一种精确敲除鸡NHE1基因W38位氨基酸的细胞系构建方法
文献发布时间:2023-06-19 12:05:39
技术领域
本发明属于基因工程技术领域,涉及到一种精确敲除鸡NHE1基因W38位氨基酸的细胞系构建方法,具体为一种基于CRISPR-Cas9编辑技术的精确敲除鸡 NHE1基因W38位氨基酸的细胞系构建方法。
背景技术
CRISPR-Cas系统最早发现于细菌的天然免疫系统,用于对抗病毒的入侵和外源DNA。其中Ⅱ型CRISPR-Cas系统运用最为广泛,主要由RNA导向的Cas9核酸内切酶、一条导向RNA(sgRNA)和反式激活RNA(tracrRNA)组成。在这一系统中,crRNA(CRISPR-derived RNA)通过碱基配对与tracrRNA结合形成双链RNA,引导Cas9蛋白到靶序列上,在PAM序列上游3bp位置特异性剪切DNA 双链,造成DNA双链断裂(DSB,double strand break),从而启动细胞内的DNA 损伤修复机制,导致修复后发生碱基缺失或插入,达到移码突变的效果,最终实现基因敲除的目的。目前该技术已经成熟的运用于真核细胞的基因组编辑中。
Na+/H+离子交换蛋白-1(Sodium/hydrogen exchanger 1,NHE1)是存在于细胞膜表面的离子转运泵蛋白家族的一员。NHE1具有维持细胞内pH值等内环境稳定以及调控宿主细胞的凋亡和增殖的重要功能,也是首个被鉴定的J亚群禽白血病病毒(Avian leukosisvirus,ALV-J)的细胞受体,该蛋白存在于所有真核细胞膜上。ALV-J的Env可特异性的结合鸡NHE1位于细胞外环-1 (Loop-1)的28-39位氨基酸,并以此介导ALV-J的入侵及感染,而对ALV-J 不易感的禽类NHE1的W38氨基酸存在变异或缺失。本研究通过CRISPR/Cas9技术,药物筛选后通过亚克隆的方法,成功获得鸡源NHE1基因W38位精确敲除的 DF-1细胞株delW38-NHE1,且发现delW38-NHE1细胞系能够有效封闭ALV-J的感染。本发明为探究NHE1基因W38氨基酸生物学功能,解析NHE1基因W38位点与ALV-J互作分子机制以及为构建抗ALV-J转基因鸡与抗病毒药物开发打下了基础,具有良好的应用研究价值。
发明内容
本发明的目的是针对上述现有问题,提供一种精确敲除鸡NHE1基因W38位氨基酸的细胞系构建方法。
本发明的目的是通过以下技术方案实现的,一种精确敲除鸡NHE1基因W38 位氨基酸的细胞系构建方法,其特征在于,包括以下步骤:
步骤1)、构建一种特异性靶向鸡NHE1基因W38位的sgRNA,所述的sgRNA位于鸡NHE1基因的第一个外显子区域,且靶序列唯一;
步骤2)、准备一种用于靶向敲除鸡NHE1基因W38位的CRISPR-Cas9系统, CRISPR-Cas9系统中含有Cas9蛋白和上述特异性靶向鸡NHE1基因W38位的sgRNA,或者含有携带编码Cas9蛋白的编码序列和编码sgRNA的编码序列;CRISPR-Cas9 系统中,Cas9蛋白的编码序列与sgRNA的编码序列位于同一质粒上,所述的质粒为lentiCRISPR v2;
步骤3)、合成以pUC57为骨架,含有缺失NHE1基因W38位所需的供体质粒,并命名为:pUC57-delW38;
步骤4)、将步骤1)构建的特异性靶向敲除鸡NHE1基因W38位的sgRNA克隆至带有Cas9基因的lentiCRISPR v2质粒,并将lentiCRISPR v2质粒与步骤3)构建的供体质粒pUC57-delW38共同转染至细胞中;
利用CRISPR-Cas9系统达到基因位点精准敲除,通过药物筛选和亚克隆的方法最后获得阳性单克隆细胞株,从而获得鸡源NHE1基因W38位敲除细胞系。
步骤1)中,对鸡NHE1基因设计了1条sgRNA,所述sgRNA靶位点位于NHE-1基因的第一个外显子区域,该外显子序列如SEQ ID NO.1所示;
所述的特异性靶向鸡NHE1基因W38位的sgRNA编码链及互补链;其序列如SEQ IDNO.2所示。
步骤1)中,靶向鸡NHE1基因的sgRNA制备方法,包括将合成的sgRNA编码链和互补链退火形成双链DNA,之后通过BsmBⅠ限制性内切酶酶切载体,将双链DNA 置于T7启动子之下构建获得。
步骤3)中,对鸡NHE1蛋白设计了缺失W38位点的模板供体质粒,所述缺失位点位于NHE1基因的第一个外显子区域,该供体质粒序列如SEQ ID NO.3所示。
步骤4)中,所述的细胞系为敲除鸡NHE1基因W38位点的细胞系。
本发明方法先进科学,通过本发明,本发明首先提供了一种特异性靶向鸡 NHE1基因W38位点的sgRNA,所述sgRNA位于鸡NHE-1基因的第一个外显子区域,且靶序列唯一,本发明所述sgRNA针对鸡NHE1基因的W38位点,其序列如SEQ ID NO.2所示。
本发明提供了一种用于靶向敲除鸡NHE1基因W38位点的CRISPRCas9系统,在所述的系统中含有Cas9蛋白和上述特异性靶向鸡NHE1基因W38位点的sgRNA,或者含有携带编码Cas9蛋白的编码序列和编码sgRNA的编码序列。
敲除的具体操作如下:
(1)利用NCBI在线数据库查找鸡NHE1基因组序列
NCBI Reference Sequence:NM_001044643.1
在该基因的第一个外显子区域设计敲除靶位点,第一个外显子的序列如SEQ IDNO.1所示。
(2)sgRNA的构建:设计好的sgRNA编码链和互补链分别命名为sgRNA_F和sgRNA_R,把引物稀释至100uM浓度,体系如下:sgRNA_F和sgRNA_R各1uL,PCR buffer 1μL,ddw 7μL,退火程序为5℃/min梯度降温至25℃,获得双链DNA。另一方面,利用BsmBI限制性内切酶酶切lentiCRISPR v2载体,酶切体系如下: BsmBI限制性内切酶1μL,lentiCRISPR v2质粒1μg,0.1M DTT 0.5μL,NEB buffer3.1 5μL,其余用ddw补至50μL,酶切条件为55℃15min,之后通过跑胶后胶回收获得含有粘性末端的lentiCRISPR v2载体质粒。最后,将获得的sgRNA与酶切后的载体质粒通过连接酶连接,最终将sgRNA放入lentiCRISPR v2质粒中,获得sgRNA和Cas9蛋白基因位于同一载体的质粒,命名为NHE1-sgRNA。
(3)缺失NHE1基因W38位点所需的供体质粒的合成:由金唯智公司合成以 pUC57为骨架,含有缺失NHE1-W38所需的供体质粒,并命名为:pUC57-delW38,其中修复模板序列如SEQ ID NO.3。
(4)敲除细胞系的获得:6孔板中转染构建好的NHE1-sgRNA和pUC57-delW38 各2μg,设立不转染的细胞作对照。48h后加入含有嘌呤霉素的培养基进行药物筛选,每3天换药1次,待阴性对照细胞全部死亡后,换成不含药物的完全培养基,存活的细胞生长至适当密度后,利用有限稀释法进行亚克隆至96孔板中,待细胞生长至足够数量时进行鉴定,之后冻存阳性细胞。
通过本发明,为构建一个鸡源NHE1基因W38位敲除的细胞系,提供一种基于CRISPR-Cas9编辑技术的敲除鸡NHE1基因W38位氨基酸的细胞系构建方法。本发明的原理和最核心的关键技术是科学合理的构建了靶向鸡NHE1基因W38位氨基酸的sgRNA,之后转染带有sgRNA和Cas9基因的lentiCRISPR v2质粒,利用CRISPR-Cas9系统达到基因位点的精确敲除,通过药物筛选及亚克隆的方法获得单克隆细胞株,从而获得鸡源NHE1基因W38位敲除的细胞系。
本发明目的是构建一种基于CRISPR-Cas9靶向敲除鸡NHE1基因W38氨基酸的方法,基于本发明建立的DF-1细胞系可以有效封闭ALV-J感染。本发明为抗ALV-J转基因鸡及抗ALV-J药物研发奠定基础。
本发明基于CRISPR-Cas9靶向敲除鸡NHE1基因W38氨基酸的细胞系构建在相关领域未见报道,本发明建立的delW38-NHE1细胞系能有效封闭ALV-J感染,为进一步探究NHE1基因W38氨基酸生物学功能,解析NHE1的W38与ALV-J互作分子机制以及为构建抗ALV-J转基因鸡及抗病毒药物开发打下了基础,具有较大的应用研究价值。
附图说明
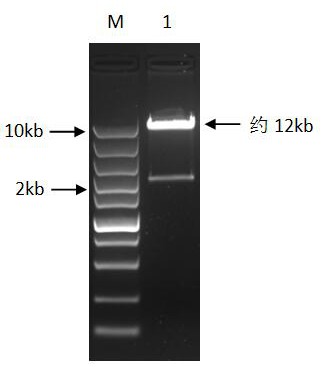
图1为lentiCRISPR v2载体质粒的酶切;
泳道M:super DNA marker;泳道1:酶切后lentiCRISPR v2载体质粒。
图2为亚克隆NHE1-deW38细胞系的测序鉴定。
图3为Western blot评价NHE1-deW38细胞系抗ALV-J效果;
泳道1:NHE1-deW38细胞系感染ALV-J;泳道2:正常DF-1细胞感染ALV-J。
具体实施方式
实施例:
1,查找目的基因:利用NCBI在线数据库查找鸡NHE1基因组序列。NCBI ReferenceSequence:NT_033779.5,在该基因的第一个外显子设计敲除靶位点,第一个外显子的序列如SEQ NO.1所示。
2,利用在线设计网站设计针对靶序列的sgRNA:利用张锋实验室网站 https://zlab.bio/guide-design-resources进行sgRNA的设计,选取6条候选 sgRNA,在sgRNA_F的5’端前部添加CACCG,在sgRNA_R的5’端添加AAAC,3’端添加C,具体引物序列见表1,由苏州金唯智生物科技有限公司合成。
SEQ ID NO.2表1.靶向敲除鸡NHE1 W38基因的sgRNA
3,双链sgRNA的获得:用ddw将sgRNA_F和sgRNA_R溶解,使其终浓度为 100μM浓度,利用以下退火体系:sgRNA_F和sgRNA_R各1μL,10×PCR buffer 1μL,ddw 7μL,退火程序为5℃/min梯度降温至25℃,获得双链DNA。
4,载体质粒的酶切:利用BsmBI限制性内切酶酶切lentiCRISPR v2载体,酶切体系如下:BsmBI限制性内切酶1μL,lentiCRISPR v2质粒1μg,0.1M DTT 0.5μL,NEB buffer3.15μL,其余用ddw补至50μL,酶切条件为55℃15min,之后通过跑凝胶电泳(图1),胶回收获得含有粘性末端的lentiCRISPR v2载体质粒。
5,表达sgRNA载体质粒的构建:将退火获得的双链sgRNA进行100倍稀释,同时将胶回收的载体质粒稀释至50ng/μL,之后按照以下体系进行连接:载体质粒1μL,双链sgRNA 1μL,T4连接酶1μL,10×T4 buffer 1μL,ddw 6μL,在4℃连接过夜,随后转化至stbl3感受态细胞中,挑取菌落提质粒后送测序鉴定。
6,缺失NHE1-W38所需的供体质粒的合成:由金唯智公司合成以pUC57为骨架,含有缺失NHE1-W38所需的供体质粒,并命名为:pUC57-delW38,其中修复模板序列如SEQ IDNO.3。
7,敲除细胞系的筛选:准备一个6孔板的DF-1细胞,每个孔分别转染4 μg的sgRNA和pUC57-delW38各2μg,不转染的细胞作为对照,转染6h后换成 5%生长液,48h后弃去原培养基,加入含有6μM嘌呤霉素的5%FBS DMEM培养基进行筛选,每隔3天换液,待阴性对照组的细胞全部死亡后,加入无药物的 5%FBS DMEM,当细胞密度达到80%左右时,进行亚克隆并扩大培养。
8,敲除细胞系的鉴定:待亚克隆的细胞生长至足够密度时,传代至48孔板,24孔板,12孔板,6孔板,之后收集细胞进行测序鉴定,以正常DF-1细胞为对照,结果如图2。
9,将DF-1和delW38-NHE1细胞系感染MOI=5的ALV-J GY03,细胞感染三天后进行Western blot验证,评价敲除细胞系抗病毒效果,结果如图3所示,感染ALV-J的野生型DF-1细胞中可以检测到强烈的Env蛋白条带,而感染ALV-J 的敲除细胞系中未检测到Env蛋白,表明所构建的敲除delW38-NHE1细胞系能有效阻断ALV-J的感染入侵。
SEQ ID NO.1
鸡NHE1基因第一个外显子序列:
Atgggggccgcggccctccgagcccttccctgggctctgctgctgctgctgggcccgctgctgc ccggccagcgcttgcaggccgacgccacgcgtgtctccgagcccacctgggagcagccgtggggagag cccgggggtatcaccgccgccccgctggccacggcccaggaggtgcacccgctgaacaaacagcacca caaccactcggccgaggggcacccgaagccccgcaaagctttccccgtgctgggcatcgactactcgc acgtccgcatccccttcgagatctcgctctggatcctgctggcctgcctgatgaagatgg
SEQ ID NO.2
SEQ ID NO.3
供体质粒pUC57-delW38,修复模板序列:
GCCCGCTGCTGCCCGGCCAGCGCTTGCAGGCCGACGCCACGCGGGTCTCCGAGCCCACCGAGCA GCCGTGGGGAGAGCCCGGGGGTATCACCGCCGCCCCGCTGGCCACGGCCCAGGAGGTGCACCCGCTGAACAAACAGCACCACAACCACTC。
序列表
<110> 扬州大学
<120> 一种精确敲除鸡NHE1基因W38位氨基酸的细胞系构建方法
<160> 4
<170> SIPOSequenceListing 1.0
<210> 1
<211> 328
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 1
atgggggccg cggccctccg agcccttccc tgggctctgc tgctgctgct gggcccgctg 60
ctgcccggcc agcgcttgca ggccgacgcc acgcgtgtct ccgagcccac ctgggagcag 120
ccgtggggag agcccggggg tatcaccgcc gccccgctgg ccacggccca ggaggtgcac 180
ccgctgaaca aacagcacca caaccactcg gccgaggggc acccgaagcc ccgcaaagct 240
ttccccgtgc tgggcatcga ctactcgcac gtccgcatcc ccttcgagat ctcgctctgg 300
atcctgctgg cctgcctgat gaagatgg 328
<210> 2
<211> 25
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 2
caccgcccca cggctgctcc caggt 25
<210> 3
<211> 25
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 3
aaacacctgg gagcagccgt ggggc 25
<210> 4
<211> 154
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 4
gcccgctgct gcccggccag cgcttgcagg ccgacgccac gcgggtctcc gagcccaccg 60
agcagccgtg gggagagccc gggggtatca ccgccgcccc gctggccacg gcccaggagg 120
tgcacccgct gaacaaacag caccacaacc actc 154
- 一种精确敲除鸡NHE1基因W38位氨基酸的细胞系构建方法
- 一种基于CRISPR-Cas9编辑技术的敲除鸡EphA2基因的细胞系的构建方法