设计态之间的映射关系的方法,包括以下步骤:
步骤一、对核心数据运行态和设计态进行实体消岐分析,得到核心数据运行态的真实实体和设计态的真实实体;
步骤二、比对核心数据运行态的真实实体和设计态的真实实体,当两者相同时,建立核心数据运行态与设计态的映射,对实际运营中的数据库结构与设计时的模型文件进行比对分析,识别出二者之间的差异,使相关用户可精确掌握运营中的数据资产与原设计模型中的差别,从而掌握数据结构的变化情况、持续提升数据模型的设计和管理能力。
作为本发明再进一步的方案:步骤S50中,建立核心数据运行态与标准态之间的映射关系的方法,包括以下步骤:
步骤一、对核心数据运行态和标准态进行实体消岐分析,得到核心数据运行态的真实实体和标准态的真实实体;
步骤二、比对核心数据运行态的真实实体和标准态的真实实体,当两者相同时,建立核心数据运行态与标准态的映射,对实际运营中的数据库结构与数据标准进行比对分析,识别出二者之间的差异,检查数据标准执行情况。
作为本发明再进一步的方案:采用基于语料库和知识库进行实体消岐分析,具体方法包括以下步骤:
a、获取数据库中待消岐数据,所述待消岐数据为核心数据运行态、设计态或标准态;
b、识别待消岐数据的命名实体;
c、基于实体消岐算法对命名实体消岐以得到消岐结果。
作为本发明再进一步的方案:步骤S70中,对核心数据资源清单数据资源标记业务标签的方式包括人工为数据资源分类标签和采用自动化工具。
作为本发明再进一步的方案:采用自动化工具标记业务标签的方法,包括以下步骤:
S71、获取核心数据资源清单数据资源和业务标签,每个业务标签具有单独的标签主题,所述标签主题包括系统、数据主题、业务事项、数据安全等级等;
S72、将标签主题与数据资源内容进行相似度匹配,得到与标签主题相同的数据表资源,为所述数据表资源分配所述业务标签;
S73、对分配结果进行校验核对。
与现有技术相比,本发明的有益效果是:
1、本发明在工作范围上通过有效表识别、核心数据识别的步骤过滤无效数据的处理,同时更加精准的确定数据盘点的范围,提升盘点效率;
2、本发明在有效表识别和核心数据资源的识别过程中利用算法模型有效的降低人工工作量,提示识别的效率和准确性;
3、本发明在三态分析方面利用消歧技术提升匹配的准确性,同时区别于传统数据盘点的重点聚集现状梳理,本发明在现状梳理的同时,发现数据管理问题并提出,推动问题解决;
4、本发明通过业务标签标记实现数据目录的多维展示,实现了面向IT资源管理模式、面向数据主题模式、面向业务事项模式优势。
附图说明
图1为数据盘点方法的流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
需要说明的是,下文描述在所附权利要求书的范围内的实施例的各种方面。应显而易见,本文中所描述的方面可体现于广泛多种形式中,且本文中所描述的任何特定结构及/或功能仅为说明性的。基于本公开,所属领域的技术人员应了解,本文中所描述的一个方面可与任何其它方面独立地实施,且可以各种方式组合这些方面中的两者或两者以上。举例来说,可使用本文中所阐述的任何数目个方面来实施设备及/或实践方法。另外,可使用除了本文中所阐述的方面中的一或多者之外的其它结构及/或功能性实施此设备及/或实践此方法。
应当理解,尽管在本发明实施例中可能采用术语第一、第二等来描述各种信息,但这些信息不应限于这些术语。这些术语仅用来将同一类型的信息彼此区分开。
随着数据的重要性日益显著,数据管理成为激发组织数据要素活力、加速数据价值释的关键。数据散落在各个系统、数据结构、数据类型、存储形式、敏感级别、重要程度各不相同,整体看起来就像是一团乱麻,如何盘点理出头绪并不容易。当前主流的数据盘点方法分为:面向IT资源管理模式、面向数据主题模式、面向业务事项模式。
传统的数据盘点方法存在盘点过程中处理数据量大、处理成本高、处理周期长,盘点结果维护更新困难、业务部门较难理解、难以发现高价值数据等问题,不利于数据价值的发挥。
基于此,请参阅图1,本发明实施例中,一种数据盘点方法,包括以下步骤:
S10、基于盘点范围获取盘点材料,所述盘点材料包括目标系统的相关材料数据、目标系统的连接信息以及盘点规范,其中,所述目标系统的相关材料数据包括目标系统的ETL抽取脚本文件、报表脚本文件、全量运行态数据字典、系统功能规格说明书、需求方案、设计文档、用户手册及接口文档,所述目标系统的连接信息包括目标系统的IP地址信息、用户名、密码和数据库名;所述盘点规范包括系统填写模板及填写要求、数据表模板及要求和数据项模板及要求;
步骤S10中,以系统填写模板为例,所述系统填写模板的填写内容包括有系统基本信息和数据库信息,其中:
系统基本信息包括:系统名称:系统名称的全称;系统简称:系统名称的简称;系统主要功能:系统主要功能的简要描述;系统网址:访问该系统的地址,指的是系统的域名或者ip地址;所属部门:系统所属的业务部门;部门接口人员:业务部门盘点工作的对接人员姓名;部门接口人员联系方式:业务部门盘点工作的对接人员联系电话;部门接口人员邮箱:业务部门盘点工作的对接人员邮箱;承建厂商:系统的开发运维单位名称;技术支撑人员:盘点工作技术的接口人员姓名;技术支撑人员联系方式:承建厂商盘点工作的对接人员联系电话;技术支撑人员邮箱:承建厂商盘点工作的对接人员邮箱;
数据库信息包括:数据库类型:业务系统的数据库类型,如Oracle、MySQl等;数据库运行版本:不同类型数据库对应的版本;数据库IP地址:数据库运行访问地址;端口号:数据库运行的端口号;数据库实例名称:数据库中用于支撑业务的相关数据库实例名称;数据库用户名:符合元数据采集要求的数据库用户名称;数据库密码:与数据库用户名对应的密码。
S20、根据盘点规范采集目标系统数据库元数据,以形成数据资源目录原始清单;
在本发明实施例步骤S20中,采集目标系统数据库元数据的方法为:采用JAVA原生开发,支持关系型数据库与非关系型数据库元数据的抽取与识别;元数据采集任务支持手动,定时触发,以及对任务进行暂停、续采、取消操作,自动分表,解决现有采集器,面对数据量大,运行慢,卡住等问题;
进一步的,步骤S20中,元数据抽取与识别的方法,包括以下步骤:
S21、提取元数据,在本发明实施例中,提取元数据的方法包括基于数据库结构提取元数据、基于文件内容提取元数据和基于文件属性提取元数据;
进一步的,所述基于数据库结构提取元数据的方法为:通过JDBC建立数据库连接,根据数据库类型,定位数据库元数据存储对应数据库表信息,获取数据库元数据信息,如MySQL数据库,抽取INFORMATION_SCHEMA.COLUMNS、INFORMATION_SCHEMA.TABLES获取数据表、数据项元数据信息;
还有,基于文件内容提取元数据的方法为:通过读取文件内容中,通过机器学习、规则配置等方式,识别文件关键字或特定位置,获取文件内容元数据信息,如表格文件首行、报告的标题、摘要等。
以及,基于文件属性提取元数据的方法为:通过遍历文件读取文件属性信息,如名称、修改日期、类型、大小等。
S22、将非结构化的元数据转换为结构化数据。
S30、根据筛选规则剔除数据资源目录原始清单中的无效数据,以得到有效业务表;
步骤S30中,所述筛选规则包括:通用筛选规则、部分通用筛选规则和个性筛选规则,其中:
(1)通用筛选规则包括空表、备份表、僵尸表、单字段表、系统用户下的系统表筛选,其中:
空表的筛选方式为:数据表记录数为0的表,即为空表;
备份表的筛选方式为:表英文名称以_bak、_ver、_temp、_tmp、_bak、_ls、_日期(年月日、月日等)、表名+日期(年月日、月日等)结尾的数据表以及表中文名称中包含“备份表”或“备份”等关键字的数据表;
僵尸表的筛选方式为:数据条目数不为0,但数据表已经超过3年未发生过更新的数据表;
(2)部分通用筛选规则包括垃圾表,垃圾表的筛选方式为:包含$符号的数据表基本为垃圾表以及以TEST或其他方式命名的数据表;
(3)个性筛选规则包括临时表和系统配置表,本发明通过数据表创建时间、更新时间、数据记录数、数据表名称等方式进行有效表识别,过滤无效数据表,同时更加精准的确定数据盘点的范围,提升盘点效率,同时对识别出的无效表进行处理,降低数据存储空间,与传统的数据盘点方式只注重数据现在梳理,变成由数据盘点向数据治理的转变。
S40、对有效业务表进行算法模型分析,以得到核心数据资源清单;
进一步的,在本发明实施例步骤S40中,所述核心数据资源清单还包括有对日志文件进行算法模型分析得到的核心数据,所述日志文件包括目标系统的操作日志以及数据库日志;
再进一步的,在本发明实施例中,对有效业务表进行算法模型分析的方法为:对有效业务表中的数据进行实体消岐和相似度分析,设置阈值,将匹配上的数据作为核心数据;对日志文件进行算法模型分析的方法为:对数据库日志、操作日志进行核心数据识别,以得到核心数据,所述核心数据识别方法包括频繁模式分析、网络节点中心性度量、网络桥节点探测等技术;
S50、对核心数据资源清单中的核心数据进行三态分析,建立核心数据运行态、设计态、标准态之间的映射关系,并对映射结果进行人工审核,得到对比分析报告,其中,核心数据运行态为数据库中处于实际运营状态的核心运行数据,设计态为数据库设计文件,标准态为数据元和参考数据标准;
进一步的,在本发明实施例步骤S50中,建立核心数据运行态与设计态之间的映射关系的方法,包括以下步骤:
步骤一、对核心数据运行态和设计态进行实体消岐分析,得到核心数据运行态的真实实体和设计态的真实实体;
步骤二、比对核心数据运行态的真实实体和设计态的真实实体,当两者相同时,建立核心数据运行态与设计态的映射,对实际运营中的数据库结构与设计时的模型文件进行比对分析,识别出二者之间的差异,使相关用户可精确掌握运营中的数据资产与原设计模型中的差别,从而掌握数据结构的变化情况、持续提升数据模型的设计和管理能力;
还有,在本发明实施例步骤S50中,建立核心数据运行态与标准态之间的映射关系的方法,包括以下步骤:
步骤一、对核心数据运行态和标准态进行实体消岐分析,得到核心数据运行态的真实实体和标准态的真实实体;
步骤二、比对核心数据运行态的真实实体和标准态的真实实体,当两者相同时,建立核心数据运行态与标准态的映射,对实际运营中的数据库结构与数据标准进行比对分析,识别出二者之间的差异,检查数据标准执行情况。
再进一步的,在本发明实施例中,采用基于语料库和知识库进行实体消岐分析,具体方法包括以下步骤:
a、获取数据库中待消岐数据,所述待消岐数据为核心数据运行态、设计态或标准态;
b、识别待消岐数据的命名实体;
a、基于实体消岐算法对命名实体消岐以得到消岐结果。
S60、基于映射关系对核心数据资源清单进行查缺补漏和确认,以使业务部门对已经形成的核心数据资源清单做进一步确认和审核,对数据资源的属性进行完善和修订,提升数据资源的完整性和准确性;
具体的,在本发明实施例步骤S60中,进行查缺补漏的方法包括对数据资源的技术属性、业务属性和管理属性在内的相关内容进行补录,完善内容包含诸如管理部门、业务描述、备注信息、更新时间等;
进一步的,查缺补漏还包括对数据项的相关信息进行补充和规范,主要完善内容为数据项名称、数据项备注、相关约束条件、计量单位等。
S70、对核心数据资源清单数据资源标记业务标签,形成具有标签标记的有效数据资产清单;
在本发明实施例步骤S70中,对核心数据资源清单数据资源标记业务标签的方式包括人工为数据资源分类标签和采用自动化工具,以标签识别方式将主题分类匹配至每个数据表资源,然后人工校核分类结果并修正,具体方法如下:
S71、获取核心数据资源清单数据资源和业务标签,每个业务标签具有单独的标签主题,所述标签主题包括系统、数据主题、业务事项、数据安全等级等;
S72、将标签主题与数据资源内容进行相似度匹配,得到与标签主题相同的数据表资源,为所述数据表资源分配所述业务标签;
S73、对分配结果进行校验核对。
步骤S70从系统、数据主题、业务事项、数据安全等级等多个维度构建灵活的数据标签体系,通过业务标签标记实现数据目录的多维展示,实现了面向IT资源管理模式、面向数据主题模式、面向业务事项模式优势,满是技术开发人员、业务管理人员、分析人员的需求,让不同人都能看懂数据目录。
S80、为所述具有标签标记的有效数据资产清单分配数据资源目录并发布。
在本发明实施例步骤S80中,由业务部门对形成的有效数据资产(具有标签标记的有效数据资产清单)进行目录分配,并基于数据敏感程度梳理数据负面清单,从而形成待发布数据资产目录。
数据资源目录的构建形式包括系统级和企业级两个层级,其中:
对于系统级数据目录:系统级数据目录以业务功能为划分维度,对数据资源进行归类管理,按照系统、功能、功能对应的数据资源、数据资源属性等层级进行梳理。
对于企业级数据资源目录:企业级数据资源目录站在全公司的高度、从业务视角对全企业的数据资源进行分类和整合,实现全局的数据资源目录构建,划分方式可根据业务需要采用多种模式和维度进行组合和切换,灵活适应全局需要。
然后由业务主管部门负责组织专家组对数据资源目录进行审核,审核通过后,对各专业目录进行归集整理,编制形成最终版的数据资源目录,并提交互联网部统一发布。
此外,一些实施例可包括具有用于在计算机上执行本说明书中记载的方法的程序的存储介质,其上存储有至少一条指令、至少一段程序、代码集或指令集,该至少一条指令、至少一段程序、代码集或指令集被处理器加载并执行时实现上述各方法实施例中的步骤,计算机可读记录介质的示例包括为了存储并执行程序命令而专门构成的硬件装置:诸如硬盘、软盘及磁带的磁介质、诸如CD-ROM、DVD的光记录介质、诸如软盘的磁光介质及ROM、RAM、闪存等。程序命令的示例可包括:由编译器编写的机器语言代码以及使用解释器等而由计算机来执行的高级语言代。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过至少一条指令、至少一段程序、代码集或指令集来指令相关的硬件来完成,的至少一条指令、至少一段程序、代码集或指令集可存储于一非易失性计算机可读取存储介质中,该至少一条指令、至少一段程序、代码集或指令集在执行时,可包括如上述各方法的实施例的流程。其中,本申请所提供的各实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和易失性存储器中的至少一种。
综上所述,本发明在工作范围上通过有效表识别、核心数据识别的步骤过滤无效数据的处理,同时更加精准的确定数据盘点的范围,提升盘点效率;本发明在有效表识别和核心数据资源的识别过程中利用算法模型有效的降低人工工作量,提示识别的效率和准确性;本发明在三态分析方面利用消歧技术提升匹配的准确性,同时区别于传统数据盘点的重点聚集现状梳理,本发明在现状梳理的同时,发现数据管理问题并提出,推动问题解决;本发明通过业务标签标记实现数据目录的多维展示,实现了面向IT资源管理模式、面向数据主题模式、面向业务事项模式优势。
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
- 一种智能货柜及商品盘点方法
- 一种基于NFC及UHF芯片的物流追溯与仓储盘点系统及方法
- 一种大型仓库中基于无人机的货物精确盘点方法及系统
- 一种快速盘点无线终端的方法
- 一种支持无线数据通讯的智能盘点装置及盘点方法
- 一种盘点设备、盘点管理系统及盘点方法