基于深度学习的预警制动方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及汽车目标的跟踪、检测及碰撞预警技术领域,特别涉及一种基于深度学习的预警制动方法。
背景技术
车辆在道路行驶过程中,周围环境瞬息万变,驾驶员注意力稍不集中就容易发生交通事故,目前大多数新能源汽车都配备有主动安全系统,可以通过对前方一定距离内出现的障碍物做到及时的预警与制动,实现对驾乘人员的安全保护。目前车辆的前碰撞预警制动系统的实现主要有以下两种方式:激光雷达测距和双目视觉测距。
激光雷达测距通过在车辆前方安装激光雷达测距装置,向目标发射出激光束,接收器接受到回波之后计算出车辆与目标之间的距离,当距离小于设定的阈值时,发出前方碰撞预警并采取相应的制动措施。双目视觉测距通过车辆前方的两个可见光相机对目标成像,计算出两幅图像的视差,从而得出目标与车辆之间的距离。
激光雷达测距精度高,但是成本也高,一台激光雷达的售价高达上万元,降低了车辆在价格上的竞争力。而双目视觉测距技术,需要两个可见光相机,虽然成本相对较低,但是测量距离范围太小,计算复杂度较高,在超过15米的测距场景下,精度较差。
发明内容
本发明的目的是为了克服已有技术的缺陷,提出一种基于深度学习的预警制动方法。
为实现上述目的,本发明采用以下具体技术方案:
一种基于深度学习的预警制动方法,利用预警制动系统实现,预警制动系统包括感知层、决策层和应用层;感知层为前端可见光相机;决策层为数据处理模块;应用层为制动控制单元;其特征在于,基于深度学习的预警制动方法包括如下步骤:
S1、可见光相机用于采集图像数据并标注,建立图像数据与车辆位置和距离信息映射关系并生成数据集;
S2、数据处理模块构建深度估计残差网络模型,对数据集进行卷积操作提取相应特征进行组合学习,得到图像的特征图模型;对深度估计残差网络模型进行训练,得到最终的网络权重;
S3、初始化网络权重参数,将原始图像数据送入到网络中,得出目标的位置和距离信息,制定相应的制动等级,并将相应的制动命令传递至后端制动控制系统。
优选的,步骤S1包括如下子步骤:
S11、在车辆的前方装备有可见光相机,根据天气条件、前方车辆距离和车辆类型的不同,设置不同的成像条件来采集图像数据;
S12、在车辆行驶过程中,对采集的图像数据进行标注;
S13、建立图像数据与车辆位置和距离信息映射关系并生成数据集;
S14、将图像数据和对应的车辆位置信息与车辆的距离信息作为样本送入数据集,生成带有标注信息的200条标注图像数据;
S15、通过数据集扩充技术,对标注图像数据进行翻转、平移和压缩,扩充成10倍的数据构建最终的标注数据集。
优选的,步骤S2包括如下子步骤:
S21、构建深度估计网络模型,深度估计网络模型的网络为残差网络;
残差网络模型利用一种多尺度的深度卷积神经网络提取图像中的车辆特征,将416x416大小的图像输入网络,经过步长为2,大小为7x7x64的卷积核进行卷积,得出208x208的特征图像;然后再经过步长为2的3x3大小的池化层和3个Conv2_x的卷积核,得到104x104的输出特征图;然后再经过4个Conv3_x的卷积核,得到52x52的输出特征图;然后再经过23个Conv4_x的卷积核,得到26x26的输出特征图;然后再经过3个Conv5_x的卷积核,得到13x13的输出特征图;
S22、对残差网络模型进行训练,得到最终的网络权重;
采用的损失函数如下:
损失函数的建立包括4个步骤:
S221:预测的矩形框对角线长度的平方和损失;
S222:预测框中心坐标和实际目标中心坐标的平方和损失;通过比较预测框中心点和图像的中心点(x
S223:表示像素深度的平方和损失,通过将深度估计损失引入到损失函数中进行迭代优化,使得网络最终能够预测当前像素所对应的深度信息;
S224:表示置信度的交叉熵损失,通过在损失函数中引入置信度损失,来迭代优化最终目标的置信度;
参数
预测框的横坐标x,纵坐标y,宽w,高h,取值经过归一化,范围在0~1之间;
S23:使用梯度下降策略,迭代优化损失函数的值,使损失函数不断下降到最优点,保存好当前的网络权重参数;在进行下次预测时,带入到当前网络权重参数中得出新的x、y、D(x,y)、diagonal、p的值。
优选的,步骤S3包括:
S31、根据网络权重生成目标的位置信息和每一个像素点对应的深度信息D(x,y);
S32、目标距离Dst(x,y)通过计算目标区域内的像素深度信息均值得到,计算方法如下:
参数x
S33、对于图像中存在的多个车辆目标,通过以下流程筛选出前车辆目标;
S331、初始化中心距离变量dmax,目标编号num max;
S332、将网络生成的所有目标遍历深度估计;
S333、当目标的置信度大于0.9,计算目标中心和图像中心的距离dcentre和目标编号num;
S334、若计算目标中心和图像中心的距离dcentre大于初始化中心距离变量dmax;dmax=dcentre,num max=num;
S335、遍历结束;
S336、取num max编号所对应的目标为前车辆目标;
S34、根据当前车辆速度、前车辆距离与制动等级的映射表,得出相应的制动等级,并将相应的制动命令传递至后端制动控制系统,制动控制系统作出制动的动作,车辆停止。
本发明提供的基于深度学习的预警制动方法,在车辆前方装备有一台可见光相机,运用深度学习神经网络技术感知前方障碍物,探测出目标与车辆之间的距离,根据当前车速和距离之间的关系,采取不同的制动策略。本发明具有成本低便于部署,可探测距离远,精确度高的特点。
附图说明
图1是根据本发明实施例提供的基于深度学习的预警制动系统流程示意图。
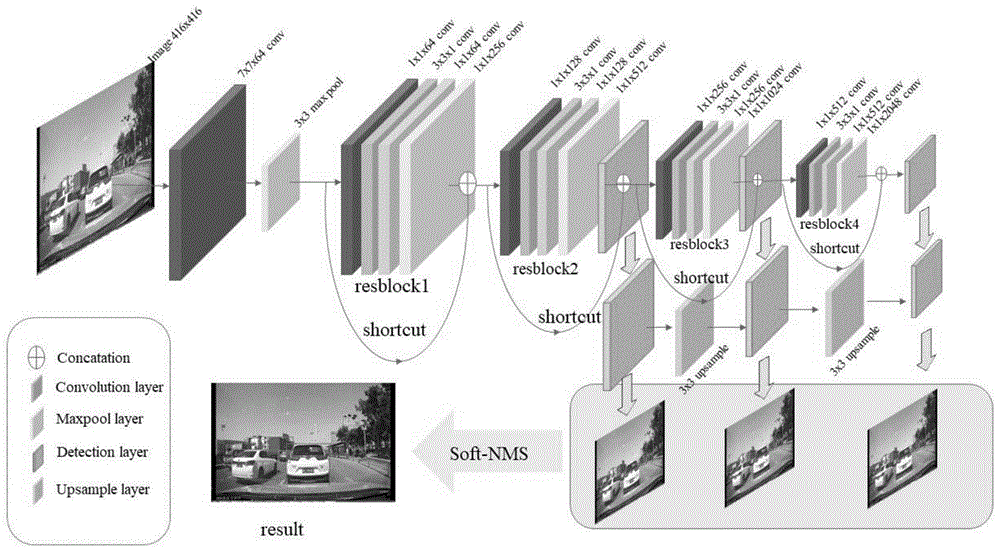
图2是根据本发明实施例提供的基于深度学习的预警制动方法网络流程示意图。
具体实施方式
在下文中,将参考附图描述本发明的实施例。在下面的描述中,相同的模块使用相同的附图标记表示。在相同的附图标记的情况下,它们的名称和功能也相同。因此,将不重复其详细描述。
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及具体实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,而不构成对本发明的限制。
图1示出了本发明实施例提供的基于深度学习的预警制动系统流程示意图。
如图1所示,本发明实施例提供的系统流程示意图包括感知层、决策层、应用层。
感知层即前端可见光相机,决策层即数据处理模块,应用层即制动控制单元。
图2示出了本发明实施例提供的基于深度学习的预警制动方法网络流程示意图。
如图2所示,本发明实施例提供的基于深度学习的预警制动方法网络流程示意图。
基于深度学习的预警制动方法包括如下步骤:
S1、可见光相机用于采集图像数据并标注,建立图像数据与车辆位置和距离信息映射关系并生成数据集;包括如下子步骤:
S11、在车辆的前方装备有可见光相机,根据天气条件、前方车辆距离和车辆类型的不同,设置不同的成像条件来采集图像数据,满足数据集的多样性要求;
S12、在车辆行驶过程中,对采集的图像数据进行标注;
S13、建立图像数据与车辆位置和距离的映射关系并生成数据集;
S14、将图像数据和对应的车辆位置信息与车辆的距离信息作为样本送入数据集,生成带有标注信息的200条图像数据,满足天气、距离和车辆类型等多样性的需求。
S15、最后通过图像数据集扩充技术,对200条数据进行翻转、平移和压缩,扩充生成10倍的数据作为最终的数据集。
可见光相机采用海康威视的USB相机E12,成像分辨率为1920x1080的RGB三通道图像,可见光相机负责对车辆前方的图像进行采集,然后将前方相机采集的图像数据送入下一步神经网络中进行特征提取与深度估计。
S2、送入数据处理模块进行处理,构建深度估计残差网络模型,对数据集进行卷积操作提取相应特征进行组合学习,得到图像的特征图模型;对深度估计残差网络模型进行训练,得到最终的网络权重;包括如下子步骤:
S21、本发明采用的深度估计网络骨架网络为残差网络,网络架构如表1所示。
表1网络结构
将416x416大小的图像输入网络,经过步长为2,大小为7x7x64的卷积核进行卷积,得出208x208的特征图像;然后再经过步长为2的3x3大小的池化层和3个Conv2_x的卷积核,得到104x104的输出特征图;然后再经过4个Conv3_x的卷积核,得到52x52的输出特征图;然后再经过23个Conv4_x的卷积核,得到26x26的输出特征图;然后再经过3个Conv5_x的卷积核,得到13x13的输出特征图。
S22、对网络模型进行训练,得到最终的网络权重。
采用的损失函数如下:
损失函数的建立包括4个步骤:
S221、预测的矩形框对角线长度的平方和损失;
S222、预测框中心的坐标和实际目标中心坐标的平方和损失;通过比较预测框中心点和图像的中心点(x
S223、表示像素深度的平方和损失,通过将深度估计损失引入到损失函数中进行迭代优化,使得网络最终能够预测当前像素所对应的深度信息;
S224、表示置信度的交叉熵损失,通过在损失函数中引入置信度损失,来迭代优化最终目标的置信度。
参数
参数x,y,w,h分别表示预测框的横纵中心坐标(x,y)和目标框的长宽(w,h),取值经过归一化,范围在0~1之间;参数x
S23、使用梯度下降策略,迭代优化损失函数的值,使损失函数不断下降到最优点,保存好当前的网络权重参数;在进行下次预测时,带入到当前网络权重参数中得出新的x、y、diagonal、D(x,y)、P等参数。
S3、初始化网络权重参数,将原始图像数据送入到网络中,得出目标的位置和距离信息,制定相应的制动等级,送入应用层执行响应策略;包括如下子步骤:
S31、生成目标的位置信息(横坐标x,纵坐标y,宽w,高h)和每一个像素点对应的深度信息D(x,y);
S32、目标的距离Dst(x,y)通过计算目标区域内的像素深度信息均值得到,计算方法如下:
参数x
S33、对于图像中存在的多个车辆目标,通过以下流程筛选出前车辆目标:
S331、初始化中心距离变量dmax,目标编号num max;
S332、将网络生成的所有目标遍历深度估计;
S333、当目标的置信度大于0.9,计算目标中心和图像中心的距离dcentre和目标编号num;
S334、若计算目标中心和图像中心的距离dcentre大于初始化中心距离变量dmax;dmax=dcentre,num max=num;
S335、遍历结束;
S336、取num max编号所对应的目标为前车辆目标。
S34、根据当前车辆速度、前车辆距离与制动等级的映射表,如表2所示,得出相应的制动等级,并将相应的制动命令传递至后端制动控制系统,制动控制系统作出制动的动作,使车辆停止。
表2车速距离与制动等级关系映射表
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
以上本发明的具体实施方式,并不构成对本发明保护范围的限定。任何根据本发明的技术构思所作出的各种其他相应的改变与变形,均应包含在本发明权利要求的保护范围内。