局部通信下基于动态组网的区域覆盖路径规划方法
文献发布时间:2024-04-18 20:01:23
技术领域
本发明涉及群体机器人协同执行区域覆盖路径规划领域,具体是一种在局部通信且仅有局部通信的情况下,群体机器人通过动态组网方式实现协同区域覆盖路径规划的方法。
背景技术
在现实应用中,自主导航机器人可以完成多种不同类型的任务,例如环境探测、灾害搜救、物品搬运、仓库管理等。而这些任务都需要机器人能够自主地规划移动路径,根据任务需求到达目标位置并执行相应的操作。对于自主导航机器人移动路径的规划,则需要路径规划算法的支撑。从任务分类角度来说,对目标区域的全覆盖路径规划算法,其目标是在出发点和目标点之间规划出最短移动路径。在完成路径规划的基础下,重点研究对于路径成本的最优化。
覆盖路径规划算法是一种智能优化算法,属于旅行商问题的一种衍生领域,它通过自主实体机器人系统,利用其装备的特定的传感器或通信设备进行移动方向的自主导航,从而解决未知或已知环境的区域覆盖问题。自提出以来它已经受到了学界的深入研究和工业界的广泛应用。
在单体机器人的覆盖路径规划问题方面,现阶段的技术,结合了诸如旅行商算法(TSP)、蚁群算法(ACO)、遗传算法(GA)、K-Means算法等多种策略用于优化覆盖路径规划问题。但若待搜索区域范围很大时,却无法规避覆盖效率低、电量损耗过多等现实问题。因此,群体机器人的协同覆盖路径规划方法得到了学界和工业界的重视,例如,2022年,Xie等提出一种改进的遗传算法以解决多区域下具有能量约束的多架无人机CPP问题。同年,Ma等提出了一种协同覆盖改进的BA
虽然目前群体机器人的覆盖路径规划问题得到了深入研究,然而,大多数目前已有的覆盖路径规划算法不具备使群体机器人在局部通信情况下仍能以最小的路径成本实现区域的完全覆盖的能力。
发明内容
为了解决上述问题,本发明提供了一种在局部通信且仅有局部通信的情况下,群体机器人通过动态组网方式实现协同区域覆盖路径规划的方法。
本发明技术原理:
基于捕食者-猎物理论,在每次迭代周期中,群体中所有机器人会同步完成向各自的下一个目标邻居点移动。同时,目标邻居点的选择由总奖励函数和通信约束规则计算得出,总奖励函数由三个子奖励函数构成,其中第一个奖励与机器人尽量远离捕食者(设置的虚拟点)的移动相关,以控制机器人的移动趋势,避免低效的折返覆盖;第二个奖励与机器人直线方向的持续运动有关,使其能够尽量保持直线运动;第三个奖励与机器人尽量覆盖边界有关,以进一步避免折返覆盖及陷入“死锁”情形。总奖励函数作为一种启发式方法在每一步引导机器人的移动覆盖方向。在目标邻居点的选择中,另一个引导因素是群体机器人间的局部通信约束规则,由于机器人间通信范围限制,算法构建了动态组网模型,以使机器人在探索下一步路径目标时能够维持组网通信,从而保证机器人群体间各自信息的实时共享。
本发明技术方案:
局部通信下基于动态组网的区域覆盖路径规划方法,包括步骤:
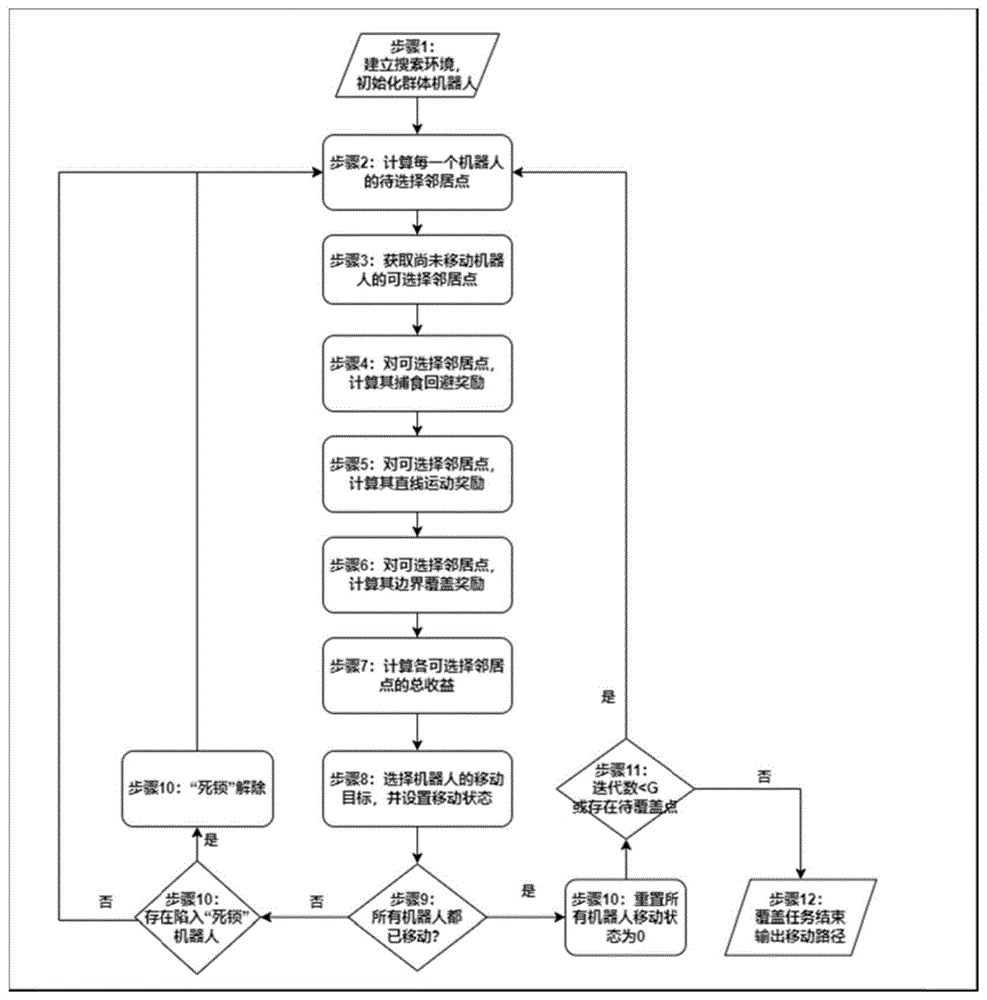
步骤1:建立搜索环境,初始化群体机器人;
步骤2:计算每一个机器人的待选择邻居点;
步骤3:基于已移动机器人群体通信范围,获取尚未移动机器人的可选择邻居点;
步骤4:对于步骤3得到的可选择邻居点,分别计算其捕食回避奖励;
步骤5:对于步骤3得到的可选择邻居点,分别计算其直线运动奖励;
步骤6:对于步骤3得到的可选择邻居点,分别计算其边界覆盖奖励;
步骤7:根据步骤4-6分别计算得出的奖励值分量,计算邻居点的总收益;
步骤8:对在本次迭代中尚未移动的机器人,根据步骤7分别计算得出的各邻居点的总收益,选择最大收益值对应的邻居点为迭代周期中对应机器人的移动目标,并设置机器人移动状态;
步骤9:在本次迭代周期中,重复步骤3-8,直至所有机器人均已移动或存在陷入“死锁”的机器人;
步骤10:若所有机器人均已移动,则本次迭代结束,重置所有机器人状态;若存在“死锁”的机器人,则进行“死锁”解除,本次迭代结束;
步骤11:若当前迭代次数达到预设值或所有环境区域均已覆盖,则执行步骤12,否则执行步骤2;
步骤12:输出各机器人的移动覆盖路径。
与现有技术相比,本发明具有如下有益效果:
本发明方法可以在局部通信且仅有局部通信的情况下,群体机器人仍能通过动态组网方式实现协同区域覆盖路径规划。在通信受限的无障碍物环境下,该方法可以有效地实时响应环境待覆盖区域变化,以最小的成本实现区域完全覆盖。
附图说明
图1为本发明局部通信下基于动态组网的区域覆盖路径规划方法的流程示意图。
图2为实施例八连通图。
图3为实施例跟随逃离机制示意图。
具体实施方式
本发明提出了局部通信下基于动态组网的区域覆盖路径规划方法,该方法可以应用在磁性空间测量问题中。
在待测定的大范围磁性空间中,常用的配备传感器或通信设备的群体机器人会受到磁场干扰,其在执行测定任务的过程中的通信范围会大幅缩短,因此,群体机器人的协同区域覆盖路径规划要受限于仅在局部通信条件下的实时信息共享。现假设机器人相比于磁性空间具有很小的尺寸和一定的局部感知范围,同时机器人本身对磁性空间不具备任何先验知识,只能通过局部通信及传感器获得通信网络内其它机器人的相关信息,并保证测定任务的执行效率及以最小的路径成本实现区域的完全覆盖。
下面将结合具体实施例及其附图对本申请提供的技术方案作进一步说明。结合下面说明,本申请的优点和特征将更加清楚。
实施例
如图1所示,局部通信下基于动态组网的区域覆盖路径规划方法包括步骤:
步骤1:建立搜索环境,采用动态栅格法划分磁性测量空间,在磁性空间外设置虚拟参考位置ψ,初始化算法参数:机器人个数N,机器人的通信距离C,权重因子ω
初始化机器人的位置o
步骤2:如图2所示,设任意一机器人k当前所在位置为o
其中,x,y为机器人k的当前坐标位置。
步骤3:获取尚未移动机器人的可选择邻居点。设P(o
其中i∈{-1,0,1}:当i=-1时,j∈{-1,0,1};当i=0时,j∈{-1,1};当i=1时,j∈{-1,0,1},o
步骤4:对于得到的可选择邻居点,分别计算其捕食回避奖励。公式如下:
其中,r为可选择邻居点个数,
步骤5:对于步骤3得到的可选择邻居点,分别计算其直线运动奖励。公式如下:
其中,r为可选择邻居点个数,
步骤6:对于步骤3得到的可选择邻居点,分别计算其边界覆盖奖励。公式如下:
其中,r为可选择邻居点个数,
步骤7:根据步骤4-6分别计算得出的奖励值分量R
R(o
其中,ω
步骤8:对在本次迭代中尚未移动的机器人,根据步骤7分别计算得出的各邻居点的总收益,选择最大收益值对应的邻居点为迭代周期中对应机器人的移动目标,并设置机器人移动状态。
步骤9:在本次迭代周期中,重复步骤3-8,直至所有机器人均已移动或存在陷入“死锁”的机器人。
步骤10:若所有机器人均已移动,则本次迭代结束,重置所有机器人状态为0;若存在“死锁”的机器人,则进行“死锁”解除,本次迭代结束。对于“死锁”解除,考虑了如下具体情况:
1)情况一,所有机器人没有任何可选择邻居点,其所有邻居点均已被覆盖。
2)情况二,存在部分机器人没有任何可选择邻居点,其所有邻居点均已被覆盖。
3)情况三,部分机器人周围虽有未被覆盖邻居点,但由于通信约束的限制,其跟随的机器人的移动方向导致其只能按相同的方向移动到特定的邻居点,而该邻居点已被自身或其它机器人覆盖,从而导致该机器人没有可选择点,被动陷入“死锁”状态。
针对情况一,采用A
针对情况二/三,当部分机器人陷入死锁状态时,采用跟随逃离机制以实现尽快到达回溯点的同时维持通信网络的不中断。跟随逃离机制的具体实现为:如图3所示,设图中以点构成的区域为覆盖区域,A′,B′以及C′为执行路径规划任务的三个机器人(C′为陷入“死锁”的机器人),青色、红色、紫色这三种颜色的线条分别为机器人A、机器人B、机器人C在完成部分区域覆盖过程中的历史移动轨迹,并且机器人A、机器人B、机器人C当前所在位置的坐标分别为A′(x
步骤11:若当前迭代次数达到预设值G或所有环境区域均已覆盖,则执行步骤12,否则执行步骤2。
步骤12:输出各机器人的移动覆盖路径。
验证
为深入所提出方法的可行性及性能表现,采用实验对比方式,与两种同为基于捕食者理论的自适应区域覆盖路径规划方法进行了比较,分别为PP-CPP(Predator-Prey-Based Coverage Path Planning)及Dec-PPCPP(Decentralized Predator-Prey-BasedCoverage Path Planning)算法。考虑到实验中涉及多个参数设置,因此,在参数设置上包括了六个方面,分别为:权重因子、机器人数量、环境规模、环境区域变化、通信范围、机器人的初始位置。参数设定汇总如下表1:
表1参数设定汇总
表2给出了所提出的方法与PP-CPP和Dec-PPCPP算法的实验比较结果:
表2实验比较结果
上述描述仅是对本申请较佳实施例的描述,并非是对本申请范围的任何限定。任何熟悉该领域的普通技术人员根据上述揭示的技术内容做出的任何变更或修饰均应当视为等同的有效实施例,均属于本申请技术方案保护的范围。