一种基于鼾声的实时呼吸暂停及低通气预测方法
文献发布时间:2023-06-19 12:21:13
技术领域
本发明涉及预测方法技术领域,特别涉及一种基于鼾声的实时呼吸暂停及低通气预测方法。
背景技术
阻塞性睡眠呼吸暂停低通气综合征(obstructive sleep apnoea hypopnoea,OSAHS)是指患者在睡眠过程中上气道塌陷阻塞引起反复呼吸暂停和低通气。该类患者临床表现为睡眠打鼾,憋醒,睡眠结构紊乱,频繁发生血氧饱和度下降,常伴有夜尿增多,晨起头痛,白天嗜睡,记忆力下降,严重者出现认知功能下降,行为异常等。OSAHS是一种全身性疾病,夜间反复发生的呼吸暂停和低通气造成慢性间歇低氧,二氧化碳潴留,引发高血压、心脑血管疾病、Ⅱ型糖尿病等代谢疾病,同时又是猝死、道路交通事故的重要原因,因而是一个严重的社会问题。据数据显示,全球OSAHS的患病人数达到10亿,而中国仍有大量的病人未被诊断。
OSAHS的标准诊断手段为多导睡眠仪(polysomnography,PSG)。该项检查需要在专门的睡眠实验室由睡眠技师整夜值守的情况下完成。通常PSG记录的信号包括脑电图、眼动电图、颏肌电图、下肢肌电图、呼吸气流信号、呼吸努力信号、血氧饱和度、体位、心电图等等。根据呼吸相关信号,可获得患者睡眠时发生呼吸事件的情况,其中呼吸暂停低通气指数(apnoea-hypopnoea index,AHI)为重要的诊断依据。呼吸事件具体包括有阻塞型呼吸暂停、中枢型呼吸暂停、混合型呼吸暂停、低通气、呼吸事件相关微觉醒等。虽然OSAHS在我国是一种常见病,但由于PSG设备组成复杂,监测费用昂贵,且检查时要求严苛,需要专业睡眠技师连接繁琐的线路以及分析整晚多路信号的数据,这使得PSG设备的实用性与普遍性大打折扣,目前只有大、中城市三级医院或部分二级医院可以对本病进行规范的诊断和治疗,致使大量患者得不到及时的诊治,给人民健康造成了极大的危害。
当进行PSG整夜监测时,患者需全身贴满传感器,这极大地削减了患者的舒适程度。同时该项检查存在监测时间和监测精度等诸多条件限制,亦不可能进行长时间段的观测检查。故在居家环境下利用手机和可穿戴设备等进行OSAHS筛查及呼吸事件预测的方法迫在眉睫。一方面得益于当今全民健康意识的提升,另一方面由于各厂商可穿戴设备监测技术的逐步完善,此提案所采用的技术在未来的适用性得到了极大的保障。
虽然阻塞性睡眠呼吸暂停低通气综合征在我国是一种常见病,但需要专业睡眠技师连接繁琐的线路以及分析整晚多路信号的数据,诊断效率低,且现有的诊断准确率低,同时目前研究很少有考虑对呼吸事件进行实时预警和干预的考察。
因此,本发明提供一种基于鼾声的实时呼吸暂停及低通气预测方法,建立基于鼾声和其他睡眠实时指标的呼吸事件预测机制,实时准确地对决策点后呼吸事件的存在性进行预警,并结合特征重要性原则等设计主动干预的方法(如舌下神经刺激、体位干预等),有助于在医工结合领域对于发生呼吸事件前上气道产生的变化进行进一步探索,有助于实时预警干预系统的落实。在全民健康和社会对睡眠问题重视程度不断提升的背景下,对医师在呼吸事件前后上气道变化从而引起的呼吸变化的主观判断进行数据支撑,为后续完整系统的构建打下夯实算法基础。
发明内容
本发明提供一种基于鼾声的实时呼吸暂停及低通气预测方法,用以获得目标对象的鼾声音频和查体数据以及多导睡眠监测数据,基于特征融合的方式将其建模在统一的特征空间并结合特征重要性原则,实时准确地预测呼吸暂停和低通气及其对应的对应概率的出现与否,在呼吸事件发生节点前进行监测并根据检测结果发出相应预警信号,并对所述目标对象主动干预。
本发明提供了一种基于鼾声的实时呼吸暂停及低通气预测方法,包括:
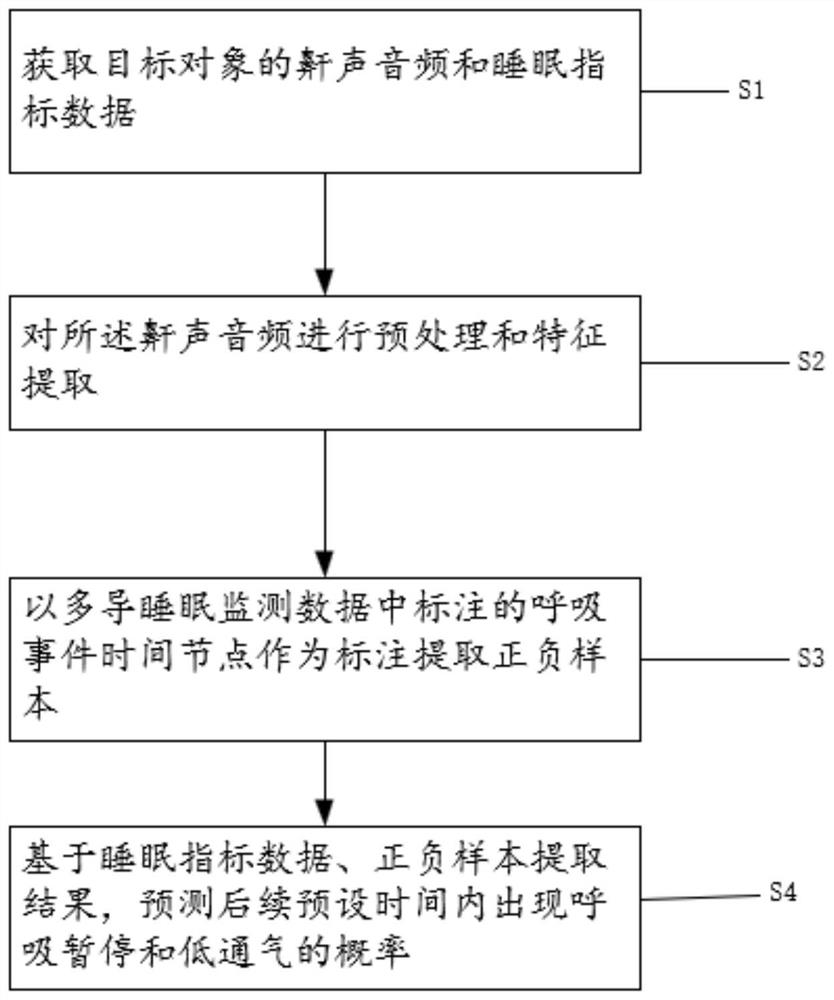
S1:获取目标对象的鼾声音频和睡眠指标数据;
S2:对所述鼾声音频进行预处理和特征提取;
S3:以多导睡眠监测数据中标注的呼吸事件时间节点作为标注提取正负样本;
S4:基于睡眠指标数据、正负样本提取结果,预测后续预设时间内出现呼吸暂停和低通气的概率。
优选的,所述的一种基于鼾声的实时呼吸暂停及低通气预测方法,S2:对所述鼾声音频进行预处理和特征提取,包括:
基于多窗谱减法和维纳滤波对所述鼾声音频进行降噪处理,再进行预加重处理,获得预处理后的鼾声音频信号;
基于预设的硬判别和软判别方式滤除非鼾帧和呼吸帧。
优选的,所述的一种基于鼾声的实时呼吸暂停及低通气预测方法,S2:对所述鼾声音频进行预处理和特征提取,还包括:
计算预处理后的鼾声音频信号的背景信号阈值;
将预处理后的鼾声音频信号划分成多个预设长度的音频段,提取每个音频段的声学特征,基于每个音频段的声学特征,确定鼾声段起始点待选区域和鼾声段终止点待选区域;
将所述起始点待选区域的逆向差分函数最大值对应的帧作为鼾声段的起始点,将所述终止点待选区域的逆向差分函数最大值对应的帧作为鼾声段的终止点;
基于相邻所述起始点和所述终止点确定连续鼾声音频信号中所有鼾声段;
获取所有鼾声帧对应的短时能量和过零率,并判断所述鼾声帧是否满足短时幅值大于最低能量阈值或过零率大于过零率阈值,若是,则判定所述鼾声帧为有效鼾声帧,否则,判定所述鼾声帧为无效鼾声帧;
获取所述连续鼾声音频信号中相邻有效鼾声帧之间的时间间隔,当所述时间间隔小于预设时间阈值,则将相邻有效鼾声帧中的第一有效鼾声帧与第二有效鼾声帧合并,进而获得合并音频;
否则,不合并。
优选的,所述的一种基于鼾声的实时呼吸暂停及低通气预测方法,S2:对所述鼾声音频进行预处理和特征提取,还包括:
将所述合并音频输入深度神经网络提取梅尔频率倒谱系数特征矩阵;
基于第一预设准则确定所述合并音频的突变点,并基于所述突变点将所述合并音频分割成若干个音频样本;
确定每个音频样本中的有效鼾声帧排列次序,所述音频样本都由预设数量个连续的有效鼾声帧构成;
基于梅尔频率倒谱系数特征矩阵将每个音频样本中位于相同排列次序的有效鼾声帧进行聚类,获得所述有效鼾声帧对应的对应的聚类中心;
确定每个聚类中心对应的所述有效鼾声帧的个数,基于对应的个数和聚类中心确定对应的有效鼾声帧的特征数据。
优选的,所述的一种基于鼾声的实时呼吸暂停及低通气预测方法,S3:以多导睡眠监测数据中标注的呼吸事件时间节点作为标注提取正负样本之前,包括:
对所述睡眠指标中的数据和有效鼾声帧的特征数据进行质量评估,获得完整的数据样本;
基于所述多导睡眠监测数据获取目标对象的睡眠分期,基于所述睡眠分期获取所述目标对象未入眠的时间段;
删除未入眠时间段对应的数据样本;
将保留的数据样本和时间轴融合,获得所述全时域覆盖数据样本,并将所述全时域覆盖数据样本基于均值等分区间离散化,获得全时域覆盖离散样本。
优选的,所述的一种基于鼾声的实时呼吸暂停及低通气预测方法,S3:以多导睡眠监测数据中标注的呼吸事件时间节点作为标注提取正负样本,包括:
获取与时间轴对齐的多导睡眠监测数据;
基于多导睡眠监测数据重标注的呼吸时间对应的时间节点作为标注提取预设数量个正预测样本和负预测样本,并提取所述正预测样本和所述负预测样本以及时间节点包含的所述有效鼾声帧的能量分布占比,作为对应的有效鼾声帧的特征向量;
计算所述正预测样本中包含的有效鼾声帧对应的特征向量两两之间的第一距离差值,并计算所述负预测样本中包含的有效鼾声帧对应的特征向量两两之间的第二距离差值,并计算所述正预测样本和所述负预测样本中包含的所有有效鼾声帧对应的特征向量与所述时间节点对应的有效鼾声帧的特征向量之间的第三距离差值;
判断所述第一距离差值和所述第二距离差值是否都小于预设距离阈值且所述第三距离差值大于所述预设距离阈值,若是,则判定所述正预测样本和所述负预测样本满足要求;
否则,当所述第三距离差值小于所述预设距离阈值时,则重新确定呼吸事件,否则,当所述第一距离差值和所述第二距离差值中存在至少一个大于所述预设距离差值时,将大于所述预设距离差值对应的有效鼾声帧作为正预测样本或负预测样本选取边界;
其中,所述正预测样本和所述负预测样本都包含:对应时间段内所述目标对象的人体测量学数据和睡眠信息以及有效鼾声帧的特征数据。
优选的,所述的一种基于鼾声的实时呼吸暂停及低通气预测方法,S4:基于睡眠指标数据、正负样本提取结果,预测后续预设时间内出现呼吸暂停和低通气的概率,还包括:
基于滑动窗口算法对正负预测样本从预设数量个维度进行特征数据提取,获得对应正预测样本或负预测样本的第一特征数据集;
基于典型关联算法将每个正预测样本或负预测样本的所述第一特征数据进行两两融合,获得对应正预测样本或负预测样本的第二特征数据集;
基于典型关联分析原理将高位的两组数据降维至一维,分析所述正预测样本或所述负预测样本的特征组中任意两组特征数据的相关系数;
基于所述相关系数将所述第一特征数据进行分类,获得对应正预测样本或所述负预测样本的分类特征数据集;
其中,所述特征组包括:第一特征数据集和第二特征数据集。
优选的,所述的一种基于鼾声的实时呼吸暂停及低通气预测方法,S获得对应正预测样本或所述负预测样本的分类特征数据集之后,还包括:
将所述正预测样本或所述负预测样本对应的分类特征数据集输入至梯度提升树模型;
基于集成学习模型对所述梯度提升树模型输出的结果进行特征重要性分析,获得多个维度的特征对应的权重值;
基于所述多个维度的特征对应的权重值和预设方法建立逻辑回归模型,获得所述多个维度的特征的分值;
基于所述正预测样本或所述负预测样本对应的分类特征数据集对预设模型库中的多个预设模型进行性能比较,选择出最优特征融合模型;
将所述正预测样本或所述负预测样本对应的分类特征数据集和对应的特征的分值输入至所述最优特征融合模型,获得融合特征;
将所述融合特征输入至所述集成模型,预测后续预设时间内出现呼吸暂停和低通气的概率;
基于预设的概率阈值将所述后续预设时间内出现呼吸暂停和低通气的概率划分为高概率区间、低概率区间。
优选的,所述的一种基于鼾声的实时呼吸暂停及低通气预测方法,预测后续预设时间内出现呼吸暂停和低通气的概率之后,还包括:
设置预警阈值;
当所述后续预设时间内出现呼吸暂停和低通气的概率大于所述预警阈值时,发出预警信号并对目标对象作出干预动作;
否则,保留所述后续预设时间内出现呼吸暂停和低通气的概率。
本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
图1为本发明实施例中一种基于鼾声的实时呼吸暂停及低通气预测方法的工作流程图。
具体实施方式
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
实施例1:
本实施例提供了一种基于鼾声的实时呼吸暂停及低通气预测方法,参考图1,包括:
S1:获取目标对象的鼾声音频和睡眠指标数据;
S2:对所述鼾声音频进行预处理和特征提取;
S3:以多导睡眠监测数据中标注的呼吸事件时间节点作为标注提取正负样本;
S4:基于睡眠指标数据、正负样本提取结果,预测后续预设时间内出现呼吸暂停和低通气的概率。
在本实施例中,所述目标对象的鼾声音频和睡眠指标数据都是实时检测获得的,其中所述睡眠指标数据包括:所述目标对象的多导睡眠监测数据和人体测量学数据和睡眠信息,所述多导睡眠监测数据由多导睡眠监测仪获得,所述鼾声音频由录音设备获取并记录。
上述技术方案的有益效果是:通过实时获取目标对象的鼾声音频和睡眠指标数据,丰富了呼吸事件预测机制的预测数据,使得呼吸事件预测考虑到目标对象的用户本身的情况和睡眠的实时数据的多方面影响,提高了呼吸事件的预测准确率,建立了基于鼾声和其他睡眠实时指标的呼吸事件预测机制,基于特征融合的方式将其建模在统一的特征空间并结合特征重要性原则,客观准确地预测呼吸暂停和低通气及其对应的对应概率的出现与否,能够在呼吸事件发生节点前进行监测并根据检测结果发出相应预警信号且对所述目标对象主动干预,实现了对医师在呼吸事件前后上气道变化从而引起的呼吸变化的主观判断进行数据支撑,为后续完整系统的构建打下夯实算法基础。
实施例2:
在上述实施例1的基础上,本实施例提供了一种基于鼾声的实时呼吸暂停及低通气预测方法,S2:对所述鼾声音频进行预处理和特征提取,包括:
基于多窗谱减法和维纳滤波对所述鼾声音频进行降噪处理,再进行预加重处理,获得预处理后的鼾声音频信号;
基于预设的硬判别和软判别方式滤除非鼾帧和呼吸帧。
在本实施例中:由于处理的音频数据为整夜的鼾声数据,存在大量噪音和干扰信号,故需对其进行多步预处理操作,在提取出的30秒的时间样本切片中采用维纳滤波,使用硬判别和软判别并行的方式进行非鼾声及呼吸帧的滤除。
在本实施例中,所述多窗谱减法可以有效降低所述鼾声音频的噪声,且对帧与帧之间进行平滑处理。
在本实施例中,基于所述维纳滤波器对所述鼾声音频进行降噪。
在本实施例中,所述预加重处理是一种对所述鼾声音频信号高频分量进行补偿的信号处理方式,有利于增强所述鼾声音频中的有效鼾声帧信号。
在本实施例中,所述硬判别具体指:所述有效鼾声帧中时长在0.2-5s外,响度在70分贝以上或频率大于800HZ作为异常有效鼾声帧处理,予以清洗剔除;
所述软判别具体指:对一位患者特征提取及选择后的部分特征进行聚类分析,设定阈值进行相应剔除。
上述技术方案的有益效果是:通过对所述鼾声音频的进行预处理,可以获得信噪比更高、帧与帧之间更加平滑、有效鼾声帧信号更强的预处理后的鼾声音频信号,有利于后续提取所述鼾声音频中的有效鼾声段并对其进行特征提取。
实施例3:
在上述实施例2的基础上,本实施例提供了一种基于鼾声的实时呼吸暂停及低通气预测方法,S2:对所述鼾声音频进行预处理和特征提取,还包括:
计算预处理后的鼾声音频信号的背景信号阈值;
将预处理后的鼾声音频信号划分成多个预设长度的音频段,提取每个音频段的声学特征(通过MCFF算法从每个音频段提取),基于每个音频段的声学特征,确定鼾声段起始点待选区域(即初步筛选所述鼾声段的起始点构成的区域)和鼾声段终止点待选区域(即初步筛选所述鼾声段的终止点构成的区域);
将所述起始点待选区域的逆向差分函数最大值(即相邻音频信号帧的短时幅值差值的最大绝对值)对应的帧作为鼾声段的起始点(即所述鼾声段起始对
应的鼾声帧),将所述终止点待选区域的逆向差分函数最大值对应的帧作为鼾声段的终止点(即所述鼾声段终止对应的鼾声帧);
基于相邻所述起始点和所述终止点确定连续鼾声音频信号中所有鼾声段(初步判定为鼾声的音频信号段);
获取所有鼾声帧对应的短时能量和过零率(即所述鼾声帧信号通过零点的次数),并判断所述鼾声帧是否满足短时幅值大于最低能量阈值或过零率大于过零率阈值,若是,则判定所述鼾声帧为有效鼾声帧,否则,判定所述鼾声帧为无效鼾声帧;
获取所述连续鼾声音频信号中相邻有效鼾声帧之间的时间间隔,当所述时间间隔小于预设时间阈值,则将相邻有效鼾声帧中的第一有效鼾声帧与第二有效鼾声帧合并,进而获得合并音频;
否则,不合并。
在本实施例中,将所述声学特征输入至混合神经网络模型中,可以分出有声音频段和无声音频段以及混合音频段,所述混合音频段即为所述起始点待选区域或鼾声段终止点待选区域;
当所述混合音频段之前的音频段为无声音频段,且之后的音频段为有声音频段,则判定所述混合音频段为起始点待选区域;
当所述混合音频段之前的音频段为有声音频段,且之后的音频段为无声音频段,则判定所述混合音频段为终止点待选区域。
在本实施例中:采用基于AV-Box端点检测的思想,根据局部信息设置双门限,使得在特定任务与时间周期下端点检测达到更优效果。
在本实施例中,所述短时幅值为:当前帧及其之前所有帧的音频信号幅值绝对值之和。
在本实施例中,所述鼾声帧即为初步筛选的有鼾声的音频信号帧。
在本实施例中,逆向差分函数最大值代表相邻音频信号帧的短时幅值差值的最大绝对值,代表此处为有声帧和无声帧的交界处,或无声帧和有声帧的交界处。
上述技术方案的有益效果是:通过设置自适应阈值的端点检测方法和设置双门限以及硬判决条件的判断,精准地筛选出有效鼾声段,并将所述有效鼾声段进行合并,获得更加精简的所述连续鼾声音频,在保证鼾声音频信号有效的情况下,实现了鼾声音频信号的精简化。
实施例4:
在上述实施例3的基础上,本实施例提供了一种基于鼾声的实时呼吸暂停及低通气预测方法,S2:对所述鼾声音频进行预处理和特征提取,还包括:
将所述合并音频输入深度神经网络提取梅尔频率倒谱系数特征矩阵(一种用于语音识别的主流特征);
基于第一预设准则(贝叶斯信息准则)确定所述合并音频的突变点(即所述连续鼾声音频类型改变点),并基于所述突变点将所述合并音频分割成若干个音频样本;
确定每个音频样本中的有效鼾声帧排列次序,所述音频样本都由预设数量个连续的有效鼾声帧构成;
基于梅尔频率倒谱系数特征矩阵将每个音频样本中位于相同排列次序的有效鼾声帧进行聚类,获得所述有效鼾声帧对应的对应的聚类中心(即按照聚类中心进行聚类);
确定每个聚类中心对应的所述有效鼾声帧的个数,基于对应的个数和聚类中心确定对应的有效鼾声帧的特征数据(即包括聚类中心及其对应的所述有效鼾声帧的个数)。
在本实施例中,提取梅尔频率倒谱系数特征包括:对所述连续鼾声音频中每一帧音频信号作离散傅里叶变换,获得每一帧音频信号对应的线性频谱;
基于梅尔频率滤波器得到每一帧音频信号对应的梅尔频谱,对所述梅尔频谱变换成倒谱域,获得每一帧音频信号对应的梅尔频率倒谱系数特征;
将所述梅尔频率倒谱系数特征按照帧的次序排列获得所述梅尔频率倒谱系数特征矩阵。
在本实施例中:在特征提取部分,对样本中的呼吸帧进行特征提取,目前使用的时频域特征为语音识别的主流特征如MFCC,LPCC等,在时域上分帧后使用使用T分布和随机近邻嵌入(Stochastic neighbour Embedding)方法及模板均值,最值等方式合并帧间特征;其他特征有体位、睡眠分期、年龄等,其中部分特征需要进行编码。
上述技术方案的有益效果是:基于对所述连续鼾声音频的梅尔频率倒谱系数特征矩阵进行分帧提取,基于预设准则确定突变点,并进行聚类分析并结合,实现有效精准地以多导睡眠监测数据中标注的呼吸事件时间节点作为标注提取正负样本。
实施例5:
在上述实施例1的基础上,本实施例提供了一种基于鼾声的实时呼吸暂停及低通气预测方法,S3:以多导睡眠监测数据中标注的呼吸事件时间节点作为标注提取正负样本之前,包括:
对所述睡眠指标中的数据和有效鼾声帧的特征数据进行质量评估,获得完整的数据样本;
基于所述多导睡眠监测数据获取目标对象的睡眠分期,基于所述睡眠分期获取所述目标对象未入眠的时间段;
删除未入眠时间段对应的数据样本;
将保留的数据样本和时间轴融合,获得所述全时域覆盖数据样本(即保留的覆盖全时域的数据样本与所述时间轴结合获得),并将所述全时域覆盖数据样本基于均值等分区间离散化,获得全时域覆盖离散样本。
在本实施例中,所属质量评估包括:检测所述睡眠指标中的数据和有效鼾声帧的特征数据的完整性,有效性、准确性,并对所述睡眠指标中的数据和有效鼾声帧的特征数据评估进行取舍。
在本实施例中:全自动提取样本的算法,以PSG输出的事件列表作为黄金标准,以PSG数据中标注的呼吸事件时间节点作为标注提取正负样本,实现全时域覆盖。医生仅需对标注的样本进行抽查及鼾声帧比例确认,这种方式大大降低了临床医生的标注量,同时有利于纳入新数据,在进行PSG数据与音轨对齐的基础上模拟实际真实情况,提出稳定负样本与离散负样本的概念,同时设置参数阈值确保正负样本占比的较一致性。
在本实施例中:考虑到整夜音频的复杂性,本提案允许在原算法的基础上通过数据清洗降低噪声:如根据睡眠分期的实时信息去除未入眠时的样本片段等。
上述技术方案的有益效果是:本发明基于获取的睡眠分期数据,去除所述样本数据中的未入眠时间段,实现了精准地清洗数据样本,在保证后续预测呼吸时间的数据完整性的情况下,实现了数据精简。
实施例6:
在上述实施例5的基础上,本实施例提供了一种基于鼾声的实时呼吸暂停及低通气预测方法,S3:以多导睡眠监测数据中标注的呼吸事件时间节点作为标注提取正负样本,包括:
获取与时间轴对齐的多导睡眠监测数据;
基于多导睡眠监测数据重标注的呼吸时间对应的时间节点作为标注提取预设数量个正预测样本(与真值对应的目标类别来说该样本为正样本)和负预测样本(与真值不对应的其他所有目标类别来说该样本为负样本),并提取所述正预测样本和所述负预测样本以及时间节点包含的所述有效鼾声帧的能量分布占比(即述有效鼾声帧的频谱能量占所有正负预测样本频谱总能量的百分比),作为对应的有效鼾声帧的特征向量;
计算所述正预测样本中包含的有效鼾声帧对应的特征向量两两之间的第一距离差值,并计算所述负预测样本中包含的有效鼾声帧对应的特征向量两两之间的第二距离差值,并计算所述正预测样本和所述负预测样本中包含的所有有效鼾声帧对应的特征向量与所述时间节点对应的有效鼾声帧的特征向量之间的第三距离差值;
判断所述第一距离差值和所述第二距离差值是否都小于预设距离阈值且所述第三距离差值大于所述预设距离阈值,若是,则判定所述正预测样本和所述负预测样本满足要求;
否则,当所述第三距离差值小于所述预设距离阈值时,则重新确定呼吸事件,否则,当所述第一距离差值和所述第二距离差值中存在至少一个大于所述预设距离差值时,将大于所述预设距离差值对应的有效鼾声帧作为正预测样本或负预测样本选取边界;
其中,所述正预测样本和所述负预测样本都包含:对应时间段内所述目标对象的人体测量学数据和睡眠信息以及有效鼾声帧的特征数据。
在本实施例中,将大于所述预设距离差值对应的有效鼾声帧作为正预测样本或负预测样本选取边界即:提取从大于所述预设距离差值对应的有效鼾声帧至所述时间节点中包含的所有正样本或负样本。
上述技术方案的有益效果是:本发明设计了样本自动提取与标注算法,以PSG数据中标注的呼吸事件时间节点作为标注提取正负样本,实现全时域覆盖。医生仅需对标注的样本进行抽查及鼾声帧比例确认,这种方式大大降低了临床医生的标注量,同时有利于纳入新数据;提出稳定负样本与离散负样本的概念,同时设置参数阈值确保正负样本占比的较一致性,实现了精准提取用于预测呼吸时间的有效样本。
实施例7:
在上述实施例1的基础上,本实施例提供了一种基于鼾声的实时呼吸暂停及低通气预测方法,S4:基于睡眠指标数据、正负样本提取结果,预测后续预设时间内出现呼吸暂停和低通气的概率,还包括:
基于滑动窗口算法对正负预测样本从预设数量个维度进行特征数据提取,获得对应正预测样本或负预测样本的第一特征数据集(包含对应正预测样本或负预测样本的鼾声音频和多导睡眠监测数据的特征数据);
基于典型关联算法将每个正预测样本或负预测样本的所述第一特征数据进行两两融合,获得对应正预测样本或负预测样本的第二特征数据集(二维特征融合后的特征数据集合);
基于典型关联分析原理将高位的两组数据降维至一维,分析所述正预测样本或所述负预测样本的特征组中任意两组特征数据的相关系数;
基于所述相关系数将所述第一特征数据进行分类,获得对应正预测样本或所述负预测样本的分类特征数据集;
其中,预设多个维度包括:所述目标对象的体位、睡眠分期、心率、血氧饱和度、呼吸气流参数、性别、年龄、有效鼾声帧等;
其中,所述特征组包括:第一特征数据集和第二特征数据集。
在本实施例中,基于相关系数分析所述正预测样本或所述负预测样本的特征组中任意两组特征数据的相关系数,包括:
式中,ρ(X,Y)为所述正预测样本或所述负预测样本的特征组中任意两组特征数据的相关系数,X,Y为所述正预测样本或所述负预测样本的特征组中任意两组特征数据,D(X)为X的方差,D(Y)为X的方差,COV(X,Y)为X,Y的协方差。
上述技术方案的有益效果是:对所述正负预测样本进行分类,实现了对所述正负预测样本的进一步精简和分类,有利于后续确定每类特征的权重值,进而为后续预测呼吸事件提供有效数据。
实施例8:
在上述实施例7的基础上,本实施例提供了一种基于鼾声的实时呼吸暂停及低通气预测方法,获得对应正预测样本或所述负预测样本的分类特征数据集之后,还包括:
将所述正预测样本或所述负预测样本对应的分类特征数据集输入至梯度提升树模型;
基于集成学习模型对所述梯度提升树模型输出的结果进行特征重要性分析,获得多个维度的特征对应的权重值(即将所述梯度提升树模型的输出结果输入至集成学习模型后获得的输出结果);
基于所述多个维度的特征对应的权重值和预设方法(SelectFromModel方法)建立逻辑回归模型,获得所述多个维度的特征的分值(反映出每一个样本中的特征的影响力,而且还表现出影响的正负性);
基于所述正预测样本或所述负预测样本对应的分类特征数据集对预设模型库中的多个预设模型(late fusion,early fusion,slow fusion等多种模型)进行性能比较,选择出最优特征融合模型(最适合本发明的特征融合模型);
将所述正预测样本或所述负预测样本对应的分类特征数据集和对应的特征的分值输入至所述最优特征融合模型,获得融合特征(用于获得预测呼吸事件的准确率);
将所述融合特征输入至所述集成模型,预测后续预设时间内出现呼吸暂停和低通气的概率;
基于预设的概率阈值将所述后续预设时间内出现呼吸暂停和低通气的概率划分为高概率区间、低概率区间(将集成模型的输出概率以一定区间进行划分:高概率区间的预测结果作为模型置信度高的解释性结果,模型拥有更高的把握预测准确;低概率区间的预测结果作为模型置信度低的解释性结果,模型预测准确的把握较低)。
在本实施例中:使用的数据包括整夜的鼾声音频,时间对齐的PSG数据,以及病人的人体测量学数据和睡眠信息。本提案致力综合这些数据,灵活选择并进行融合。对于音频及查体数据,在时域帧间使用T分布和随机近邻嵌入(Stochastic neighbour Embedding)方法进行帧间信息合并后,本提案使用SelectFromModel方法建立逻辑回归模型进行特征打分;在结合实时睡眠指标和病人查体数据的基础上本提案选用late fusion,earlyfusion,slow fusion等多种模型进行性能比较,选择其中最适合本提案的特征融合模型。为了提高模型的可解释性及对模型部署速度的需求,本提案拟使用XGBoost在python3.8环境下进行数据建模。
在本实施例中:主要侧重于睡眠生理参数及查体特征的解释,进一步辅助建立后续实时预警与诊断系统,其包括:
特征重要性分析:使用SHAP模型对梯度提升树模型输出的结果进行特征重要性分析:以合作博弈论为启发构建一个加性的解释模型,将所有的特征都视为“贡献者”进行考察分析。其优点为SHAP对于反映出每一个样本中的特征的影响力,而且还表现出影响的正负性。通过对整体SHAP value的考察,目前结果显示睡眠体位因素在众多特征中表现抢眼。
置信区间预警分析:将集成模型的输出概率以一定区间进行划分:高概率区间的预测结果作为模型置信度高的解释性结果,模型拥有更高的把握预测准确;低概率区间的预测结果作为模型置信度低的解释性结果,模型预测准确的把握较低。
上述技术方案的有益效果是:基于所述分类特征数据集和SHAP模型对梯度提升树模型输出的结果进行特征重要性分析,反映出每一个样本中的特征的影响力,有利于后需获得所述集成模型对应的输出预测概率,并将所述后续预设区间划分为高概率区间、低概率区间,可以准确判断是否需要进行提醒,有效地改善触发呼吸事件的情况。
实施例9:
在上述实施例8的基础上,本实施例提供了一种基于鼾声的实时呼吸暂停及低通气预测方法,预测后续预设时间内出现呼吸暂停和低通气的概率之后,还包括:
设置预警阈值(根据实际情况预先设置的);
当所述后续预设时间内出现呼吸暂停和低通气的概率大于所述预警阈值时,发出预警信号并对目标对象作出干预动作(如使用舌下神经刺激、体位干预方式等);
否则,保留所述后续预设时间内出现呼吸暂停和低通气的概率。
上述技术方案的有益效果是:通过根据实际情况预先设置预警阈值,可以自动判断是否需要进行干预提醒,实现了在有效改善触发呼吸事件的情况下避免过多打扰用户睡眠。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 一种基于鼾声的实时呼吸暂停及低通气预测方法
- 根据鼾声声学特征确定阻塞性睡眠呼吸暂停与低通气综合症严重程度的方法