一种基于深度图和语义学习的专利价值评估方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明属于专利评估技术领域,特别涉及一种基于深度图和语义学习的专利价值评估方法。
背景技术
“高价值专利”是业界高度关注热词,培育高价值专利已经成为创新驱动高质量发展的时代共识,国家知识产权主管部门更是将培育高价值专利、提升专利质量作为重点工作之一。为此,如何评估专利价值、识别高价值专利就成为当前迫切需要解决的关键问题。然而,随着知识产权战略的深入推进和实施,我国专利数量实现了大幅增长,传统的专利价值评估方法逐渐无法满足对大量待评估专利进行价值评估的需求。因此,构建适用于大数据背景的专利价值评估模型,从数量众多的专利中快速有效识地别出高价值专利已经成为提升创新发展质量的关键问题。
目前的有关于专利价值的研究主要从单指标探究专利价值影响因素,比如“HallB,Trajtenberg M.Market value and patent citations[J].The Rand Journal ofEconomics,2005,36(1):16–38”、“Lerner J,The importance of patent scope:anempirical analysis[J].The Rand Journal ofEconomics,1994,25,319-333.”、“HarhoffD,Scherer F M,Vopel K.Citations,family size,opposition and the valueof patentrights[J].Research Policy,2003,32(8).”和“LanjouwJ O,SchankermanM.Patent quality and research productivity:measuringinnovationwith multipleindicators[J].Economic Journal,2004,114(495):441–465.”,又或者是从多指标评估专利价值展开,比如“万小丽,朱雪忠.专利价值的评估指标体系及模糊综合评价[J].科研管理,2008(02):185-191.”、“宋河发,穆荣平,陈芳.专利质量及其测度方法与测度指标体系研究[J].科学学与科学技术管理,2010,31(04):21-27.”和“郭磊,蔡虹,张越.专利战略化情境下的产业核心专利态势分析[J].科学学研究,2016,34(11):1663-1671+1757.”)。如Hall等最早提出利用专利被引频次反应专利的价值,Lerner研究发现专利涉及的技术范围对专利价值有显著影响,但这些方法都难以客观反映专利的经济价值;其次,现存的许多研究都集中在依靠专利指标来评估专利的价值,例如专利被引证数、专利诉讼等,万小丽等通过层次分析和模糊综合评价的方法建立了包含创新度、技术含量等17个指标在内的指标体系,通过定性与定量相结合方式为专利价值的评估提出一种新思路;郭磊等研究发现权利宽度、技术范围及自引行为与专利价值间有显著的正向关系,但是可以发现,研究中的各项指标都是专利的特征信息,模型中涉及的指标及指标权重各不相同,学术界对于指标的选取未达成共识。同时,专利的文本信息是反映专利新颖性的重要因素,而这种语义新颖性是现有研究中尚未考虑的。因此需要研究人员提出一种能够有效融合多指标,同时能够从语义角度衡量专利价值的专利价值评估方法。
发明内容
本发明的针对现有研究的不足,结合专利的特点提出专利价值评估方法。首先对专利特征进行筛选,然后结合深度语义学习提出衡量专利的语义新颖性。同时,为了有效融合外部指标和语义信息,基于互信息最大化学习节点的表示,保留节点的局部信息和网络的全局信息,最后结合XGBoost算法估算出专利的价值。本发明首次使用语义学习和深度图学习提供了一种面向大数据的专利经济价值评估的方法。
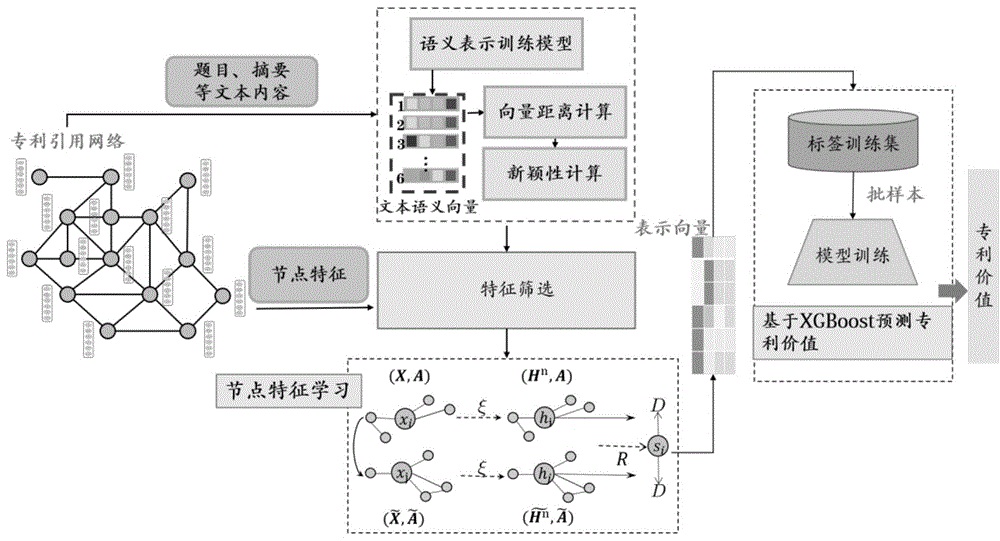
本发明的技术方案:一种基于深度图和语义学习的专利价值评估方法,通过已有的专利数据集建立有效融合多指标和语义新颖性的综合评估值综合评估模型,将综合评估模型运用于待评估专利数据集预测专利的价值。包括以下步骤:
步骤1.获取专利的属性特征与专利之间的引用关系,构建专利引用网络;
步骤2.以转让专利作为高经济价值专利的标准,确定专利价值评估的海选指标及指标所属准则层;
构建专利价值评估的海选指标专利价值评估的海选指标所属的准则层包括:技术类指标、被引证类指标、IPC类指标、国际化类指标、时间类指标、权利类指标和专利权人指标;海选指标的构建见表1;
表1准则层与海选指标体系表
步骤3.基于K-S方法对专利价值评估的海选指标进行筛选并构建用于专利价值评估的指标体系;
步骤3.1、专利价值评估的海选指标数据标准化处理;
数据标准化处理为采用最大值-最小值标准化方法,对专利价值评估的海选指标的样本数据进行处理,消除量纲的影响;
步骤3.2、计算单个指标D值;
通过计算已有的专利数据集中,各专利价值评估的海选指标对应的转让专利与未转让专利累计频率差值的最大值,得出专利价值评估的海选指标的K-S检验统计量D值;
步骤3.3、计算同一准则层中指标相关系数;
计算同一准则层内任意两个指标间的相关系数,确定专利价值评估的海选指标中反映信息重复的指标对,在相关系数大于0.7的指标对中删除D值小的指标,完成专利价值评估的海选指标的第一次筛选;剩余的K个专利价值评估的海选指标组成指标体系;
步骤3.4、计算专利经济价值得分;
根据K-S检验统计量D值对剩余专利价值评估的海选指标进行赋权,确保D值越大的指标,权重越大;通过线性加权的方式计算专利的经济价值得分;利用公式(1)计算专利价值评估的海选指标权重:
利用公式(2)计算专利经济价值得分:
其中,w
步骤3.5、计算指标体系的K-S检验统计量D值;
类比单个价值评估的海选指标D值的计算,计算出由指标体系得出的专利经济价值得分的K-S检验统计量D值;
步骤3.6、在计算出第一次筛选后剩余K个专利价值评估的海选指标组成的指标体系D值后,依次删除一个专利价值评估的海选指标,计算剩余K-1个专利价值评估的海选指标组合中D值的最大值,对比删除该专利价值评估的海选指标前后D值的变化,当删除该专利价值评估的海选指标后,剩余指标组合D值比删除前变大,则删除该专利价值评估的海选指标;
步骤3.7、循环步骤3.6直至删除任意一个专利价值评估的海选指标后,剩余指标组合D值均小于删除该专利价值评估的海选指标前的D值,此时停止删除专利价值评估的海选指标,完成专利价值评估的海选指标的第二次筛选;剩下的专利价值评估的海选指标为最优专利价值评估的海选指标组合;
步骤4.计算专利的语义新颖性,包括以下步骤;
步骤4.1、根据专利的发明名称与摘要建立语料库集合T={t
步骤4.2、根据段落向量矩阵和单词向量矩阵中的唯一列向量,也就是文本段落和单词的平均值预测文本段落t
其中,M是所有训练单词的个数,v
其中,N
Pr=Ua(w
其中,U和b是softmax参数,a是由w
步骤4.3、计算专利的文本段落表征向量与它所引用专利文本段落表征向量之间的欧几里得距离:
步骤4.4、汇总专利引用网络中所有专利引用对|R|之间的欧几里得距离并排名,计算专利的语义新颖性S
步骤5、基于步骤3获取的最优专利价值评估的海选指标组合与步骤4计算的语义新颖性,生成节点特征矩阵
步骤5.1、输入节点特征矩阵X,通过图卷积网络ε集成目标节点的邻域信息获取正样本中节点局部表示;信息集成过程为:
其中,
步骤5.2、使用函数
步骤5.3、通过传递函数
其中,N代表正样本数量;
步骤5.4、使用判别器
/>
步骤5.5、最小化最终的损失函数L
其中,N
步骤6、专利价值预测;将专利节点最终表示输入到机器学习XGBoost模型中预测专利的价值,获得评分预测结果
其中,f
本发明的有益效果:本发明提供了一种基于深度图和语义学习的专利价值评估方法。在指标筛选过程中,将专利转让与专利价值评估指标体系的构建结合起来,为特征选择提供了一个客观公允、操作性强的评估方法。其次,通过文本语义学习计算专利的新颖性,从语义角度衡量专利价值。进一步利用深度图学习,最大化局部表示和全局表示之间的信息集成节点特征表示,对专利价值进行评估。本方法突破了传统方法在专利价值评估问题中的不足,同时引入专利文本新颖性衡量专利的价值。实验结果表明提出的方法具有较高的准确性和可靠性。本发明提供了一种专利价值评估新方法,同时为专利价值的研究提供了一种新的解决方案。
附图说明
图1为本发明的基于深度图和语义学习的专利价值评估方法流程图。
图2为指标筛选流程图。
具体实施方式
以下结合附图和技术方案,进一步说明本发明的具体实施方式。
本实施例以公开时间大于5年的2209件生物制药领域专利作为例子,使用公开时间大于5年的指标及准则层进行专利价值评估模型构建及模型有效性验证。选取1473件专利样本用于构建价值评估模型,736件专利样本用于专利价值评估及评估模型有效性的验证,本发明技术方案实施步骤如下:
1.根据真实的专利发表情况以及引用信息,构建专利引用网络。
2.根据公开时间不同专利指标的特点,选取海选指标并构建准则层。
3.通过最大值-最小值标准化方法,对专利样本的指标数据进行标准化处理,消除量纲的影响。
4.单个指标的K-S检验统计量D值计算。
通过海选指标D值的大小来衡量指标对专利转让状态的区分能力,指标的D值越大,表明转让专利与未转让专利在该指标上的差异程度越大,即通过该指标越能识别出专利是否转让的状态。下面以指标“说明书页数”为例,说明单个指标D值的计算步骤。为方便理解,假设“说明书页数”标准化数值为1,0.5,0。
(4.1)每个“说明书页数”指标数值都对应着一个或几个专利,这些指标数值相同的专利构成一个专利群,将这些专利群按照“说明书页数”指标的数值大小降序排列。列入表2第2行,表2第1行为专利群的编号。
(4.2)计算各专利群中的转让专利个数和未转让专利的个数,分别列入表2第3行和第4行。
(4.3)计算各累加专利群中转让专利个数和未转让专利的个数。
指标数值最高的专利群作为第一个累加专利群,然后每次累加下一个指标数值较低的专利群,即前两个专利群构成第二个累加专利群,前三个专利群构成第三个累加专利群。计算各个累加专利群中转让专利个数和未转让专利的个数,并分别列入表2的第5行和第6行。
(4.4)计算各累加专利群中转让专利累计频率和未转让专利累计频率。
表2第5行中累加的转让专利个数分别除以表2第5行最后一列累加的转让专利总数,得到转让专利的累计频率,列入表2第7行。同理,累加的未转让专利个数除以累加的未转让专利总数,得到未转让专利的累积频率,列入表2第8行。
(4.5)计算各个累加专利群中,转让专利累计频率和未转让专利累计频率的差值d,d=|转让专利累计频率-未转让专利累计频率|,分别列入表2第9行中。
(4.6)确定单个指标的K-S检验统计量D值。
K-S检验统计量D值是转让专利累计频率与为转让专利累计频率之差d的最大值,即D=max(d),得到的D值列入表2第10行中。
表2 K-S检验统计量D值的计算
5.删除反映信息重复的指标,进行指标的第一次筛选
计算同一准则层内任意两个指标间的相关系数,在相关系数大于0.7的指标对中删除D值小的指标,即避免指标体系的信息冗余、又避免了误删区分转让能力强的指标。指标q与指标j间相关系数计算公式为:
其中,r
通过相关分析,在专利公开时间大于5年的指标体系中,共删除“引证本国专利数”、“引证外国专利数”等9个指标,剩余20个指标。
6.基于D值对指标赋权
根据“指标的转让区分能力K-S检验统计量D值越大,指标权重就越大”的思路对指标进行赋权。赋权公式为:
其中,w
7.计算专利价值得分
通过线性加权的方式计算专利的经济价值得分,加权公式如下:
其中,Z为专利价值得分;w
8.计算专利价值得分的D值,对指标体系进行第二次筛选。
(8.1)计算第一次筛选后,剩余20个指标组成的评级指标体系的D
根据单个指标D值的计算方法,计算20个指标组成体系的专利价值得分的D
(8.2)确定最大值
在得出20个指标D
(8.3)筛选出专利转让区分能力D值强的指标体系。
当D
(8.4)重复步骤(2)和步骤(3),继续删除指标,直至当
说明在k个指标中任意去掉一个指标后,剩余k-1个指标组成的指标体系对专利转让的区分能力变弱,此时则应保留k个指标的指标体系,终止指标筛选。
第二次指标筛选后,在专利公开时间大于5年的指标体系中,共删除“IPC小类数”、“附图个数”等9个指标,剩余11个指标,剩余指标组成的指标体系即为专利转让区分能力强的指标体系。
9.计算专利的语义新颖性。
(9.1)根据专利的发明名称与摘要建立语料库集合T={t
其中M是所有训练单词的个数,v
计算每篇论文输出的对数概率:
Pr=Ua(w
其中,U和b是softmax参数,a是由w
(9.2)计算专利的向量与它所引用专利向量之间的距离:
(9.3)汇总所有引用对之间的距离并排名,计算专利的语义新颖性得分S
10.基于筛选指标与计算的语义新颖性,生成节点特征矩阵
(10.1)输入特征矩阵X,通过图卷积网络ε集成目标节点的邻域信息获取正样本中节点表示:
其中
(10.2)使用函数
(10.3)通过传递函数
其中N代表正样本数量。
(10.4)使用判别器
(10.5)计算最终的损失函数:
其中,N
(10.6)最小化损失函数,生成每个专利节点的表示h
11.专利价值预测。将专利节点表示输入到价值预测模型XGBoost中,获得评分预测结果。对于某个样本i,输入其特征表示h
其中,f
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,本领域的技术人员在本发明的基础上所做的任何非实质性的变化及替换均属于本发明所要求保护的范围,本发明的保护范围以所述权利要求的保护范围为准。
- 基于深度学习的专利价值评估的方法
- 基于深度学习的专利价值评估的方法