一种基于测地距离与样本熵的认知情感识别方法
文献发布时间:2023-06-19 09:41:38
技术领域
本发明涉及情感计算与人脸识别领域,具体涉及一种基于测地距离与样本熵的认知情感识别方法。
背景技术
情感计算是通过挖掘大数据表达与识别人的情感的理论,也是实现高级人工智能的关键技术。心理学研究表明,认知和情感是人类心理活动的两个重要部分,是有机联系在一起的一个过程的两个方面。研究任务中人的认知情感对及时发现任务风险与采取必要措施具有重要的作用。然而,当前情感计算与识别的研究主要集中在对日常六种基本情感的分析,忽略了对任务过程中人的认知情感的研究。
研究表明由人的认知状态引发的情感表达是一个持续1到4秒的过程,而非静态的情感峰值。然而,当前的脸部情感特征提取方法大都从二维静态图像中提取人脸表情的峰值特征,诸如Gabor小波、LBP和PCA方法,无法有效表达认知情感过程的时序动态属性。由于认知情感时序动态表达的特点,其分析的数据对象应为与时间序列相关的视频数据。然而,区别于静态图像,基于视频的数据处理增加了时间维信息,大大增加了数据量,多时甚至达到了上百万维的数据,其数据处理的难度也随之增大,增加了认知情感特征提取难度,导致认知情感计算与识别精度较低。
综上所述,针对持续过程的认知情感计算与识别问题,基于视频数据的人脸情感特征提取相比于传统的基于静态图像的特征提取更能够反映情感表达的过程,但这增加了数据维度,从而导致特征提取难度的激增。因此,如何快速有效地处理时序视频的大量数据,提取视频数据中人脸情感的时空特征,实现准确有效的认知情感识别是控制任务风险,避免重大事故的关键技术,也是当前情感计算人工智能的研究重点与难点。
发明内容
针对上述技术问题,本发明提出一种基于测地距离与样本熵的认知情感识别方法,能够有效从视频数据中提取人脸认知情感的时空特征,实现准确高效的认知情感识别,控制、预防与减少由人为因素导致的事故,降低任务风险,提高系统可靠性与安全性。
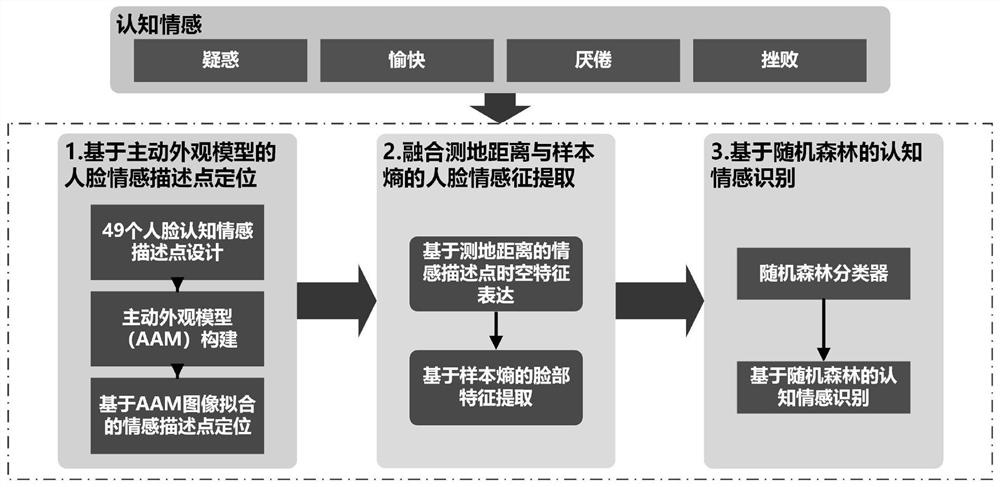
本发明采用的技术方案为:一种基于测地距离与样本熵的认知情感识别方法,该方法包括如下步骤:
步骤(1)、基于主动外观模型的人脸情感描述点定位;
步骤(2)、融合测地距离与样本熵的人脸情感特征提取;
步骤(3)、基于随机森林的认知情感识别。
其中,步骤(1)具体包括以下步骤:
1)认知情感描述点标定
本发明采用Mcdaniel、Rodrigo以及Baker等人研究的四种认知情感作为本发明的分析对象,分别为:疑惑、愉快、厌倦和挫败。
情感描述点标定的基本原则是用尽量少的脸部点来描述人脸表情的信息。传统研究一般采用标准的66到68个描述点对人脸表情进行标定,本发明通过分析认知情感特点,设计了49 个人脸的认知情感描述点;
2)训练图像对其与预处理
采用Procrustes分析对所有图像进行归一化处理,包括处理个图像的旋转角度参数、缩放参数以及二维位移参数。
3)主动外观模型的形状和纹理模型构建
利用主成分分析法处理所有图像的冗余信息,得到一组新的相互正交变量,从而每幅图像都可以通过这个变量的线性组合来表达,即主动外观模型的形状模型:
其中,
在将形状投影到平均形状中之后,训练图像即可得到一个“形状无关”的图像块。然后,再将该图像块中的像素光栅式地扫描到一个向量中,即可利用亮度对比度规范化得到纹理g。同样,纹理g也是通过PCA投影到纹理子空间,最终主动外观模型纹理模型可以表达为:
其中,
4)生成主动外观模型
主动外观模型模型是进一步将形状模型和纹理模型结合起来,通过加权值W形成一个新的向量,即:
然后,对b做主成分分析,得到变换矩阵Q。最终,主动外观模型构建完成并可以表达为:
其中,c是外观参数,矩阵Q
5)基于主动外观模型图像拟合的情感描述点定位
基于主动外观模型的图像拟合的目的是为测试图像寻找准确的模型参数。由此,主动外观模型图像拟合是一个参数寻优将待拟合图像与主动外观模型合成图像的差异最小化的过程。将两者之间的差异定义为:
δg=g
其中,g
i).计算纹理误差:δg=g
ii).估计纹理方差能量:E
iii).估算与误差对应的偏差值:δp
iv).更新参数:p
v).根据估算的误差值计算出相应的外观图像,并计算出应对的纹理误差:
vi).再次估计纹理方差能量:E
vii).判断是否E
在本发明中,利用主动外观模型完成图像拟合,并获得测试图像的49个情感描述点,每个图像的数据维度为2×49维。
其中,步骤(2)具体包括以下步骤:
1)基于测地距离的情感描述点时空特征表达
根据心理学实验与统计数据,认知情感的持续时间为1秒到4秒之间。认知情感的表达为一个持续过程,并以一段视频或动态图像为分析的单个样本对象。因此,假设每个样本包含n 张图像,从而一个数据样本的情感描述点集可以表达为:
Sample={S
由于每张图像包含49个情感描述点,每个描述点有2维坐标,因此该数据集的维数为 2×49×n。
由于人脸表情的表达即为一系列人脸情感描述点在空间上的变化,因此计算样本中各图像数据与第1幅图像数据情感描述点之间的测地距离,以此表达样本数据情感描述点的时空特征:
其中,d
当两个数据点a
因此,获得基于测地距离的数据特征时空表达Feature
2)基于样本熵的脸部认知情感特征提取
将第j(1≤j≤49)个数据样本的情感描述点时空特征的表达d
构建一个维数为m的向量序列:X
定义向量X
d{X
对于给定的X
增加维数到m+1,同样统计X
B
通过分析,在本发明中,参数m=2并且r为原始信号标准差的0.2倍。
由此,将时序数据Feature
Feature=SampEn(Feature
=SampEn{|d
={SampEn(1),SampEn(2),...,SampEn(49)}
至此,融合测地距离与样本熵的人脸情感特征提取完毕。
其中,步骤(3)具体包括以下步骤:
使用随机森林分类器,对输入的样本数据进行训练与分类,实现对四类认知情感的识别。具体流程为:
1)通过使用自助采样,从训练集中选择样本选择k个样本,并且每个所选样本的样本大小与训练集相同;
2)为每个样本构建决策树模型,并利用这k个模型获得k个分类结果;
3)基于k个分类结果,通过对每条记录进行表决来确定最终的分类结果。通过构建不同的训练集,RF能够增加分类模型之间的差异,以便增强集合分类模型的外推预测能力。在训练后,获得分类模型系列{h
其中,H(x)是组合分类器模型,h
本发明与现有技术相比的优点在于:
1)本发明通过分析认知与情感的内在规律,提出了面向任务环境中的人脸认知情感识别方法,设计了49个高效的脸部图像情感描述点,相对于传统的66到68个描述点,在保证描述情感变化的同时,降低了描述点的个数,从而有效提高了情感表达效率,为认知情感特征提取与情感识别奠定了基础。
2)依据心理学对认知情感发生过程的定义,将单个数据样本定义为一个持续时间在1到 4秒内的视频数据,并提出了融合测地距离与样本熵的特征提取方法,在提取数据有效信息的同时,降低了数据维度,使得浅层分类器能够实现快速、准确与稳定的识别。
3)本发明所提的技术方法能够应用在交通运输、生产作业等人机交互领域,实现工业工程中对工作人员认知情感优劣的监测,控制任务的风险,降低人为因素导致的事故概率。
附图说明
图1为本发明一种基于测地距离与样本熵的认知情感识别方法方案图;
图2为49个高效的人脸情感描述点;
图3为采集的四种认知情感视频的原始数据示例;
图4为基于主动外观模型的人脸情感描述点定位;
图5为融合测地距离与样本熵的人脸情感特征提取模型流程图;
图6为四种认知情感的欧氏距离与奇异值特征;
图7为四种认知情感的测地距离与样本熵特征。
具体实施方式
下面结合附图以及具体实施方式进一步说明本发明。
本发明针对工业工程中控制与减少人为失误的需求,以解决缺乏客观与准确的技术手段衡量人的认知情感的问题为目标,提出了一种基于测地距离与样本熵的认知情感识别方法。
本发明要解决的技术问题为:工业系统中人机交互密切,交通运输过程中人机环境复杂,使得人为因素造成的事故频频发生。通过情感状态的识别是判断任务回路中人的认知状态优劣的关键所在。然而,当前情感计算理论与方法缺乏与认知状态的关联,难以实现时序视频数据模式下的认知情感特征高效提取与认知情感状态准确识别。针对上述技术难题,本发明提出一种基于测地距离与样本熵的认知情感识别方法,能够有效从视频数据中提取人脸认知情感的时空特征,实现准确高效的认知情感识别,控制、预防与减少由人为因素导致的事故,降低任务风险,提高系统可靠性与安全性。
本发明采用的技术方案为:一种基于测地距离与样本熵的认知情感识别方法,该方法包括如下步骤:
步骤(1)、基于主动外观模型的人脸情感描述点定位;
步骤(2)、融合测地距离与样本熵的人脸情感特征提取;
步骤(3)、基于随机森林的认知情感识别。
其中,步骤(1)具体包括以下步骤:
2)认知情感描述点标定
本发明采用Mcdaniel、Rodrigo以及Baker等人研究的四种认知情感作为本发明的分析对象,分别为:疑惑、愉快、厌倦和挫败。
情感描述点标定的基本原则是用尽量少的脸部点来描述人脸表情的信息。传统研究一般采用标准的66到68个描述点对人脸表情进行标定,本发明通过分析认知情感特点,设计了49 个人脸的认知情感描述点;
2)训练图像对其与预处理
采用Procrustes分析对所有图像进行归一化处理,包括处理个图像的旋转角度参数、缩放参数以及二维位移参数。
3)主动外观模型的形状和纹理模型构建
利用主成分分析法处理所有图像的冗余信息,得到一组新的相互正交变量,从而每幅图像都可以通过这个变量的线性组合来表达,即主动外观模型的形状模型:
其中,
在将形状投影到平均形状中之后,训练图像即可得到一个“形状无关”的图像块。然后,再将该图像块中的像素光栅式地扫描到一个向量中,即可利用亮度对比度规范化得到纹理g。同样,纹理g也是通过PCA投影到纹理子空间,最终主动外观模型纹理模型可以表达为:
其中,
4)生成主动外观模型
主动外观模型模型是进一步将形状模型和纹理模型结合起来,通过加权值W形成一个新的向量,即:
然后,对b做主成分分析,得到变换矩阵Q。最终,主动外观模型构建完成并可以表达为:
其中,c是外观参数,矩阵Q
5)基于主动外观模型图像拟合的情感描述点定位
基于主动外观模型的图像拟合的目的是为测试图像寻找准确的模型参数。由此,主动外观模型图像拟合是一个参数寻优将待拟合图像与主动外观模型合成图像的差异最小化的过程。将两者之间的差异定义为:
δg=g
其中,g
viii).计算纹理误差:δg=g
ix).估计纹理方差能量:E
x).估算与误差对应的偏差值:δp
xi).更新参数:p
xii).根据估算的误差值计算出相应的外观图像,并计算出应对的纹理误差:
xiii).再次估计纹理方差能量:E
xiv).判断是否E
在本发明中,利用主动外观模型完成图像拟合,并获得测试图像的49个情感描述点,每个图像的数据维度为2×49维。
其中,步骤(2)具体包括以下步骤:
3)基于测地距离的情感描述点时空特征表达
根据心理学实验与统计数据,认知情感的持续时间为1秒到4秒之间。认知情感的表达为一个持续过程,并以一段视频或动态图像为分析的单个样本对象。因此,假设每个样本包含n 张图像,从而一个数据样本的情感描述点集可以表达为:
Sample={S
由于每张图像包含49个情感描述点,每个描述点有2维坐标,因此该数据集的维数为 2×49×n。
由于人脸表情的表达即为一系列人脸情感描述点在空间上的变化,因此计算样本中各图像数据与第1幅图像数据情感描述点之间的测地距离,以此表达样本数据情感描述点的时空特征:
其中,d
当两个数据点a
因此,获得基于测地距离的数据特征时空表达Feature
4)基于样本熵的脸部认知情感特征提取
将第j(1≤j≤49)个数据样本的情感描述点时空特征的表达d
构建一个维数为m的向量序列:X
定义向量X
d{X
对于给定的X
增加维数到m+1,同样统计X
B
通过分析,在本发明中,参数m=2并且r为原始信号标准差的0.2倍。
由此,将时序数据Feature
Feature=SampEn(Feature
=SampEn{|d
={SampEn(1),SampEn(2),...,SampEn(49)}
至此,融合测地距离与样本熵的人脸情感特征提取完毕。
其中,步骤(3)具体包括以下步骤:
使用随机森林分类器,对输入的样本数据进行训练与分类,实现对四类认知情感的识别。具体流程为:
1)通过使用自助采样,从训练集中选择样本选择k个样本,并且每个所选样本的样本大小与训练集相同;
2)为每个样本构建决策树模型,并利用这k个模型获得k个分类结果;
3)基于k个分类结果,通过对每条记录进行表决来确定最终的分类结果。通过构建不同的训练集,RF能够增加分类模型之间的差异,以便增强集合分类模型的外推预测能力。在训练后,获得分类模型系列{h
其中,H(x)是组合分类器模型,h
为了具体说明本发明的方法,本发明对Belfast Natural Induced EmotionDatabase和MMI Facial Expression Database数据库的人脸数据进行分析。以这两个数据库为实验的基础样本库,实验从数据库中选择被试者表现出愉快、疑惑、厌倦和挫败四种认知情感的脸部表情视频片段中,共选取包含了22个测试者的168段视频作为原始采集数据,其中女性6名和男性16名,每位测试者有4到14段视频片段。每个视频片段的参数为:帧率25帧/秒,分辨率为768×576。如图3所示,为本次实验所采用的原始视频片段示例。原始视频片段经过预处理后,在本次实验中共采用900个视频样本作为实验的训练和测试样本。
步骤(1)、基于主动外观模型的人脸情感描述点定位;
首先,对900个视频数据进行分解,每个视频样本能够分解成25-100帧图像,并对图像进行规范化处理;其次,本文定义了49个人脸情感描述点,通过构建主动外观模型形状和纹理模型,形成完整的主动外观模型的外观模型;最终,利用主动外观模型对900×n (n=25-100)幅样本数据图像进行情感描述点定位,实施人脸情感描述点定位过程如图4所示获得900个原始人脸情感描述点信息样本,每个样本数据长度为n×49×2。
步骤(2)、融合测地距离与样本熵的人脸情感特征提取;
利用本发明提出的融合测地距离与样本熵的特征提取方法对人脸情感描述点样本提取特征,方法实施过程如图5所示,最终得到900个认知情感特征向量样本,单个样本数据长度为 1×49。为验证本文所提特征提取方法的有效性和优越性,在实验中采用传统的欧氏距离与奇异值特征作为比较。
如图6和图7所示,两图所示四条曲线分别是对四种认知情感提取欧氏距离与奇异值特征和测地距离与样本熵特征的结果。
由图6可见,四种认知情感对应的四条曲线变化程度较小,高低起伏趋势差异不明显。相反,由图7所示,融合测地距离与样本熵的特征曲线变化较大,高低起伏趋势较大。这是由于融合测地距离与样本熵的认知情感特征能够表达认知情感数据在时间与空间的变化趋势,并反映到二维曲线当中。因此,通过对比欧氏距离与奇异值特征提取方法,实验结果验证了本文所提的测地距离与样本熵方法的优越性与鲁棒性。另一方面,从图7不难发现,四种认知情感特征的差异明显,验证了该方法的有效性。
步骤(3)、基于随机森林的认知情感识别。
采用本发明提出的基于随机森林的方法对认知情感进行识别,为比较验证所提方法的有效性与优越性,传统分类器SVM在本文中被使用以完成对比分析。对于随机森林和SVM,本发明设置的训练样本数量均为180个,则测试样本为720个。
本发明提出的基于随机森林的方法以及基于SVM的方法对认知情感识别的结果如表1所 示。本发明将900个样本数据随机分成5份,进行交叉验证。由图7可以发现,SVM方法对 于厌倦与疑惑认知情感有相对较好的识别准确度,而对于挫败和愉快两种情感的识别率较 低。尤其对于挫败情感(图中红色网格柱形图),SVM方法表现出的识别准确性波动较大。 结合表1的具体数值,识别结果显示SVM方法对于挫败的识别精度波动范围高达19.95%,易 受训练样本差异的影响。最终,SVM方法的总体平均识别率为78.91%,未达到80%。对于本 文所提随机森林分类器,比较表1中数据可以发现,RF分类器的识别效果优于SVM,且其最 终总体平均识别率为82.44%。与此同时,对于每一种认知情感,其识别准确率均在80%以上, 达到了良好的识别精度。
表1.基于监督学习的认知情感识别结果
由此,通过数据分析实施了本发明的应用过程,并且验证了本发明方法的有效性与优越性。
上述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和调整,这些改进和调整也应视为本发明的保护范围。
- 一种基于测地距离与样本熵的认知情感识别方法
- 一种基于认知评价理论的汉语文本情感识别方法