基于机器学习的对象辨识系统及其方法
文献发布时间:2023-06-19 11:03:41
技术领域
本公开是有关于一种基于机器学习的对象辨识系统及其方法。
背景技术
传统利用深度学习网络对彩色二维影像进行对象识别过程中,在框选彩色二维影像的候选区域阶段,会利用卷积神经网络所获得大量对象特征,在彩色二维影像中生成候选区域,然而,这个步骤需要高速运算资源并消耗大量时间才能获得计算结果,这是传统深度学习网络的主要缺点。
中国专利公开第105975915A号提出一种基于多任务卷积神经网络的前方车辆参数识别方法,卷积神经网络(Convolutional Neural Network,CNN)的输入RGB-D图像,即一种包含彩色及深度信息的四信道颜色深度图像;将输入图像RGB-D图像进行局部对比度归一化的预处理,处理后的数据交给卷积神经网络进行训练,训练前初始化所有的权值为随机数;训练分为两个阶段:信号前向传播阶段和误差后向回馈阶段;当卷积神经网络的实际输出值与期望输出值的误差保持在预设范围内即终止卷积神经网络训练,并保存卷积神经网络结构,适用于交通场景的车辆参数识别的多任务卷积神经网络训练完毕。上述方法通过卷积神经网络进行学习分类能够识别其他车辆、行人等,RGB-D图像信息与普通的图像信息相比具有距离信息,在一定程度上提高了精确性。但是上述方法中RGB-D只能识别距离较近范围的物体,距离较远的物体识别精度低,如果应用在无人车上容易造成事故。
此外,中国专利公开第107576960A号提出一种视觉雷达时空信息融合的目标检测方法及系统,将RGB图像和LIDAR深度图片融合成RGB-LIDAR图片,将连续M次采集的RGB-LIDAR图片进行叠加,获得叠加后的RGB-LIDAR图片,以多个所述的叠加后的RGB-LIDAR图片建立RGB-LIDAR数据集,输入到深度学习网络进行训练学习,建立分类模型。根据分类模型对目标的分析结果采取相对应的决策。但是上述方法中融合成RGB-LIDAR图片需消耗大量时间及运算资源,且大量的RGB-LIDAR数据集输入到深度学习网络中才能获得计算结果,不符合实时辨识的需求。
公开内容
本公开有关于一种基于机器学习的对象辨识系统及其方法,可根据三维空间点云数据进行对象分割,并进行深度识别,以预先框选一关注区域,进而节省后续运算模块的运算时间。
根据本公开的一方面,提出一种基于机器学习的对象辨识系统,包括二维影像撷取模块、三维空间撷取模块、一数据框选模块、一数据对齐模块、一特征撷取模块以及一侦测模块。二维影像撷取模块用以撷取二维影像。三维空间撷取模块用以撷取三维空间点云数据。数据框选模块根据三维空间点云数据进行对象分割,并进行深度识别,以框选至少一关注区域。数据对齐模块映射关注区域的坐标至二维影像的坐标中。特征撷取模块计算二维影像的特征,并由二维影像的特征中提取对应关注区域的坐标的至少一关注特征。侦测模块用以取得至少一关注特征,并根据关注特征,对二维影像中的至少一对象进行识别。
根据本公开的一方面,提出一种基于机器学习的对象辨识方法,包括下列步骤。撷取二维影像。撷取三维空间点云数据。根据三维空间点云数据进行对象分割,并进行深度识别,以框选至少一关注区域。映射关注区域的坐标至二维影像的坐标中。计算二维影像的特征,并由二维影像的特征中提取对应关注区域的坐标的至少一关注特征。根据关注特征,对二维影像中的至少一对象进行识别。
附图说明
图1绘示依照本公开一实施例的基于机器学习的对象辨识系统的示意图。
图2绘示依照本公开一实施例的基于机器学习的对象辨识系统的具体架构的示意图。
图3绘示依照本公开一实施例的基于机器学习的对象辨识方法的示意图。
图4绘示图3中基于机器学习的对象辨识方法的进一步具体步骤的示意图。
附图标记说明
100:对象辨识系统
110:二维影像撷取模块
111:二维影像
120:三维空间撷取模块
121:三维空间点云数据
130:运算模块
132:数据框选模块
134:数据对齐模块
136:特征撷取模块
138:侦测模块
S11~S16、S111~S171:各个步骤
具体实施方式
以下系提出实施例进行详细说明,实施例仅用以作为范例说明,并非用以限缩本公开欲保护之范围。以下是以相同/类似的符号表示相同/类似的组件做说明。以下实施例中所提到的方向用语,例如:上、下、左、右、前或后等,仅是参考所附图式的方向。因此,使用的方向用语是用来说明并非用来限制本公开。
依照本公开的一个实施例,提出一种基于机器学习的对象辨识系统及其方法,例如采用卷积神经网络进行深度学习,并在深度学习网络中进行训练,以建立分类模型。卷积神经网络由一个或多个卷积层和顶端的全连通层组成,同时也包括关联权重和池化层(pooling layer),使得卷积神经网络能够利用输入数据的二维结构进行演算。与其他深度学习结构相比,卷积神经网络在图像和对象辨识方面具有更好的结果,且需要考虑的参数更少,因此对象辨识准确率相对较高,例如大于90%。卷积神经网络还可分为区域卷积神经网络(R-CNN)、快速型区域卷积神经网络(Fast R-CNN)及更快速型区域卷积神经网络(Faster R-CNN),通过对输入数据分成多个区域,并将每个区域分到对应的类别中,再将所有的区域结合在一起,以完成目标物体的检测。
传统的基于机器学习的对象辨识方法,系利用卷积神经网络直接对二维影像的RGB图像、RGB-D图像或融合的RGB-LIDAR图像进行机器学习并进行对象特征撷取,由于传统的方法需进行高速运算并消耗大量时间及运算资源,才能获得计算结果,因而无法减少运算时间。
相对地,本实施例中基于机器学习的对象辨识系统及其方法,其中运算模块可先利用卷积神经网络、K-means分群法或基于SVM及K-means分群架构进行机器学习,以对三维空间点云数据进行对象分割,并进行深度识别,以得到粗框选的至少一关注区域(简称为“粗关注区域”)。被框选之关注区域可为一个或多个,本实施例不加以限定。接着,再根据「粗关注区域」的坐标数据,对二维影像中对应「粗关注区域」的至少一关注特征进行特征提取及“细关注区域”的微调,以供运算模块能更快速地辨识“细关注区域”中的对象种类,因此能有效减少运算时间,例如少于90微秒(ms)。
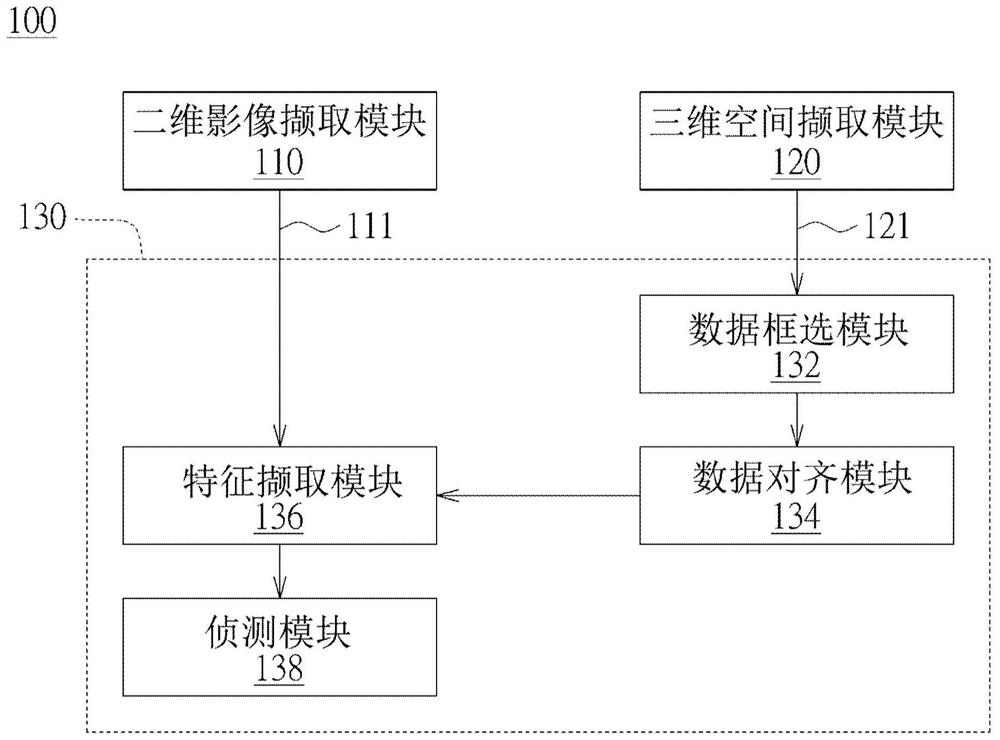
请参照图1,其绘示依照本公开一实施例的基于机器学习的对象辨识系统100的示意图。对象辨识系统100包括二维影像撷取模块110、三维空间撷取模块120以及一运算模块130。二维影像撷取模块110例如为相机,用以撷取二维影像111。三维空间撷取模块120例如为光学雷达(LIDAR)模块或三维光学扫描模块,可利用时差测距(time-of-flight)或三角测距(triangulation)技术撷取三维空间点云数据121,以建立三维空间中的物体模型。在另一实施例中,三维空间撷取模块120也可利用结构光投影在目标物上,并以二维影像撷取模块110撷取具有结构光的二维影像111,以产生深度影像的数据。
运算模块130用以同步取得二维影像撷取模块110及三维空间撷取模块120撷取的二维影像111及三维空间点云数据121,并通过机器学习,对三维空间点云数据121进行对象分割,并进行深度识别。同时,运算模块130还可通过机器学习,对二维影像111中对应关注区域的至少一对象进行识别,以判断对象的种类和对象的距离。有关运算模块130的具体架构请参照图2的说明。
请参照图2,其绘示依照本公开一实施例的基于机器学习的对象辨识系统100的具体架构的示意图。运算模块130可包括一数据框选模块132、一数据对齐模块134、一特征撷取模块136以及一侦测模块138。数据框选模块132根据三维空间点云数据121进行对象分割,并进行深度识别,以框选至少一关注区域。数据对齐模块134映射关注区域的坐标至二维影像111的坐标中。特征撷取模块136计算二维影像的特征,并由二维影像的特征中提取对应关注区域的坐标的至少一关注特征。侦测模块138用以取得关注特征,并根据关注特征,对二维影像111中的至少一影像进行识别。
在一实施例中,数据框选模块132可利用特征侦测器(feature detector)来选取三维空间点云数据121中的一些局部特征,并可结合选择性搜寻、卷积神经网络模型以及支持向量机(SVM)分类器来进行机器学习,以找到目标对象可能所在的位置。选择性搜寻可考虑点云的空间分布、距离相似度、尺寸相似度与填充相似度等相似度演算,将局部特征从点云数据中分割出来,以成为至少一关注区域。被框选之关注区域可为一个或多个,本实施例不加以限定。同时,数据框选模块132只需针对目标对象可能所在的位置的关注区域进行粗框选,不需进一步判断对象的特征,相对减少演算时间。
此外,数据对齐模块134映射关注区域的坐标至二维影像111的坐标中,以使特征撷取模块136取得关注区域的坐标与二维影像111的坐标的对应关系。也就是说,将三维空间的坐标(x,y,z)映射至二维影像111的每个像素坐标中(pixel x,pixel y),其中pixel x表示对应X轴坐标的像素,pixely表示对应Y轴坐标的像素,z为深度信息。在本实施例中,数据对齐模块134只需将关注区域的坐标映射至二维影像111的坐标中,不需将所有的三维空间点云数据121映射至二维影像111的坐标中,以减少数据处理量。
此外,特征撷取模块136取得关注区域的坐标与二维影像111的坐标的对应关系之后,计算二维影像的特征,并由二维影像的特征中提取对应关注区域的坐标的至少一关注特征。也就是说,特征撷取模块136只对二维影像111的局部区域进行分析,以对二维影像111中对应“粗关注区域”的一关注特征进行特征提取。
另外,侦测模块138取得关注特征之后,可根据关注特征,对二维影像111中的一对象进行识别。同时,侦测模块138还能通过对象分割结果,在二维影像111上精确地得到对应此对象的一细关注区域,以缩小“粗关注区域”的范围。
请参照图3,其绘示依照本公开一实施例的基于机器学习的对象辨识方法的示意图。对象辨识方法包括下列步骤S11~S17。在步骤S11中,撷取二维影像111。在步骤S12中,撷取三维空间点云数据121。在步骤S13中,根据三维空间点云数据121进行对象分割,并进行深度识别,以框选至少一关注区域。被框选之关注区域可为一个或多个,本实施例不加以限定。在步骤S14中,映射关注区域的坐标至二维影像111的坐标中。在步骤S15中,计算二维影像111的特征,并由二维影像111的特征中提取对应关注区域的坐标的至少一关注特征。在步骤S16中,根据关注特征,对二维影像111中的至少一对象进行识别。
请参照图2及图4,其中图4绘示图3中基于机器学习的对象辨识方法的具体步骤的示意图。对象辨识方法包括下列步骤S111~S171。在步骤S111中,撷取二维影像111。在步骤S121中,撷取三维空间点云数据121。步骤S131,三维空间撷取模块120先将三维空间点云数据121转换至一深度影像,并根据深度影像进行对象分割,以供后续进行深度识别。待对象分割之后,数据框选模块132进行深度识别,以框选至少一关注区域。被框选之关注区域可为一个或多个,本实施例不加以限定。在步骤S141中,数据对齐模块134建立三维空间点云数据121的空间坐标与二维影像111的平面坐标的对应关系,以供后续映射关注区域的坐标至二维影像111的坐标中,以产生一映射数据。在步骤S151中,特征撷取模块136取得二维影像111与映射数据之后,计算二维影像的所有特征(但不用分析所有特征代表的含义),并由二维影像111的特征中提取对应关注区域的坐标的至少一关注特征(不需要对所有特征进行提取)。在步骤S161中,侦测模块138根据关注特征,对二维影像111中的至少一对象进行识别,且侦测模块138还可根据深度影像计算此对象的一深度信息。此外,在步骤S171中,当侦测模块138得知此对象的深度信息之后,还可重新定义二维影像111中对应此对象的一框选区域(即细框选区域),并以深度信息为一对象遮罩,去除二维影像111中对应框选区域的对象以外的一背景影像(即对象表面轮廓外的背景影像)。
也就是说,在步骤S171中,由于二维影像111中对应框选区域的对象以外的一背景影像已被去除,因此对象的关注特征更为明显,以排除二维影像111的背景对对象辨识度的影响,故能提高对象辨识准确率,例如高于93%以上。
本公开上述实施例所述的基于机器学习的对象辨识系统及其方法,利用三维点云数据辅助二维影像识别网络,数据框选模块采用来自三维空间的点云数据来辅助二维影像的识别,是通过由三维空间的点云数据直接框选二维影像中对应关注区域的一关注特征,不需获得二维影像识别的数据后再转为三维点云数据与数据库进行比对,也不需将深度数据D与二维影像的RGB数据结合为RGB-D图像或将LIDAR数据与二维影像的RGB数据融合为RGB-LIDAR图像,因此可有效减少运算时间。同时,本实施例的对象辨识系统及其方法能应用在无人车或自动化驾驶的领域中,除了可提高对象辨识速度之外,更可进一步提高对象辨识准确率,符合实时辨识的需求。
综上所述,虽然本公开已以实施例揭露如上,然其并非用以限定本公开。本公开所属技术领域中具有通常知识者,在不脱离本公开之精神和范围内,当可作各种的更动与润饰。因此,本公开的保护范围当视后附的申请专利范围所界定者为准。
- 基于机器学习的对象辨识系统及其方法
- 基于机器学习的高轨道卫星光压模型辨识方法及系统