两个音频通道上的声源的离散双声道空间化
文献发布时间:2024-04-18 19:58:26
技术领域
本公开总体上涉及在头戴式设备(headset)处呈现音频,并且具体涉及耦接到头戴式设备的音频系统的两个音频通道上的声源的离散双声道空间化。
背景技术
空间化多个虚拟声源的常规方法是通过滤波器(例如,与头部相关的传递函数)来提供未空间化的音频信号的一个通道,该滤波器在结合空间线索的同时为每只耳朵生成一个音频通道信号,以在收听者周围的声音场景(即,物理空间)中的特定位置生成对每个虚拟声源的感知。对于具有无线连接的典型人工现实头戴式设备场景(例如,与智能手机或控制台的蓝牙连接),音频信号仅经由两个音频通道而被传输到头戴式设备,这将声音场景限制为两个虚拟声源。
发明内容
本公开的各实施例支持以下方法、计算机可读介质和装置:该方法、计算机可读介质和装置用于对音频系统的两个音频通道上的两个以上声源进行离散双声道空间化以向该音频系统的用户呈现音频内容。音频系统的至少一部分集成在用户所佩戴的头戴式设备中。在音频系统处收集多个声音信号,该多个声音信号各自从多个声源中的对应声源发出。给每个声源分配声音场景的角度范围内的各自虚拟位置。通过根据各自虚拟位置对每个声音信号进行平移(panning),来生成第一多源音频信号和第二多源音频信号。向第一方向空间化第一多源音频信号,以生成第一左信号和第一右信号。向第二方向空间化第二多源音频信号,以生成第二左信号和第二右信号。使用第一左信号、第二左信号、第一右信号和第二右信号来生成双声道信号。由音频系统生成的双声道信号使得每个声源对于用户而言像是源自于各自虚拟位置。
根据本公开的第一方面,提供了一种方法,该方法包括:收集多个声音信号,该多个声音信号各自从多个声源中的对应声源发出;给每个声源分配声音场景的角度范围内的各自虚拟位置;通过根据各自虚拟位置对每个声音信号进行平移,来生成第一多源音频信号和第二多源音频信号;向第一方向空间化第一多源音频信号,以生成第一左信号和第一右信号;向第二方向空间化第二多源音频信号,以生成第二左信号和第二右信号;以及使用第一左信号、第二左信号、第一右信号和第二右信号来生成双声道信号,其中,双声道信号使得每个声源对于用户而言像是源自于各自虚拟位置。
在一些实施例中,该多个声源是与用户进行电话会议的不同的人。
在一些实施例中,该方法还包括:对每个声音信号的第一对应部分进行求和,以生成第一多源音频信号;以及对每个声音信号的第二对应部分进行求和,以生成第二多源音频信号。
在一些实施例中,第一方向与角度范围的第一边界相匹配;并且第二方向与角度范围的第二边界相匹配。
在一些实施例中,生成第一多源音频信号和第二多源音频信号包括:基于相对于第一方向和第二方向的各自虚拟位置,在与第一方向相关联的第一能量和与第二方向相关联的第二能量之间分割每个声音信号的能量。
在一些实施例中,该方法还包括:通过将与第一方向相关联的第一对头相关传递函数(head-related transfer function,HRTF)应用于第一多源音频信号,来空间化第一多源音频信号;以及通过将与第二方向相关联的第二对HRTF应用于第二多源音频信号,来空间化第二多源音频信号。
在一些实施例中,该方法还包括:将第一空间滤波器应用于第一多源音频信号,以向第一方向空间化第一多源音频信号;以及将第二空间滤波器应用于第二多源音频信号,以向第二方向空间化第二多源音频信号。
在一些实施例中,该方法还包括:基于用户的头部移动来更新第一空间滤波器和第二空间滤波器,使得每个声源像是源自于声音场景内固定的各自虚拟位置的。
在一些实施例中,该方法还包括:通过对第一左信号和第二左信号进行求和,来生成双声道信号中用于呈现给用户的左耳的左分量;以及通过对第一右信号和第二右信号进行求和,来生成双声道信号中用于呈现给用户的右耳的右分量。
在一些实施例中,该方法还包括:经由音频系统的转换器阵列将双声道信号呈现给用户。
在一些实施例中,音频系统集成在用户所佩戴的头戴式设备中。
根据本公开的第二方面,提供了一种音频系统,该音频系统包括:非暂态计算机可读存储介质,该非暂态计算机可读存储介质被配置为收集多个声音信号,该多个声音信号各自从多个声源中的对应声源发出;以及音频控制器,该音频控制器耦接到该非暂态计算机可读存储介质,该音频控制器被配置为:给每个声源分配声音场景的角度范围内的各自虚拟位置;通过根据各自虚拟位置对每个声音信号进行平移,来生成第一多源音频信号和第二多源音频信号;向第一方向空间化第一多源音频信号,以生成第一左信号和第一右信号;向第二方向空间化第二多源音频信号,以生成第二左信号和第二右信号;以及使用第一左信号、第二左信号、第一右信号和第二右信号来生成双声道信号,其中,双声道信号使得每个声源像是源自于各自虚拟位置。
在一些实施例中,音频控制器还被配置为:对每个声音信号的第一对应部分进行求和,以生成第一多源音频信号;以及对每个声音信号的第二对应部分进行求和,以生成第二多源音频信号。
在一些实施例中,音频控制器还被配置为:基于相对于第一方向和第二方向的各自虚拟位置,在与第一方向相关联的第一能量和与第二方向相关联的第二能量之间分割每个声音信号的能量,以生成第一多源音频信号和第二多源音频信号。
在一些实施例中,音频控制器还被配置为:通过将与第一方向相关联的第一对头相关传递函数(HRTF)应用于第一多源音频信号,来空间化第一多源音频信号;以及通过将与第二方向相关联的第二对HRTF应用于第二多源音频信号,来空间化第二多源音频信号。
在一些实施例中,音频控制器还被配置为:将第一空间滤波器应用于第一多源音频信号,以向第一方向空间化第一多源音频信号;以及将第二空间滤波器应用于第二多源音频信号,以向第二方向空间化第二多源音频信号。
在一些实施例中,音频控制器还被配置为:基于音频系统的用户的头部移动来更新第一空间滤波器和第二空间滤波器,使得每个声源像是源自于声音场景内固定的各自虚拟位置的。
在一些实施例中,音频控制器还被配置为:通过对第一左信号和第二左信号进行求和,来生成双声道信号中用于呈现给音频系统的用户的左耳的左分量;以及通过对第一右信号和第二右信号进行求和,来生成双声道信号中用于呈现给用户的右耳的右分量。
在一些实施例中,音频系统还包括转换器阵列,该转换器阵列耦接到音频控制器,该转换器阵列被配置为:将所生成的双声道信号呈现给音频系统的用户。
根据本公开的第三方面,提供了一种非暂态计算机可读存储介质,该非暂态计算机可读存储介质上编码有指令,所述指令在被处理器执行时使该处理器:在该非暂态计算机可读存储介质处收集多个声音信号,该多个声音信号各自从多个声源中的对应声源发出;给每个声源分配声音场景的角度范围内的各自虚拟位置;通过根据各自虚拟位置对每个声音信号进行平移,以生成第一多源音频信号和第二多源音频信号;向第一方向空间化第一多源音频信号,以生成第一左信号和第一右信号;向第二方向空间化第二多源音频信号,以生成第二左信号和第二右信号;以及使用第一左信号、第二左信号、第一右信号和第二右信号来生成双声道信号,其中,双声道信号使得每个声源像是源自于各自虚拟位置的。
应理解的是,本文描述为适合于结合到本公开的一个或多个方面或实施例中的任何特征旨在可推广到本公开的任何和所有的方面和实施例。本领域技术人员可以根据本公开的说明书、权利要求书和附图理解本公开的其它方面。上述总体描述和以下详细描述仅是示例性和说明性的,并不对权利要求进行限制。
附图说明
图1A是根据一个或多个实施例的被实现为眼镜设备的头戴式设备的立体图。
图1B是根据一个或多个实施例的被实现为头戴式显示器(head-mounteddisplay,HMD)的头戴式设备的立体图。
图2是根据一个或多个实施例的音频系统的框图。
图3A是根据一个或多个实施例的在图2中的音频系统处实现的离散声源的离散双声道空间化的框图。
图3B示出了根据一个或多个实施例的由图3A中的离散双声道空间化产生的声音场景中的各声源的虚拟位置。
图4是示出了根据一个或多个实施例的多个声源的离散双声道空间化过程的流程图。
图5是根据一个或多个实施例的包括头戴式设备的系统。
这些附图仅出于说明的目的而描绘了各个实施例。本领域技术人员将从以下论述中容易地认识到,可以在不脱离本文所描述的原理的情况下,采用本文所示出的结构和方法的替代实施例。
具体实施方式
本公开的各实施例涉及音频系统的一对音频通道上的两个以上声源(例如,虚拟声源)的离散双声道空间化。本公开描述了一种用于生成源自两个以上声源的双声道信号的方法和系统,使得对于音频系统的用户而言,双声道信号像是源自该用户所佩戴的头戴式设备(例如,人工现实眼镜)周围的声音场景内的各声源的各自虚拟位置。声源的虚拟位置是声音场景内的地点,来自该声源的声音被感知为源自声音场景内的该地点。在一些实施例中,音频系统完全集成到头戴式设备中。在一些其它实施例中,音频系统分布在多个设备之间,例如分布在一计算设备(例如,智能手机或控制台)和与该计算设备接合(例如,经由无线连接)的头戴式设备之间。由于通信带宽要求,音频系统仅利用两个音频通道进行通信,这两个音频通道例如为:位于头戴式设备处的一对音频通道(如果音频系统完全集成到头戴式设备中),或者位于计算设备与头戴式设备之间的一对音频通道(如果音频系统分布在计算设备与头戴式设备之间)。因此,本文所提出的音频系统利用其两个音频通道来执行两个以上声源的离散双声道空间化。本文所提出的音频系统结合幻觉源感知现象来应用局部求和,以在仅利用两个音频通道的同时在声音场景中放置两个以上声源。
本文所提出的音频系统收集多个声音信号,该多个声音信号各自从多个声源中的对应声源发出,以及给每个声源分配声音场景的角度范围内的各自虚拟位置。音频系统通过根据每个声音信号的各自虚拟位置对该每个声音信号进行平移,来生成与声音场景中的第一方向相关联的第一多源音频信号和与声音场景中的第一方向相关联的第二多源音频信号。音频系统向第一方向空间化第一多源音频信号,以生成第一左信号和第一右信号。类似地,音频系统向第二方向空间化第二多源音频信号,以生成第二左信号和第二右信号。音频系统通过组合第一左信号、第二左信号、第一右信号和第二右信号来生成用于呈现给用户的双声道信号。所生成的用于呈现给用户的双声道信号使得每个声源对于用户而言像是源自于该每个生源的各自虚拟位置的。
本文所提出的音频系统应用了一种方案,该方案便于在利用用于在音频系统与头戴式设备之间传输音频信号的现有带宽要求的同时,在头戴式设备的用户周围的声音场景内放置两个以上的虚拟声源。这一点在本文中是通过独立声源的离散空间化来实现的,该离散空间化生成与音频系统的一对音频通道兼容的一对空间化多源音频信号。这一对空间化多源音频信号被馈送到两个音频通道中,以呈现给用户。
本公开的各实施例可以包括人工现实系统或结合人工现实系统来实现。人工现实是在呈现给用户之前已经以某种方式进行了调整的现实形式,该人工现实例如可以包括虚拟现实(virtual reality,VR)、增强现实(augmented reality,AR)、混合现实(mixedreality,MR)、混合现实(hybrid reality)或它们的某种组合和/或衍生物。人工现实内容可以包括完全生成的内容或与采集到的(例如,真实世界)内容相结合而生成的内容。人工现实内容可以包括视频、音频、触觉反馈或它们的某种组合,以上中任何一种可以在单通道或多通道(例如,给观看者带来三维效果的立体视频)中被呈现。另外,在一些实施例中,人工现实还可以与应用、产品、附件、服务或它们的某种组合相关联,这些应用、产品、附件、服务或它们的某种组合用于在人工现实中创建内容,和/或以其它方式在人工现实中使用。提供人工现实内容的人工现实系统可以在各种平台上实现,这些平台包括连接到主计算机系统的可穿戴设备(例如,头戴式设备)、独立可穿戴设备(例如,头戴式设备)、移动设备或计算系统、或能够向一位或多位观看者提供人工现实内容的任何其它硬件平台。
图1A是根据一个或多个实施例的被实现为眼镜设备的头戴式设备100的立体图。在一些实施例中,眼镜设备是近眼显示器(near eye display,NED)。一般而言,头戴式设备100可以被佩戴在用户的面部上,使得内容(例如,媒体内容)使用显示组件和/或音频系统来呈现。然而,头戴式设备100还可以被使用以使得以不同的方式向用户呈现媒体内容。由头戴式设备100所呈现的媒体内容的示例包括一个或多个图像、视频、音频或它们的某种组合。头戴式设备100包括框架,并且可以包括显示组件(该显示组件包括一个或多个显示元件120)、深度摄像头组件(depth camera assembly,DCA)、音频系统以及位置传感器190等其它部件。尽管图1A示出了头戴式设备100的各部件位于头戴式设备100上的示例位置,但是这些部件可以位于头戴式设备100上的其它位置、位于与头戴式设备100配对的外围设备上、或者它们的某种组合。类似地,头戴式设备100上可以存在比图1A中所示出的部件更多的部件或更少的部件。
框架110保持头戴式设备100的其它部件。框架110包括:保持一个或多个显示元件120的前部,以及附接到用户头部的端件(例如,镜腿)。框架110的前部跨过用户鼻子的顶部。端件的长度可以是可调整的(例如,可调整的镜腿长度)以适合不同的用户。端件还可以包括在用户的耳朵后面弯曲的部分(例如,腿套、耳承)。
一个或多个显示元件120向佩戴着头戴式设备100的用户提供光。如所示出的,针对用户的每只眼睛,头戴式设备包括一显示元件120。在一些实施例中,显示元件120生成图像光,该图像光被提供到头戴式设备100的适眼区(eye box)。适眼区是用户在佩戴头戴式设备100时的眼睛所占据的空间中的位置。例如,显示元件120可以是波导显示器。波导显示器包括光源(例如,二维源、一个或多个线源、一个或多个点源等)和一个或多个波导。来自光源的光被内耦合到一个或多个波导中,该一个或多个波导以使得在头戴式设备100的适眼区中存在瞳孔复制的方式输出光。光从一个或多个波导的内耦合和/或外耦合可以使用一个或多个衍射光栅来完成。在一些实施例中,波导显示器包括扫描元件(例如,波导、镜子等),该扫描元件在来自光源的光被内耦合到一个或多个波导中时对该光进行扫描。注意,在一些实施例中,显示元件120中的一者或两者是不透明的,并且不透射来自头戴式设备100周围的局部区域的光。该局部区域是头戴式设备100周围的区域。例如,该局部区域可以是佩戴着头戴式设备100的用户处于其内部的房间,或者佩戴着头戴式设备100的用户可能在外部并且该局部区域是户外区域。在这种背景下,头戴式设备100生成VR内容。替代地,在一些实施例中,显示元件120中的一者或两者是至少部分透明的,使得来自局部区域的光可以与来自该一个或多个显示元件的光组合,以生成AR内容和/或MR内容。
在一些实施例中,显示元件120不生成图像光,而是作为将来自局部区域的光传输到适眼区的透镜(lens)。例如,显示元件120中的一者或两者可以是未矫正(非处方用)的透镜或有助于矫正用户视力缺陷的处方用透镜(例如,单光透镜、双焦和三焦透镜或渐进式透镜)。在一些实施例中,显示元件120可以是偏光的和/或有色的,以保护用户的眼睛免受太阳影响。
在一些实施例中,显示元件120可以包括附加的光学器件块(optics block)(未示出)。光学器件块可以包括将来自显示元件120的光引导到适眼区的一个或多个光学元件(例如,透镜、菲涅耳透镜等)。光学器件块例如可以校正一些或全部图像内容中的像差、放大一些或全部图像、或者它们的某种组合。
DCA确定头戴式设备100周围的局部区域的一部分的深度信息。DCA包括一个或多个成像设备130和DCA控制器(图1A中未示出),并且还可以包括照明器140。在一些实施例中,照明器140利用光来照亮局部区域的一部分。该光例如可以是红外线(infrared,IR)中的结构光(例如,点状图案结构光、条形结构光等)、用于飞行时间(time-of-flight,ToF)的IR闪光灯等。在一些实施例中,一个或多个成像设备130采集局部区域中包括来自照明器140的光的部分的图像。如所示出的,图1A示出了单个照明器140和两个成像设备130。在替代实施例中,不存在照明器140且存在至少两个成像设备130。
DCA控制器使用采集到的图像和一种或多种深度确定技术,来计算局部区域的该部分的深度信息。深度确定技术例如可以是直接飞行时间(ToF)深度感测、间接ToF深度感测、结构光、被动式立体分析、主动式立体分析(使用通过来自照明器140的光而添加到场景中的纹理)、用于确定场景的深度的一些其它技术、或它们的某种组合。
音频系统提供音频内容。音频系统包括转换器阵列、传感器阵列和音频控制器150。然而,在其它实施例中,音频系统可以包括不同的部件和/或附加的部件。类似地,在一些情况下,参考音频系统中的各部件描述的功能可以按照与本文所描述的方式不同的方式分布在这些部件之中。例如,音频控制器150的一些或全部功能可以由远程服务器执行。
转换器阵列向用户呈现声音。转换器阵列包括多个转换器。转换器可以是扬声器160或组织转换器170(例如,骨传导转换器或软骨传导转换器)。尽管扬声器160被示出为在框架110的外部,但是扬声器160可以封闭在框架110中。组织转换器170耦接到用户的头部,并直接振动用户的组织(例如,骨或软骨)以产生声音。根据本公开的各实施例,转换器阵列包括两个转换器(例如,两个扬声器160、两个组织转换器170、或者一个扬声器160和一个组织转换器170),即每只耳朵一个转换器。各转换器的位置可以与图1A中所示出的位置不同。
传感器阵列检测头戴式设备100的局部区域内的声音。传感器阵列包括多个声学传感器180。声学传感器180采集从局部区域(例如,房间)中的一个或多个声源发出的声音。每个声学传感器被配置为检测声音并将检测到的声音转换为电子格式(模拟或数字)。声学传感器180可以是声波传感器、传声器、声音转换器或适合于检测声音的类似传感器。
在一些实施例中,一个或多个声学传感器180可以被放置在每只耳朵的耳道中(例如,充当双声道传声器)。在一些实施例中,声学传感器180可以被放置在头戴式设备100的外表面上、被放置在头戴式设备100的内表面上、与头戴式设备100分开(例如,作为某种其它设备的一部分)或它们的某种组合。声学传感器180的数量和/或位置可以与图1A中所示出的数量和/或位置不同。例如,可以增加声学检测位置的数量,以增加收集到的音频信息量以及该信息的灵敏度和/或准确性。声学检测位置可以被定向为使得传声器能够检测佩戴着头戴式设备100的用户周围的宽范围方向上的声音。
音频控制器150对来自传感器阵列的、描述由该传感器阵列检测到的声音的信息进行处理。音频控制器150可以包括处理器和非暂态计算机可读存储介质。音频控制器150可以被配置为生成波达方向(direction of arrival,DOA)估计结果、生成声学传递函数(例如,阵列传递函数和/或头相关传递函数)、追踪声源的地点、在声源的方向上形成波束、对声源进行分类、生成用于扬声器160的声音滤波器、或它们的某种组合。
根据本公开的各实施例,音频控制器150执行音频系统的一对音频通道上的两个以上声源(例如,虚拟声源)的离散双声道空间化。音频控制器150可以生成源自于两个以上声源的双声道信号,使得该双声道信号对于音频系统的用户而言像是源自于头戴式设备100周围的声音场景内的各声源的各自虚拟位置。所生成的双声道信号例如可以经由扬声器160和/或组织转换器170呈现给用户。
音频控制器150可以首先(例如,在非暂态计算机可读存储介质处)收集多个声音信号,该多个声音信号各自从对应声源发出。音频控制器150可以给每个声源分配声音场景的角度范围内的各自虚拟位置。音频控制器150可以通过根据每个声源的各自虚拟位置分割和平移每个声音信号的能量来执行从两个以上声源发出的声音信号的感知定位求和,以生成多源音频信号。可以给音频系统的每个音频通道分配特定的角度方向(例如,与角度范围的边界相匹配的角度方向)。每个多源声音信号可以被馈送到音频系统的各自音频通道中,以便(例如,通过由音频控制器150应用对应的声音滤波器)在特定的角度方向上进行空间化,并生成对于用户而言像是源自于每个声源的各自虚拟位置的双声道信号。
以此方式,音频系统能够在分配给角度范围中的特定角度方向(例如,与角度范围的边界相匹配的角度方向)的一对声源之间添加附加声源(例如,说话者)。在一示例性情况下,音频系统记录(例如,由音频控制器150记录)具有总共三个不同呼叫者(即,声源或说话者)的空间群呼。声音场景的角度范围(例如,120°的角度范围)可以在这三个不同的声源之间均匀地划分,并且给每个声源分配具有对应的角度方向的各自虚拟位置。所有声源可以处于声音场景内的相同高度。一般而言,各声源可以在声音场景内的任意两个点之间传播。
在一些实施例中,可以将多个声源中的两个声源分配给与角度范围的边界相匹配的虚拟位置,例如分配给声音场景中具有+60°角度方向和-60°角度方向的虚拟位置。可以将第三声源分配给其它两个声源之间的中心位置,例如分配给声音场景中具有0°角度方向的虚拟位置。音频控制器150可以在两个音频通道之间均匀地分割(即,平移)来自第三声源的声音信号的能量,并且该来自第三声源的声音信号将表现为源自于声音场景中其它两个声源之间的中心位置。这是因为两个定位线索(例如,与+60°角度方向和-60°角度方向相对应)被感知地求和到与角度方向0°相对应的虚拟位置。其它两个声源的虚拟位置不受影响,因为其它两个声源的声音信号各自具有与单个虚拟位置(例如,具有+60°角度方向或-60°角度方向的虚拟位置)相关联的空间线索。尽管与来自其它两个声源的声音信号混合在一起,但是来自第三声源的声音信号在音频系统的两个音频通道中是相干的,并且只有来自第三声源的声音信号中的那些相干部分受到感知求和定位的影响。
在一些实施例中,音频系统完全集成在头戴式设备100中。在一些其它实施例中,音频系统分布在多个设备之间,例如分布在计算设备(例如,智能手机或控制台)与头戴式设备100之间。计算设备可以(例如,经由有线连接或无线连接)与头戴式设备100接合。在这种情况下,本文所提出的多个处理步骤中的一些处理步骤可以在音频系统集成在计算设备中的一部分处来执行。例如,音频控制器150的一个或多个功能可以在计算设备处实现。结合图2、图3A和图3B、图4以及图5描述了关于音频系统的结构和操作的更多细节。
位置传感器190响应于头戴式设备100的运动而生成一个或多个测量信号。位置传感器190可以位于头戴式设备100的框架110的一部分上。位置传感器190可以包括惯性测量单元(inertial measurement unit,IMU)。位置传感器190的示例包括:一个或多个加速度计、一个或多个陀螺仪、一个或多个磁力计、检测运动的其它合适类型的传感器、用于IMU的误差校正的一类传感器、或它们的某种组合。位置传感器190可以位于IMU的外部、IMU的内部或它们的某种组合。
音频系统可以使用描述头戴式设备100的位置信息(例如,来自位置传感器190)来更新各声源的虚拟位置,使得各声源在位置上相对于头戴式设备100被锁定。在这种情况下,当佩戴着头戴式设备100的用户转动其头部时,各虚拟源的虚拟位置随该头部移动。可替代地,各虚拟源的虚拟位置不相对于头戴式设备100的方位被锁定。在这种情况下,当佩戴着头戴式设备100的用户转动其头部时,各声源的表观虚拟位置不会改变。
在一些实施例中,头戴式设备100可以针对头戴式设备100的位置以及局部区域的模型更新而提供同步定位与地图构建(simultaneous localization and mapping,SLAM)。例如,头戴式设备100可以包括生成彩色图像数据的无源摄像头组件(passive cameraassembly,PCA)。PCA可以包括采集局部区域中的一些或全部区域的图像的一个或多个RGB摄像头。在一些实施例中,DCA中的一些或全部成像设备130也可以用作PCA。由PCA采集的图像和由DCA确定的深度信息可以用于确定局部区域的参数、生成局部区域的模型、更新局部区域的模型、或它们的某种组合。此外,位置传感器190追踪头戴式设备100在房间内的位置(position)(例如,地点(location)和姿势)。以下结合图2、图3A和图3B、以及图5论述了关于头戴式设备100的各部件的附加细节。
图1B是根据一个或多个实施例的被实现为HMD的头戴式设备105的立体图。在描述AR系统和/或MR系统的实施例中,HMD正面的多个部分在可见波段(约380纳米(nm)至750nm)中至少部分透明,并且HMD中位于HMD正面与用户眼睛之间的多个部分至少部分透明(例如,部分透明的电子显示器)。HMD包括前部刚性体115和带175。头戴式设备105包括许多与以上参考图1A所描述的部件相同的部件,但是这些部件被修改为与HMD形状要素集成。例如,HMD包括显示组件、DCA、音频系统和位置传感器190。图1B示出了照明器140、多个扬声器160、多个成像设备130、多个声学传感器180和位置传感器190。扬声器160可以位于各种位置,例如被耦接到带175(如所示出的)、被耦接到前部刚性体115、或者可以被配置为插入用户的耳道内。
图2是根据一个或多个实施例的音频系统200的框图。图1A或图1B中的音频系统可以是音频系统200的实施例。音频系统200为用户生成一个或多个声学传递函数。然后,音频系统200可以使用该一个或多个声学传递函数来为用户生成音频内容。在图2的实施例中,音频系统200包括转换器阵列210、传感器阵列220和音频控制器230。音频系统200的一些实施例具有与本文所描述的部件不同的部件。类似地,在一些情况下,各功能可以以与本文所描述的方式不同的方式分布在各部件之间。
转换器阵列210被配置为呈现音频内容。转换器阵列210包括一对转换器,即每只耳朵一个转换器。转换器是提供音频内容的设备。转换器例如可以是扬声器(例如,扬声器160)、组织转换器(例如,组织转换器170)、提供音频内容的一些其它设备、或它们的某种组合。组织转换器可以被配置为用作骨传导转换器或软骨传导转换器。转换器阵列210可以经由空气传导(例如,经由一个或两个扬声器)、经由骨传导(经由一个或两个骨传导转换器)、经由软骨传导音频系统(经由一个或两个软骨传导转换器)或它们的某种组合来呈现音频内容。
骨传导转换器通过振动用户头部的骨头/组织来产生声学压力波。骨传导转换器可以耦接到头戴式设备的一部分,并且可以被配置为位于耦接到用户头骨的一部分的耳廓后面。骨传导转换器从音频控制器230接收振动指令,并基于接收到的指令振动用户头骨的一部分。来自骨传导转换器的振动产生一种组织传播的声学压力波,该声学压力波绕过鼓膜向用户的耳蜗传播。
软骨传导转换器通过振动用户耳朵的耳软骨的一个或多个部分来产生声学压力波。软骨传导转换器可以耦接到头戴式设备的一部分,并且可以被配置为耦接到耳朵的耳软骨的一个或多个部分。例如,软骨传导转换器可以耦接到用户耳朵的耳廓的后部。软骨传导转换器可以位于外耳周围沿耳软骨的任何地方(例如,耳廓、耳屏、耳软骨的某些其它部分、或它们的某种组合)。振动耳软骨的一个或多个部分可以产生:耳道外的空气传播的声学压力波;组织传播的声学压力波,该组织传播的声学压力波引起耳道的某些部分振动从而在耳道内产生空气传播的声学压力波;或它们的某种组合。所产生的空气传播的声学压力波沿着耳道向鼓膜传播。
转换器阵列210根据来自音频控制器230的指令来生成音频内容。在一些实施例中,音频内容被空间化。空间化的音频内容是像是源自于特定的方向和/或目标区域(例如,局部区域中的对象和/或虚拟对象)的音频内容。例如,空间化的音频内容可以使声音像是源自于位于音频系统200的用户房间的另一端的虚拟歌手。转换器阵列210可以耦接到可穿戴设备(例如,头戴式设备100或头戴式设备105)。在替代实施例中,转换器阵列210可以是与可穿戴设备分开(例如,耦接到外部控制台)的一对扬声器。
传感器阵列220检测传感器阵列220周围的局部区域内的声音。传感器阵列220可以包括多个声学传感器,该多个声学传感器各自检测声波的气压变化、并将检测到的声音转换为电子格式(模拟或数字)。多个声学传感器可以位于头戴式设备(例如,头戴式设备100和/或头戴式设备105)上、用户上(例如,在用户的耳道中)、颈带上、或它们的某种组合上。声学传感器例如可以是传声器、振动传感器、加速度计、或它们的任意组合。在一些实施例中,传感器阵列220被配置为使用多个声学传感器中的至少一些声学传感器来监测由转换器阵列210生成的音频内容。增加传感器的数量可以提高描述由转换器阵列210产生的声场和/或来自局部区域的声音的信息(例如,方向性)的准确性。
音频控制器230控制音频系统200的运行。在图2的实施例中,音频控制器230包括数据存储库235、DOA估计模块240、传递函数模块250、追踪模块260、波束成形模块270和声音滤波器模块280。在一些实施例中,音频控制器230可以位于头戴式设备内部。音频控制器230的一些实施例具有与本文所描述的部件不同的部件。类似地,各功能可以以与本文所描述的方式不同的方式分布在各部件之间。例如,音频控制器230的一些功能可以在头戴式设备外部执行。用户可以选择加入以允许音频控制器230将由头戴式设备采集到的数据传输到头戴式设备外部的系统,并且用户可以选择用于对访问任何此类数据进行控制的隐私设置。
数据存储库235存储用于由音频系统200使用的数据。数据存储库235中的数据可以包括:在音频系统200的局部区域中记录的声音、音频内容、头相关传递函数(HRTF)、一个或多个传感器的传递函数、一个或多个声学传感器的阵列传递函数(array transferfunction,ATF)、声源地点、局部区域的虚拟模型、波达方向估计结果、声音滤波器、声源的虚拟位置、多源音频信号、每只耳朵的转换器(例如,扬声器)的信号、以及与由音频系统200进行使用相关的其它数据、或它们的任意组合。数据存储库235可以被实现为非暂态计算机可读存储介质。根据本公开的各实施例,数据存储库235可以用作缓冲区,以收集和存储各自从多个声源中的对应(虚拟)声源发出的多个声音信号。该多个声源例如可以是与音频系统200的用户进行电话会议的不同人。
用户可以选择加入以允许数据存储库235记录由音频系统200采集的数据。在一些实施例中,音频系统200可以采用始终记录(always on recording),其中音频系统200记录由音频系统200所采集的所有声音,以改善用户的体验。用户可以选择加入或选择退出,以允许或阻止音频系统200记录、存储或向其它实体发送所记录的数据。
DOA估计模块240被配置为部分地基于来自传感器阵列220的信息,来定位局部区域中的声源。定位是确定声源相对于音频系统200的用户所处的位置的过程。DOA估计模块240执行DOA分析,以定位局部区域内的一个或多个声源。DOA分析可以包括:分析每个声音在传感器阵列220处的强度、频谱和/或到达时间,以确定声音的起源方向。在一些情况下,DOA分析可以包括用于分析音频系统200所处的周围声学环境的任何合适的算法。
例如,DOA分析可以被设计为接收来自传感器阵列220的输入信号,并且将数字信号处理算法应用于这些输入信号以估计波达方向。这些算法例如可以包括延迟求和算法,在该延迟求和算法中,对输入信号进行采样,并且对得到的采样信号的加权版本和延迟版本一起进行平均以确定DOA。也可以实现最小均方(least mean squared,LMS)算法来创建自适应滤波器。然后,该自适应滤波器可以用于识别例如信号强度的差或到达时间的差。然后,这些差可以用于估计DOA。在另一实施例中,可以通过将输入信号转换到频域并且选择时频(time-frequency,TF)域内的特定频率间隔(bin)以进行处理来确定DOA。可以对每个所选择的TF频率间隔进行处理,以确定该频率间隔是否包括音频频谱中具有直接路径音频信号的部分。然后,可以对具有直接路径信号的部分的那些频率间隔进行分析,以识别传感器阵列220接收到该直接路径音频信号时所处的角度。然后,所确定的角度可以用于识别接收到的输入信号的DOA。以上未列出的其它算法也可以单独使用或与以上算法组合使用来确定DOA。
在一些实施例中,DOA估计模块240也可以确定与音频系统200在局部区域内的绝对位置相关的DOA。可以从外部系统(例如,头戴式设备的某些其它部件、人工现实控制台、地图构建服务器、位置传感器(例如,位置传感器190)等)接收传感器阵列220的位置。外部系统可以创建局部区域的虚拟模型,在该虚拟模型中绘制了音频系统200的局部区域和位置。接收到的位置信息可以包括音频系统200的一些部分或全部部分(例如,传感器阵列220)的地点和/或方位。DOA估计模块240可以基于接收到的位置信息来更新所估计的DOA。
传递函数模块250被配置为生成一个或多个声学传递函数。一般而言,传递函数是针对每个可能的输入值给出对应的输出值的数学函数。传递函数模块250基于检测到的声音的参数,生成与音频系统相关联的一个或多个声学传递函数。声学传递函数可以是ATF、HRTF、其它类型的声学传递函数、或它们的某种组合。ATF表征传声器如何接收来自空间中的点的声音。
ATF包括多个传递函数,这些传递函数表征声源与传感器阵列220中的多个声学传感器所接收的对应的声音之间的关系。因此,针对一声源,对于传感器阵列220中的每个声学传感器均存在对应的传递函数。并且该组传递函数被统称为ATF。因此,对于每个声源,均存在对应的ATF。注意,该声源例如可以是在局部区域中生成声音的某人或某物、用户、或转换器阵列210中的一个或多个转换器。由于人的生理结构(例如,耳朵形状、肩膀等)在声音向人耳行进时会影响该声音,因此相对于传感器阵列220的特定声源地点的ATF可能因用户的不同而有所区别。因此,传感器阵列220的各ATF对于音频系统200的每个用户是个性化的。
在一些实施例中,传递函数模块250确定音频系统200的用户的一个或多个HRTF。HRTF表征耳朵如何接收来自空间中的点的声音。由于人的生理结构(例如,耳朵形状、肩膀等)在声音向人耳行进时会影响该声音,因此相对于人的特定声源地点的HRTF对于这个人的每只耳朵而言是独特的(从而对于这个人而言是独特的)。在一些实施例中,传递函数模块250可以使用校准过程来确定用户的HRTF。在一些实施例中,传递函数模块250可以向远程系统提供关于用户的信息。用户可以调整隐私设置,以允许或防止传递函数模块250向任何远程系统提供关于用户的信息。远程系统例如使用机器学习来确定为用户定制的一组HRTF,并且将定制的该组HRTF提供给音频系统200。
追踪模块260被配置为追踪一个或多个声源的地点。追踪模块260可以将多个当前DOA估计结果进行比较,并且将这些当前DOA估计结果与先前DOA估计结果的存储历史进行比较。在一些实施例中,音频系统200可以按照周期性时间表(例如,每秒一次或每毫秒一次)来重新计算DOA估计结果。追踪模块可以将当前DOA估计结果与先前DOA估计结果进行比较,并且追踪模块260可以响应于声源的DOA估计结果的变化来确定声源发生了移动。在一些实施例中,追踪模块260可以基于从头戴式设备或某种其它外部源接收到的视觉信息来检测地点的变化。追踪模块260可以追踪一个或多个声源随时间的移动。追踪模块260可以存储声源的数量值以及每个声源在每个时间点的地点。追踪模块260可以响应于声源的数量值或地点的变化来确定声源发生了移动。追踪模块260可以计算局域方差(localizationvariance)的估计结果。局域方差可以用作每次确定移动变化的置信水平。
波束成形模块270被配置为对一个或多个ATF进行处理,以选择性地强调来自某个区域内的声源的声音,同时不强调来自其它区域的声音。在对传感器阵列220检测到的声音进行分析时,波束成形模块270可以组合来自不同声学传感器的信息,以强调与局部区域的特定区相关联的声音,同时不强调来自该区之外的声音。波束成形模块270例如可以基于来自DOA估计模块240和追踪模块260的不同DOA估计结果,将与来自特定声源的声音相关联的音频信号与局部区域中的其它声源隔离开。因此,波束成形模块270可以对局部区域中的离散声源进行选择性地分析。在一些实施例中,波束成形模块270可以增强来自声源的信号。例如,波束成形模块270可以应用声音滤波器,该声音滤波器消除高于某些频率、低于某些频率或位于某些频率之间的信号。信号增强用于相对于由传感器阵列220检测到的其它声音来增强与给定的所识别的声源相关联的声音。
声音滤波器模块280确定转换器阵列210的声音滤波器。在一些实施例中,声音滤波器使音频内容被空间化,使得音频内容像是源自于目标区域的。声音滤波器模块280可以使用HRTF和/或声学参数来生成声音滤波器。声学参数描述局部区域的声学特性。声学参数例如可以包括混响时间、混响水平、房间脉冲响应等。在一些实施例中,声音滤波器模块280计算这些声学参数中的一个或多个声学参数。在一些实施例中,声音滤波器模块280从地图构建服务器(例如,如以下关于图5所描述的)请求声学参数。
在一些实施例中,相同的(即,静态的)声音滤波器(例如,HRTF)被应用于用户头部的不同位置,从而相对于用户的头部位置锁定声源的虚拟位置,即声源的虚拟位置是“头部锁定的”。可替代地,声音滤波器模块280可以基于用户的头部位置来更新声音滤波器,从而锁定声源在局部区域内的虚拟位置,即声源地点的虚拟位置是“世界锁定的”。由声音滤波器模块280确定的声音滤波器可以与音频系统200的两个音频通道相关联。在这种情况下,虚拟声源出现在同一高度。然而,如果音频系统200包括一个或多个附加音频通道(例如,总共三个音频通道),则可以应用与附加音频通道相关联的一个或多个附加声音滤波器,并且虚拟声源可以出现在不同高度,即虚拟声源可以被放置在任何空间点(例如,空间中的三个点)内的声音场景中。类似地,与具有同一高度的多个声源的情况一样,具有不同高度的多个声源的虚拟位置可以是头部锁定的或世界锁定的。
声音滤波器模块280向转换器阵列210提供声音滤波器。在一些实施例中,声音滤波器可以作为频率的函数引起声音的正放大或负放大。结合图3A描述了关于应用声音滤波器的附加细节。
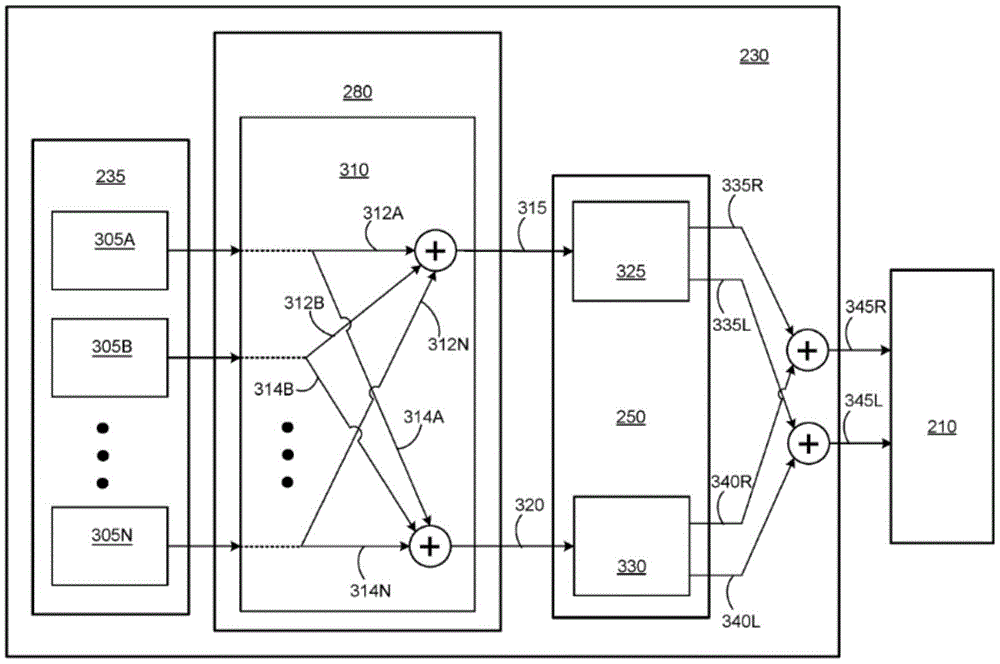
图3A是根据一个或多个实施例的在音频系统200处实现的多个离散声源的离散双声道空间化的框图。数据存储库235可以记录和收集多个声音信号305A、305B、……、305N(即,两个以上声音信号),该多个声音信号各自从多个声源中的对应声源发出。因此,数据存储库235可以充当存储器缓冲区。多个声源例如可以是与音频系统200的用户进行电话会议的不同人。可替代地,声音信号305A、305B、……、305N可以在音频控制器230的某些其它模块处被收集,或者在(例如,经由无线连接)与音频系统200和音频控制器230接合的计算设备(例如,智能手机、控制台、远程服务器等)处被收集。
音频控制器230可以给每个声源分配音频系统200周围的声音场景的角度范围内的各自虚拟位置。例如,声音场景的角度范围可以是120°,例如,跨度在-60°与+60°之间。分配给所有声源的各虚拟位置可以位于同一高度处的声音场景内。在一实施例中,各声源被放置在用户前面具有0°高度的水平面中。在另一实施例中,各声源被放置在地平线以下,例如具有-30°的角高度。在又一实施例中,各声源被放置在地平线以上,例如具有+30°的角高度。在又一实施例中,各声源在声音场景中沿对角线分布。
在一些实施例中,可以根据各虚拟位置在角度范围内的均匀分布来给各声源分配虚拟位置,即所分配的虚拟位置可以在声音场景的角度范围内彼此均等地分开,这在多个声源之间提供了最大化的语音清晰度。一般而言,当具有同一高度的多个声源在声音场景内均等分布时,每两个相邻虚拟位置之间的角度间隔等于AR/(NS-1),其中AR是角度范围(例如,120°)且NS是待在声音场景内均等分布的独立声源的数量。在声音场景内具有不同高度的多个声源的虚拟位置的相等空间分隔也可以提供最大化的语音清晰度。在一些其它实施例中,可以根据一个或多个其它分布来给声源分配虚拟位置。
在一实施例中,仅存在四个独立的声音信号305A至305D。在这种情况下,各自发出对应的独立声音信号305A至305D的四个独立声源可以均等地分布在声音场景内以供用户感知。声音信号305A至305D可以在数据存储库235处被记录和收集。可以将与角度范围的第一边界相匹配的第一虚拟位置分配给声音信号305A源自的第一声源,例如,第一虚拟位置可以在声音场景内具有+60°的角度方向。类似地,可以将与角度范围的第二边界相匹配的第四虚拟位置分配给声音信号305D源自的第四声源,例如,第四虚拟位置可以在声音场景中具有-60°的角度方向。可以将第二虚拟位置分配给声音信号305B源自的第二声源,该第二声源在声音场景中具有+20°的角度方向。最后,可以将第三虚拟位置分配给声音信号305C源自的第三声源,该第三声源在声音场景中具有-20°的角度方向。因此,在NS=4个独立声源的情况下,每两个相邻虚拟位置之间的角度间隔为120°/3=40°。
在另一实施例中,在声音场景内的非均匀间隔上(例如在-20°与+60°之间)分配多个声源中的至少一部分声源。另外,可以将至少一个声源(例如,最响的声源)放置在角度范围之外的声音场景内,其它声源被分配到该角度范围。例如,可以将最响的声源分配给具有-50°的角度方向的虚拟位置。如果多个声源不被放置在声音场景内以彼此重叠,则用户对具有显著响度差异的多个声源的感知可以改善。一般而言,较响声源的一个或多个较大空间分隔将允许较安静声源的更高清晰度。
音频控制器230的平移子模块310可以根据每个声源的各自虚拟位置执行对从数据存储库235检索到的每个声音信号305A、305B、……、305N的平移,来生成第一多源音频信号315和第二多源音频信号320。平转子模块310知晓关于分配给各声源的各自虚拟位置的信息,例如,可以从数据存储库235获取关于该各自虚拟位置的信息。第一多源音频信号315可以与声音场景的角度范围的第一方向相关联。角度范围的第一方向可以与角度范围的第一边界(例如,声音场景内具有+60°的角度方向的边界)相匹配。第二多源音频信号320可以与声音场景的角度范围的第二方向相关联。角度范围的第二方向可以与角度范围的第二边界(例如,声音场景内具有-60°的角度方向的边界)相匹配。
由平移子模块310执行的平移可以通过基于每个声源的各自虚拟位置,在与第一方向相关联的第一能量和与第二方向相关联的第二能量之间分割每个声音信号305A、305B、……、305N的能量来实现。可以对所有声音信号305A、305B、……、305N并行地执行平移。如图3A所示,平移子模块310可以将声音信号305A的能量分割为与第一方向相关联的声音信号312A的能量和与第二方向相关联的声音信号314A的能量。类似地,平移子模块310可以将声音信号305B的能量分割为与第一方向相关联的声音信号312B的能量和与第二方向相关联的声音信号314B的能量等,并且平移子模块310可以将声音信号305N的能量分割为与第一方向相关联的声音信号312N的能量和与第二方向相关联的声音信号314N的能量。
可以通过对与第一方向相关联的所有声音信号312A、312B、……、312N进行求和,来生成第一多源音频信号315。类似地,可以通过对与第二方向相关联的所有声音信号314A、314B、……、314N进行求和,来生成第二多源音频信号320。在一些实施例中,如果分配给产生声音信号305A的声源的虚拟位置与第一方向相匹配,则声音信号314A的能量将为零。类似地,如果分配给产生声音信号305N的声源的虚拟位置与第二方向相匹配,则声音信号312N的能量将为零。
平移子模块310可以被配置为根据以下规律来对声音信号305A、305B、……、305N执行平移:线性平移规律、能量平移规律、圆形平移规律、恒定功率平移规律、某些其它平移规律、或它们的组合。如图3A所示,平移子模块310可以是声音滤波器模块280的一部分。可替代地,平移子模块310可以是音频控制器230的某个其它模块的一部分,例如DOE估计模块240的一部分、传递函数模块的一部分或波束成形模块270的一部分。在另一实施例中,平移子模块310是音频控制器230的独立模块。在又一实施例中,平移子模块310集成在与音频系统200分开的计算设备中。
第一多源音频信号315可以被馈送到音频系统200的第一音频通道上,以通过传递函数325进行空间化。类似地,第二多源音频信号320可以被馈送到音频系统200的第二音频通道上,以通过传递函数330进行空间化。传递函数325可以执行第一多源音频信号315向第一方向的空间化,以生成第一右信号335R和第一左信号335L。传递函数325可以是用于与第一方向(例如具有+60°的角度方向)相关联的用户双耳的一对HRTF或某些其它空间滤波器对。传递函数330可以执行第二多源音频信号320向第二方向的空间化,以生成第二右信号340R和第二左信号340L。传递函数330可以是用于与第二方向(例如具有-60°的角度方向)相关联的用户双耳的一对HRTF或某些其它空间滤波器对。
在一些实施例中,相同的传递函数325、330用于用户头部的不同位置。在这种情况下,当用户手的方位改变时,各声源的虚拟位置的地点也将在声音场景内移动,使得各声源的虚拟位置相对于用户手的方位保持固定。在一些其它实施例中,基于用户的头部移动来更新传递函数325、330(即,可以从传递函数模块250检索到的不同传递函数325、330),使得每个声源对于用户而言像是源自于声音场景内固定的各自虚拟位置。如图3A所示,应用于第一多源音频信号315和第二多源音频信号320的传递函数325、330可以是传递函数模块250的一部分。可替代地,传递函数325、330可以是音频控制器230的某个其它模块的一部分,例如,声音滤波器模块280的一部分。
音频控制器230可以使用第一右信号335R、第一左信号335L、第二右信号340R和第二左信号340L来生成双声道信号345R、345L。双声道信号345R、345L可以使得每个声源像是源自于各自的虚拟位置。可以通过对第一右信号335R和第二右信号340R进行求和,来生成双声道信号中用于呈现给用户的右耳的右分量345R。类似地,可以通过对第一左信号335L和第二左信号340L进行求和,来生成双声道信号中用于呈现给用户的左耳的左分量345L。可以将双声道信号345R、345L提供给转换器阵列210以呈现给音频系统的用户。例如,可以将右分量345R提供给为右耳产生声学压力波的对应扬声器160和/或对应组织转换器170。类似地,可以将左分量345L提供给为左耳产生声学压力波的对应扬声器160和/或对应组织转换器170。
图3B示出了根据一个或多个实施例的由图3A中的离散双声道空间化产生的声音场景中的各声源的虚拟位置(即,所感知的源位置)。如图3A所示,音频系统的音频控制器230可以执行多个声源(例如,发出声音信号305A、305B、305C、……、305N的各声源)的离散双声道空间化,以生成双声道信号的右分量345R、左分量345L。然后,可以将双声道信号的右分量345R和左分量345L提供给音频系统200的转换器阵列210,以呈现给用户。用户将声音信号305A、305B、305C、……、305N分别感知为源自于角度范围355内的虚拟位置350A、350B、350C、……,350N。如上所述,虚拟位置350A、350B、350C、……、350N可以均匀地分布在角度范围355内。然而,虚拟位置350A、350B、350C、……、350N的某些其它分布也是可能的。
图4是根据一个或多个实施例的多个声源的离散双声道空间化的方法400的流程图。图4中所示出的过程可以由音频系统(例如,音频系统200)的部件来执行。在其它实施例中,其它实体可以执行图4中的一些或全部步骤。各实施例可以包括不同的步骤和/或附加的步骤,或者以不同的顺序执行各步骤。
音频系统(例如,在数据存储库235处)收集多个声音信号(405),该多个声音信号各自从多个声源中的对应声源发出。该多个声源例如可以是与音频系统的用户进行电话会议的不同人。音频系统例如可以通过缓存电话会议的一个或多个时间段的每个预定时间段期间从各声源传入的声音信号来收集该多个声音信号(405)。
音频系统(例如,通过音频控制器230)给每个声源分配声音场景的角度范围内的各自虚拟位置(410)。对于120°的总角度范围,角度范围例如可以在-60°与+60°之间。角度范围可以在多个声源之间平均地划分为多个角度方向,并且分配给每个声源的各自虚拟位置可以与各自角度方向相对应。可替代地,多个声源可以是非均等分布的,即相邻声源之间的角度间隔可以不同。
音频系统通过根据各自虚拟位置对每个声音信号进行平移,来(例如,由音频控制器230)生成第一多源音频信号和第二多源音频信号(415)。音频系统可以基于各自的虚拟位置,在与第一方向相关联的第一能量和与第二方向相关联的第二能量之间分割每个声音信号的能量来生成第一多源音频信号和第二多源音频信号。第一方向可以与角度范围的第一边界相匹配,并且第二方向可以与角度范围的第二边界相匹配。音频系统可以对每个声音信号的第一对应部分(例如,与第一方向相关联的部分)进行求和,以生成第一多源音频信号。音频系统还可以对每个声音信号的第二对应部分(例如,与第二方向相关联的部分)进行求和,以生成第二多源音频信号。
音频系统(例如,通过音频控制器230)向第一方向空间化第一多源音频信号,以生成第一左信号和第一右信号(420)。音频系统可以通过将与第一方向相关联的第一对HRTF(例如,用于用户的双耳)应用于第一多源音频信号,来空间化第一多源音频信号。音频系统可以将第一空间滤波器(例如,用于用户的双耳)应用于第一多源音频信号,以向第一方向空间化第一多源音频信号。音频系统可以基于用户的头部移动来更新第一空间滤波器(例如,第一对HRTF),使得每个声源像是源自于声音场景内固定的各自虚拟位置。
音频系统(例如,通过音频控制器230)向第二方向空间化第二多源音频信号,以生成第二左信号和第二右信号(425)。音频系统可以通过将与第二方向相关联的第二对HRTF(例如,用于用户的双耳)应用于第二多源音频信号,来空间化第二多源音频信号。音频系统可以将第二空间滤波器(例如,用于用户的双耳)应用于第二多源音频信号,以向第二方向空间化第二多源音频信号。音频系统可以基于用户的头部移动来更新第二空间滤波器(例如,第二对HRTF),使得每个声源像是源自于声音场景内固定的各自虚拟位置。
音频系统使用第一左信号、第二左信号、第一右信号和第二右信号来(例如,通过音频控制器230)生成双声道信号(430),其中,双声道信号使得每个声源像是源自于各自的虚拟位置。音频系统可以通过对第一左信号和第二左信号进行求和,来生成双声道信号中用于呈现给用户的左耳的左分量。音频系统可以通过对第一右信号和第二右信号进行求和,来生成双声道信号中用于呈现给用户的右耳的右分量。音频系统例如可以经由转换器阵列210将用户双声道信号呈现给用户。
系统环境
图5是根据一个或多个实施例的包括头戴式设备505的系统500。在一些实施例中,头戴式设备505可以是图1A中的头戴式设备100或图1B中的头戴式设备105。系统500可以在人工现实环境(例如,虚拟现实环境、增强现实环境、混合现实环境或它们的某种组合)中运行。图5所示出的系统500包括头戴式设备505、耦接到控制台515的输入/输出(input/output,I/O)接口510、网络520以及地图构建服务器525。尽管图5示出了包括一个头戴式设备505和一个I/O接口510的示例系统500,但是在其它实施例中,系统500可以包括任意数量的这些部件。例如,可以存在多个头戴式设备,该多个头戴式设备各自具有相关联的I/O接口510,其中每个头戴式设备和I/O接口510与控制台515通信。在替代配置中,系统500可以包括不同的和/或附加的部件。另外,在一些实施例中,结合图5中所示出的一个或多个部件而描述的功能可以以与结合图5而描述的方式不同的方式分布在各部件之间。例如,控制台515的一些或全部功能可以由头戴式设备505来提供。
头戴式设备505包括显示组件530、光学器件块535、一个或多个位置传感器540以及DCA 545。头戴式设备505的一些实施例具有与结合图5而描述的部件不同的部件。另外,在其它实施例中,由结合图5而描述的各种部件所提供的功能可以不同地分布在头戴式设备505的各部件之间,或者在远离头戴式设备505的单独组件中体现。
显示组件530根据从控制台515接收到的数据向用户显示内容。显示组件530使用一个或多个显示元件(例如,显示元件120)来显示内容。显示元件例如可以是电子显示器。在各个实施例中,显示组件530包括单个显示元件或多个显示元件(例如,用户的每只眼睛一个显示器)。电子显示器的示例包括:液晶显示器(liquid crystal display,LCD)、有机发光二极管(organic light emitting diode,OLED)显示器、有源矩阵有机发光二极管显示器(active-matrix organic light-emitting diode display,AMOLED)、波导显示器、某种其它显示器、或它们的某种组合。注意,在一些实施例中,显示元件120还可以包括光学器件块535的一些或全部功能。
光学器件块535可以放大从电子显示器接收到的图像光、校正与该图像光相关联的光学误差、并向头戴式设备505的一个或两个适眼区呈现经校正的图像光。在各个实施例中,光学器件块535包括一个或多个光学元件。包括在光学器件块535中的示例光学元件包括:光圈、菲涅耳透镜、凸透镜、凹透镜、滤光器、反射表面或影响图像光的任何其它合适的光学元件。此外,光学器件块535可以包括不同光学元件的组合。在一些实施例中,光学器件块535中的一个或多个光学元件可以具有一个或多个涂层,例如部分反射涂层或抗反射涂层。
通过光学器件块535对图像光的放大和聚焦允许电子显示器与更大的显示器相比,在物理上更小、重量更轻并且功耗更低。另外,放大可以增大电子显示器所呈现的内容的视场。例如,所显示的内容的视场使得所显示的内容是使用几乎全部的用户视场(例如,约110度对角线)来呈现的,并且在一些情况下,所显示的内容是使用全部的用户视场来呈现的。另外,在一些实施例中,可以通过添加或移除光学元件来调整放大量。
在一些实施例中,光学器件块535可以被设计为校正一种或多种类型的光学误差。光学误差的示例包括桶形畸变或枕形畸变、纵向色差或横向色差。其它类型的光学误差还可以包括:球面像差,色差,或由于透镜场曲、像散所引起的误差,或任何其它类型的光学误差。在一些实施例中,提供给电子显示器用于显示的内容是预失真的,并且光学器件块535在其接收到来自电子显示器的图像光(该图像光是基于该内容而生成的)时,校正该失真。
位置传感器540是生成指示头戴式设备505的位置的数据的电子设备。位置传感器540响应于头戴式设备505的运动而生成一个或多个测量信号。位置传感器190是位置传感器540的实施例。位置传感器540的示例包括:一个或多个IMU、一个或多个加速度计、一个或多个陀螺仪、一个或多个磁力计、检测运动的另一合适类型的传感器、或它们的某种组合。位置传感器540可以包括用于测量平移运动(向前/向后、向上/向下、向左/向右)的多个加速度计和用于测量转动运动(例如,俯仰、横摆、翻滚)的多个陀螺仪。在一些实施例中,IMU快速地对测量信号进行采样,并且根据所采样的数据计算头戴式设备505的估计位置。例如,IMU随时间对从加速度计接收到的测量信号进行积分来估计速度矢量,并且随时间对速度矢量进行积分来确定头戴式设备505上的参考点的估计位置。参考点是可以用于描述头戴式设备505的位置的点。尽管参考点通常可以被定义为空间中的点,然而,该参考点实际上被定义为头戴式设备505内的点。
DCA 545生成局部区域的一部分的深度信息。DCA包括一个或多个成像设备以及DCA控制器。DCA 545还可以包括照明器。以上关于图1A对DCA 545的运行和结构进行了描述。
音频系统550向头戴式设备505的用户提供音频内容。音频系统550大体上与上述音频系统200相同。音频系统550可以包括一个或多个声学传感器、一个或多个转换器和音频控制器。音频系统550可以向用户提供空间化音频内容。根据本公开的各实施例,音频系统550在其两个音频通道上执行两个以上声源的离散双声道空间化,以向用户呈现音频内容。音频系统550可以通过根据声源在声音场景中的预分配的虚拟位置来对来自该声源的声音信号进行平移以生成一对多源音频信号。这一对多源音频信号可以被传输到音频系统550的两个音频通道,并通过应用适当的声音滤波器被转换为用于呈现给用户的双声道信号。双声道信号可以使得每个声源像是源自于其声音场景内的各自虚拟位置。在一些实施例中,音频系统550可以通过网络520请求来自地图构建服务器525的声学参数。声学参数描述了局部区域的一个或多个声学特性(例如,房间脉冲响应、混响时间、混响水平等)。音频系统550可以提供例如来自DCA 545的、描述局部区域的至少一部分的信息和/或来自位置传感器540的、头戴式设备505的位置信息。音频系统550可以使用从地图构建服务器525接收到的一个或多个声学参数来生成一个或多个声音滤波器,并且使用所述声音滤波器来向用户提供音频内容。
I/O接口510是允许用户向控制台515发送动作请求并从控制台515接收响应的设备。动作请求是执行特定动作的请求。例如,动作请求可以是开始或结束采集图像数据或视频数据的指令,或者是在应用程序内执行特定动作的指令。I/O接口510可以包括一个或多个输入设备。示例输入设备包括:键盘、鼠标、游戏控制器或用于接收动作请求并向控制台515传输动作请求的任何其它合适的设备。由I/O接口510接收到的动作请求被传输到控制台515,该控制台执行与该动作请求相对应的动作。在一些实施例中,I/O接口510包括采集校准数据的IMU,该校准数据指示I/O接口510相对于I/O接口510的初始位置的估计位置。在一些实施例中,I/O接口510可以根据从控制台515接收到的指令来向用户提供触觉反馈。例如,当接收到动作请求时提供触觉反馈,或者控制台515在该控制台515执行动作时向I/O接口510传输指令,从而使得I/O接口510生成触觉反馈。
控制台515根据从以下中的一者或多者接收到的信息来向头戴式设备505提供内容以供处理:DCA 545、头戴式设备505和I/O接口510。在图5所示的示例中,控制台515包括应用程序存储库555、追踪模块560和引擎565。控制台515的一些实施例具有与结合图5而描述的模块或部件不同的模块或部件。类似地,以下进一步描述的功能可以以与结合图5而描述的方式不同的方式分布在控制台515的各部件之间。在一些实施例中,本文所论述的关于控制台515的功能可以在头戴式设备505或远程系统中实现。
应用程序存储库555存储一个或多个应用程序以供控制台515执行。应用程序是一组指令,所述指令在被处理器执行时生成用于呈现给用户的内容。由应用程序生成的内容可以响应于经由头戴式设备505或I/O接口510的移动而从用户接收到的输入。应用程序的示例包括:游戏应用程序、会议应用程序、视频播放应用程序或其它合适的应用程序。
追踪模块560使用来自DCA 545、一个或多个位置传感器540或它们的某种组合的信息,来追踪头戴式设备505或I/O接口510的移动。例如,追踪模块560基于来自头戴式设备505的信息,确定头戴式设备505的参考点在局部区域的绘图中的位置。追踪模块560还可以确定对象或虚拟对象的位置。另外,在一些实施例中,追踪模块560可以使用来自位置传感器540的指示头戴式设备505的位置的数据的一部分以及来自DCA 545的局部区域的表示,来预测头戴式设备505的未来位置。追踪模块560向引擎565提供头戴式设备505或I/O接口510的估计的或预测的未来位置。
引擎565执行应用程序,并且从追踪模块560接收头戴式设备505的位置信息、加速度信息、速度信息、预测的未来位置或它们的某种组合。引擎565基于接收到的信息,来确定待向头戴式设备505提供的用于呈现给用户的内容。例如,如果接收到的信息指示用户已经看向左边,则引擎565生成用于头戴式设备505的以下内容:该内容是用户在虚拟局部区域或局部区域(利用附加内容增强了该局部区域)中的移动的镜像。另外,引擎565响应于从I/O接口510接收到的动作请求,在控制台515上所执行的应用程序内执行动作,并向用户提供该动作已被执行的反馈。已提供的反馈可以是经由头戴式设备505的视觉反馈或听觉反馈,或者是经由I/O接口510的触觉反馈。
网络520将头戴式设备505和/或控制台515耦接到地图构建服务器525。网络520可以包括使用无线通信系统和/或有线通信系统这两者的局域网和/或广域网的任意组合。例如,网络520可以包括互联网以及移动电话网。在一个实施例中,网络520使用标准通信技术和/或标准通信协议。因此,网络520可以包括使用如下技术的链路:例如以太网、802.11、全球微波接入互操作(worldwide interoperability for microwave access,WiMAX)、2G/3G/4G移动通信协议、数字用户线路(digital subscriber line,DSL)、异步传输模式(asynchronous transfer mode,ATM)、无限带宽(InfiniBand)、高速外设组件互连高级交换(PCI Express Advanced Switching)等。类似地,在网络520上使用的联网协议可以包括多协议标签交换(multiprotocol label switching,MPLS)、传输控制协议/网际协议(transmission control protocol/Internet protocol,TCP/IP)、用户数据报协议(UserDatagram Protocol,UDP)、超文本传输协议(hypertext transport protocol,HTTP)、简单邮件传输协议(simple mail transfer protocol,SMTP)、文件传输协议(file transferprotocol,FTP)等。通过网络520交换的数据可以使用以下技术和/或格式来表示:该技术和/或格式包括二进制形式的图像数据(例如可移植网络图形(Portable NetworkGraphics,PNG))、超文本标记语言(hypertext markup language,HTML)、可扩展标记语言(extensible markup language,XML)等。另外,可以使用常规加密技术对全部或一些链路进行加密,这些常规加密技术例如为安全套接层(secure sockets layer,SSL)、传输层安全协议(transport layer security,TLS)、虚拟专用网络(virtual private network,VPN)、互联网安全协议(Internet Protocol security,IPsec)等。
地图构建服务器525可以包括存储有描述多个空间的虚拟模型的数据库,其中,该虚拟模型中的一个位置与头戴式设备505的局部区域的当前配置相对应。地图构建服务器525经由网络520从头戴式设备505接收描述局部区域的至少一部分的信息和/或局部区域的位置信息。用户可以调整隐私设置以允许或防止头戴式设备505将信息发送到地图构建服务器525。地图构建服务器525基于接收到的信息和/或位置信息,确定该虚拟模型中与头戴式设备505的局部区域相关联的位置。地图构建服务器525部分地基于所确定的在该虚拟模型中的位置以及与所确定的位置相关联的任何声学参数,确定(例如,检索)与局部区域相关联的一个或多个声学参数。地图构建服务器525可以向头戴式设备505发送局部区域的位置以及与局部区域相关联的任意声学参数值。
系统500中的一个或多个部件可以包含存储用户数据元素的一个或多个隐私设置的隐私模块。
用户数据元素对用户或头戴式设备505进行了描述。例如,用户数据元素可以描述用户的身体特征、由用户执行的动作、头戴式设备505的用户的位置、头戴式设备505的位置、用户的HRTF等。可以以任何合适的方式存储用户数据元素的隐私设置(或“访问设置”),例如,与用户数据元素相关联地存储、存储在授权服务器上的索引中、以另一合适的方式存储或它们的任意合适的组合。
用户数据元素的隐私设置指定可以如何访问、存储或以其它方式使用(例如,查看、共享、修改、复制、执行、显现或识别)用户数据元素(或与用户数据元素相关联的特定信息)。在一些实施例中,用户数据元素的隐私设置可以指定可能无法访问与用户数据元素相关联的某些信息的实体的“黑名单”。与用户数据元素相关联的隐私设置可以指定许可访问或拒绝访问的任何合适的粒度。例如,一些实体可以具有查明特定用户数据元素存在的许可,一些实体可以具有查看特定用户数据元素的内容的许可,并且一些实体可以具有修改特定用户数据元素的许可。隐私设置可以允许用户允许其它实体在有限的时间段内访问或存储用户数据元素。
隐私设置可以允许用户指定可访问用户数据元素的一个或多个地理位置。对用户数据元素的访问或拒绝访问可以取决于试图访问用户数据元素的实体的地理位置。例如,用户可以允许访问用户数据元素,并且指定仅在用户处于特定位置时用户数据元素对于实体而言是可访问的。如果用户离开该特定位置,则用户数据元素对于该实体而言可能不再是可访问的。作为另一示例,用户可以指定用户数据元素仅对于距用户阈值距离内的实体(例如与该用户相同的局部区域内的头戴式设备的另一用户)而言是可访问的。如果用户随后改变位置,则具有对该用户数据元素的访问权的实体可能失去访问权,而一组新实体在它们来到用户的阈值距离内时可以获得访问权。
系统500可以包括用于实施隐私设置的一个或多个授权/隐私服务器。来自实体的、针对特定用户数据元素的请求可以识别与该请求相关联的实体,并且如果授权服务器基于与该用户数据元素相关联的隐私设置确定该实体被授权访问该用户数据元素,则可以仅向该实体发送该用户数据元素。如果请求实体未被授权访问该用户数据元素,则授权服务器可以防止所请求的用户数据元素被检索或者可以防止所请求的用户数据元素被发送到该实体。尽管本公开描述了以特定方式实施隐私设置,但是本公开考虑了以任何合适的方式实施隐私设置。
附加配置信息
已经出于说明的目的呈现了实施例的以上描述;这并不旨在是详尽的或者将专利权限制为所公开的精确形式。相关领域的技术人员可以理解的是,考虑到以上公开内容,许多修改和变型是可能的。
本描述的一些部分在对信息进行操作的算法和符号表示方面描述了实施例。这些算法描述和表示通常被数据处理领域的技术人员用来向本领域的其它技术人员有效地传达其工作的实质内容。尽管在功能上、计算上或逻辑上对这些操作进行了描述,但这些操作被理解为由计算机程序或等效电路或微代码等实现。此外,事实证明,在不失一般性的情况下,有时为了方便将这些操作的布置结构称为模块。所描述的操作和它们的相关联的模块可以被实施在软件、固件、硬件或它们的任意组合中。
本文所描述的任何步骤、操作或过程可以使用一个或多个硬件或软件模块单独地或者与其它设备组合地执行或实现。在一个实施例中,使用包括计算机可读介质的计算机程序产品来实现软件模块,该计算机可读介质包含计算机程序代码,该计算机程序代码可以被计算机处理器执行,以执行所描述的步骤、操作或过程中的任何或全部步骤、操作或过程。
各实施例还可以涉及一种用于执行本文中的操作的装置。该装置可以为所需目的而专门构造,和/或该装置可以包括通用计算设备,该通用计算设备由存储在计算机中的计算机程序选择性地激活或重新配置。此类计算机程序可以存储在可耦接到计算机系统总线的非暂态有形计算机可读存储介质中、或适合于存储电子指令的任何类型的介质中。此外,在本说明书中提及的任何计算系统可以包括单个处理器,或者可以是采用用于增加的计算能力的多处理器设计的架构。
各实施例还可以涉及一种由本文所描述的计算过程产生的产品。此类产品可以包括从计算过程得到的信息,其中该信息被存储在非暂态有形计算机可读存储介质上并且可以包括本文所描述的计算机程序产品或其它数据组合的任何实施例。
最后,本说明书中所使用的语言主要是出于可读性和指导目的而选择的,并且该语言可能不是为了划定或限制专利权而选择的。因此,旨在专利权的范围不受本具体实施方式的限制,而是受基于本文的申请上公布的任何权利要求的限制。因此,各实施例的公开内容旨在对专利权的范围进行说明而非限制,该专利权的范围在以下权利要求中得到阐述。
- 基于麦克风信号来提供空间提示集合的设备、方法以及用于提供双声道音频信号和空间提示集合的设备
- 基于麦克风信号来提供空间提示集合的设备、方法和计算机程序以及用于提供双声道音频信号和空间提示集合的设备