一种基于文本信息指导的开放域图像内容识别方法
文献发布时间:2023-06-19 09:46:20
技术领域
本发明涉及计算机视觉,图形处理技术领域,具体涉及一种开放域的图像内容识别方法。
背景技术
开放域图像内容识别是根据测试图像(目标域)中所包含的内容给出具体标签,其中训练图像(源域)标签集合是测试图像标签集合的子集。即需要对训练数据中不存在的标签类别进行判别,同时训练数据和测试数据来自于不同数据域,如源域是卡通图像,目标域是真实图像。因此开放域图像识别面临如下两个主要的难题。
首先,由于目标域中的未知类样本没有标注的训练数据或任何辅助属性信息,很难对其进行具体分类。只有了解已知类与未知类之间的关系,才能将已知类的分类规则传播给未知类。因此,处理未知类的关键思想是将从熟悉类中获得的知识用于描述新类。文献“X.Wang,Y.Ye,and A.Gupta.Zero-shot recognition via semantic embeddings andknowledge graphs.in Proc.IEEE Conference on Computer Vision and PatternRecognition,2018,pp.6857–6866”中利用单词嵌入和WordNet编码的类关系来估计未知类的分类器。J.Song等人在文献“J.Song,C.Shen,Y.Yang,Y.Liu,and M.Song.Transductiveunbiased embedding for zero-shot learning.in Proc.IEEE Conference on ComputerVision and Pattern Recognition,2018,pp.1024–1033”中提出了平衡约束损失以防止已知类被划分为未知类。虽然这些方法通过改变网络结构或增加附加约束来逐步提高未知类的识别精度,但大多忽略了在知识传播过程中不同的邻居对中心节点的贡献不同。
其次,由于开放域识别中目标域和源域之间的域差距,使得模型将有偏差的语义嵌入迁移到未知类别,从而降低了模型的泛化能力。即源域和目标域的样本在标签空间和数据分布上都存在较大的差异。在这种情况下,直接对齐整个分布,如文献“M.Long,Y.Cao,J.Wang,and M.I.Jordan.Learning transferable features with deep adaptationnetworks,arXiv preprint arXiv:1502.02791,2015”中提出的最大均值差异,文献“J.Zhuo,S.Wang,W.Zhang,and Q.Huang.Deep unsupervised convolutional domainadaptation.In Proceedings of the 2017ACM on Multimedia Conference,pages 261–269.ACM,2017”提出的深度域适应方法,会导致严重的负迁移。因为目标域中的未知类别对域适应的效果有很大影响。
发明内容
为了克服现有技术的不足,本发明提供一种基于文本信息指导的开放域图像内容识别方法。本发明公开了一种新的基于文本信息指导的开放域图像内容识别框架,主要解决了现有的算法对源域和目标域在数据分布以及标签空间上都存在较大差异的局限性。
本发明解决其技术问题所采用的技术方案的步骤为:
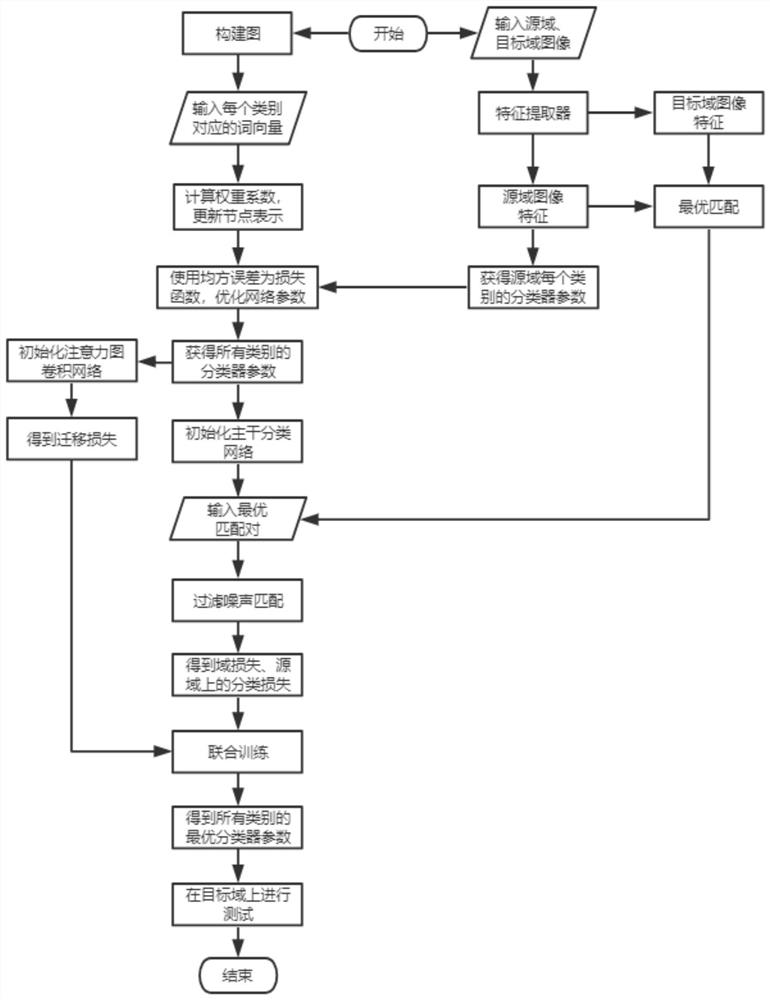
步骤1,在源域上训练已知类的分类器;
属于m个类的源域样本有丰富的标签信息,选择模型,以样本的真实标签作为监督信息,通过梯度下降法优化网络参数,将最后一层分类层的参数作为m个已知类的初始分类器;
步骤2,利用注意力图卷积将已知类的分类规则迁移到未知类;
首先通过WordNet编码的类关系构建包含n个节点的图,每个节点代表一个不同的类,n个节点包括目标域中的所有类别以及为了创建完整路径的目标域中所有类别的子类或者目标域中所有类别的父类,或者目标域中所有类别的子类的子类;每条边表示两个类别之间的关系,再利用预训练语言模型提取每个类别对应的词向量作为图卷积网络的输入,通过权重矩阵W将原始的输入转换为高维的特征表示之后,利用公式(1)计算任意两个节点之间的权重系数:
其中,
根据各邻居节点的特征表示以及中心节点的各邻居节点与中心节点的注意力系数,更新中心节点的特征表示:
其中,z
以步骤1中得到的m个类别的分类层参数作为真实标签,其中m 步骤3,最小化域差异; 将源域和目标域中的所有图像输入到主干分类网络中进行特征提取,对于目标域中的每个样本,计算目标域中的每个样本与源域中每个样本之间的特征距离,然后选择特征距离最小的源域样本作为匹配对,得到两个域之间的最优匹配对,将最优匹配对输入到主干分类网络中,利用语义一致性过滤掉噪声匹配:
其中, 通过公式(4)和公式(5),在主干分类网络的最后一层得到匹配对中两个样本的分类器响应,计算两个分类器响应的误差,如果误差大于给定阈值,那么这个匹配对就是噪声匹配,公式(5)的值为0,给公式(4)乘以0,就过滤掉匹配对;如果误差小于给定阈值,就视为正确的匹配对,此时公式(5)的值为1,给公式(4)乘以1,即为保留下该匹配对,如果是正确的匹配对,即两个样本是属于同一个类别,最后通过所有匹配对的特征距离衡量域差异; 步骤4,联合训练; 将过滤掉噪声匹配的匹配对输入到主干分类网络中,对有标签的源域样本计算分类损失,网络的初始输入是步骤2生成的参数,通过最小化分类损失、迁移损失以及域损失的损失和:
Z L 其中,L 同时对主干分类网络以及注意力图卷积网络通过梯度下降法进行优化,最终得到所有类别的最优分类器。 所述步骤1中,使用在ILSVRC-2012数据集上预训练的ResNet-50作为基本模型, 所述步骤2中,预训练语言模型选择Glove模型。 本发明的有益效果是: 1.识别结果正确率更高。本发明提出的基于注意力图卷积的知识迁移,考虑到不同邻居节点对中心节点的贡献不同,给它们赋予不同的权重,从而让中心节点学习到更具表现力的特征表示,进一步提高分类准确率。 2.系统更有实用价值。本发明的问题背景是源域和目标域在标签空间和数据分布上都存在着较大差异,这更加符合自然界的真实情况。相比于以往研究单一的标签空间差异或者数据分布差异,本系统具有更高的实用价值,而且本发明的研究思想可以应用于语言翻译、文本检测等其他任务。 3.对于开放度的变化更鲁棒。本发明提出的基于语义匹配最优的域适应方法,能够有效过滤掉噪声匹配,减少未知类对域适应的影响,进行避免域差异导致模型将有偏差的语义嵌入迁移到未知类别。因此,与其他方法相比,未知类所占的比例增大时,识别准确率的变化较小。 附图说明 图1为本发明实施的具体流程图。 具体实施方式 下面结合附图和实施例对本发明进一步说明。 具体地,本发明的目的在于改善以下几个方面: 1.传统的未知类识别算法对知识图谱中邻居节点信息利用不足。 2.现有的未知类识别算法不能适应于源域和目标域在数据分布上存在较大差异的不足。 3.现有的域适应方法不能适应于源域和目标域在标签空间上存在较大差异的不足。 4.现有开放域识别算法未考虑开放度因素。 本发明提出一种文本信息指导的开放域图像内容识别框架,以解决现有开放域识别系统的局限性。其技术方案包括三大模块:基于注意力图卷积的知识迁移,基于语义匹配最优的域适应和联合训练。 基于注意力图卷积的知识迁移: 1.首先构建包含n个节点的图,每个节点代表一个不同的类,每条边表示两个类别之间的关系。利用在Wikipedia上预训练的语言模型(如Glove)提取每个类别对应的词向量作为图卷积网络的输入。 2.通过权重矩阵W将原始的输入转换为高维的特征表示之后,利用下面的函数计算任意两个节点之间的权重系数:
3.获得权重系数之后,根据各邻居节点n
4.前m个类别(m
基于语义匹配最优的域适应: 1.对于目标域中的每个样本,我们计算它与源域中每个样本之间的特征距离。然后选择距离最小的源域样本作为匹配对。通过这种简单有效的方法,可以得到两个域之间的最优匹配对。 2.利用语义一致性过滤掉噪声匹配。如果 通过公式(4)衡量域差异。
联合训练: 1.利用注意力图卷积网络产生的所有类别的分类器参数来初始化主干分类网络。由于源域和目标域的差异影响了知识从未知类到已知类的迁移,因此我们考虑了注意力图卷积网络在联合训练中的迁移损失(L 2.联合训练时,通过最小化分类损失、迁移损失以及域损失来优化网络参数。 L 参照图1,本发明的具体实现步骤如下: 步骤1,在源域上训练已知类的分类器; 属于m个类的源域样本有丰富的标签信息,使用在ILSVRC-2012数据集上预训练的ResNet-50作为基本模型,以样本的真实标签作为监督信息,通过梯度下降法优化网络参数,将最后一层分类层的参数作为m个已知类的初始分类器; 步骤2,利用注意力图卷积将已知类的分类规则迁移到未知类; 首先通过WordNet编码的类关系构建包含n个节点的图,每个节点代表一个不同的类,n个节点包括目标域中的所有类别以及为了创建完整路径的目标域中所有类别的子类或者目标域中所有类别的父类,或者目标域中所有类别的子类的子类;每条边表示两个类别之间的关系,再利用预训练语言模型(如Glove)提取每个类别对应的词向量作为图卷积网络的输入,通过权重矩阵W将原始的输入转换为高维的特征表示之后,利用公式(1)计算任意两个节点之间的权重系数:
其中, 根据各邻居节点的特征表示以及中心节点的各邻居节点与中心节点的注意力系数,更新中心节点的特征表示:
其中,z 以步骤1中得到的m个类别的分类层参数作为真实标签,其中m 步骤3,最小化域差异; 将源域和目标域中的所有图像输入到主干分类网络中进行特征提取,对于目标域中的每个样本,计算目标域中的每个样本与源域中每个样本之间的特征距离,然后选择特征距离最小的源域样本作为匹配对,得到两个域之间的最优匹配对,将最优匹配对输入到主干分类网络中,利用语义一致性过滤掉噪声匹配:
其中, 通过公式(4)和公式(5),在主干分类网络的最后一层得到匹配对中两个样本的分类器响应,计算两个分类器响应的误差,如果误差大于给定阈值,那么这个匹配对就是噪声匹配,这种情况下,公式(5)的值为0,给公式(4)乘以0,就过滤掉了;如果误差小于给定阈值,就视为正确的匹配对,此时公式(5)的值为1,给公式(4)乘以1,即为保留下来,如果是正确的匹配对,即两个样本是属于同一个类别,一个匹配对中的两个样本的分类器响应之差会比较小,因为属于同一类的样本具有高度相似的分类响应,最后通过所有匹配对的特征距离衡量域差异; 步骤4,联合训练; 将过滤掉噪声匹配的匹配对输入到主干分类网络中,对有标签的源域样本计算分类损失,由于目标域和源域之间的域差距,使得模型会将有偏差的语义嵌入迁移到未知类别,因此还需要考虑注意力图卷积网络在联合训练中的迁移损失;此时,网络的初始输入是步骤2生成的参数,通过最小化分类损失、迁移损失以及域损失的损失和:
Z L 其中,L 同时对主干分类网络以及注意力图卷积网络通过梯度下降法进行优化,最终得到所有类别的最优分类器。 本发明的效果通过以下仿真实验做进一步的说明。 1.仿真条件 本发明是在中央处理器为 2.仿真内容 仿真中使用的数据为I2AwA和I2CIFAR。I2AwA的源域是在Google搜索引擎上获得的2970张模拟图像,包含40个类。目标域是AwA2,一共有37322张图像,属于50个类,显然,这50个类中,有40个已知类,10个未知类。I2CIFAR的源域是在Google搜索引擎上获得的1130张模拟图像,包含15个类,目标域是由CIFAR100中45个类组成的,这45个类中,有15个已知类,30个未知类。我们对整个目标域中的样本进行分类。评价指标为已知类别、未知类别和目标域中所有类别的识别准确率。 为了证明算法的有效性,选择zGCN,dGCN,adGCN,pmd-bGCN,UODTN作为对比算法。其中,zGCN是文献“X.Wang,Y.Ye,and A.Gupta.Zero-shot recognition via semanticembeddings and knowledge graphs.in Proc.IEEE Conference on Computer Visionand Pattern Recognition,2018,pp.6857–6866”中提出的处理零样本识别的方法;dGCN是文献“J.Song,C.Shen,Y.Yang,Y.Liu,and M.Song.Transductive unbiased embeddingfor zero-shot learning.in Proc.IEEE Conference on Computer Vision and PatternRecognition,2018,pp.1024–1033”中提出的方法;adGCN是文献“M.Kampffmeyer,Y.Chen,X.Liang,H.Wang,Y.Zhang,and E.P.Xing.Rethinking knowledge graph propagationfor zero-shot learning.in Proc.IEEE Conference on Computer Vision and PatternRecognition,2019,pp.11487–11496”中提出的方法;pmd-bGCN是文献“J.Chen,C.Li,Y.Ru,and J.Zhu.Population matching discrepancy and applications in deeplearning.in Proc.Advances in Neural Information Processing Systems,2017,pp.6262–6272”中提出的方法;UODTN是文献“J.Zhuo,S.Wang,S.Cui,andQ.Huang.Unsupervised open domain recognition by semantic discrepancyminimization.in Proc.IEEE Conference on Computer Vision and PatternRecognition,2019,pp.750–759”中提出的方法。AGCN-SMO是我们的方法所得到的结果。对比结果如表1、表2、表3所示: 表1 I2AwA上的准确率,开放度=0.2
表2 I2AwA上的准确率,开放度=0.4
表3 I2CIFAR上的准确率
从表1、表2、表3可见,本发明的识别准确率要优于其它算法。另外,从表1、表2可见,当未知类所占的比例增大时,本发明提出的方法的准确率下降值是最小的,说明本发明对于开放度的变化更鲁棒。
- 一种基于文本信息指导的开放域图像内容识别方法
- 一种基于学习跨数据域子空间的图像内容识别的分类方法及装置