自动适配基于音频数据的助理处理
文献发布时间:2024-04-18 19:58:30
背景技术
人类可以利用本文中称为“自动化助理”(也称为“聊天机器人”、“交互式个人助理”、“智能个人助理”、“个人话音助理”、“会话代理”等)的交互式软件应用参与人机对话。例如,人类(当他们与自动化助理交互时可以被称为“用户”)可以通过下述方式向自动化助理提供命令/请求:使用口语自然语言输入(即口述话语),在某些情况下可以将口语自然语言输入转换为文本然后进行处理;和/或通过提供文本(例如,键入的)自然语言输入。自动化助理通常通过提供响应式用户界面输出(例如,听觉和/或视觉用户界面输出)、控制智能设备和/或执行其他动作来响应于命令或请求。
如上所述,许多自动化助理被配置为经由口述话语与其进行交互。为了保护用户隐私和/或节省资源,自动化助理可以避免基于经由助理设备(即,(至少部分)实现自动化助理的客户端设备)的麦克风检测到的音频数据中存在的所有口述话语执行一个或多个自动化助理功能。相反,基于捕获口述话语的音频数据的某些处理仅响应于确定存在某些条件而被自动化助理执行。
例如,许多助理设备包括热词检测模型。当助理设备的麦克风未被解除激活时,助理设备可以使用热词检测模型连续处理经由麦克风检测到的音频数据,以生成指示是否存在一个或多个热词(包括多词短语)的预测输出。例如,预测输出可以是指示是否存在一个或多个热词的概率。例如,当概率满足阈值时,可以确定热词存在。当预测输出指示存在热词时,可以执行进一步的特定助理处理。然而,当预测输出指示不存在热词时,对应的音频数据将被丢弃,而不执行进一步的特定助理处理。
例如,可以利用助理调用热词检测模型来检测是否存在用于调用自动化助理的热词,诸如“嘿,助理”、“OK,助理”和/或“助理”。当使用助理调用热词检测模型生成的预测输出指示存在热词中的一个热词时,则可以执行进一步的助理处理。例如,当预测输出指示存在热词中的一个热词时,可以将在该热词的阈值时间量内跟随和/或之前(并且可选地被确定为包括话音活动)的音频数据由一个或多个设备上和/或远程自动化助理组件——诸如语音辨识组件——处理。此外,可以使用自然语言理解(NLU)引擎处理辨识的文本(来自语音辨识组件),和/或可以基于使用NLU引擎生成的NLU输出来执行动作。动作可以包括例如生成和提供响应和/或控制一个或多个应用和/或智能设备。
作为另一示例,动作热词检测模型可以至少选择性地用于检测用于经由自动化助理直接调用特定动作的热词何时存在于音频数据中。当使用动作热词检测模型生成的预测输出指示存在热词中的一个热词时,则可以执行调用特定动作的进一步的助理处理。例如,当助理设备处有传入话音和/或视频呼叫时,可以利用动作热词检测模型来检测音频数据中是否存在“回答”,并且当检测到“回答”时,自动化助理可以直接调用回答动作,从而使传入的话音和/或视频得到回答。此外,例如,可以利用动作热词检测模型来检测音频数据中是否存在“播放音乐”,并且当检测到“播放音乐”时,自动化助理可以直接调用特定的音乐流式传输服务来播放音乐,从而使得来自特定音乐流式传输服务的音乐开始在助理设备处流式传输。作为又一实例,可以利用动作热词检测模型来检测音频数据中是否存在“OK示例”,并且当检测到“OK示例”时,自动化助理可以调用特定的第三方应用(具有别名“示例”),从而使得特定第三方应用经由自动化助理与用户进行对话,以促进经由特定第三方应用执行动作。
热词检测模型在许多情况下表现良好,准确地在包括热词的音频数据和不包括热词的音频数据之间进行区分。然而,仍然存在响应于使用热词检测模型检测到热词而执行进一步的助理处理的情况,尽管用户没有意图执行进一步的助理处理。这样的情况的发生在本文中被称为“误肯定”。除了隐私问题之外,误肯定还可能通过不必要地执行进一步的助理处理来浪费网络和/或计算资源。
作为一个示例,假设“Vivian”是用于调用自动化助理或用于经由自动化助理直接调用特定动作的热词,并且给定的助理设备包括用于监视热词发生的热词检测模型。进一步假设给定的助理设备位于用户的膝上型计算机附近,并且用户正在利用膝上型计算机的麦克风和扬声器来参与与多个参与者——包括名为Vivian的参与者——的视频呼叫。自动化助理或特定动作可能会响应于用户或另一参与者在视频通话期间说出词“Vivian”而被无意地调用。这会由于不必要地执行进一步的助理处理而浪费网络和/或计算资源。虽然助理设备可以包括用于手动解除激活助理设备的麦克风并且由此防止该情况的硬件或软件按钮,但是用户可能已经忘记解除激活麦克风。此外,手动解除激活麦克风并且随后忘记手动重新激活麦克风可能导致随后的误否定情况,这将在下面更详细地描述。
作为另一示例,假设“贵宾犬”是用于调用自动化助理或经由自动化助理执行特定动作的热词,并且给定的助理设备包括用于监视热词的发生的热词检测模型。进一步假设用户在给定的助理设备附近说“Noodle(面条)”。响应于用户说出“Noodle”,可能会无意调用自动化助理或特定动作。这可能是由于使用热词检测模型生成的预测输出错误地指示“Poodle”被说出。例如,假设预测输出是一个概率,并且在进一步的助理处理被执行之前该概率必须大于0.80阈值。尽管说出了“Noodle”,但生成的概率可以是0.81,这导致执行进一步的助理处理。这会由于不必要地执行进一步的助理处理而浪费网络和/或计算资源。虽然一些助理设备启用用于手动适配阈值(例如,其可以相对于0.80增大或减小)的选项,但用户可能不知道该选项或者可能尚未使用该选项。进一步地,一旦手动适配,阈值保持静态,直到再次手动适配,并且该阈值对于助理设备的所有用户是公共的。此外,增加阈值的手动适配可能导致误否定增加,而降低阈值的手动适配可能导致误肯定增加。
此外,还存在这样的情况:尽管存在要执行进一步的助理处理的用户意图并且尽管有音频数据(其捕获口述话语)适合于促使执行进一步的助理处理,但不响应于用户的口述话语而执行进一步的助理处理。这样的情况的发生在本文中被称为“误否定”。误否定可以延长人类/自动化助理的交互,迫使人类重复最初意图激活自动化助理功能的话语(和/或执行其他动作)。
例如,假设使用热词检测模型生成的预测输出是概率,并且在执行进一步的助理处理之前,该概率必须大于0.85阈值。进一步假设音频数据中捕获的口述话语确实包括与热词检测模型相对应的热词,但是使用热词检测模型基于处理音频数据生成的预测概率仅为0.82。在这样的情况下,功能将不会被激活(因为0.82不大于0.85),从而导致误否定。误否定的发生会延长人类/自动化助理的交互,迫使人类重复最初意图激活自动化助理功能的话语(和/或执行其他动作)。
一些自动化助理附加地或可替代地至少选择性地实现可以启用的免调用模式。当在助理设备处启用时,免调用自由模式可以导致助理设备处理经由客户端设备的麦克风检测到的任何口述话语,并且确定该口述话语是否意图用于助理的,或者代替地,不意图用于助理(例如,代替地针对另一个人的口述话语)。在意图用于助理的口述话语和非意图用于助理的口述话语之间进行辨别时,可以使用机器学习模型来处理捕获口述话语的音频数据。音频数据可以可选地与来自对口述话语和/或其表示执行的语音辨识的辨识文本(例如,基于辨识文本生成的自然语言理解数据)一起被处理。预测输出是基于处理生成的,并且指示口述话语是否意图用于自动化助理。仅当预测输出指示口述话语意图用于自动化助理时,才执行某些进一步的自动化助理处理。否则,不执行某些进一步的自动化助理处理,并且丢弃与口述话语相对应的数据。某些进一步自动化助理处理可以包括例如进一步验证口述话语意图用于自动化助理和/或基于口述话语执行动作。
用于在意图用于助理的口述话语和在许多情况下表现不佳的口述话语之间进行辨别的机器学习模型在那两种类型的口述话语之间准确地进行区分。然而,仍然存在误肯定情况,其中,响应于确定口述话语意图用于助理而执行进一步的助理处理,尽管用户没有意图执行进一步的助理处理。此外,仍然存在不执行进一步的助理处理的误否定情况,尽管用户意图执行进一步的助理处理。
发明内容
本文公开的实施方式涉及至少间歇地处理动态场境参数以及依赖于动态场境参数的处理而动态自动地适配在助理设备处执行的音频数据处理。根据本文公开的实施方式的音频数据处理的动态和自动适配减轻了热词处理、免调用语音辨识和/或其他基于自动化助理音频数据的处理技术中误肯定和/或误否定的发生。减轻误肯定的发生可以通过防止无意的基于特定音频数据的助理处理来减轻隐私问题和/或节省计算和/或网络资源。减轻误否定的发生可以通过减轻对应用户重复话语和/或执行意图用于激活自动化助理功能的其他动作的发生来使能实现更有效的人类/自动化助理交互。
实施方式动态地自动适配两个或更多个状态之间的音频数据处理。音频数据处理从当前状态到替代状态的自动适配是响应于对动态场境参数的当前值的处理满足一个或多个条件。例如,可以使用一个或多个经过训练的机器学习模型来处理动态场境参数的当前值,以生成输出,该输出指示:鉴于当前值,两个或更多个状态中的哪个(些)应该是活动的。在这样的示例中,条件的满足可以包括输出,该输出指示替代状态应该是活动的,取代了当前活动的当前状态。另外,例如,动态场境参数的当前值可以附加地或可替代地使用(例如,由助理设备的注册用户限定)的一个或多个规则来处理,每个规则都针对对应的状态,以确定规则是否得到满足。在这样的示例中,条件的满足可以包括指示满足替代状态的规则的处理。
响应于条件的满足,基于音频数据的处理可以从当前状态适配到替代状态。适配可以是自动的。也就是说,从当前状态到替代状态的适配实例可以独立于接收请求或确认适配实例的任何显式用户界面输入而被执行。以这些和其他方式,可以减轻误肯定和/或误否定,或者通过适配实例以其他方式改进人类/自动化助理交互——并且不需要用户界面输入来实现该适配实例。在一些实施方式中,虽然适配是自动的,但是可以响应于该适配而渲染用户界面输出,并且用户界面输出可以可选地反映基于音频数据的处理所适配至的替代状态。这可以向助理设备的用户通知该适配。
此外,在那些实施方式中的一些中,响应于用户界面输出,可以提供进一步的用户界面输入以提供反馈。该反馈可以是例如适配是正确的反馈、应该已经进行替代适配的反馈、或者不应该已经进行适配的反馈。例如,反馈可以经由口述输入和/或经由与促进反馈的图形界面元素的交互。反馈可用于适配(例如,对于至少助理设备)适配所基于的机器学习模型和/或规则。以这些和其他方式,可以改进未来适配的准确性和/或鲁棒性。附加地或可替代地,指示不应该已经进行适配或应该已经进行替代适配的反馈可用于进一步立即使基于音频数据的处理适配至先前的当前状态或另一替代状态。这可以促进人/自动化助理交互,以确保当前的适配是正确的。
作为本文公开的实施方式的一个特定示例,自动适配可以是到至少完全活动状态、部分活动状态和/或不活动状态或来自至少完全活动状态、部分活动状态和/或不活动状态。在完全活动状态下,针对向助理设备注册的一个或多个注册用户(例如,具有存储在助理设备处和/或与助理设备相关联的用户简档)完全执行基于特定音频数据的助理处理,并且对于未向助理设备注册的任何用户(例如,所谓的“访客”用户)也完全执行基于特定音频数据的助理处理。在部分活动状态下,对于一个或多个注册用户完全执行基于特定音频数据的助理处理,但是对于未向助理设备注册的任何用户抑制基于特定音频数据的助理处理的至少一部分。在不活动状态下,基于特定音频数据的助理处理的至少一部分对于一个或多个注册用户被抑制,并且对于未向助理设备注册的任何用户也被抑制。
例如,假设基于音频数据的处理是调用热词处理。在完全活动状态下,可以处理音频数据流以监视调用热词的发生,并且响应于检测到调用热词的发生,可以执行进一步的助理处理。进一步的助理处理可以包括例如自动语音辨识(ASR)以生成对热词之前和/或之后的口述话语的辨识、基于该辨识的自然语言理解(NLU)、和/或基于基于执行NLU生成的NLU数据的履行。值得注意的是,在完全活动状态下,进一步的助理处理是响应于检测到调用热词的发生而执行的,并且是在注册用户说出该热词时以及在访客说出该热词时执行的。
部分活动状态可以类似于完全活动状态。然而,在部分活动状态下,当确定热词尚未被注册用户说出时,可以抑制ASR、NLU和/或履行。例如,可以利用依赖文本的说话者识别(TDSID)和/或不依赖文本的说话者识别(TISID)来确定热词和/或(在热词之前和/或之后的)口述话语是否来自注册用户。ASR、NLU和/或履行的性能可以取决于验证热词和/或口述话语是否来自注册用户。基于视觉的面部验证可以附加地或可替代地用于确定热词和/或口述话语是否来自注册用户。
在不活动状态下,可以对所有用户将音频数据流的处理以监视调用热词的发生完全解除激活。在一些实施方式中,尽管抑制了对音频数据流的处理以监视调用热词的发生,但是音频数据流可以可选地被处理用于一个或多个其他目的,诸如生成用于本文描述的当前活动场境参数的值。因此,在那些实施方式中,并未出于所有目的而完全禁用助理设备的麦克风。
作为本文公开的实施方式的另一特定示例,自动适配可以是到至少第一阈值状态和第二阈值状态或来自至少第一阈值状态和第二阈值状态。在第一阈值状态中,一个或多个第一阈值用于基于特定音频数据的助理处理,而在第二阈值状态中,一个或多个不同的第二阈值用于基于特定音频数据的助理处理。
例如,假设基于音频数据的处理是免调用语音辨识处理。在第一阈值状态和第二阈值状态两者中,可以对捕获口述话语(例如,如由话音活动检测所指示的)的音频数据执行语音辨识以生成口述话语的辨识。此外,在两种状态下,可以(例如,使用机器学习模型)处理辨识和/或音频数据以生成输出,该输出指示口述话语是否是助理命令。在第一阈值状态中,将输出与第一阈值进行比较以确定口述话语是否是助理命令。在第二阈值状态中,将输出与第二阈值进行比较以确定口述话语是否是助理命令。在两种状态下,仅响应于确定口述话语是助理命令才可以执行进一步的助理处理。例如,进一步的助理处理可以包括基于辨识来执行NLU和/或基于来自NLU的NLU数据来执行履行。如上所述,在第一阈值状态和第二阈值状态下使用不同的阈值来确定是否执行进一步的助理处理。因此,该确定在第一阈值状态和第二阈值状态中的一个状态中限制性较大,而在另一个状态中限制性较小。因此,在限制性较小的状态中,给定的口述话语可以被确定为针对自动化助理,而在限制性较大的状态下,相同的给定口述话语可以被确定为不针对自动化助理。
除了前面示例中提供的那些之外,还可以利用附加的和/或可替代的状态和/或适配。例如,状态可以包括第一阈值完全活动状态、第二阈值完全活动状态、第一阈值部分活动状态、第二阈值部分活动状态和不活动状态。另外,例如,状态可以包括第一阈值完全活动状态、第二阈值完全活动状态、第三阈值完全活动状态和不活动状态。
如上所述,本文描述的自动适配基于对动态场境参数的当前值的处理。在一些实施方式中,动态场境参数包括注册用户参数、当前活动参数和/或时间参数。
用于注册用户参数的注册用户值可以指示一个或多个注册用户是否存在于助理设备的环境中和/或可以指示一个或多个注册用户中的哪个(些)存在于该环境中。例如,可以在助理设备本地并且通过使用TISID模型处理音频数据来执行TISID,以确定注册用户是否当前存在于和/或哪个(些)注册用户当前存在于助理设备附近,以及注册用户值可以反映该确定。此外,例如,可以附加地或可替代地在助理设备本地执行基于视觉的(例如,基于来自助理设备的视觉组件的视觉数据)面部验证,以确定注册用户是否当前存在于和/或哪个(些)注册用户当前存在于助理设备附近,并且注册的用户值可以反映该确定。
当前活动参数的当前活动值可以指示一个或多个活动是否在环境中正在发生和/或可以指示一个或多个活动中的哪个(些)在环境中正在发生。例如,注册用户的日历条目可以由助理设备访问,以确定该用户正在视频呼叫中,并且当前活动值通常可以反映注册用户正在从事某项活动,或者更具体地,用户正在开会或视频呼叫中。作为另一个示例,可以在助理设备本地处理来自助理设备的麦克风的音频数据流,以确定指示特定活动发生的声音的存在,并且当前活动值可以一般地反映活动正在发生,或更具体地,反映特定的活动。例如,可以基于指示餐具声音的存在的音频数据流的本地处理来推断“吃”活动,并且当前活动值可以反映特定的吃活动。
时间参数的当前时间值可以指示一个或多个当前时间条件,诸如一天中的时间(例如,明确的,诸如上午9:00;或一般的,诸如早上)、一周中的一天(例如,星期一、星期二等)、一年中的一天(例如12月23日)或月份。
还如上所引用,在各种实施方式中,动态场境参数的当前值的处理可以经由经过训练的机器学习模型和/或规则。在一些实施方式中,经过训练的机器学习模型可以基于监督或半监督训练示例来训练,诸如基于过去与自动化助理的交互生成的那些和/或基于响应于本文描述的自动适配接收到的反馈实例生成的那些。助理设备上使用的机器学习模型可以可选地基于使用助理设备和/或与助理设备显式链接的其他助理设备生成的训练示例来专门或部分地进行训练(例如,属于同一注册用户的那些)。
作为非限制性示例,假设经过训练的机器学习模型,该模型被训练来处理场境值并且生成输出,该输出指示在给定场境值的情况下用户将与自动化助理交互的似然性。例如,输出可以是从0到1的概率,较高的值指示增加的交互的似然性。在该示例中,当输出大于0.6时,助理设备可以被适配至第一阈值状态(如果尚未在该状态),并且否则适配至第二阈值状态(如果尚未在该状态)。第一阈值状态可以使用比第二阈值状态中使用的第二阈值限制性更小的第一阈值。在此示例中,可以基于发生助理交互而没有被取消或中断的先前实例来生成肯定训练示例。例如,每个肯定训练示例可以包括作为输入的、反映那些实例中的一个实例处的场境的场境值以及作为输出的值“1”。在此示例中,可以可选地基于先前的实例生成否定训练示例,在这些实例中,助理交互被发起但很快被取消或中断(例如,推断出误肯定情况)。例如,每个否定训练示例可以包括作为输入的、反映那些实例中的一个实例处的场境的场境值以及作为输出的值“0”。训练示例可以附加地或可替代地基于本文描述的反馈实例来生成。
作为另一个非限制性示例,假设经过训练的机器学习模型,其被训练来处理场境值并且生成指示完全活动状态的第一似然性、部分活动状态的第二似然性、以及完全不活动状态的第三似然性的输出。例如,输出中的每个输出可以是从0到1的概率,较高的值指示增加的交互的似然性,并且可以对概率进行归一化(例如,经由softmax)。在此示例中,在下述情况下,助理设备可以被适配至三种状态中的对应一种状态(如果尚未在该状态):在该状态的似然性大于其他两种状态的似然性时,并且可选地,如果它满足某个阈值(例如,0.5)和/或其他条件得到满足。在该示例中,可以基于用户经由反馈和/或其他手段确认三种状态中的一个状态的先前实例来生成肯定训练示例。例如,每个肯定训练示例可以包括作为输入的、反映那些实例中的一个实例的场境的场境值,以及作为输出的、用于确认状态的值“1”和用于另外两个状态的值“0”。
在利用规则的实施方式中,它们可以与机器学习模型结合使用或代替机器学习模型。例如,在确定是否在给定实例处适配基于音频数据的处理时,如果给定在给定实例处的当前场境条件而满足该规则,则可以利用该规则,否则,可以利用机器学习模型。作为规则的一个非限制性示例,用户可以指定“在工作日晚餐期间关闭免调用语音处理”。作为响应,可以生成规则,其使得免调用语音处理在工作日以及当周围噪声检测和/或其他信号(例如,指示烹饪完成的智能烤箱)指示“晚餐”正在发生时处于不活动状态。作为规则的另一个非限制性示例,用户可以指定“每当我参加视频会议时限制对我的热词调用”。作为响应,可以生成一条规则,其当用户处于视频会议中时(例如,如用户的日历所反映的),使得调用热词处理处于部分活动状态。
在一些实施方式中,当提供智能设备的生态系统并且将其彼此链接(例如,经由主页图和/或经由向公共用户账户注册)时,助理设备中的每个助力设备可以确定并且实施它自己的适配,并且可以可选地具有在适配中使用的、针对助理设备定制的机器学习模型和/或规则。在一些其他实施方式中,一个助理设备处的适配可以导致生态系统中的其他助理设备处的相同适配。例如,一个助理设备可以响应于适配至给定状态而与一个或多个链接的助理设备通信以使它们也转变到给定状态。
以上仅被提供作为一些实施方式的概述。本文更详细地公开了那些和/或其他实施方式。
附图说明
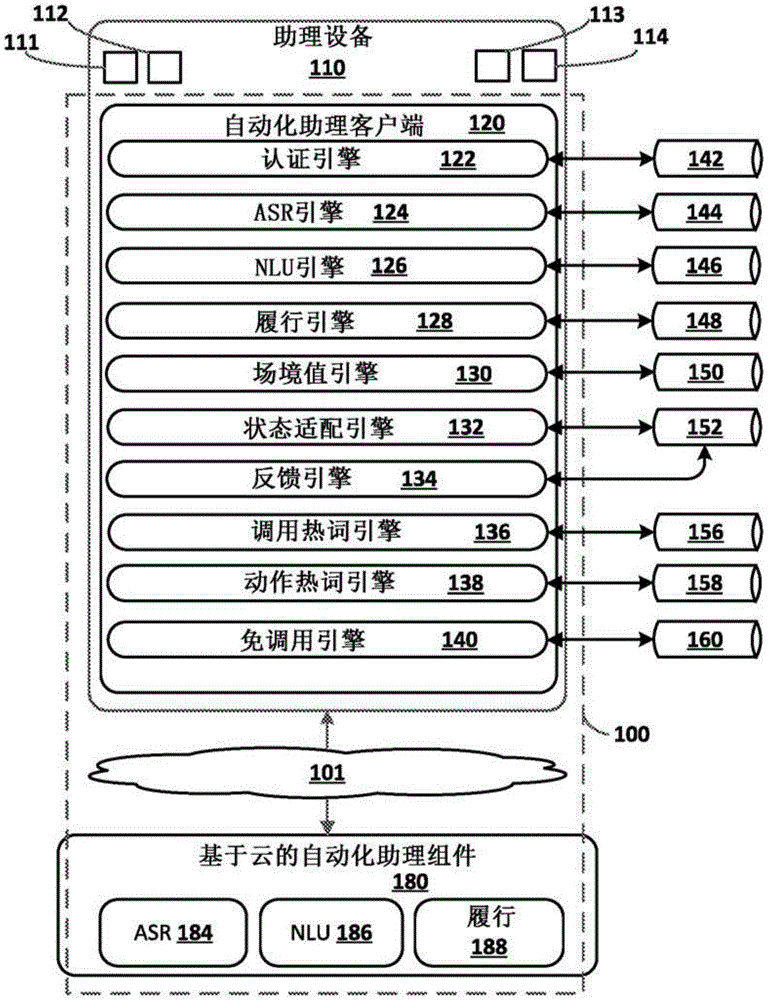
图1是其中可以实现本文所公开的实施方式的示例计算环境的框图。
图2是图示取决于场境参数自动适配基于音频数据的助理处理的示例方法的流程图。
图3是图示取决于当前活动状态执行调用热词处理的示例方法的流程图。
图4是图示取决于当前活动状态而执行动作热词处理的示例方法的流程图。
图5是图示取决于当前活动状态执行免调用语音处理的示例方法的流程图。
图6A、图6B、图6C、图6D和图6E图示了示例助理设备和对反映基于音频数据的助理处理的当前自动适配状态的用户界面输出进行渲染以及对反馈用户界面元素进行渲染的示例。
图7图示了计算设备的示例架构。
具体实施方式
首先转向图1,图示了可以在其中执行各种实施方式的示例环境。图1包括至少选择性地执行自动化助理客户端120的实例的助理设备110。如本文所使用的,助理设备是执行自动化助理客户端和/或经由其可以以其他方式访问自动化助理的客户端设备。一个或多个基于云的自动化助理组件180可以在一个或多个计算系统(统称为“云”计算系统)上实现,这些计算系统经由一般在101处指示的一个或多个局域网和/或广域网(例如,互联网)通信地耦合到助理设备110。
自动化助理客户端120的实例可以可选地经由与基于云的自动化助理组件180中的一个或多个自动化助理组件的交互形成从用户的角度来看似乎是自动化助理的逻辑实例,用户可以参与与该自动化助理的人机对话。图1中描绘了这样的自动化助理100的实例。
助理设备110可以是例如:台式计算设备、膝上型计算设备、平板计算设备、移动电话计算设备、车辆的计算设备(例如,车载通信系统、车载娱乐系统、车载导航系统)、独立交互式扬声器、具有显示器的独立交互式扬声器、诸如智能电视的智能电器、和/或包括计算设备的可穿戴装置(例如,具有计算设备的手表、具有计算设备的眼镜、虚拟或增强现实计算设备)。
助理设备110可以由家庭、企业或其他环境中的一个或多个用户使用。此外,一个或多个用户可以向助理设备110注册,并且每个注册用户可以具有可经由助理设备110访问的对应用户账户。对于注册用户来说,用户账户可以包括例如用于验证口述话语是否来自注册用户的注册用户的验证特征,诸如TDSID特征(例如,嵌入)、TISID特征(例如,嵌入)和/或面部特征(例如,嵌入)。
图1中的助理设备110被示为包括一个或多个麦克风111、一个或多个扬声器112、一个或多个相机和/或其他视觉组件113、以及一个或多个显示器114(例如,触敏显示器)。客户端设备110可以进一步包括压力传感器、接近传感器、加速计、磁力计和/或其他传感器。来自麦克风111、视觉组件113和/或其他传感器的传感器数据可以被处理以生成本文描述的场境特征的值。
图1中的自动化助理客户端120被图示为包括认证引擎122、自动语音辨识(ASR)引擎124、自然语言理解(NLU)引擎126、履行引擎128、场境值引擎130、状态适配引擎132、反馈引擎134、调用热词引擎136、动作热词引擎138和免调用引擎140。在一些实施方式中,可以从自动化助理客户端120中省略所示引擎中的一个或多个。例如,引擎可以代替地仅由基于云的自动化助理组件180来实现或者可以从自动化助理客户端120和基于云的自动化助理组件180中省略。附加地,在一些实施方式中,附加引擎可以在自动化助理客户端120上被提供,诸如文本转语音(TTS)引擎、话音活动检测器(VAD)引擎、端点检测器引擎和/或其他引擎。
认证引擎122可以确定存在于助理设备110的环境中的用户是否是注册用户和/或访客用户,并且可以可选地确定用户是特定注册用户。认证引擎122可以利用例如依赖文本的说话者识别(TDSID)技术、不依赖文本的说话者识别(TISID)技术、面部验证技术和/或其他验证技术(例如PIN录入)确定给定用户是注册用户还是未注册访客用户。在来自相关联的注册用户的许可下,可以为助理设备110的注册用户中的每个注册用户生成并且存储验证特征(例如,与其对应的用户账户相关联地本地存储在助理设备110处)。认证引擎122可以将当前基于传感器的特征与存储的验证特征进行比较以确定是否存在匹配。如果存在匹配,则认证引擎122可以确定对应的注册用户存在于助理设备110的环境中。
在一些实施方式中,认证引擎122在生成当前基于传感器的特征时利用一个或多个本地认证机器学习模型142。作为一个示例,可以使用本地认证机器学习模型142的TDSID模型来处理被确定为捕获调用热词的音频数据,以生成当前TDSID嵌入。此外,可以将当前TDSID嵌入与用户TDSID嵌入进行比较,每个用户TDSID嵌入与对应的用户账户相关联地存储,以确定是否存在匹配(例如,当前TDSID嵌入与用户TDSID嵌入之间的距离小于阈值)。如果是,则认证引擎122可以确定该热词是由匹配的注册用户说出的。作为另一示例,可以使用本地认证机器学习模型142的TISID模型来处理捕获口述话语的音频数据,以生成当前TISID嵌入。此外,可以将当前TISID嵌入与用户TISID嵌入进行比较,每个用户TISID嵌入与对应的用户账户相关联地存储,以确定是否存在匹配(例如,当前TISID嵌入与用户TISID嵌入之间的距离小于阈值)。如果是,则认证引擎122可以确定口述话语是由匹配的注册用户说出的。作为又一示例,可以使用本地认证机器学习模型142的面部验证模型来处理捕获用户面部的视觉数据,以生成当前面部嵌入。此外,可以将当前面部嵌入与用户面部嵌入进行比较,每个用户面部嵌入与对应的用户账户相关联地存储,以确定是否存在匹配(例如,当前面部嵌入与用户面部嵌入之间的距离小于阈值)。如果是,则认证引擎122可以确定注册用户存在于助理设备110的环境中。
在一些实施方式中,认证引擎122可以用于在基于音频数据的处理的至少一些状态下确定口述话语是否来自注册用户(一般确定,或确定是否来自特定注册用户)。例如,认证引擎122可以执行图3的方法300的框310A、图4的方法400的框410A和/或图5的方法500的框510A。在一些附加或可替代实施方式中,认证引擎122可以用于生成本文描述的场境参数的注册用户参数的注册用户值。例如,认证引擎122可以处理来自麦克风111和/或视觉组件113的音频数据,以生成指示一个或多个注册用户是否存在于助理设备的环境中,以及/或者可以指示一个或多个注册用户中的哪个(些)存在于环境中的值。
ASR引擎124可以处理捕获口述话语的音频数据以生成口述话语的辨识。例如,ASR引擎124可以利用本地ASR机器学习模型144来处理音频数据以生成与话语相对应的辨识文本的预测。
NLU引擎126可以处理音频数据和/或由ASR引擎124从音频数据生成的辨识,并且基于该处理生成NLU数据。NLU数据可以反映对应口述话语的语义含义。例如,NLU数据可以包括意图和该意图的参数。NLU引擎126可以进一步可选地确定与那些语义含义相对应的助理动作。在一些实施方式中,NLU引擎126将助理动作确定为基于ASR引擎124的辨识确定的意图和/或参数。在一些情况下,NLU引擎126可以基于用户的单个话语解析意图和/或参数,并且在其他情况下,可以基于未解析的意图和/或参数生成提示,那些提示被渲染给用户,以及用户对那些提示的响应被NLU引擎126用于解析意图和/或参数。在那些情况下,NLU引擎126可以可选地与对话管理器引擎(未图示)协同工作,对话管理器引擎确定未解析的意图和/或参数和/或生成对应的提示。NLU引擎126可以利用本地NLU机器学习模型146来生成NLU数据和/或确定助理动作。
履行引擎128可以促使执行由NLU引擎126确定的助理动作。例如,如果NLU引擎126确定“打开厨房灯”的助理动作,则履行引擎128可以引起对应数据的传输(直接到灯或到与灯制造商相关联的远程服务器)以使得“厨房灯”被“接通”。作为另一个示例,如果NLU引擎126确定助理动作“提供用户今天的会议的摘要”,则履行引擎128可以访问用户的日历,总结用户当天的会议,并且使得该摘要被视觉上(经由显示器114)和/或听觉上(经由扬声器112)在助理设备110处被渲染。
场境值引擎130至少间歇性地生成动态场境参数的当前值,并且提供当前值以供状态适配引擎132使用。在一些实施方式中,场境值引擎130执行图2的方法200的框202。在生成当前值中的一个或多个当前值时,场境值引擎130可以可选地利用一个或多个本地场境机器学习模型150。在一些实施方式中,场境值引擎130生成用于注册用户参数、当前活动参数和/或时间参数的当前值。
当场境值引擎130生成注册用户参数的注册用户值时,它们可以指示一个或多个注册用户是否存在于助理设备的环境中和/或可以指示一个或多个注册用户中的哪个(些)注册用户在环境中存在。在生成注册用户值时,场境值引擎130可以与认证引擎122进行接口连接,以确定注册用户是否存在于和/或哪个(些)注册用户当前存在于助理设备110的环境中。例如,认证引擎122可以在助理设备110本地执行TISID,以确定注册用户是否当前存在于和/或哪个(些)注册用户当前存在于助理设备附近。可以由场境值引擎130利用对应的数据来生成反映注册用户是否当前存在和/或哪个(些)注册用户存在的注册用户值。
当场境值引擎130生成当前活动参数的当前活动值时,它们可以指示一个或多个活动是否正在环境中发生和/或可以指示一个或多个活动中的哪个(些)在环境中正在发生。例如,可以由场境值引擎130访问注册用户的本地存储的日历条目,以确定用户是否正在开会,并且场境值引擎130可以生成反映用户是否正在开会的当前活动值。例如,当前活动值可以一般地反映注册用户正在参与活动,或者更具体地,用户正在会议中和/或会议的一个或多个属性。作为另一示例,场境值引擎可以访问与助理设备110上和/或环境中的其他客户端设备上运行的应用相对应的活动数据,并且场境值引擎130可以生成反映经由应用执行的一个或多个活动的当前活动值。例如,场境值引擎130可以基于来自分离的平板计算机并且与平板计算机的视频应用相对应的活动数据来生成反映用户正在开会的当前活动值。活动数据可以由视频应用或由平板计算机的操作系统提供。
作为又一示例,场境值引擎130可以使用本地场境机器学习模型150中的一个或多个本地场境机器学习模型来处理来自麦克风111的音频数据流,以监视一个或多个类型的声音的发生。场境值引擎130可以生成直接或间接指示某种类型的声音的当前活动值当前是否被检测到。例如,响应于最近(例如,在最后5秒、10秒或其他阈值内)检测到一种类型的声音,场境值引擎130可以生成通常指示活动正在发生,或更具体地,反映与声音类型相对应的特定活动的当前活动值。例如,可以基于指示餐具声音的存在的音频数据流的本地处理来推断“吃”活动,并且当前活动值可以反映特定的吃活动。作为另一个示例,可以基于指示音乐的存在的音频数据流的本地处理来推断“听音乐”活动,并且当前活动值可以反映特定的听音乐活动。作为另一个示例,可以基于指示电话振铃存在的音频数据流的本地处理来推断“电话振铃”活动,并且当前活动值可以反映特定电话振铃活动。作为又一示例,可以基于指示门铃响铃的存在的音频数据流的本地处理来推断“门铃响铃”活动,并且当前活动值可以反映特定的门铃响铃活动。
当场境值引擎130生成时间参数的当前时间值时,它们可以指示一个或多个当前时间条件,诸如一天中的时间(例如,明确的,诸如上午9:00;或一般的,诸如早上)、一周中的一天(诸如星期一、星期二等)、一年中的一天(例如12月23日)或月份。
状态适配引擎132至少间歇地处理由场境值引擎130生成的场境参数的当前值,以确定是否使基于音频数据的助理处理的当前状态自动适配至不同的状态。在一些实施方式中,状态适配引擎132执行图2的方法200的框204、206和/或208。
状态适配引擎132可以响应于处理满足一个或多个条件而确定将基于音频数据的助理处理从当前状态自动适配到替代状态。例如,状态适配引擎132可以使用一个或多个经过训练的适配机器学习模型152来处理动态场境参数的当前值,以生成输出,该输出指示:鉴于当前值,两个或更多个状态中的哪个(些)应该是活动的。在这样的示例中,条件的满足可以包括指示替代状态应该是活动的,代替当前活动的当前状态的输出。另外,例如,状态适配引擎132可以附加地或可替代地使用各自针对对应状态的一个或多个规则来处理动态场境参数的当前值,以确定是否满足该规则。在这样的示例中,条件的满足可以包括指示针对替代状态的规则被满足的处理。响应于条件的满足,状态适配引擎132可以引导一个或多个对应的引擎将它们的基于音频数据的处理从当前状态自动地适配到替代状态。例如,状态适配引擎132可以引导调用热词引擎从当前活动的第一阈值状态转变到替代的第二阈值状态。作为另一个示例,状态适配引擎132可以引导免调用引擎140从当前活动的完全活动状态转变到替代的部分活动状态。
在一些实施方式中,状态适配引擎132可以响应于使处理适配至替代状态而使得反映基于音频数据的处理被适配至的替代状态的用户界面输出被渲染。例如,与替代状态相对应的响声可以在适配时经由扬声器112被听觉地渲染,和/或与替代状态相对应的图形元素可以经由显示器114被视觉地渲染。用户界面输出中的一个或多个用户界面的渲染可以可选地贯穿替代状态的持续时间持续存在,然后响应于对不同状态的适配而被替换为替代用户界面输出。
反馈引擎134可以利用经由助理设备110接收的用户反馈来:选择性地改变由状态适配引擎132做出的适配;训练由状态适配引擎132使用的机器学习模型;以及/或者改变由状态适配引擎132使用的规则。例如,响应于导致状态适配引擎132的适配被实现,可以由用户提供进一步的用户界面输入,以提供关于适配的反馈。该反馈可以是例如适配是正确的反馈、应该已经进行替代适配的反馈、或者不应该已经进行适配的反馈。例如,反馈可以经由口述输入和/或经由与促进反馈的图形界面元素的交互。反馈引擎134可以利用要适配的反馈(例如,至少对于助理设备110)、适配机器学习模型152和/或适配所基于的规则。例如,反馈可以指示应当删除或修改适配所基于的规则。作为响应,反馈引擎134可以相应地删除或修改规则。
作为另一示例,基于状态适配引擎136使用机器学习模型152中的一个处理当前场境值并且生成指示第一状态的最高概率的第一输出,适配可能已经是到第一状态。该反馈可以指示应当利用第二状态来代替第一状态。作为响应,反馈引擎134可以生成训练示例,该训练示例包括作为输入的处理后的当前场境值以及作为输出的指示第二状态的最高概率的替代输出。反馈引擎134可以基于所生成的训练示例来训练适配机器学习模型152中的一个适配机器学习模型。附加地或可替代地,当反馈指示不应该已经进行适配或应该已经进行替代适配时,反馈引擎134可以使用反馈来进一步立即将基于音频数据的处理适配至先前的当前状态或另一替代状态。
在一些实施方式中,反馈引擎134执行图2的方法200的框212和/或214、图3的方法300的框316和/或318、图4的方法400的框416和/或418和/或图5的方法500的框520和/或522。
调用热词引擎136可以使得响应于调用热词的检测执行进一步的助理处理。例如,调用热词引擎136可以响应于检测到诸如“嘿,助理”、“OK,助理”和/或“助理”的一个或多个口述调用热词中的任何一个来调用自动化助理100。调用热词引擎136可以连续地处理(例如,如果不处于“不活动”状态)基于来自助理设备110的一个或多个麦克风111的输出的音频数据流,以监视发生调用热词。该处理可以利用一个或多个调用热词机器学习模型156。在监视口述调用短语的发生时,调用热词引擎136丢弃(例如,在临时存储在缓冲器中之后)不包括调用热词的任何音频数据。然而,当调用热词引擎136在处理的音频数据中检测到调用热词的发生时,调用热词引擎136可以至少选择性地使得进一步的助理处理被执行。进一步的助理处理可以包括例如自动语音辨识(ASR)(例如,通过ASR引擎124和/或基于云的ASR引擎184)以生成对在调用热词之前和/或之后的口述话语的辨识、基于辨识的NLU(例如,通过NLU引擎126和/或基于云的NLU引擎186)和/或基于以执行NLU为基础而生成的NLU数据的履行(例如,通过履行引擎128和/或基于云的履行引擎188)。
在一些实施方式中,在确定处理的音频数据中是否存在调用热词时,调用热词引擎136可以将从处理音频数据生成的输出与阈值进行比较。此外,在那些实施方式中的一些实施方式中,所利用的阈值可以取决于由状态适配引擎132指示的当前活动状态。在一些附加或替代实施方式中,在确定是否执行进一步的助理处理时,调用热词引擎136可以进一步基于调用热词和/或口述话语是否来自注册用户(特定注册用户或任何注册用户)来做出确定。此外,在那些实施方式中的一些实施方式中,该确定是否进一步基于调用热词和/或口述话语是否来自注册用户可以取决于由状态适配引擎132指示的当前活动状态。
在一些实施方式中,调用热词引擎136执行图3的方法300的框302、304、306、308和/或310。
动作热词引擎138可以响应于检测到口述动作热词而经由自动化助理100引起特定动作被调用。例如,动作热词引擎138可以响应于检测到“播放音乐”动作热词和/或“尽情享受音乐(jam out)”动作热词而导致直接调用“播放音乐”动作。动作热词引擎138可以连续地处理(例如,如果不处于“不活动”状态)基于来自助理设备110的麦克风111中的一个或多个麦克风的输出的音频数据流,以监视动作热词的发生。该处理可以利用一个或多个动作热词机器学习模型158。在监视动作热词的发生时,动作热词引擎138丢弃(例如,在临时存储在缓冲器中之后)不包括口述调用短语的任何音频数据。然而,当动作热词引擎138在处理的音频数据中检测到动作热词的发生时,动作热词引擎138可以至少选择性地使得动作被调用。
在一些实施方式中,在确定动作热词是否存在于处理的音频数据中时,动作热词引擎138可以将从处理音频数据生成的输出与阈值进行比较。此外,在那些实施方式中的一些实施方式中,所利用的阈值可以取决于由状态适配引擎132规定的当前活动状态。在一些附加或可替代实施方式中,在确定是否调用动作时,动作热词引擎138可以进一步基于动作热词是否来自注册用户(特定注册用户或任何注册用户)来做出确定。此外,在那些实施方式中的一些实施方式中,该确定是否进一步基于动作热词是否来自注册用户可以取决于由状态适配引擎132规定的当前活动状态。
在一些实施方式中,动作热词引擎138执行图4的方法400的框402、404、406、408和/或410。
免调用引擎140可以(例如,如果不处于“不活动”状态)使得ASR引擎124对于基于来自助理设备110的一个或多个麦克风111的输出的音频数据执行ASR处理,以生成在音频数据中捕获的口述话语的辨识。此外,免调用引擎140可以使用免调用模型160来处理辨识和/或音频数据,以生成指示口述话语是否是助理命令的输出。当输出指示口述话语不是助理命令时,免调用引擎140可以丢弃音频数据和辨识。然而,当输出指示口述话语是助理命令时,免调用引擎140可以使得进一步的助理处理被执行。例如,进一步的助理处理可以包括基于辨识来执行NLU和/或基于来自NLU的NLU数据来执行履行。
在一些实施方式中,在确定口述话语是否是助理命令时,免调用引擎140可以将从处理辨识和/或音频数据所生成的输出与阈值进行比较。此外,在那些实施方式中的一些实施方式中,所利用的阈值可以取决于由状态适配引擎132规定的当前活动状态。在一些附加或可替代实施方式中,在确定口述话语是否是助理命令时,免调用引擎140可以进一步基于口述话语是否来自注册用户(特定注册用户或任何注册用户)来做出确定。此外,在那些实施方式中的一些实施方式中,该确定是否进一步基于口述话语是否来自注册用户可以取决于由状态适配引擎132规定的当前活动状态。
在一些实施方式中,免调用引擎140执行图5的方法500的框502、506、508、510、512、514、516和/或518。
在各种实施方式中,助理设备110可以除了自动化助理客户端120之外还可选地操作的一个或多个其他应用,诸如消息交换客户端(例如,SMS、MMS、在线聊天)、浏览器等等。在那些各种实施方式中的一些中,一个或多个其他应用可以可选地与自动化助理100接口连接(例如,经由应用编程接口),或者包括它们自己的自动化助理应用实例(其也可以与基于云的自动化助理组件180接口连接)。
基于云的自动化助理组件180是可选的,并且可以与助理客户端120的对应组件协同操作和/或可以(总是或选择性地)代替助理客户端120的对应组件来使用。在一些实施方式中,基于云的组件180可以充分利用云的几乎无限的资源来相对于自动化助理客户端120的任何对应部分执行对音频数据和/或其他数据的更鲁棒和/或更准确的处理。在各种实施方式中,助理设备110可以响应于热词引擎检测到热词或检测到自动化助理100的一些其他的显式调用而向基于云的自动化助理组件180提供音频数据和/或其他数据。
所示的基于云的自动化助理组件180包括基于云的ASR引擎182、基于云的NLU引擎186和基于云的履行引擎148。这些组件可以执行与其自动化助理对应部分(如果有的话)类似的功能性。在一些实施方式中,可以省略所示的基于云的引擎中的一个或多个(例如,替代地仅由自动化助理客户端120来实现)和/或可以提供附加的基于云的引擎(例如,基于云的认证引擎对应部分和/或免调用引擎对应部分)。
图2是图示取决于场境参数自动适配基于音频数据的助理处理的示例方法200的流程图。为了方便起见,参考执行操作的系统来描述流程图的操作。该系统可以包括各种计算机系统的各种组件,诸如自动化助理客户端120的一个或多个组件。此外,虽然以特定次序示出方法200的操作,但这并不意味着限制。可以重新排序、省略或添加一个或多个操作。
在框202处,系统生成场境参数的当前值。可以基于来自助理设备的传感器的基于传感器的观察和/或基于在助理设备处本地可用的数据来生成当前值中的一个或多个当前值。框202可选地包括框202A、202B和/或202C。
在框202A处,系统针对场境参数的注册用户参数生成当前值的注册用户值。注册用户值可以指示一个或多个注册用户是否存在于助理设备的环境中和/或可以指示一个或多个注册用户中的哪个(些)存在于环境中。在一些实施方式中,系统与认证引擎接口连接以生成注册用户值。
在框202B处,系统生成场境参数的当前活动参数的当前值中的当前活动值。当前活动值可以指示环境中是否正在发生一个或多个活动和/或可以指示环境中正在发生一个或多个活动中的哪个(些)。
在框202C处,系统针对场境参数的当前时间参数生成当前值的时间值。
在框204处,系统处理在框202的最近迭代处生成的当前值,以确定基于音频数据的助理处理的目标状态。基于音频数据的助理处理可以是例如热词处理(调用和/或动作热词处理)和/或免调用热词处理。在一些实施方式中,系统处理当前值以生成输出并基于输出满足哪个(些)条件来确定目标状态。例如,第一状态可以与第一输出相关,第二状态与第二输出相关,第三状态与第三输出相关,等等。在一些实施方式中,框204可选地包括框204A和/或204B。在那些实施方式中的一些中,执行框204A,并且如果框204A不满足条件,则执行框204B。
在框204A处,系统使用与状态相关的规则来处理当前值。例如,第一规则可以与第一状态相关,第二规则可以与第二状态相关,第三规则可以与第一状态相关,等等。在框204A,系统可以确定给定状态是响应于确定满足与给定状态相关的规则的目标状态。确定规则被满足可以包括将当前值应用于规则。确定给定状态的条件被满足可以包括确定与给定状态相关的规则被满足。在具有冲突的相关状态的多个规则被满足的情况下,可以利用一种或多种技术来选择一个规则(及其对应的相关状态)而不是其他满足的规则。例如,系统可以选择最近创建的规则或者可以选择最具体的规则(例如,其具有最大数量的场境参数的值或值范围)。
在框204B处,系统使用适配ML模型来处理当前值以生成适配输出。在框204B,系统可以响应于适配输出与给定状态相关来确定给定状态是目标状态。例如,输出可以指示:鉴于当前值,两个或更多个状态中的哪个(些)应该是活动的。确定给定状态被满足的条件可以包括确定输出指示给定状态应该是活动的。
在框206处,系统确定在框204的最近迭代处生成的目标状态是否与助理设备处当前活动的当前状态相同。在一些情况下,当前活动的当前状态可以是在框208的最近一次迭代处最近自动适配的状态(如下所述)。在一些其他情况下,当前活动的当前状态可以是由助理设备的用户通过在助理设备处提供一个或多个显式用户界面输入来手动设置的状态。
如果在框206,系统确定目标状态与当前状态相同,则系统返回框202以执行框202、204和206的另一次迭代。在一些实施方式中,系统立即返回到框202。在一些其他实施方式中,系统在返回到框202之前暂停固定或动态阈值时间量(例如,5秒、30秒或1分钟),然后和/或者在返回到框202之前等待其他条件的发生。例如,其他条件可以是检测话音活动、经由助理设备的无源存在检测器检测存在、和/或基于来自助理设备的相机的图像来检测存在。
如果在框206系统确定目标状态与当前状态不同,则系统进行到框208并且将基于音频数据的助理处理从当前状态自动适配为目标状态。然后系统返回到框202以执行框202、204和206的另一次迭代。在一些实施方式中,系统立即返回到框202。在一些其他实施方式中,系统在返回框202之前暂停固定或动态阈值时间量(例如,5秒、30秒或1分钟)和/或在返回框202之前等待其他条件的发生。
当执行框208的迭代时,系统可选地进行到可选框210。在框210处,系统渲染反映从框208的最近迭代到目标状态的适配的UI输出。例如,UI输出可以包括描述目标状态的文本和/或与目标状态相关(并且与其他状态的图形符号不同)的图形符号。
在可选框212,系统确定是否接收到来自助理设备的用户的反馈。例如,反馈可以是响应于框210处的可选渲染而接收到的用户界面输入。例如,框210处的渲染可以进一步包括视觉地渲染可选择的替代图形元素,每个图形元素反映不是目标状态的对应替代状态。在这样的实例中,反馈可以是用户对替代图形元素中的一个替代图形元素的选择,并且可以是指示应该已经实现对应的替代状态来代替目标状态的负反馈。作为另一实例,反馈可以是用户的主动反馈。例如,主动反馈可以是用户提供指示替代状态的口述输入的负反馈和/或可以是用户在框208的最近迭代的自动适配的阈值持续时间内手动适配至替代状态。作为又一实例,反馈可以是用户确认目标状态是期望状态的正反馈。例如,可以视觉地渲染目标状态的确认可选择图形元素,并且确认可选择图形元素的选择可以指示目标状态对于当前场境值是正确的。如果在框212处没有接收到反馈,则系统可以返回到框212并且继续监视反馈——持续至少阈值持续时间。
如果在可选框212处接收到反馈,则系统可以进行到可选框214。在可选框214处,系统可以使用反馈来适配在框204的最近迭代处使用的适配ML模型和/或规则。可选地,如果反馈是指示替代状态的负反馈,则系统可以附加地或可替代地立即使基于音频数据的处理适配至替代状态。
作为框214的一个示例,系统可以基于反馈生成监督训练示例,并且使用训练示例来进一步训练适配ML模型。作为框214的另一个示例,系统可以使用反馈来删除或适配在框204的最近迭代中确定目标状态时使用的规则。
图3是图示取决于当前活动状态执行调用热词处理的示例方法300的流程图。任何给定时间的当前活动状态可以基于例如来自图2的方法200的框208的最新适配。
为了方便起见,参考执行操作的系统来描述流程图的操作。该系统可以包括各种计算机系统的各种组件,诸如自动化助理客户端120的一个或多个组件。此外,虽然以特定次序示出方法300的操作,但这并不意味着限制。可以重新排序、省略或添加一个或多个操作。
在框302,系统确定调用热词处理的当前状态是否为不活动状态。如果是,则系统执行框302的另一次迭代。如果否,则系统进行到框304。响应于当前状态再次适配至不活动状态,系统可以在任何时间返回到框302。
在框304,系统使用调用热词ML模型处理音频数据,以监视调用热词的发生。框304可选地包括框304A,其中,系统在监视发生时将从处理生成的一个或多个概率与当前状态的阈值进行比较。例如,如果当前活动状态指定特定阈值,则可以利用该特定阈值来确定热词是否发生。例如,第一状态可以指定第一更宽松的阈值,并且第二状态可以指定第二更限制性的阈值。
在框306,系统确定是否存在调用热词的发生。如果不是,则系统返回到框304。如果是,则系统前进到框308。
在框308,系统确定当前状态是否需要验证。例如,如果当前活动状态指定调用热词处理仅对于注册用户或仅对于特定注册用户是活动的,则系统可以确定当前状态需要验证。另一方面,如果当前活动状态指定调用热词处理完全活动,则系统可以确定当前状态不需要验证。
如果在框308,系统确定当前状态不需要验证,则系统进行到框314并且执行进一步的助理处理。如果在框308,系统确定当前状态需要验证,则系统进行到框310。
在框310,系统确定热词是否由当前状态的注册用户说出。在一些实施方式中,框310包括框310A,在框310A中,系统对音频数据中与热词相对应的部分执行TDSID,以确定当前状态的注册用户(即,热词处理对于当前状态的注册用户是活动的)说出了热词。在一些实施方式中,在框310处,系统可以附加地或可替代地执行TISID(例如,对捕获热词的音频数据和/或一个在前和/或在后的音频数据)和/或面部验证(例如,基于捕获说话的用户的图像)来确定热词是否是由当前状态的注册用户说出的。
在框312处,系统确定框310处的确定是否指示热词被验证为由针对当前状态验证的注册用户说出。如果在框312,系统确定当前状态的注册用户没有说出热词(例如,代替地是由访客用户说出),则系统返回到框304,从而抑制框314的任何进一步的助理处理。
如果在框312,系统确定热词是由当前状态的注册用户说出的,则系统进行到框314并且执行进一步的助理处理。
框314可选地包括框314A、框314B和/或框314C。
在框314A处,系统对热词之前和/或热词之后的音频数据执行ASR。执行ASR可以导致对音频数据中捕获的口述话语的辨识,其中,口述话语是除热词之外还有的。
在框314B处,系统对来自ASR的辨识执行NLU,诸如在框314A中执行的ASR或在框314之前执行的ASR(例如,当314A的执行没有被选择性地抑制时)。系统基于执行NLU来生成NLU数据。
在框314C处,系统使得动作基于来自NLU的NLU数据来被执行,诸如在框314B中执行的或在框314之前执行的NLU(例如,当框314B的执行未被选择性地抑制时)。
在可选框316处,系统确定指示当前状态正确和/或不正确的用户反馈是否被接收到。例如,如果用户对从框314的进一步的助理处理执行的动作有肯定响应和/或进一步参与该动作,这可以指示当前状态是正确的(即,意图执行调用热词处理)。另一方面,如果用户通过中间用户界面输入(例如,讲出“取消”或选择“取消”用户界面元素)对框314的进一步的助理处理有否定响应和/或停止框314的进一步的助理处理,则这可以指示当前状态不正确(即,不意图执行调用热词处理)。
如果在框316处没有接收到反馈,则系统可以返回到框316并且继续监视反馈——持续至少阈值持续时间。
如果在可选框316接收到反馈,则系统可以进行到可选框318。在可选框318,系统可以使用反馈来适配在导致当前状态的框204(图2的方法200)的最近迭代处使用的适配ML模型和/或规则。可选地,如果反馈是指示替代状态的负反馈,则系统可以附加地或可替代地立即使基于音频数据的处理适配至替代状态。作为框318的一个示例,系统可以基于反馈生成监督训练示例,并且使用训练示例来进一步训练适配ML模型。作为框318的另一个示例,系统可以使用反馈来删除或适配在框204的最近迭代中确定目标状态时使用的规则。
图4是图示取决于当前活动状态执行动作热词处理的示例方法400的流程图。任何给定时间的当前活动状态可以基于例如来自图2的方法200的框208的最近适配。
为了方便起见,参考执行操作的系统来描述流程图的操作。该系统可以包括各种计算机系统的各种组件,诸如自动化助理客户端120的一个或多个组件。此外,虽然以特定次序示出方法400的操作,但这并不意味着限制。可以重新排序、省略或添加一个或多个操作。
在框402,系统确定调用热词处理的当前状态是否为不活动状态。如果是,则系统执行框402的另一次迭代。如果否,则系统进行到框404。响应于当前状态被再次适配至不活动状态,系统可以在任何时间返回到框402。
在框404处,系统使用动作热词ML模型来处理音频数据,以监视动作热词的发生。框404可选地包括框404A,其中,系统在监视发生时将从处理生成的一个或多个概率与当前状态的阈值进行比较。例如,如果当前活动状态指定特定阈值,则可以利用该特定阈值来确定动作热词是否发生。例如,第一状态可以指定第一更宽松的阈值,并且第二状态可以指定第二更限制性的阈值。
在框406,系统确定是否存在动作热词的发生。如果不是,则系统返回到框404。如果是,则系统前进到框408。
在框408,系统确定当前状态是否需要验证。例如,如果当前活动状态指定调用热词处理仅对于注册用户或仅对于特定注册用户是活动的,则系统可以确定当前状态需要验证。另一方面,如果当前活动状态指定调用热词处理完全活动,则系统可以确定当前状态不需要验证。
如果在框408,系统确定当前状态不需要验证,则系统进行到框414并且执行进一步的助理处理。如果在框408,系统确定当前状态需要验证,则系统进行到框410。
在框410,系统确定热词是否由当前状态的注册用户说出。在一些实施方式中,框410包括框410A,其中,系统对与动作热词相对应的音频数据的部分执行TDSID和/或TISID,以确定当前状态(即,热词处理对于当前状态的注册用户来说是活动的)的注册用户是否说出了活动热词。在一些实施方式中,在框410处,系统可以附加地或可替代地利用面部验证(例如,基于捕获讲话用户的图像)来确定动作热词是否是由当前状态的注册用户说出的。
在框412处,系统确定框410处的确定是否指示动作热词被验证为由针对当前状态验证的注册用户说出。如果在框412,系统确定当前状态的注册用户没有说出热词(例如,代替地由访客用户说出),则系统返回到框404,从而抑制框414的任何进一步的助理处理。
如果在框412系统确定热词是由当前状态的注册用户说出的,则系统进行到框414并且执行进一步的助理处理。
框414可选地包括框414A,其中,系统执行直接映射到检测到的动作热词的动作。例如,如果动作热词是“播放音乐”,则动作可以包括使得本地存储的音乐被播放或者使得流式传输音乐会话利用远程音乐流式传输服务来被发起。
在可选框416处,系统确定是否接收到指示当前状态正确和/或不正确的用户反馈。例如,如果用户对从框414的进一步的助理处理执行的动作有肯定响应和/或进一步参与该动作,这可以指示当前状态是正确的(即,意图执行调用热词处理)。另一方面,如果用户通过中间用户界面输入(例如,讲出“取消”或选择“取消”用户界面元素)对框414的进一步的助理处理有否定响应和/或停止框414的进一步的助理处理,则这可以指示当前状态不正确(即,不意图执行调用热词处理)。
如果在框416处没有接收到反馈,则系统可以返回到框416并且继续监视反馈——持续至少阈值持续时间。
如果在可选框416接收到反馈,则系统可以进行到可选框418。在可选框418,系统可以使用反馈来适配导致当前状态的框204(图2的方法200)的最近迭代使用的适配ML模型和/或规则。可选地,如果反馈是指示替代状态的负反馈,则系统可以附加地或可替代地立即使基于音频数据的处理适配至替代状态。作为框418的一个示例,系统可以基于反馈生成监督训练示例,并且使用训练示例来进一步训练适配ML模型。作为框418的另一个示例,系统可以使用反馈来删除或适配在框204的最近迭代中确定目标状态时使用的规则。
图5是图示取决于当前活动状态执行免调用语音处理的示例方法500的流程图。任何给定时间的当前活动状态可以基于例如来自图2的方法200的框208的最近适配。
为了方便起见,参考执行操作的系统来描述流程图的操作。该系统可以包括各种计算机系统的各种组件,诸如自动化助理客户端120的一个或多个组件。此外,虽然以特定次序示出方法500的操作,但这并不意味着限制。可以重新排序、省略或添加一个或多个操作。
在框502,系统确定调用热词处理的当前状态是否为不活动状态。如果是,则系统执行框502的另一次迭代。如果否,则系统进行到框504。响应于当前状态再次被适配至不活动状态,系统可以在任何时间返回到框502。
在框504处,系统使用助理设备本地的ASR模型来处理音频数据,以尝试生成针对音频数据中捕获的任何口述话语的辨识结果。在一些实施方式中,系统连续地执行框504。在其他实施方式中,系统响应于检测话音活动(例如,使用话音活动检测器)和/或响应于其他条件被满足来执行框504。
在框506处,系统根据框504的处理确定是否存在ASR辨识。如果没有,则系统返回到框504。如果有,则系统前进到框508。
在框508,系统确定当前状态是否需要验证。例如,如果当前活动状态指定免调用处理仅对于注册用户或仅对于特定注册用户是活动的,则系统可以确定当前状态需要验证。另一方面,如果当前活动状态指定免调用处理完全活动,则系统可以确定当前状态不需要验证。
如果在框508,系统确定当前状态不需要验证,则系统前进到框514。如果在框508,系统确定当前状态需要验证,则系统前进到框510。
在框510处,系统确定与框506的最近迭代的辨识相对应的口述话语是否是由当前状态的注册用户说出的。在一些实施方式中,框510包括框510A,其中,系统对音频数据的与口述话语相对应的部分执行TISID,以确定当前状态的注册用户(即,热词处理对于当前状态的注册用户是活动的)是否说出了口述话语。在一些实施方式中,在框510处,系统可以附加地或可替代地利用面部验证(例如,基于捕获讲话用户的图像)来确定口述话语是否是由当前状态的注册用户说出的。
在框512处,系统确定框510处的确定是否指示口述话语被验证为由针对当前状态验证的注册用户说出。如果在框512处,系统确定口述话语不是由当前状态的注册用户说出的(例如,代替地由访客用户说出的),则系统返回到框504,从而抑制框518的任何进一步的助理处理。
如果在框512,系统确定口述话语是由当前状态的注册用户说出的,则系统前进到框514。
在框514处,系统确定框506的最近迭代的辨识是否是助理命令。在一些实施方式中,框514包括框514A,其中,系统使用助理命令ML模型来处理音频数据(与口述话语相对应)、口述话语的辨识和/或NLU数据,以生成输出。此外,系统将输出与阈值进行比较以确定辨识是否是助理命令。例如,助理命令ML模型可以被训练来处理辨识(例如,辨识的词嵌入)和音频数据的特征,以生成输出,该输出是指示辨识是否是助理命令的概率。该概率可以与阈值进行比较。在一些实施方式中,阈值是特定于当前状态的阈值。例如,如果当前活动状态指定特定阈值,则该特定阈值可以被利用来确定动作热词是否发生。例如,第一状态可以指定第一更宽松的阈值,并且第二状态可以指定第二更限制性的阈值。
在框516处,系统确定框514处的确定是否指示辨识是助理命令。如果否,则系统返回到步骤504。如果是,则系统前进到步骤518并且执行进一步的助理处理。
在框518处,系统执行进一步的助理处理。在一些实施方式中,框518包括框518A,其中,系统对辨识执行NLU和/或使得动作被执行(例如,基于来自框518A的NLU和/或先前执行的NLU的NLU数据)。
在可选框520,系统确定是否接收到指示当前状态正确和/或不正确的用户反馈。例如,如果用户对从框514的进一步的助理处理执行的动作有肯定响应和/或进一步参与所述动作,这可以指示当前状态是正确的(即,意图执行免调用处理)。另一方面,如果用户通过中间用户界面输入(例如,讲出“取消”或选择“取消”用户界面元素)对框414的进一步的助理处理有否定响应和/或停止框414的进一步的助理处理,则这可以指示当前状态不正确(即不意图执行免调用处理)。
如果在框520处没有接收到反馈,则系统可以返回到框416并且继续监视反馈——持续至少阈值持续时间。
如果在可选框520处接收到反馈,则系统可以前进到可选框522。在可选框418处,系统可以使用反馈来适配导致当前状态的框204(图2的方法200)的最近迭代使用的适配ML模型和/或规则。可选地,如果反馈是指示替代状态的负反馈,则系统可以附加地或可替代地立即使基于音频数据的处理适配至替代状态。
注意,在一些实施方式中,助理设备仅执行方法300、方法400和方法500中的一个方法。在一些其他实施方式中,助理设备可以执行方法300、方法400和方法500中的多个方法。在方法300、方法400和方法500中的多个方法被执行的实施方式中,它们都可以基于方法200的相同实例,或者可替代地,一个或多个可以基于方法200的其自己的实例。例如,当基于方法200的相同实例时,相同的适配将被应用于方法300、400和500中的每个方法。例如,如果调用热词处理处于第一状态,则免调用处理也将处于相同的第一状态。当一个或多个基于方法200的其自己的实例时,不同的适配将至少选择性地被应用在方法300、400和500的不同方法中。例如,方法200的第一实例可以利用特定于调用热词处理并且可用于适配调用热词处理的状态(例如,用于仅适配调用热词处理的状态)的适配机器学习模型和/或规则。此外,方法200的第二实例可以利用特定于免调用处理并且可以用于适配免调用处理的状态(例如,用于仅适配免调用处理的状态)的适配机器学习模型和/或规则。因此,在这样的情况下,调用热词处理可以处于第一状态(例如,完全活动状态),并且调用费用处理可以同时处于不同的第二状态(例如,部分活动状态)。
图6A、6B、6C、6D和6E图示了示例助理设备610和助理设备610在显示器614上视觉地渲染反映基于音频数据的助理处理的当前自动适配状态的用户界面输出以及渲染反馈用户界面元素的示例。
图6A图示了渲染图形界面的助理设备610,该图形界面包括指示热词处理已经自动适配至完全不活动状态的界面元素691A。进一步地,图6A包括第一可选择元素692A和第二可选择元素693A。第一可选择元素692A可以被选择,并且响应于选择,热词处理可以被切换到完全活动状态和/或该选择可以被用作例如训练本文所述的适配ML模型中的反馈。第二可选择元素693A可以被选择,并且响应于选择,热词处理可以被切换到部分活动状态(例如,仅针对注册用户而被激活)和/或该选择可以被用作在例如训练本文所述的适配ML模型中的反馈。
图6B图示了渲染图形界面的助理设备610,该图形界面包括指示热词处理已经自动适配至部分活动状态的界面元素691B。进一步地,图6B包括第一可选择元素692B和第二可选择元素693B。第一可选择元素692B可以被选择,并且响应于选择,热词处理可以被切换到完全活动状态和/或该选择可以被用作例如训练本文所述的适配ML模型中的反馈。第二可选择元素693B可以被选择,并且响应于选择,热词处理可以被切换到不活动状态和/或该选择可以被用作例如训练本文所述的适配ML模型中的反馈。
图6C图示呈现图形界面的助理设备610,该图形界面包括界面元素691C,界面元素691C指示免调用处理已经被自动适配至不活动状态,并且指示其基于“晚餐规则”被自动适配至不活动状态。进一步地,图6C包括第一可选择元素692C和第二可选择元素693C。第一可选择元素692C可以被选择,并且响应于选择,免调用处理可以被切换到完全活动状态或部分活动状态。第二可选元素693C可以被选择,并且响应于选择,进一步的界面可以被呈现,其使得用户能够提供输入以删除和/或细化晚餐规则(例如,细化规则的时间条件)。
图6D图示了渲染图形界面的助理设备610,该图形界面包括指示基于音频数据的处理(例如,热词处理和/或免调用处理)已经被自动适配至较低阈值状态的界面元素691D。进一步地,图6D包括第一可选择元素692D,其可以被选择,并且响应于选择,基于音频数据的处理可以被切换到较高阈值状态和/或该选择可以用作例如训练本文所述的适配ML模型中的反馈。
图6E图示了渲染图形界面的助理设备610,该图形界面包括界面元素691E,该界面元素691E指示基于音频数据的处理(例如,热词处理和/或免调用处理)已经被自动适配至针对注册用户和访客用户的较高阈值状态。进一步地,图6E包括第一可选择元素692E和第二可选择元素692E。第一可选择元素692E可以被选择,并且响应于选择,基于音频数据的处理可以被切换到针对注册用户和访客用户的较低阈值状态。第二可选择元素693E可以被选择,并且响应于选择,基于音频数据的处理可以被切换到仅针对注册用户的较低阈值状态(即,对于访客用户维持在较高阈值状态)。元素692E或693E的选择还可以用作例如训练本文所述的适配ML模型中的反馈。
图7是可以可选地用来执行本文描述的技术的一个或多个方面的示例计算设备710的框图。在一些实施方式中,客户端计算设备中的一个或多个和/或其他组件可以包括示例计算设备710的一个或多个组件。
计算设备710通常包括至少一个处理器714,其经由总线子系统712与多个外围设备通信。这些外围设备可以包括存储子系统724,包括例如存储器子系统725和文件存储子系统726、用户界面输出设备720、用户界面输入设备722和网络接口子系统716。输入和输出设备允许用户与计算设备710交互。网络接口子系统716提供到外部网络的接口并且耦合到其他计算设备中的对应的接口设备。
用户界面输入设备722可以包括键盘、诸如鼠标、轨迹球、触摸板或图形输入板的指示设备、扫描仪、并入显示器中的触摸屏、诸如话音辨识系统、麦克风的音频输入设备、和/或其他类型的输入设备。一般而言,术语“输入设备”的使用意图包括将信息输入到计算设备710或通信网络上的所有可能类型的设备和方式。
用户界面输出设备720可以包括显示子系统、打印机、传真机或非视觉显示器,诸如音频输出设备。显示子系统可以包括阴极射线管(“CRT”)、诸如液晶显示器(“LCD”)的平板设备、投影设备或用于创建可见图像的某种其他机构。显示子系统还可以诸如经由音频输出设备来提供非视觉显示。一般而言,术语“输出设备”的使用意图包括将信息从计算设备710输出到用户或另一机器或计算设备的所有可能类型的设备和方式。
存储子系统724存储提供本文描述的一些或所有模块的功能的编程和数据构造。例如,存储子系统724可以包括用于执行本文所述的方法的一个或多个方法的所选择方面和/或实现本文描绘的各种组件的逻辑。
这些软件模块通常由处理器714单独执行或与其他处理器组合执行。存储子系统724中使用的存储器725可以包括多个存储器,包括用于在程序执行期间存储指令和数据的主随机存取存储器(“RAM”)730和其中固定指令被存储的只读存储器(“ROM”)732。文件存储子系统726可以为程序和数据文件提供持久存储,并且可以包括硬盘驱动器、软盘驱动器以及相关联的可移动介质、CD-ROM驱动器、光盘驱动器或可移动介质盒。实现某些实施方式的功能性的模块可以由文件存储子系统726存储在存储子系统724中,或者存储在可由处理器714访问的其他机器中。
总线子系统712提供用于使得计算设备710的各种组件和子系统按意图彼此通信的机制。尽管总线子系统712被示意性地示出为单个总线,但是总线子系统的替代实施方式可以使用多个总线。
计算设备710可以是不同的类型,包括工作站、服务器、计算集群、刀片服务器、服务器场、或任何其他数据处理系统或计算设备。由于计算机和网络的不断改变的性质,对图7中描绘的计算设备710的描述仅意图作为用于说明一些实施方式的目的的具体示例。计算设备710的许多其他配置可能具有比图7中描绘的计算设备更多或更少的组件。
在本文描述的系统收集关于用户(或本文中经常提到的“参与者”)的个人信息或可以使用个人信息的情况下,可以向用户提供机会来控制是否程序或功能收集用户信息(例如,有关用户的社交网络、社交动作或活动、职业、用户偏好或用户当前地理位置的信息),或控制是否和/或如何从内容服务器接收可能与用户更相关的内容。此外,某些数据在存储或使用之前可能会以一种或多种方式进行处理,以便移除个人身份信息。例如,可以处理用户的身份,以便无法确定该用户的个人身份信息,或者可以在获取地理位置信息时概括用户的地理位置(诸如至城市、邮政编码或州级别),从而无法确定用户的特定地理位置。因此,用户可以控制如何收集和/或使用关于用户的信息。
在一些实施方式中,提供了一种由处理器实现的方法,其包括:在第一时间处理第一值,并且响应于在第一时间的处理满足一个或多个第一条件:将在助理设备本地执行的基于特定音频数据的助理处理从在第一时间处活动的第一状态自动适配到第二状态。在第一时间处处理的第一值用于第一时间处的动态场境参数。该方法进一步包括在第二时间处理第二值,并且响应于在第二时间处的处理满足一个或多个第二条件:使在助理设备本地执行的基于特定音频数据的助理处理自动适配至第三状态。至第三状态的适配是来自第一状态或第二状态中的一个状态,并且第一状态或第二状态中的一个状态在第二时间处是活动的。第二值用于第二时间处的动态场境参数。
本文公开的这些和其他实施方式可以包括以下特征中的一个或多个。
在一些实施方式中,第一状态是以下中的一个:(a)完全活动状态,其中,对于向助理设备注册的一个或多个注册用户完全执行基于特定音频数据的助理处理,并且对于未向助理设备注册的任何用户也完全执行基于特定音频数据的助理处理;(b)部分活动状态,其中,对于一个或多个注册用户中的至少一些注册用户,完全执行基于特定音频数据的助理处理,但是对于未在助理设备上注册的任何用户抑制基于特定音频数据的助理处理的至少一部分;以及,(c)不活动状态,其中,基于特定音频数据的助理处理的至少一部分对于一个或多个注册用户被抑制并且对于未向助理设备注册的任何用户也被抑制。在那些实施方式的一些版本中,第二状态是以下中的另一个:(a)完全活动状态、(b)部分活动状态、以及(c)不活动状态,并且可选地,第三状态是以下中的剩余状态:(a)完全活动状态,(b)部分活动状态,以及(c)不活动状态。在那些版本的一些热词实施方式中,基于特定音频数据的助理处理是热词处理,并且热词处理包括:使用助理设备的一个或多个本地热词模型来处理音频数据流,以监视热词的发生,音频数据流经由助理设备的至少一个麦克风来被检测;以及,使得基于检测音频数据流中热词的发生进行进一步的助理处理。在热词实施方式的一些版本中,在部分活动状态下,对于未向助理设备注册的任何用户,通过使得进一步的助理处理进一步基于以下内容来被执行来抑制基于特定音频数据的助理处理:验证热词由一个或多个注册用户中的一个注册用户说出。在那些版本的一些版本中,验证热词由一个或多个注册用户中的一个注册用户说出包括:使用依赖文本的说话人识别(TDSID)模型处理捕获热词的音频数据流的至少一部分;以及,验证使用基于处理的TDSID模型生成的输出与一个或多个注册用户中的一个注册用户的存储的TDSID嵌入相匹配。在热词实施方式的一些版本中,热词是用于调用自动化助理的助理热词。在那些版本中的一些版本中,进一步的助理处理包括:对捕获口述话语并且在音频数据流中的热词之后和/或之前的音频数据执行语音辨识,以生成口述话语的辨识;对辨识执行自然语言理解,以生成自然语言理解数据;以及/或者,使得一个或多个动作基于自然语言理解数据来被执行。在热词实施方式的一些版本中,热词是用于经由自动化助理直接调用特定动作的动作热词,并且,进一步处理包括由自动化助理使得基于检测音频数据流中热词的发生来执行特定动作。在热词实施方式的一些版本中,热词是用于经由自动化助理直接调用特定第三方应用的第三方助理应用热词,并且,进一步的处理包括通过自动化助理使得特定第三方助理应用基于检测到音频数据流中热词的发生而被调用。在那些版本的一些免调用实施方式中,基于特定音频数据的助理处理是免调用语音辨识处理,免调用语音辨识处理包括:使用助理设备的一个或多个本地语音辨识模型对捕获口述话语的音频数据执行语音辨识,以生成对口述话语的辨识;基于对辨识的处理,确定口述话语是否是助理命令;以及,使得进一步的助理处理基于口述话语被确定为助理命令来被执行。在免调用实施方式的一些版本中,在部分活动状态下,通过使得进一步的助理处理进一步基于以下内容被执行,来对于未向助理设备注册的任何用户抑制基于特定音频数据的助理处理:验证口述话语是由一个或多个注册用户中的一个注册用户说出。在那些版本的一些版本中,验证口述话语是由一个或多个注册用户中的一个注册用户说出包括:使用不依赖文本的说话人识别(TISID)模型来处理捕获口述话语的音频数据的至少一部分;以及,验证使用基于处理的TISID模型生成的输出与一个或多个注册用户中的一个注册用户的存储的TISID嵌入相匹配。在免调用实施方式的一些版本中,进一步的助理处理包括:使得一个或多个动作基于辨识被执行。
在一些实施方式中,第一状态是以下中的一个:(a)第一阈值状态,其中,一个或多个第一阈值用于基于特定音频数据的助理处理;(a)第二阈值状态,其中,一个或多个第二阈值用于基于特定音频数据的助理处理;以及,(c)不活动状态,其中,针对一个或多个注册用户抑制特定音频数据处理,并且针对未向助理设备注册的任何用户抑制特定音频数据处理。在那些实施方式的一些版本中,第二状态是以下中的另一个:(a)第一阈值状态、(b)第二阈值状态和(c)不活动状态;以及/或者其中,第三状态是以下中的剩余:(a)第一阈值状态、(b)第二阈值状态和(c)不活动状态,以及可选地,第三状态状态是以下中的剩余:(a)第一阈值状态、(b)第二阈值状态和(c)不活动状态。在那些版本的一些热词实施方式中,基于特定音频数据的助理处理是热词处理,热词处理包括:使用助理设备的一个或多个本地热词模型来处理音频数据流,以监视热词的发生,经由助理设备的至少一个麦克风来检测音频数据流;以及,使得进一步的助理处理基于检测音频数据流中热词的发生而被执行。在那些热词实施方式的一些版本中,在第一阈值状态下,将基于处理音频数据流使用一个或多个本地热词模型生成的值与一个或多个第一阈值中的第一阈值进行比较,以确定是否在音频数据流中检测到热词,并且在第二阈值状态下,将基于处理音频数据流使用一个或多个本地热词模型生成的值与一个或多个第二阈值中的第二阈值进行比较,以确定是否在音频数据流中检测到热词。在那些版本的一些免调用实施方式中,特定音频数据处理是免调用语音辨识处理,该免调用语音辨识处理包括:对捕获口述话语的音频数据执行语音辨识并且使用助理设备的一个或多个本地语音辨识模型,以生成对口述话语的辨识;基于对辨识的处理,确定所述口述话语是否是助理命令;以及使得进一步的助理处理基于所述口述话语被确定为助理命令来被执行。在免调用实施方式的一些版本中,在第一阈值状态中,将在确定口述话语是否是助理命令时生成的值与一个或多个第一阈值中的第一阈值进行比较,并且在第二阈值状态中,将在确定口述话语是否是助理命令时生成的值与一个或多个第二阈值中的第二阈值进行比较。
在一些实施方式中,动态场境参数包括:注册用户参数,其指示一个或多个注册用户是否存在于助理设备的环境中和/或指示该一个或多个注册用户中的哪个(些)在助理设备的环境中;当前活动参数,其指示环境中是否正在发生一个或多个活动和/或指示环境中正在发生一个或多个活动中的哪个(些);以及/或者,指示一个或多个当前时间条件的时间参数。在那些实施方式的一些版本中,动态场境参数包括注册用户参数。在那些版本中的一些中,注册用户参数的第一值中的第一注册用户值基于检测到一个或多个注册用户中的给定注册用户在第一时间存在于环境中。检测给定的注册用户存在可以可选地包括:(a)基于在助理设备处对在助理设备处检测到的音频数据的处理来执行基于话音的说话者识别,和/或(b)基于在助理设备处处理在助理设备处检测到的视觉数据来执行基于视觉的辨识。在那些实施方式的一些附加或替代版本中,动态场境参数包括当前活动参数。在那些附加或替代版本中的一些中,当前活动用户参数的第一值中的第一当前活动值基于确定给定活动当前正在发生。检测给定活动当前正在发生可以可选地包括:(a)基于在助理设备处对在助理设备处检测到的音频数据的处理来执行基于音频的活动识别,和/或(b)访问一个或多个注册用户的日历信息。
在一些实施方式中,在第一时间处理第一值包括:使用训练的适配机器学习模型来处理第一值以生成适配输出。在那些实施方式的一些版本中,第一时间满足一个或多个第一条件的处理包括满足一个或多个第一条件的适配输出。在那些版本的一些实施方式中,适配输出包括至少一个概率,并且满足一个或多个第一条件的适配输出包括满足第一阈值的概率。在那些版本的一些附加和/或可替代实施方式中,响应于对第一状态、第二状态和/或第三状态的先前自动适配,至少部分地基于在助理设备处检测到的隐式或显式用户反馈来训练经过训练的适配机器学习模型。
在一些实施方式中,一个或多个第一条件中的至少给定第一条件是基于来自助理设备的注册用户的用户界面输入的一个或多个先前实例来确定的,该用户界面输入明确地指示给定第一条件。
在一些实施方式中,该方法进一步包括:识别与助理设备链接的附加助理设备;响应于第一时间的处理满足一个或多个第一条件:将在附加助理设备处本地执行的基于特定音频数据的助理处理从在第一时间在附加助理设备处活动的第一状态自动地适配至第二状态;以及,响应于第二时间的处理满足一个或多个第二条件:使在附加助理设备本地执行的基于特定音频数据的助理处理自动适配到第三状态。到第三状态的适配是来自第一状态或第二状态中的一个状态,其中,第一状态或第二状态中的一个状态在第二时间在附加助理设备处是活动的。
在一些实施方式中,该方法进一步包括:使得助理设备提供:响应于对第一状态的适配的第一接口输出、响应于对第一状态的适配的第二接口输出、和/或响应于对于第一状态的适配的第三接口输出。在那些实施方式中的一些实施方式中,第一接口输出响应于对第一状态的适配来被提供,并且第一接口输出贯穿第一状态的持续时间内持续。
在一些实施方式中,响应于基于特定音频数据的助理处理向第一状态的先前自动适配,第一状态在第一时间是活动的。在那些实施方式中的一些实施方式中,将基于特定音频数据的助理处理自动地适配到第三状态是来自第二状态,并且响应于在第一时间向第二状态的适配,第二状态在第二时间是活动的。
在一些实施方式中,第二状态是阈值状态,其中:对于向助理设备注册的一个或多个注册用户,对于基于特定音频数据的助理处理,使用一个或多个第一阈值,并且对于未向助理设备注册的任何用户,对于基于特定音频数据的助理处理,使用一个或多个第二阈值。
在一些实施方式中,提供了一种由处理器实现的方法,其包括:在第一时间处理动态场境参数的第一值,并且响应于在第一时间的处理满足一个或多个第一条件:将在助理设备处本地执行的基于特定音频数据的助理处理从在第一时间活动的第一状态自动地适配到第二状态。第一值用于第一时间处的动态场境参数。第一状态是以下中的一个:(a)完全活动状态,其中,针对向助理设备注册的一个或多个注册用户完全执行基于特定音频数据的助理处理,并且还针对未向助理设备注册的任何用户完全执行基于特定音频数据的助理处理;以及,(b)部分活动状态,其中,对于一个或多个注册用户中的至少一些完全执行基于特定音频数据的助理处理,但是对于未向助理设备上注册的任何用户抑制基于特定音频数据的助理处理的至少一部分。第二状态是(a)完全活动状态和(b)部分活动状态中的另一个。
在一些实施方式中,提供了一种由处理器实现的方法,其包括:在第一时间处理动态场境参数的第一值,并且响应于在第一时间的处理满足一个或多个第一条件:将在助理设备处本地执行的基于特定音频数据的助理处理从在第一时间活动的第一状态自动地适配到第二状态。第一值用于第一时间处的动态场境参数。第一状态是以下中的一个:(a)第一阈值状态,其中,一个或多个第一阈值用于基于特定音频数据的助理处理;以及(b)第二阈值状态,其中,一个或多个第二阈值用于基于特定音频数据的助理处理。第二状态是(a)完全活动状态和(b)部分活动状态中的另一个。
此外,一些实施方式可以包括一种系统,该系统包括一个或多个计算设备(例如,助理设备),每个计算设备具有一个或多个处理器以及与所述一个或多个处理器可操作地耦合的存储器,其中,所述一个或多个计算设备的存储器存储指令,所述指令响应于由一个或多个计算设备的一个或多个处理器执行,使一个或多个处理器执行本文描述的任何方法。一些实施方式还包括至少一种非暂时性计算机可读介质,其包括指令,其响应于一个或多个处理器对指令的执行,使得该一个或多个处理器执行本文描述的方法中的任一种方法。
- 动态地适配分组助理设备的设备上模型以用于助理请求的协作处理
- 基于检测到的嘴运动和/或凝视的适配自动助理