节点性能检测方法和装置
文献发布时间:2023-06-19 11:45:49
技术领域
本公开涉及分布式计算领域,尤其涉及一种节点性能检测方法和装置。
背景技术
在大规模分布式计算服务中,计算节点集群的规模可达到数千台物理机或虚拟机,所有的计算服务运行在各节点上。但由于节点性能参差不齐,在分布式计算服务中,虽已经为宕机节点配置了容错能力,但是也受到木桶理论的限制,用户作业(job)最终的运行时间取决于计算任务所有拆分任务(task)中运行时间最长的task所消耗的时间。在某此task运行时间过长的情况下,无法在短时间内快速定位影响性能、导致任务运行慢的原因,也无法自动且准确的探测确定异常节点。虽然通过基本硬件健康信息或者系统日志能够判断发生异常的位置,但由于集群众多,且机器机型差异性也比较大,无法统一硬件信息检查的入口,因此探测成本非常高。且很多情况下探测结果表明机器系统日志及硬件并没有异常,但是性能确实存在问题(可能由于硬件老化等其他原因造成)。
综上,缺乏对分布式计算服务性能进行分析的有效机制。
发明内容
为克服相关技术中存在的问题,本公开提供一种用于分布式计算系统中的节点性能检测方法和装置。
根据本公开实施例的第一方面,提供一种用于分布式计算系统中的节点性能检测方法,包括:
获取集群中各节点的历史任务的运行数据;
分析所述历史任务的运行数据;
根据分析结果,确定各节点的性能。
优选的,所述获取集群中各节点的历史任务的运行数据的步骤包括:
周期性的获取集群中各节点的历史任务的运行数据。
优选的,所述历史任务的运行数据包括任务指标数据和任务明细数据;
其中,所述任务指标数据至少包括以下数据中的任一或任意多项:
所述历史任务的数量、历史任务的类型、各类型的历史任务的平均运行时间,一个类型的历史任务的平均运行时间为该类型的所述历史任务的总运行时间/该类型的所述历史任务的个数;
所述任务明细数据至少包括以下数据中的任一或任意多项:
执行所述历史任务的节点的身份信息、各个历史任务的运行时间;
所述分析所述历史任务的运行数据的步骤包括:
确定各历史任务的实际超发倍数,所述实际超发倍数为:
该所述历史任务的运行时间/所述历史任务的平均执行时间;
遍历分析所述历史任务,从中筛选出实际超发倍数超过预设的标准超发倍数的历史任务;
当所述历史任务的实际超发倍数大于所述标准超发倍数时,确定执行所述历史任务的节点为所述历史任务的实际执行节点;
针对每个实际超发倍数超过预设的标准超发倍数的所述历史任务生成超发记录;
所述超发记录至少包括以下信息:
所述历史任务的实际执行节点,该所述历史任务的实际超发倍数。
优选的,所述根据分析结果,确定各节点的性能的步骤包括:
对所生成的所有超发记录进行处理,确定每个节点作为实际执行节点出现的频次和平均超发倍数,得到分析信息,
所述节点的平均超发倍数为所述节点对应的所有超发记录中实际超发倍数的平均值,
所述分析信息至少包括以下信息中的任一或任意多项:
所述节点的身份信息,所述节点出现的频次,所述节点的平均超发倍数;
根据所述节点出现的频次和/或平均超发倍数,对各节点进行排序;
根据排序确定节点的性能。
优选的,该方法还包括:
判定符合预设的低性能标准的节点为低性能节点,所述低性能标准至少包含以下条件中的任一个或任意多个:
节点出现的频次大于预设的频次数量阈值,
节点的平均超发倍数大于预设的节点超发倍数阈值。
优选的,所述历史任务类型为映射map任务或还原reduce任务。
优选的,所述历史任务的运行数据包括执行过程中被中止的任务信息,所述分析所述历史任务的运行数据的步骤包括:
遍历所述历史任务的运行数据,生成各节点的节点性能数据,所述节点性能数据至少包括节点的身份信息以及该节点上被中止的任务数量。
优选的,所述根据分析结果,确定各节点的性能的步骤包括:
按照节点上被中止的任务数量降序的规则对各个节点进行排序;
根据排序确定所述节点的性能。
优选的,该方法还包括:
判定符合预设的低性能标准的节点为低性能节点,所述低性能标准至少包含以下条件:
节点上被中止的任务数量超过预设的节点中止任务数量阈值。
根据本公开的实施例的第二方面,提供了一种用于分布式计算系统中的节点性能检测装置,包括:
数据获取模块,用于获取集群中各节点的历史任务的运行数据;
数据分析模块,用于分析所述历史任务的运行数据;
性能分析模块,用于根据分析结果,确定各节点的性能。
优选的,所述历史任务的运行数据包括任务指标数据和任务明细数据;
其中,所述任务指标数据至少包括以下数据中的任一或任意多项:
所述历史任务的数量、历史任务的类型、各类型的历史任务的平均运行时间,一个类型的历史任务的平均运行时间为该类型的所述历史任务的总运行时间/该类型的所述历史任务的个数,
所述任务明细数据至少包括以下数据中的任一或任意多项:
执行所述历史任务的节点的身份信息、各个历史任务的运行时间,
所述数据分析模块包括:
超发倍数计算子模块,用于确定各历史任务的实际超发倍数,所述实际超发倍数为:
所述历史任务的实际执行时间/所述历史任务的平均执行时间;
任务筛选子模块,用于遍历分析所述历史任务,从中筛选出实际超发倍数超过预设的标准超发倍数的历史任务;
执行节点确定子模块,用于当所述历史任务的实际超发倍数大于所述标准超发倍数时,确定执行所述历史任务的节点为所述历史任务的实际执行节点;
超发记录生成子模块,用于针对每个实际超发倍数超过预设的标准超发倍数的所述历史任务生成超发记录;
所述超发记录至少包括以下信息:
所述历史任务的实际执行节点,所述历史任务的实际超发倍数。
优选的,所述性能分析模块包括:
记录处理子模块,用于对所生成的所有超发记录进行处理,确定每个节点作为实际执行节点出现的频次和平均超发倍数,得到分析信息,
所述节点的平均超发倍数为所述节点对应的所有超发记录中实际超发倍数的平均值,
所述分析信息至少包括以下信息中的任一或任意多项:
所述节点的身份信息,所述节点出现的频次,所述节点的平均超发倍数;
第一节点排序子模块,用于根据所述节点出现的频次和/或平均超发倍数,对各节点进行排序;
第一节点性能确定子模块,用于根据排序确定节点的性能。
优选的,该装置还包括:
第一低性能节点判定模块,用于判定符合预设的低性能标准的节点为低性能节点,所述低性能标准至少包含以下条件中的任一个或任意多个:
节点出现的频次大于预设的频次数量阈值,
节点的平均超发倍数大于预设的节点超发倍数阈值。
优选的,所述历史任务的运行数据包括执行过程中被中止的任务信息,所述数据分析模块包括:
性能数据生成子模块,用于遍历所述历史任务的运行数据,生成各节点的节点性能数据,所述节点性能数据至少包括节点的身份信息以及该节点上被中止的任务数量。
优选的,所述性能分析模块包括:
第二节点排序子模块,用于按照节点上被中止的任务数量降序的规则对各个节点进行排序;
第二节点性能确定子模块,用于根据排序确定所述节点的性能。
优选的,该装置还包括:
第二低性能节点判定模块,用于判定符合预设的低性能标准的节点为低性能节点,所述低性能标准至少包含以下条件:
节点上被中止的任务数量超过预设的节点中止任务数量阈值。
根据本公开的示例性实施例的第三方面,提供了一种计算机装置,包括:
处理器;
用于存储处理器可执行指令的存储器;
其中,所述处理器被配置为:
获取集群中各节点的历史任务的运行数据;
分析所述历史任务的运行数据;
根据分析结果,确定各节点的性能。
优选的,所述处理器进一步被配置为执行上述节点性能检测方法的全部步骤。
根据本公开的实施例的第四方面,提供了一种非临时性计算机可读存储介质,当所述存储介质中的指令由移动终端的处理器执行时,使得移动终端能够执行一种节点性能检测方法,所述方法包括:
获取集群中各节点的历史任务的运行数据;
分析所述历史任务的运行数据;
根据分析结果,确定各节点的性能。
优选的,所述方法包括上述节点性能检测方法的全部步骤。
本公开的实施例提供的技术方案可以包括以下有益效果:在分布式计算系统中,获取集群中各节点的历史任务的运行数据,分析所述历史任务的运行数据,并根据分析结果,确定各节点的性能。无需添加新的硬件或软件系统,通过历史任务的运行数据,对不同场景下的分布式计算系统运行情况进行分析,解决了缺乏对分布式计算系统性能分析机制的问题,实现了低成本、高效率、准确的节点性能检测。
应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。
附图说明
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本发明的实施例,并与说明书一起用于解释本发明的原理。
图1是根据一示例性实施例示出的一种节点性能检测方法的流程图。
图2是根据一示例性实施例示出的一种节点性能检测方法的流程图。
图3是根据一示例性实施例示出的分析历史任务的运行数据的流程图。
图4根据一示例性实施例示出的确定各节点的性能的流程图。
图5是根据一示例性实施例示出的一种节点性能检测方法的原理示意图。
图6是根据一示例性实施例示出的一种节点性能检测方法的流程图。
图7是根据一示例性实施例示出的确定各节点的性能的流程图。
图8是根据一示例性实施例示出的一种节点性能检测方法的原理示意图。
图9是根据一示例性实施例示出的一种节点性能检测装置的框图。
图10是根据一示例性实施例示出的一种数据分析模块902的框图。
图11是根据一示例性实施例示出的一种性能分析模块903的框图。
图12是根据一示例性实施例示出的一种节点性能检测装置的框图。
图13是根据一示例性实施例示出的一种节点性能检测装置的框图。
图14是根据一示例性实施例示出的一种装置的框图(服务器的一般结构)。
具体实施方式
这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本发明相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本发明的一些方面相一致的装置和方法的例子。
在大规模分布式计算服务中,计算节点集群的规模可达到数千台物理机或虚拟机,所有的计算服务运行在各节点上。但由于节点性能参差不齐,在分布式计算服务中,虽已经为宕机节点配置了容错能力,但是也受到木桶理论的限制,用户job最终的运行时间取决于计算任务所有拆分task中运行时间最长的task所消耗的时间。在某此task运行时间过长的情况下,无法在短时间内快速定位影响性能、导致任务运行慢的原因,也无法自动且准确的探测确定异常节点。虽然通过基本硬件健康信息或者系统日志能够判断发生异常的位置,但由于集群众多,且机器机型差异性也比较大,无法统一硬件信息检查的入口,因此探测成本非常高。且很多情况下探测结果表明机器系统日志及硬件并没有异常,但是性能确实存在问题(可能由于硬件老化等其他原因造成)。
为了解决上述问题,本公开的实施例提供了一种节点性能检测方法和装置,在分布式计算系统中获取集群中各节点的历史任务的运行数据,分析所述历史任务的运行数据,并根据分析结果,确定各节点的性能。以节点为单位,分析分布式计算系统的计算性能,能够在多种应用场景下准确的定位发生异常的节点,且无需增加额外的配置,在降低维护成本的同时解决了缺乏对分布式计算系统性能分析机制的问题。进一步的,可为后续的低性能现象原因分析与解决提供数据基础。
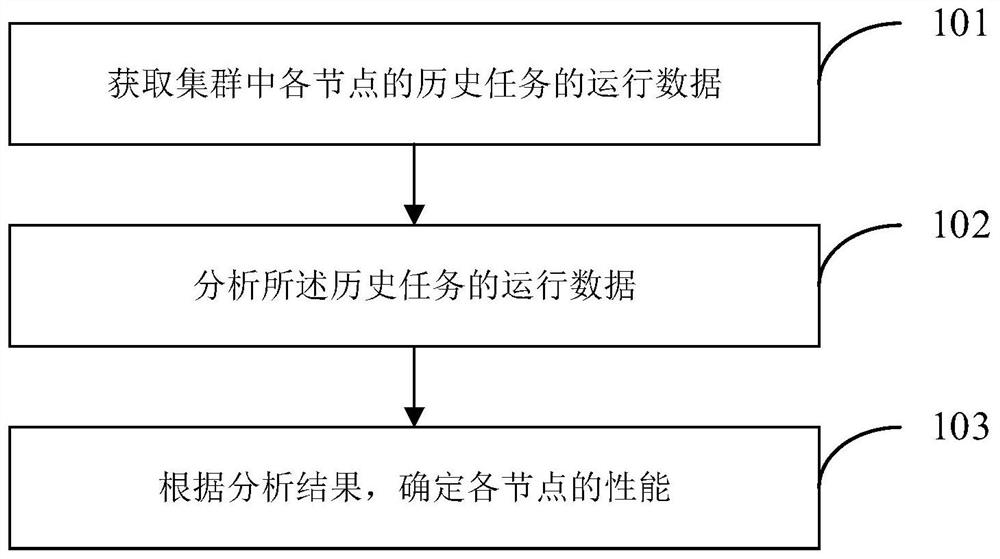
本公开的一示例性实施例提供了一种节点性能检测方法,使用该方法完成节点性能检测的流程如图1所示,包括:
步骤101、获取集群中各节点的历史任务的运行数据。
本公开实施例中,所述历史任务的运行数据表明节点运行任务的效率。分布式计算系统由多个可通信的节点组成。无论分布式计算系统是否开启推测执行功能,其在运行过程中都会产生历史任务的运行数据。对历史任务的运行数据进行处理分析,即可确定各节点的性能表现。
优选的,本公开的实施例提供的节点性能检测方法可周期性运行,以及时更新节点性能方面的数据。相应的,本步骤也可周期性进行,即周期性的获取集群中各节点的历史任务的运行数据。
步骤102、分析所述历史任务的运行数据。
本步骤中,分析所述历史任务的运行数据,以节点为单位对所述历史任务的运行数据进行处理,以确定各节点的性能表现。
步骤103、根据分析结果,确定各节点的性能。
在确定各节点的性能表现后,即可看出各节点的性能差异,在此基础上,可筛选出性能相对较低甚至明显较低的节点,定位异常节点。
本公开的一示例性实施例还提供了一种节点性能检测方法,在分布式计算系统未开启推测执行功能的情况下,涉及的历史任务包括映射(map)或还原(reduce)任务,一个map/reduce任务分为map阶段和reduce阶段,每个阶段又分为若干任务。使用该方法分析节点性能的流程如图2所示,包括:
步骤201、获取集群中各节点的历史任务的运行数据。
本步骤中,分布式计算系统具体为分布式计算服务集群,其中运行有多个应用Applicaiotn 1–Application N。所述历史任务的运行数据表明节点运行任务的效率,自分布式计算服务集群获取原始的历史任务的运行数据后进行数据清洗,即可得到历史任务的运行数据中包含的任务指标数据和任务明细数据。
具体的,原始的历史任务的运行数据可通过调取分布式计算服务作业历史(jobhistory)的rest接口的方式获取集群历史运行任务数据列表,进一步获取到历史任务的运行数据,获取的历史任务的运行数据中涉及的任务数量取决于job history的配置。然后,以job为单位进行数据清洗,即得到任务指标数据和任务明细数据。可通过历史作业服务器保留分布式计算服务作业历史中的作业数量(如2w)或者作业保留时间(如7天)控制可访问的历史任务范围。
其中,所述任务指标数据至少包括以下数据中的任一或任意多项:
所述历史任务的数量、历史任务的类型、各类型的历史任务的平均运行时间,一个类型的历史任务的平均运行时间为该类型的所述历史任务的总运行时间/该类型的所述历史任务的个数。
具体的,所述历史任务的类型可包括map任务和reduce任务,相应的所述历史任务的数量可包含map任务数量和reduce任务数量两部分。
每个历史任务的平均运行时间可包含每个map任务平均运行时间和每个reduce任务平均运行时间两部分。具体的,map任务这一类型的历史任务的平均运行时间为map任务的总运行时间/map任务的个数,reduce任务这一类型的历史任务的平均运行时间为reduce任务的总运行时间/reduce任务的个数。
所述任务指标数据还可包括应用标识(AppID)。
所述任务明细数据至少包括以下数据中的任一或任意多项:
执行所述历史任务的节点的身份信息,各个历史任务的运行时间。
其中,所述各个历史任务的运行时间具体可包含各个map任务的运行时间及各个reduce任务的运行时间。所述各个历史任务的运行时间为历史任务实际执行所消耗的时间。
在获取历史任务的运行数据后,即可对运行数据进行进一步的分析,进入步骤202。
步骤202、分析所述历史任务的运行数据。
本步骤具体如图3所示,包括:
步骤2021、确定各历史任务的实际超发倍数。
本步骤中,所述实际超发倍数为:
所述历史任务的运行时间/所述历史任务的平均执行时间;
具体的,可根据以下表达式计算各map任务的map任务超发倍数:
map任务超发倍数=map任务的运行时间/map任务平均运行时间。
可根据以下表达式计算各reduce任务的reduce任务超发倍数:
reduce任务超发倍数=reduce任务的运行时间/reduce任务平均运行时间。
优选的,在本步骤中,可先过滤掉任务数量较少的作业涉及的任务。例如,对于某一作业来说,其包含的map任务和reduce任务之和小于5,其涉及的任务数量过少,数据不具有参考价值,可归类为不可靠数据。将这类数据过滤后再进行实际超发倍数的计算,有助于减少不可靠数据的干扰,提升计算效率。
步骤2022、遍历分析所述历史任务,从中筛选出实际超发倍数超过预设的标准超发倍数的历史任务。
本步骤中,根据步骤2021的计算结果,从中筛选中实际超发倍数超过预设的标准超发倍数的历史任务,这部分历史任务由于超发倍数过大,表明存在运行速度过慢的可能。
本公开实施例中,可预先设置标准超发倍数,所述标准超发倍数可任对一类或多类任务进行设置。例如,对于map任务和reduce任务分别设置标准超发倍数,也可只设置一个标准超发倍数。本公开实施例中,以设置一个标准超发倍数值为例进行说明。
步骤2023、当所述历史任务的实际超发倍数大于所述标准超发倍数时,确定执行所述历史任务的节点为所述历史任务的实际执行节点。
本步骤中,在发现存在超发的历史任务后,进一步的,确定执行该历史任务的节点,以该节点作为实际执行节点。
步骤2024、针对每个实际超发倍数超过预设的标准超发倍数的所述历史任务生成超发记录。
本步骤中,针对筛选得到的历史任务,结合实际执行节点的信息,生成超发记录。
所述超发记录至少包括以下信息:
所述历史任务的实际执行节点,所述历史任务的实际超发倍数。
本步骤中,在每发现一个超发倍数超过标准超发倍数的任务时,即生成一条超发记录。具体的,在每发现一个超发倍数超过标准超发倍数的map任务时,即生成一条超发记录;在每发现一个超发倍数超过标准超发倍数的reduce任务时,也会生成一条超发记录。对于同一节点,其在map阶段有可能发生其处理的map任务超发倍数超过标准超发倍数的情况,而没有reduce阶段超发倍数超过标准超发倍数的情况;也可能在map阶段和reduce阶段均发生超发倍数超过标准超发倍数的情况。
经过本步骤处理后,即可得到多条超发记录,构成一个实际执行节点和实际超发倍数的数据集合。例如:
{[节点1,6],[节点2,8],[节点1,7]...}
对实际超发倍数的计算会针对全部的map和reduce任务进行。
步骤203、根据分析结果,确定各节点的性能。
本步骤具体如图4所示,包括:
步骤2031、对所生成的所有超发记录进行处理,确定每个节点作为实际执行节点出现的频次和平均超发倍数,得到分析信息。
本公开实施例中,所述节点的平均超发倍数为所述节点对应的所有超发记录中实际超发倍数的平均值。
所述分析信息至少包括以下信息中的任一或任意多项:
所述节点的身份信息,所述节点出现的频次,所述节点的平均超发倍数。
其中,所述的节点出现的频次为涉及所述节点的全部超发记录的数量,所述节点的平均超发倍数=节点的全部超发记录中的实际超发倍数之和/节点的超发记录数量。
以下为一种分析信息的格式示例:
{“节点1”:[节点1出现的频次,节点1的平均超发倍数],“节点2”:[节点2出现的频次,节点2的平均超发倍数]...}
步骤2032、根据所述节点出现的频次和/或平均超发倍数,对各节点进行排序。
本步骤中,可以节点性能数据中的节点的超发记录数量和/或节点的平均超发倍数为维度,对节点进行排序,排序结果能够在一定程度上反映不同节点间性能的差异。
步骤2033、根据排序确定节点的性能。
由于任务基数大,任务在各个节点上的分布也相对平均,即使在步骤202中由于数据倾斜而导致误判成“低性能节点”,此时数据倾斜的情况会较平均的分布在所有节点上,并且数量上会远小于真实的性能低的节点数量。例如,在依据节点的超发记录数量从大到小的顺序排名时,排名靠前且远比其他值大的节点大概率是低性能节点所在,可称其为“嫌疑节点”。对“嫌疑节点”可发送警告邮件通知管理员,由管理员分析处理;或进行回调处理,调用分布式计算服务的相关接口或调用外部命令关闭巡检出异常的计算节点服务。
例如,步骤202得到的超发记录集合如下:
A100(实际执行节点,下同),6(实际超发倍数,下同);
A200,10;
A101,9;
A100,8。
接下来以实际执行节点为单位对超发记录进行聚合操作(例如COUNT和AVG),即第一列是实际执行节点,第二列是节点出现的频次,第三列是平均超发倍数。以第二、三列为维度做降序排序,排序结果如下所示:
A100,2,7
A200,1,10
A101,1,9
这样就得到了作为实际执行节点的每个节点的出现的频次和平均超发倍数的信息,出现的频次决定了“慢”节点(低性能节点的一种)出现的频率,平均超发倍数决定了“慢”节点的影响力程度。一般情况下出现的频次远高于其他的节点,其为“慢”节点的概率非常高。而“慢”节点出现次数多,其平均倍数也会高(“慢”节点由于低性能会导致分配到该节点的任务运行缓慢很多倍)。按照以上排序,排序越靠前的节点,其为“慢节点”的可能性越大。
步骤204、判定符合预设的低性能标准的节点为低性能节点。
优选的,可设置低性能标准,划定一个范围,符合低性能标准落入该范围的节点表明该节点属于低性能节点的可能性较大,可判定落入该范围的节点即为低性能节点,对低性能节点可进行进一步的分析排查,以确定异常节点和异常原因。
本公开实施例中,所述低性能标准至少包含以下条件中的任一个或任意多个:
节点出现的频次大于预设的频次数量阈值,
节点的平均超发倍数大于预设的节点超发倍数阈值。
如图3所示的节点性能检测流程,可周期性进行,例如每小时进行一次。
如图5所示,为本公开实施例的实现原理示意图。
本公开的一示例性实施例还提供了一种节点性能检测方法,在分布式计算系统开启推测执行功能的情况下,使用该方法分析节点性能的流程如图6所示,包括:
步骤601、获取集群中各节点的历史任务的运行数据。
本步骤中,分布式计算系统具体为分布式计算服务集群,其中运行有多个应用Applicaiotn1–ApplicationN。所述历史任务的运行数据表明节点运行任务的效率,自分布式计算服务集群获取原始的历史任务的运行数据,进一步获取推测执行的任务信息,清洗后得到历史任务的运行数据,所述历史任务的运行数据包括推测执行过程中被中止的任务信息。
具体的,通过调取分布式计算服务集群job history的rest接口的方式,获取集群历史运行任务数据列表,获取到原始的历史任务的运行数据,涉及的任务数量取决于jobhistory的配置。然后,获取原始的历史任务的运行数据中的应用标识(AppID),拼接出该任务的App任务详情的地址串(URL),使用爬虫的方式解析该地址串。也可调用resourcemanager的内部接口获取任务信息。再解析web,抓取其中由于推测执行特性被中止(kill)历史任务所在的节点信息,所述历史任务包含map和reduce阶段所有被kill的任务,解析web可获取map和reduce阶段所有被kill的任务的信息和被kill的原因(如:Speculation:attempt_1574834589794_7504_m_000309_0succeeded first!)。由于集群一般会开启代理服务器(proxy server)降低外部对web的恶意攻击,优选采取伪造cookie的方式对web进行解析,解析后可得到包含被中止的历史任务的节点的数据集合。
在获取历史任务的运行数据后,即可进入步骤602,分析所述历史任务的运行数据。
步骤602、分析所述历史任务的运行数据。
本步骤中,遍历所述历史任务的运行数据,生成各节点的节点性能数据,所述节点性能数据至少包括节点的身份信息以及该节点上被中止的任务数量。
例如对节点A200,使用正则匹配判定该节点上执行的历史任务是否由于推测执行被kill,如果是,则生成这个节点的节点性能数据,或更新这个节点已有的节点性能数据中的被中止的任务数量,将数量加1。如果当前的作业中没有被中止的map或者reduce任务则跳过,开始扫描下个历史任务。
本步骤中,对步骤601获取的数据集合中的数据以节点为单位进行聚合,计算数据集合每个节点出现的次数,即为节点上被中止的任务数量。
以下为一种节点性能数据格式的举例:
{“节点1”:”节点1上被中止的任务数量”,“节点2”:”节点2上被中止的任务数量”,...}。
步骤603、根据分析结果,确定各节点的性能。
本步骤具体如图7所示,包括:
步骤6031、按照节点上被中止的任务数量降序的规则对各个节点进行排序。
本步骤中,可以“节点上被中止的任务数量”为维度进行降序排序,排序结果能够在一定程度上反映不同节点间性能的差异。
由于任务基数大,任务在各个节点上的分布也相对平均,即使在步骤602中由于数据倾斜而导致误判成“低性能节点”,此时数据倾斜的情况会较平均的分布在所有节点上,并且数量上会远小于真实的性能低的节点数量。
步骤6032、根据排序确定所述节点的性能。
例如,在依据节点的超发记录数量从大到小的顺序排名时,排名靠前且远比其他值大的节点大概率是低性能节点所在,可称其为“嫌疑节点”。例如,按照“节点上被中止的任务数量”从高到低的降序顺序对节点进行排序,排名靠前且远比其他值大的节点大概率是低性能节点所在,可称其为“嫌疑节点”。对“嫌疑节点”可发送警告邮件通知管理员,由管理员分析处理;或进行回调处理,调用分布式计算服务的相关接口或调用外部命令关闭巡检出异常的计算节点服务。
步骤604、判定符合预设的低性能标准的节点为低性能节点。
优选的,可设置低性能标准,划定一个范围,符合低性能标准落入该范围的节点表明该节点属于低性能节点的可能性较大,可判定落入该范围的节点即为低性能节点,对低性能节点可进行进一步的分析排查,以确定异常节点和异常原因。
所述低性能标准至少包含以下条件:
节点上被中止的任务数量超过预设的节点中止任务数量阈值。
如图6所示的节点性能检测流程,可周期性进行,例如每小时进行一次。
如图8所示,为本公开实施例的实现原理示意图。
本公开的一示例性实施例还提供了一种节点性能检测装置,适用于分布式计算系统,其结构如图9所示,包括:
数据获取模块901,用于获取集群中各节点的历史任务的运行数据;
数据分析模块902,用于分析所述历史任务的运行数据;
性能分析模块903,用于根据分析结果,确定各节点的性能。
优选的,所述历史任务的运行数据包括任务指标数据和任务明细数据;
其中,所述任务指标数据至少包括以下数据中的任一或任意多项:
所述历史任务的数量、历史任务的类型、各类型的历史任务的平均运行时间,一个类型的历史任务的平均运行时间为该类型的所述历史任务的总运行时间/该类型的所述历史任务的个数。
所述任务明细数据至少包括以下数据中的任一或任意多项:
执行所述历史任务的节点的身份信息,各个历史任务的运行时间。
所述数据分析模块902的结构如图10所示,包括:
超发倍数计算子模块9021,用于确定各历史任务的实际超发倍数,所述实际超发倍数为:
所述历史任务的实际执行时间/所述历史任务的平均执行时间;
任务筛选子模块9022,用于遍历分析所述历史任务,从中筛选出实际超发倍数超过预设的标准超发倍数的历史任务;
执行节点确定子模块9023,用于当所述历史任务的实际超发倍数大于所述标准超发倍数时,确定执行所述历史任务的节点为所述历史任务的实际执行节点;
超发记录生成子模块9024,用于针对每个实际超发倍数超过预设的标准超发倍数的所述历史任务生成超发记录;
所述超发记录至少包括以下信息:
所述历史任务的实际执行节点,所述历史任务的实际超发倍数。
优选的,所述性能分析模块903的结构如图11所示,包括:
记录处理子模块9031,用于对所生成的所有超发记录进行处理,确定每个节点作为实际执行节点出现的频次和平均超发倍数,得到分析信息,
所述节点的平均超发倍数为所述节点对应的所有超发记录中实际超发倍数的平均值,
所述分析信息至少包括以下信息中的任一或任意多项:
所述节点的身份信息,所述节点出现的频次,所述节点的平均超发倍数;
第一节点排序子模块9032,用于根据所述节点出现的频次和/或平均超发倍数,对各节点进行排序;
第一节点性能确定子模块9033,用于根据排序确定节点的性能。
优选的,该装置的结构如图12所示,还包括:
第一低性能节点判定模块904,用于判定符合预设的低性能标准的节点为低性能节点,所述低性能标准至少包含以下条件中的任一个或任意多个:
节点出现的频次大于预设的频次数量阈值,
节点的平均超发倍数大于预设的节点超发倍数阈值。
优选的,所述历史任务的运行数据包括执行过程中被中止的任务信息,所述数据分析模块902还包括:
性能数据生成子模块9025,用于遍历所述历史任务的运行数据,生成各节点的节点性能数据,所述节点性能数据至少包括节点的身份信息以及该节点上被中止的任务数量。
优选的,所述性能分析模块903还包括:
第二节点排序子模块9034,用于按照节点上被中止的任务数量降序的规则对各个节点进行排序;
第二节点性能确定子模块9035,用于根据排序确定所述节点的性能。
优选的,该装置的结构如图13所示,还包括:
第二低性能节点判定模块905,用于判定符合预设的低性能标准的节点为低性能节点,所述低性能标准至少包含以下条件:
节点上被中止的任务数量超过预设的节点中止任务数量阈值。
关于上述实施例中的装置,其中各个模块执行操作的具体方式已经在有关该方法的实施例中进行了详细描述,此处将不做详细阐述说明。
本公开的一示例性实施例还提供了一种计算机装置,包括:
处理器;
用于存储处理器可执行指令的存储器;
其中,所述处理器被配置为:
获取集群中各节点的历史任务的运行数据;
分析所述历史任务的运行数据;
根据分析结果,确定各节点的性能。
优选的,所述处理器进一步被配置为执行本公开的实施例提供的节点性能检测方法的全部步骤。
本公开的一示例性实施例还提供了一种非临时性计算机可读存储介质,当所述存储介质中的指令由移动终端的处理器执行时,使得移动终端能够执行一种节点性能检测方法,所述方法包括:
获取集群中各节点的历史任务的运行数据;
分析所述历史任务的运行数据;
根据分析结果,确定各节点的性能。
优选的,所述方法还包括本公开的实施例提供的节点性能检测方法的全部步骤。
图14是根据一示例性实施例示出的一种用于节点性能检测的装置1400的框图。例如,装置1400可以被提供为一服务器。参照图14,装置1400包括处理组件1422,其进一步包括一个或多个处理器,以及由存储器1432所代表的存储器资源,用于存储可由处理组件1422的执行的指令,例如应用程序。存储器1432中存储的应用程序可以包括一个或一个以上的每一个对应于一组指令的模块。此外,处理组件1422被配置为执行指令,以执行上述方法。
装置1400还可以包括一个电源组件1426被配置为执行装置1400的电源管理,一个有线或无线网络接口1450被配置为将装置1400连接到网络,和一个输入输出(I/O)接口1458。装置1400可以操作基于存储在存储器1432的操作系统,例如Windows ServerTM,MacOS XTM,UnixTM,LinuxTM,FreeBSDTM或类似。
本公开的实施例提供了一种节点性能检测方法和装置,在分布式计算系统中,获取集群中各节点的历史任务的运行数据,分析所述历史任务的运行数据,并根据分析结果,确定各节点的性能。无需添加新的硬件或软件系统,通过历史任务的运行数据,对不同场景下的分布式计算系统运行情况进行分析,解决了缺乏对分布式计算系统性能分析机制的问题,实现了低成本、高效率、准确的节点性能检测。
本公开支持对数千台的异构节点集群中低性能节点的快速定位,且可通过探测低性能节点的探测结果,为判断任务执行缓慢原因和后续回调处理等提供判断依据。在降低维护成本的同时解决了缺乏对分布式计算系统性能分析机制的问题。进一步的,可为后续的低性能现象原因分析与解决提供数据基础。
覆盖了分布式计算服务的全部场景,可周期性检测,且检测期间不影响业务正常使用。基于真实运行中产生的历史任务的运行数据进行检测,准确率高。根据检测结果,还可进行回调处理等自动处理,自动关闭问题节点,在用户无感知的情况下排除系统异常。
本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本发明的其它实施方案。本申请旨在涵盖本发明的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本发明的一般性原理并包括本公开未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本发明的真正范围和精神由下面的权利要求指出。
应当理解的是,本发明并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本发明的范围仅由所附的权利要求来限制。
- 交叉节点检测方法、利用计算机执行该方法的交叉节点检测程序、以及在交叉节点检测方法中使用的移动终端和中继装置
- 节点性能检测方法和装置