一种布尔可满足性求解器中学习子句的删除方法及布尔可满足性求解器
文献发布时间:2023-06-19 10:58:46
技术领域
本发明涉及电子设计自动化(Electronic Design Automation,EDA)领域,尤其涉及一种布尔可满足性求解器中学习子句的删除方法及布尔可满足性求解器。
背景技术
布尔可满足性问题是计算机科学领域的核心问题之一,其广泛应用于电子设计自动化、集成电路形式验证、模型验证等领域,一些工业领域的现实问题常常转化为可满足性问题进行求解。在可满足性问题中,问题的输入是一个合取范式(CNF),合取范式由子句构成,子句和子句之间以布尔运算“与”的形式连接,而构成子句的是文字,文字和文字之间以布尔运算“或”的形式连接,文字为变量本身或变量的“非”。布尔可满足性问题求解即为找到一组包含所有变量的解使得整个问题满足,如果找不到这样的解,则输出该问题不可满足。例如:对于这样一个合取范式:
作为直接影响可满足性问题求解时间的决定因素,求解器算法一直是该问题研究的重点。求解器算法按照框架主要分为三种:完备算法、不完备算法和混合算法,其中完备算法以现在主流的CDCL算法为主。近年来出现了一批以CDCL为算法框架的高效求解器,Glucose求解器就是其中最重要的代表之一,该求解器应用的LBD学习子句删除策略,大幅度提升了算法的求解性能。其中,Glucose求解器的主要求解过程分为六步,分别为预处理,分支启发,布尔约束传播,冲突分析及学习子句生成,学习子句删除和重启。Glucose求解器的简要工作流程大致如下:先对读入的CNF文件进行预处理,旨在化简冗余子句,之后会根据分支启发策略选择一个文字赋值,并使其满足,由于该文字的赋值可以推导出其他文字的赋值,继而导致更多文字的赋值,由此产生的循环赋值过程即为布尔约束传播。在传播过程中遇到冲突的子句会进行冲突分析,并生成学习子句,以此保证下次不会产生相同的冲突,同时返回导致冲突产生的赋值层,重新开始赋值。由于在求解的过程中,直到求解结束,每一次冲突都会产生新的学习子句,学习子句会大量的累积并占用系统空间,因此,学习子句积累到一定数目会被删除,用以释放空间,提高搜索效率。
Glucose求解器中的LBD(Literals Blocks Distance,文字块距离)策略可简要概括为一种评价学习子句质量的标准,该策略通过计算每个学习子句的LBD值,然后将学习子句的LBD值排序,进而将LBD大的学习子句删除。LBD值反映了在学习子句中所有文字所在的赋值层数。一个学习子句的LBD值越小意味着这个子句被赋值的难度越小,因此变量之间的约束就更加紧密,当再次遇到冲突时,就可以高效的避免重复的冲突发生。但在经实际的多组测试例子运行之后发现,经过LBD排序筛选得到的学习子句并非都能在冲突分析时被多次用到,详细数据如表一所示:
表一
通过表一中的三个测试例子可以看出,被使用1次以下(包含1次)的学习子句保留率在40%以上,因此LBD策略保留的学习子句并不都是高效的学习子句。
发明内容
本发明的目的是针对现有技术的布尔可满足性求解器中的学习子句删除策略保留的学习子句并不都是高效的学习子句的技术问题,本发明提出一种布尔可满足性求解器中学习子句的删除方法及布尔可满足性求解器。
本发明实施例中,提供了一种布尔可满足性求解器中学习子句的删除方法,其包括:
在求解的过程中生成多个学习子句,并对每个学习子句的使用次数及LBD值进行记录;
当触发学习子句删除条件时,根据学习子句的使用次数和LBD值对学习子句进行删减。
本发明实施例中,所述学习子句删除条件为学习子句的数量或者求解的时间达到设定的阈值。
本发明实施例中,根据学习子句的使用次数和LBD值对学习子句进行删减,包括:
根据学习子句的使用次数对学习子句进行排序,并根据预先设定的使用次数范围及LBD值范围对学习子句进行初步删减;
对初步删减后的学习子句再根据LBD值进行排序,并删除排序靠后的学习子句。
本发明实施例中,对每个学习子句的使用次数进行记录,包括:
在学习子句产生时,给保存学习子句信息的结构体中增加一个用于记录学习子句使用次数的标志位,该标志位的初始值为0;
在求解的过程中每一次遇到冲突时,对发生冲突的子句进行判断,看其是否为学习子句,如果是,则更新所述标志位。
本发明实施例中,根据LBD值对初步删减后的学习子句进行排序时,如果两个学习子句的LBD值相等,活跃值较大的学习子句排序靠前。
本发明实施例中,对学习子句进行初步删减时,删除使用次数小于1且LBD值大于3的学习子句。
本发明实施例中,删除排序靠后的学习子句时,删除排序前一半中LBD大于2且为非原因子句的学习子句。
本发明实施例中,所述布尔可满足性求解器采用Glucose3.0求解器。
本发明实施例中,还提供了一种布尔可满足性求解器,其对学习子句进行删除时,采用上述的方法。
与现有技术相比较,采用本发明的布尔可满足性求解器中学习子句的删除方法及布尔可满足性求解器,先用基于冲突使用次数对学习子句进行粗略的删减,之后再根据LBD值进行排序,并删除排序靠后的学习子句,经过两次的删减之后能够有效的删除冗余的学习子句,有效提高了学习子句的质量,提升求解器的运行效率。
附图说明
图1是现有技术的求解器中学习子句使用次数与LBD值的关系统计图。
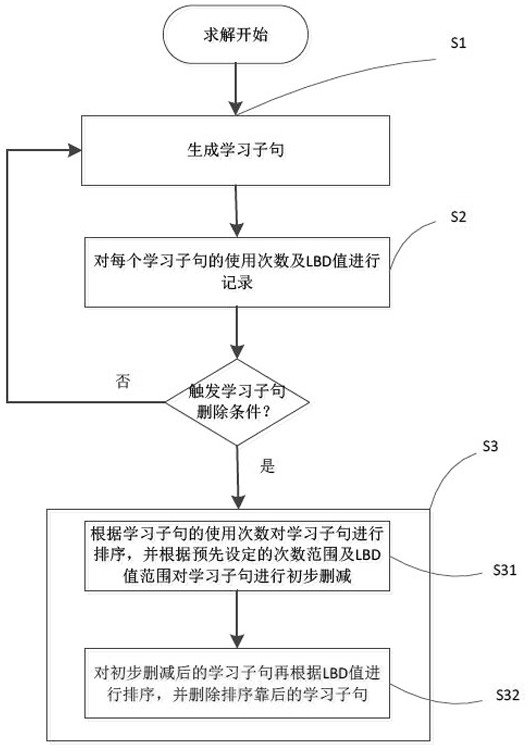
图2是本发明实施例的布尔可满足性求解器中学习子句的删除方法的流程图。
具体实施方式
在开始阐述本发明的技术方案之前,先介绍一下学习子句的使用次数的概念,学习子句的使用次数是指当一个学习子句被添加到合取范式的整个子句系统中之后,在接下来的布尔约束传播中,再次发生以该学习子句中的文字为冲突的传播时的次数。即,在布尔约束传播时发生的包含学习子句的冲突的次数。
接下来介绍一下本发明的技术方案中学习子句的使用次数和LBD值之间的关系。本专利申请发明人在经过在实际运行多组测试例子后,对学习子句的使用次数和学习子句的LBD值分别进行统计,得出一个大致的结论:当学习子句的使用次数较少时,其对应的LBD值往往也较大,随着学习子句的使用次数的增加,其LBD值则会逐渐变小,详细统计图如图1所示。考虑到使用LBD策略进行删除后的学习子句中有一部分在的使用次数很少,因此可以先根据学习子句的使用次数对其进行初步删减,再使用LBD策略删除,这样得到的学习子句集理论上为冲突使用次数最多和LBD值最小的交集,即为高效的学习子句。
因此,本发明针对以上学习子句的使用次数和LBD值的关系,提出一种基于使用次数和LBD策略相结合来删除学习子句的方法,如图2所示,所述方法包括步骤S1-S3,下面分别进行说明。
步骤S1:在求解的过程中生成学习子句。
需要说明的是,本发明实施例中,采用的求解器采用的是Glucose求解器,其求解过程包括预处理,分支启发,布尔约束传播,冲突分析及学习子句生成,学习子句删除和重启。具体地,先对读入的CNF文件进行预处理,旨在化简冗余子句,之后会根据分支启发策略选择一个文字赋值,并使其满足,由于该文字的赋值可以推导出其他文字的赋值,继而导致更多文字的赋值,由此产生的循环赋值过程即为布尔约束传播。在传播过程中遇到冲突的子句会进行冲突分析,并生成学习子句,以此保证下次不会产生相同的冲突,同时返回导致冲突产生的赋值层,重新开始赋值,直到求解完成。求解完成包括求解成功和求解失败。当找到符合一组包含所有变量的赋值使得CNF范式满足时,求解成功。当遍历各种赋值后CNF合取范式仍无法满足,则求解失败。
步骤S2:对每个学习子句的使用次数及LBD值进行记录。
本发明实施例中,在求解的过程中,对每个学习子句的使用次数进行记录,包括:
在学习子句产生时,给保存学习子句信息的结构体中增加一个用于记录学习子句使用次数的标志位,该标志位的初始值为0;
在求解的过程中每一次遇到冲突时,对发生冲突的子句进行判断,看其是否为学习子句,如果是,则更新所述标志位。
学习子句地LBD值为在学习子句中所有文字所在的赋值层数,在学习子句生成时即可得到。
步骤S3:当触发学习子句删除条件时,根据学习子句的使用次数和LBD值对学习子句进行删减。
需要说明的是,由于在求解的过程中,直到求解结束,每一次冲突都会产生新的学习子句,学习子句会大量的累积并占用系统空间,因此,学习子句积累到一定数目会被删除,用以释放空间,提高搜索效率。本发明实施例中,所述学习子句删除条件为学习子句的数量或者求解的时间达到设定的阈值。
具体地,步骤S3进一步包括:
步骤S31:根据学习子句的使用次数对学习子句进行排序,并根据预先设定的使用次数范围及LBD值范围对学习子句进行初步删减;
步骤S32:对初步删减后的学习子句再根据LBD值进行排序,并删除排序靠后的学习子句。
本发明实施例中,在步骤S21中,删除使用次数小于1且LBD值大于3的学习子句,即当触发学习子句删除的标志位时,先根据使用次数对学习子句进行排序,并删除使用1次以下且LBD值大于3的学习子句。当然,用户也可以根据实际地需要,对学习子句进行初步删减条件进行调整。
在步骤S22中,对初步删减后的学习子句再次进行LBD大小的排序。即按照Glucose求解器的常规LBD策略对学习子句再次排序,排序过后的学习子句以LBD值递减的方式存储。在排序地过程中,如果两个学习子句的LBD值相等,那么就比较两者的活跃值,活跃值较大的学习子句被认为是更高效的。该步骤的目的是使LBD值较大的学习子句排在总数的前一半,以确保删除前一半学习子句时能够删除LBD值较大的学习子句。然后,对排序后的学习子句进行删除,删除排序前一半中LBD大于2且为非原因子句的学习子句,保留下的学习子句即为高效的学习子句。
采用本发明的方法对学习子句进行删除后,使用次数较少和LBD值较大的学习子句(除了原因子句的学习子句)都被删除,与现有技术的Glucose求解器的常规LBD删除策略相比,删除和保留的详细数据如下表二所示:
表二
此外,对本发明的方法和原Glucose求解器的算法分别用基准例进行测试,运行时间如下表三所示:
表三
其中,实验主机的硬件配置为
从运行结果上来看,采用本发明的布尔可满足性求解器中学习子句的删除方法,对一些较难的可满足性问题性能提升都较为明显,对一些例子,运行时间能缩短80%。从总运行时间上来看,使用原算法运行11个例子的总时间为3919.22秒,相比之下改进后的算法运行总时间为2487.25秒,运行总时间缩短了36.5%。可以看出采用本发明的方法能够更有效地筛选出高质量的学习子句,提升了求解效率。
采用本发明的布尔可满足性求解器中学习子句的删除方法及布尔可满足性求解器,先用基于冲突使用次数对学习子句进行粗略的删减,之后再根据LBD值进行排序,并删除排序靠后的学习子句,经过两次的删减之后能够有效的删除冗余的学习子句,有效提高了学习子句的质量,提升算法的运行效率。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 一种布尔可满足性求解器中学习子句的删除方法及布尔可满足性求解器
- 一种布尔可满足性验证方法、系统、CNF生成方法及存储装置