一种基于自主探索算法的机器人脑波自适应抓取方法和系统
文献发布时间:2024-04-18 19:59:31
技术领域
本发明涉及环保装置技术领域,尤其涉及一种基于自主探索算法的机器人脑波自适应抓取方法和系统。
背景技术
目前,机器人是一种能够半自主或全自主工作的智能机器,机器人能够通过编程和自动控制来执行诸如作业或移动等任务,机器人一般具有感知、决策、执行等基本特征,可以辅助甚至替代人类完成危险、繁重、复杂的工作,提高工作效率与质量,服务人类生活,扩大或延伸人的活动及能力范围,其中工业机器人中应用最为广泛的就是物件的抓取的;
目前工业机器人抓取时一般按程序输入方式区分有编程输入型和示教输入型两类,编程输入型是将计算机上已编好的作业程序文件,通过RS-232串口或者以太网等通信方式传送到机器人控制柜;
而示教输入型的示教方法有两种:一种是由操作者用手动控制器,将指令信号传给驱动系统,使执行机构按要求的动作顺序和运动轨迹操演一遍;
另一种是由操作者直接领动执行机构,按要求的动作顺序和运动轨迹操演一遍;
在示教过程的同时,工作程序的信息即自动存入程序存储器中在机器人自动工作时,控制系统从程序存储器中检出相应信息,将指令信号传给驱动机构,使执行机构再现示教的各种动作,因此示教输入程序的工业机器人称为示教再现型工业机器人;
但是现有的机器人抓取时往往无法在未知环境中自主地寻找、识别和抓取物体,并且无法在无需人工干预或预先给定目标物体的信息下完成抓取工作,其次,无法对环境进行实时感知、对物体的智能分析和对抓取动作的自适应控制,并且无法识别和分析物体的高层特征,使其无法根据物体的特征和抓取价值自动生产一个抓取动作序列,实现不同物体的精准性抓取动作。
因此,如何提供一种基于自主探索算法的机器人脑波自适应抓取方法和系统是本领域技术人员亟需解决的问题。
发明内容
本发明的一个目的在于提出一种基于自主探索算法的机器人脑波自适应抓取方法和系统,本发明能够使机器人在未知环境中自主地寻找、识别和抓取物体,而无需人工干预或预先给定目标物体的信息,且可结合机器人的视觉和触觉反馈,实现了对环境的实时感知、对物体的智能分析和对抓取动作的自适应控制,除此之外,通过特征提取器能够从图像中提取物体的高层特征,从而实现物体的识别和分析,随后动作生成器可根据分析结果生成一个抓取动作的序列,从而实现抓取动作的生成和控制。
根据本发明实施例的一种基于自主探索算法的机器人脑波自适应抓取方法,包括以下步骤:
S1、将自主探索算法与机器人进行结合,使其机器人能够通过视觉和触觉感知未知环境,决策并执行探索动作,寻找潜在的抓取目标;
S2、通过基于深度神经网络的物体识别和分析模块,对感知到的物体进行特征提取,确定物体的类别、位置、大小、姿态和颜色,并计算抓取价值;
S3、利用基于深度神经网络的抓取动作生成和控制模块可根据物体的特征和抓取价值生成合适的抓取动作,具体包括抓取位置、方向和力度参数,实时根据触觉反馈动态调整抓取动作,以适应不同物体和环境的变化;
S4、通过机械臂和机械手执行生成的抓取动作,视觉传感器实时感知环境和物体,触觉传感器获取抓取过程中的压力信息,脑波采集分析机为整个系统提供高层次的脑波信号分析,以实现机器人的自主探索和自适应抓取;
所述S1中自主探索算法基于深度强化学习策略,且该策略能够根据机器人的视觉和触觉反馈,自动地生成和评估候选的抓取目标和抓取动作,实现机器人的自主抓取,所述深度强化学习策略基于深度神经网络的价值函数,该价值函数能够估计每个状态动作的长期回报,并指导机器人的探索和抓取,该价值函数的更新公式为:
其中,s
所述深度强化学习策略使用了一种基于奖励函数的探索机制,所述奖励函数的探索机制机制能够根据物体的抓取价值和抓取的难易程度给出不同的奖励,从而激励机器人探索更有价值和更有挑战性的物体,提高机器人的探索效率和质量,该奖励函数的定义为:
r
其中,v
所述深度强化学习策略使用了一种基于元学习的优化方法,所述元学习的优化方法能够使机器人在不同的环境中,快速地适应和学习,从而实现了机器人的在线学习和优化,该算法的更新公式为:
其中,θ表示机器人的参数,θ
优选的,所述S2中物体识别和分析模块的输入端为机器人在时刻t的视觉传感器获取的图像v
其中,v
优选的,所述S2中物体识别和分析模块基于深度神经网络的方法,所述深度神经网络的方法从机器人的视觉输入中提取物体的特征,如形状、大小、姿态和颜色,并根据物体的特征和抓取的难易程度,给出物体的抓取价值,从而指导机器人的探索和抓取,该方法是一种基于卷积神经网络的特征提取器,且该特征提取器能够从图像中提取物体的高层特征,从而实现物体的识别和分析,该特征提取器的具体结构为:f(x)=W
其中,x表示图像的输入,f(x)表示图像的输出,W
优选的,所述S3中抓取动作生成和控制模块基于深度神经网络的方法,所述深度神经网络的方法根据物体的特征和抓取价值生成合适的抓取动作,并根据机器人的触觉反馈,实时地调整抓取动作,实现机器人的自适应抓取,该方法是
一种基于循环神经网络的动作生成器,该动作生成器能够根据物体的特征和抓取价值,生成一个抓取动作的序列,从而实现抓取动作的生成和控制,该动作生成
器的具体结构为:
h
y
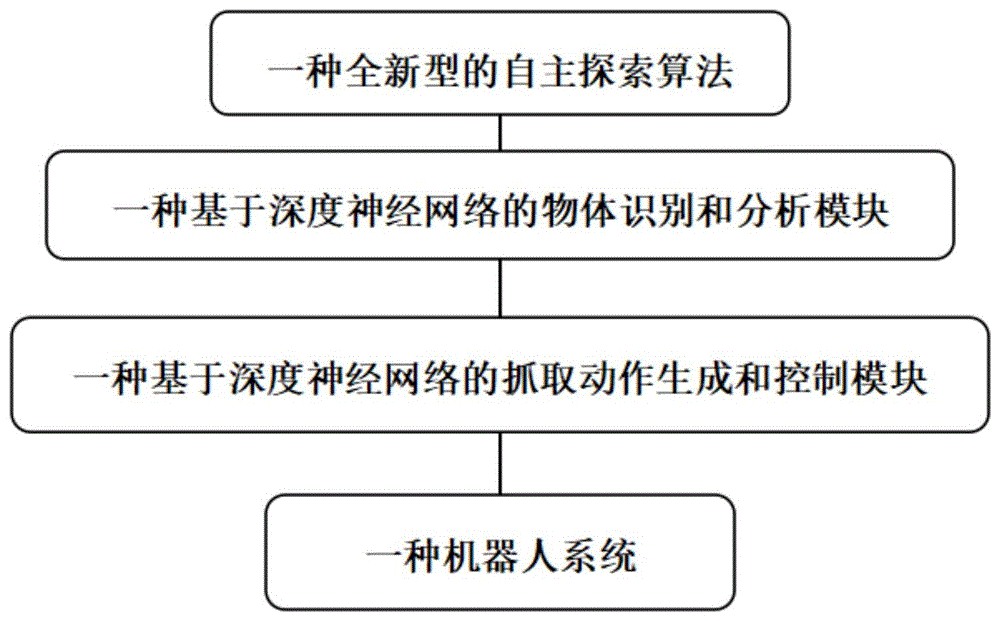
其中,x
一种基于自主探索算法的机器人脑波自适应抓取系统,包括:基于深度神经网络的物体识别和分析模块、基于深度神经网络的抓取动作生成和控制模块以及机器人。
优选的,所述机器人包括机械臂、机械手、视觉传感器、触觉传感器和计算机,所述机械臂和机械手用于执行抓取动作,所述视觉传感器和触觉传感器用于获取环境和物体的信息,所述计算机用于运行自主探索算法、物体识别和分析模
块以及抓取动作生成和控制模块
优选的,所述机械臂由若干个关节和连杆组成,且能够在空间中移动和旋转
达到不同的位置和姿态,所述机械臂的运动学和动力学由以下公式描述:
q=J(q)x
τ=M(q)q+C(q,q)q+G(q)τ=M(q)q+C(q,q)q+G(q)
其中,q表示机械臂的关节角,x表示机械臂的末端位置,j表示机械臂的雅可比矩阵,τ表示机械臂的关节力矩,M表示机械臂的惯性矩阵,C表示机械臂的科氏力和离心力,G表示机械臂的重力。
优选的,所述机械手由若干个指节和指尖组成,且能够在机械臂的末端进行开合和握持从而抓取不同的物体,所述机械手的运动学和动力学由以下公式描述:
其中,τ表示指节力矩,M表示机械手的惯性矩阵,C表示机械手的科氏力和离心力,G表示机械手的重力,F表示机械手的摩擦力。
优选的,所述视觉传感器由多个摄像头组成,能够在不同的角度和距离拍摄环境和物体的图像从而获取环境和物体的信息,所述视觉传感器的工作原理由以下公式描述:x=K[R∣t]X;
其中,x表示图像坐标,X表示世界坐标,K表示内参矩阵,R表示旋转矩阵,t表示平移向量。
优选的,所述触觉传感器由多个压力传感器组成,且能够在机械手的指尖或指节测量物体的压力,从而获取物体的信息,所述触觉传感器的工作原理由以下公式描述:p=kf;
其中,p表示压力,f表示力,k表示灵敏度。
本发明的有益效果是:
1、本发明提出了一种基于全新型自主探索算法的机器人自适应抓取方法和系统,该方法和系统能够使机器人在未知环境中自主地寻找、识别和抓取物体,而无需人工干预或预先给定目标物体的信息,这样,机器人可以更好地适应复杂和变化的环境,提高抓取的成功率和效率,扩展抓取的范围和类型,增强抓取的智能性和灵活性。
2.本发明利用深度强化学习和深度神经网络,结合机器人的视觉和触觉反馈,实现了对环境的实时感知、对物体的智能分析和对抓取动作的自适应控制,这样,机器人可以更好地利用自身的感知和学习能力,提高抓取的准确性和鲁棒性,减少抓取的数据和计算资源的需求,缩短抓取的训练时间。
3.本发明采用了一种基于卷积神经网络的特征提取器,该特征提取器能够从图像中提取物体的高层特征,从而实现物体的识别和分析,这样,机器人可以更好地处理图像的噪声、模糊、遮挡、变形等问题,提高物体识别和分析的质量和可用性。
4.本发明采用了一种基于循环神经网络的动作生成器,该动作生成器能够根据物体的特征和抓取价值,生成一个抓取动作的序列,从而实现抓取动作的生成和控制,这样,机器人可以更好地根据物体的特点和抓取的要求,动态地生成和调整抓取动作,提高抓取的效率和灵活性。
5.本发明包括了一个机械臂,一个机械手,一个视觉传感器,一个触觉传感器,以及一个脑波采集分析机,这些组成部分能够协同工作,实现机器人的自主探索和自适应抓取,这样,机器人可以更好地利用自身的硬件和软件资源,提高抓取的性能和稳定性,降低抓取的成本和风险。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
图1为本发明提出的一种基于自主探索算法的机器人脑波自适应抓取方法和系统的模块图;
图2为本发明提出的一种基于自主探索算法的机器人脑波自适应抓取方法和系统的装置实现模块图。
具体实施方式
现在结合附图对本发明作进一步详细的说明。这些附图均为简化的示意图,仅以示意方式说明本发明的基本结构,因此其仅显示与本发明有关的构成。
参考图1-2,一种基于自主探索算法的机器人脑波自适应抓取方法,包括以下步骤:
S1、将自主探索算法与机器人进行结合,使其机器人能够通过视觉和触觉感知未知环境,决策并执行探索动作,寻找潜在的抓取目标;
具体的,该算法能够使机器人在未知环境中自主地寻找、识别和抓取物体,而无需人工干预或预先给定目标物体的信息。
该算法利用深度强化学习和深度神经网络,结合机器人的视觉和触觉反馈,实现了对环境的实时感知、对物体的智能分析和对抓取动作的自适应控制。
该算法的实现方法用公式进行详细解释如下:
该算法的总体框架为:
a
s
θ←θ+Δθ
其中,s
该算法的状态s
s
其中,v
该算法的动作a
a
其中,e
该算法的奖励r
r
其中,r
该算法的参数更新Δθ由机器人的优化方法给出,即:
其中,J(θ)表示机器人的目标函数,
J(θ)由机器人的价值函数给出,
J(θ)和
需要注意的是,自主探索算法采用了一种基于深度强化学习的策略,该策略能够根据机器人的视觉和触觉反馈,自动地生成和评估候选的抓取目标和抓取动作,从而实现了机器人的自主抓取。
该策略的核心是一种基于深度神经网络的价值函数,该价值函数能够估计每个状态动作的长期回报,从而指导机器人的探索和抓取。
该价值函数的更新公式为:
其中,s
该公式能够使机器人不断地更新自己的价值函数,从而提高自己的抓取能力。
除此之外,所述深度强化学习策略使用了一种基于奖励函数的探索机制,所述奖励函数的探索机制机制能够根据物体的抓取价值和抓取的难易程度给出不同的奖励,从而激励机器人探索更有价值和更有挑战性的物体,提高机器人的探索效率和质量,该奖励函数的定义为:
r
其中,v
所述深度强化学习策略使用了一种基于元学习的优化方法,所述元学习的优化方法能够使机器人在不同的环境中,快速地适应和学习,从而实现了机器人的在线学习和优化,该算法的更新公式为:
其中,θ表示机器人的参数,θ
参考图1-2,S2、通过基于深度神经网络的物体识别和分析模块,对感知到的物体进行特征提取,确定物体的类别、位置、大小、姿态和颜色,并计算抓取价值;
具体的,基于深度神经网络的物体识别和分析模块能够从机器人的视觉输入中提取物体的特征,如形状、大小、姿态、颜色等,并根据物体的特征和抓取的难易程度,给出物体的抓取价值,从而指导机器人的探索和抓取。
该模块的输入为机器人的视觉反债v
该图像可以是彩色的或灰度的,可以是单目的或双目的,可以是静态的或动态的,可以是全景的或局部的,可以是高分辩率的或低分辩率的,等等。该图像的大小为H×W×C,其中H表示图像的高度,W表示图像的宽度,C表示图像的通道数。该图像的格式为一个三维的张量,即:
其中,v
该像素值可以是一个整数或一个浮点数,取决于图像的类型和范围。
该像素值可以表示图像的亮度、颜色、深度、光流、分割、特征等信息。
该图像的输入可以通过机器人的视觉传感器直接获取,也可以通过一些预处理的方法进行转换或增强,以提高图像的质量和可用性。
该模块的输出为物体的特征和抓取价值f
该结果包括物体的类别、位置、大小、姿态、颜色等特征,以及物体的抓取价值,即物体对机器人的探索和抓取的重要性和难度。
该结果的大小为N×M,其中N表示物体的数量,M表示物体的特征和抓取价值的维度。
该结果的格式为一个二维的矩阵,即:
其中,f
该结果的输出可以直接用于机器人的探索和抓取的决策,也可以通过一些后处理的方法进行篮选或排序,以提高结果的可靠性和有效性。
该模块的实现方法为一种基于深度神经网络的方法,该方法能够从机器人的视觉输入中提取物体的特征,如形状、大小、姿态、颜色等,并根据物体的特征和抓取的难易程度,给出物体的抓取价值,从而指导机器人的探索和抓取。
该方法的核心是一种基于卷积神经网络的特征提取器,该特征提取器能够从图像中提取物体的高层特征,从而实现物体的识别和分析。
该特征提取器的结构为:
f
其中,v
该结构能够使机器人利用大量的标注数据,提高物体识别和分析的准确性和鲁棒性。
参考图1-2,S3、利用基于深度神经网络的抓取动作生成和控制模块可根据物体的特征和抓取价值生成合适的抓取动作,具体包括抓取位置、方向和力度参数,实时根据触觉反馈动态调整抓取动作,以适应不同物体和环境的变化;
具体的,基于深度神经网络的抓取动作生成和控制模块能够根据物体的特征和抓取价值,生成合适的抓取动作,如抓取位置、方向、力度等,并根据机器人的触觉反馈,实时地调整抓取动作,从而实现了机器人的自适应抓取。
该模块的输入为物体的待征和抓取份值f
该结果包括物体的类别、位置、大小、姿态、颜色等特征,以及物体的抓取价值,即物体对机器人的探索和抓取的重要性和难度。
该结果的大小为N×M,其中N表示物体的数量,M表示物体的特征和抓取价值的维度。
该结果的格式为一个二维的矩阵,即:
其中,f
该特征或抓取价值可以是一个整数或一个浮点数,取决于特征或抓取价值的类型和范围。
该特征或抓取价值可以表示物体的类别、位置、大小、姿态、颜色等特征,以及物体的抓取价值,即物体对机器人的探索和抓取的重要性和难度。
该结果的输入可以由物体识别和分析模块直接给出,也可以通过一些后处理的方法进行篮选或排序,以提高结果的可靠性和有效性。
该模块的输出为抓取动作g
该动作包括抓取位置、方向、力度等参数,以及抓取反馈,即抓取是否成功、物体是否稳定等信息。
该动作的大小为L×K,其中L表示抓取动作的长度,K表示抓取动作的维度。
该动作的格式为一个二维的矩阵,即:
其中,g
该参数或反馈可以是一个整数或一个浮点数,取决于参数或反馈的类型和范围。
该参数或反馈可以表示抓取位置、方向、力度等参数,以及抓取反债,即抓取是否成功、物体是否稳定等信息。
该动作的输出可以由机器人的机械臂和机械手执行,也可以由机器人的触觉传感器获取,以实现机器人的自适应抓取。
该模块的实现方法为一种基于深度神经网络的方法。
该方法能够根据物体的特征和抓取价值,生成合适的抓取动作,如抓取位置、方向、力度等,并根据机器人的触觉反馈,实时地调整抓取动作,从而实现了机器人的自适应抓取。
该方法的核心是一种基于循环神经网络的动作生成器,该动作生成器能够根据物体的特征和抓取价值,生成一个抓取动作的序列,从而实现抓取动作的生成和控制。
该动作生成器的结构为:
h
y
其中,x
参考图1-2,S4、通过机械臂和机械手执行生成的抓取动作,视觉传感器实时感知环境和物体,触觉传感器获取抓取过程中的压力信息,脑波采集分析机为整个系统提供高层次的脑波信号分析,以实现机器人的自主探索和自适应抓取;
一种基于自主探索算法的机器人脑波自适应抓取系统,包括:基于深度神经网络的物体识别和分析模块、基于深度神经网络的抓取动作生成和控制模块以及机器人。
其中,所述机器人包括机械臂、机械手、视觉传感器、触觉传感器和计算机,所述机械臂和机械手用于执行抓取动作,所述视觉传感器和触觉传感器用于获取环境和物体的信息,所述计算机用于运行自主探索算法、物体识别和分析模块以及抓取动作生成和控制模块。
具体的,机械臂由若干个关节和连杆组成,能够在空间中移动和旋转,以达到不同的位置和姿态。
该机械臂的运动学和动力学由以下公式描述:
q=J(q)x
τ=M(q)q+C(q,q)q+G(q)
其中,q表示机械臂的关节角,x表示机械臂的末端位置,j表示机械臂的雅可比矩阵,τ表示机械臂的关节力矩,M表示机械臂的惯性矩阵,C表示机械臂的科氏力和离心力,G表示机械臂的重力。
该公式能够使机械暨根据探索动作和抓取动作,执行相应的运动,以实现机器人的自主探索和自适应抓取。
机械手由若干个指节和指尖组成,能够在机械臂的末端进行开合和握持,以抓取不同的物体。
该机械手的运动学和动力学由以下公式描述:
τ表示指节力矩,M表示机械手的惯性矩阵,C表示机械手的科氏力和离心力,G表示机械手的重力,F表示机械手的摩擦力。
该公式能够使机械手根据抓取动作,执行相应的开合和握持,以实现机器人的自适应抓取。
视觉传感器由一个或多个摄像头组成,能够在不同的角度和距离,拍摄环境和物体的图像,以获取环境和物体的信息。该视觉传感器的工作原理由以下公式描述:
x=K[R∣t]X
其中,x表示图像坐标,X表示世界坐标,K表示内参矩阵,R表示旋转矩阵,t表示平移向量。该公式能够使视觉传感器根据摄像头的位置和姿态,将环境和物体的三维坐标,转换为图像的二维坐标,以实现对环境和物体的视觉感知。
力,从而获取物体的信息,所述触觉传感器的工作原理由以下公式描述:p=kf;
其中,p表示压力,f表示力,k表示灵敏度。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。