基于弱监督协同学习算法的安全帽识别方法及存储介质
文献发布时间:2023-06-19 09:27:35
技术领域
本发明属于深度识别和目标识别技术领域,具体涉及一种基于弱监督协同学习算法的安全帽识别方法及存储介质。
背景技术
基于建筑工地的安全性考虑要求每个进入工地的人员都要佩戴安全帽,安全帽作为最后一道安全防线,作用十分重要。但是进入建筑工地区域的人员经常由于偷懒、遗忘或者抱着侥幸心理不带安全帽,所存在的危险伤害隐患巨大。所以安全帽检测识别提醒对建筑工地的安全防范来说就显得尤为重要,检测预警在岗工人是否按照要求戴好安全帽,做好安全防范措施作业,才能真正做到安全生产信息化管理,做到事前预防事中常态监测,事后规范管理。
针对建筑工地人员佩戴安全帽的检测,通常的办法就是在入口处进行检测,但是在建筑工地区域内,人员是否戴帽就很难检测了。目前常见的检测方式有以下几种:
(1)人工检测,在工地的每个入口安排专人把守检查,在建筑工地区域安排人员巡逻检查,但是该方式需要耗费人力资源,而且存在检查遗漏的可能。
(2)采用传感器、芯片或标签来进行提醒,在安全帽中安置这些感知设备,当工人或访客佩戴安全帽进入工地时,门禁阅读器会识别安全帽中的传感器、芯片或标签,如果没有佩戴将触发系统提醒。这种方法虽然可以在入口处不遗漏地检测,但是无法检测出人员是否正确佩戴,如果是简单携带并无佩戴,是无法检测出来的。同时这种检测方法也只能在入口处进行检测,一旦进入建筑工地区域,该方法就失效,还是需要人力来检测。
(3)基于计算机视频图像识别的安全帽佩戴行为检测。在工地的每个入口和重要地点安置摄像机,根据摄像机拍摄视频画面,采用计算机视频图像识别算法检测出画面中的施工人员头部和安全帽位置,进而进行是否佩戴安全帽的判断,实现对施工人员安全帽佩戴行为的实时检测与预警。这种方法利用到了计算机做图像处理识别,既节省了人工和传感器的成本,又提高了检测精度和效率,是目前的主流方法,而这个方法大多基于深度学习算法,大致分为两类:第一类、两步骤(Two-stage)算法,先产生候选区域(regionproposals),然后采用卷积神经网络(Convolutional Neural Networks,CNN)进行分类,这类算法典型代表有R-CNN,Fast R-CNN和Faster R-CNN等。第二类、一步骤(One-stage)算法,直接产生物体的类别和位置坐标值,这类算法典型有YOLO和SSD等。
上述基于深度学习的工地安全帽检测算法都是采用有监督的算法,例如中国专利号CN201810913181一种动态背景中的安全帽检测方法与系统、CN201811570198一种安全帽识别方法及装置、CN201910300441基于深度学习的安全帽佩戴识别方法及设备和CN201910484745基于深度学习的安全帽定位与颜色识别的方法及系统。采用有监督的算法,即通过有标签的训练样本(即打好标签的安全帽图片)来训练深度学习算法网络,从而得到一个最优算法模型,再利用这个模型对新的工地安全帽图像数据进行识别判断从而实现检测的目的。而这个过程中最大的问题就是训练样本的生成成本太大了,有监督算法的训练样本图片的标签要求是很高的,图像中训练目标物体不仅要给出物体类别,还要有位置坐标等信息,这是一种边界框级别(bounding-box level)的标签,而且这些标签通常是由人工标记上去的,这个过程费时费力。
另外,虽然业界也在进行无监督算法的研究,即用无标签的训练样本来训练深度学习算法网络,但这个学习过程太过复杂困难了,技术发展很缓慢一直没有突破。而弱监督算法做为有监督和无监督的折中算法应运而生,它训练样本只是图像级别(image level)的标签(即标注仅包含图片中物体的类别),而不是费时费力的边界框级别(bounding-boxlevel)的标签,这样既保证了学习训练过程的简单易操作,又提高了算法的效率,是工地安全帽检测算法的一种理想选择,但目前也尚未出现相关的研究成果。
本发明针对上述问题,如何设计一种基于弱监督协同学习算法的工地安全帽识别方法,通过视频实时分析和预警,对未佩戴安全帽的危险行为实时预警,将报警截图和视频保存到数据库形成报表,是亟需解决的一个技术问题。
发明内容
本发明的目的之一在于克服以上缺点,提供一种基于弱监督协同学习算法的安全帽识别方法,能够对建筑工地生产区域内人员是否佩戴安全帽进行实时分析识别、跟踪和报警。
为了解决上述技术问题,本发明提供了一种基于弱监督协同学习算法的安全帽识别方法,包括以下步骤:
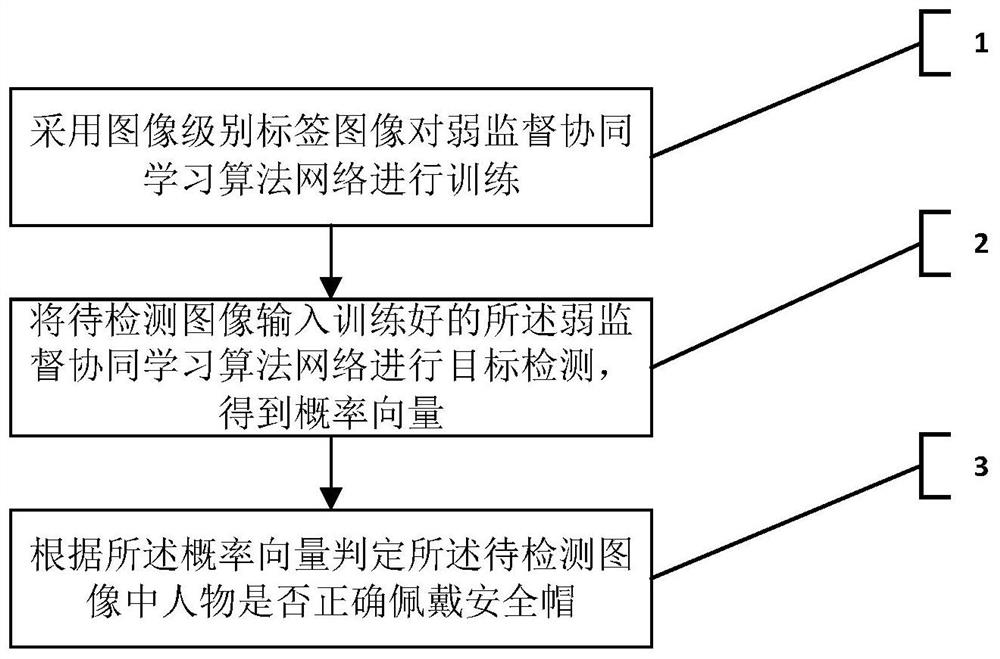
步骤1、采用图像级别标签图像对弱监督协同学习算法网络进行训练;
步骤2、将待检测图像输入训练好的所述弱监督协同学习算法网络进行目标检测,得到概率向量;
步骤3、根据所述概率向量判定所述待检测图像中人物是否正确佩戴安全帽。
进一步地,所述采用图像级别的标签样本对弱监督协同学习算法网络进行训练,包括以下步骤:
步骤11、通过卷积层和ROI池化层对图像级别标签图像进行特征提取,得到包含样本实例训练图片包;
步骤12、弱监督学习模块根据所述训练图片包进行训练并生成边界框级别标签图像第一实例子集;
步骤13、有监督学习模块根据所述训练图片包以及所述边界框级别标签图像第一实例子集进行训练并生成边界框级别标签图像第二实例子集;
步骤14、有监督学习模块对所述边界框级别标签图像第一实例子集以及所述边界框级别标签图像第二实例子集进行计算一致性损失,并根据计算结果更新所述有监督学习模块的网络参数。
进一步地,所述弱监督学习模块根据所述训练图片包进行训练并生成边界框级别标签图像第一结果集,包括以下步骤:
步骤121、连续实例选择器对所述训练图片包中的样本实例进行子集划分;
步骤122、连续评估器根据所述训练图片包样本实例子集划分结果对所述训练图片包中的样本实例进行评估;
步骤123、将评估后的所述训练图片包作为边界框级别标签图像第一结果集。
进一步地,所述连续实例选择器对所述训练图片包中的样本实例进行子集划分,包括以下步骤:
步骤1211、连续实例选择器计算所述训练图片包中每个样本实例的得分,所述得分的计算公式为:S(t
步骤1212、从所述训练图片包所有样本实例中选取得分最高且不属于任何一个边界框级别标签图像实例子集的样本实例,建立一个新的边界框级别标签图像实例子集;
步骤1213、将与步骤1211中所述得分最高的样本实例图片重叠面积大于或等于τ,且不属于任何一个边界框级别标签图像实例子集的样本实例归入相同的边界框级别标签图像实例子集中,其中,τ表示连续参数,取值范围为[0,1];
步骤1214、根据已经建立的所述边界框级别标签图像实例子集计算连续实例选择器的目标函数值,所述连续实例选择器的目标函数为:
其中,t
步骤1215、判断所述连续实例选择器的目标函数值是否大于预设的阈值;
步骤1216、若所述连续实例选择器的目标函数值小于或等于预设的阈值,则跳转至步骤1212继续执行;
步骤1217、若所述连续实例选择器的目标函数值大于预设的阈值,则子集划分完成。
进一步地,所述连续评估器根据所述训练图片包样本实例子集划分结果对所述训练图片包中的样本实例进行评估,评估公式为:
其中,IOU函数表示两个样本实例之间的交并比,t
进一步地,所述预测一致性损失计算,计算公式为:
其中,L
进一步地,所述概率向量,包括:待检测图像中的物体识别为安全帽的概率值、待检测图像中的物体识别为人的概率值以及待检测图像中的物体位置坐标信息。
进一步地,所述根据所述概率向量判定所述待检测图像中人物是否正确佩戴安全帽,包括以下步骤:
若待检测图像中的物体识别为人的概率值以及物体识别为安全帽的概率值大于固定阈值且安全帽位置在人头顶上,则判定待检测图像中的人物正确佩戴安全帽,否则判定图像中的人物未正确佩戴安全帽。
相应地,本申请还提供了一种计算机可读存储介质,其特征在于,所述计算机可读存储介质存储有一个或者多个程序,所述一个或者多个程序可被一个或者多个处理器执行,以实现上述权利要求中任一项基于弱监督协同学习算法的安全帽识别方法的步骤。
本发明技术方案的有益效果有:
1.本申请的技术方案采用弱监督的深度学习算法,仅需要图像级别的标签样本图片进行训练,对训练样本图片的要求大大降低,减少了人工处理训练样本图片的时间,提高了工作效率。
2.本申请的弱监督深度学习算法采用改进的连续多实例学习方法,它通过平滑多实例学习方法的目标函数并将其转换成多个更容易解决的子问题,从而多个子问题的目标函数联合去逼近最终的目标函数,能更好地解决弱监督目标函数的非凸性,避免模型过早陷入局部极小值,从而获得更好的优化结果。
3.本申请技术方案中弱监督协同学习算法采用一种新的协同学习构架,它在弱监督的学习过程中把弱监督检测子网络和有监督检测子网络连接成一个统一的整体,利用预测一致性损失加强了这两个检测子网络的实例预测一致性,这样让这个弱监督协同学习算法既具有弱监督的高效的训练网络的能力,也具有有监督的算法精准的检测精度。
附图说明
图1是本发明的一种基于弱监督协同学习算法的安全帽识别方法步骤流程图。
图2是本发明采用图像级别的标签样本对弱监督协同学习算法网络进行训练步骤流程图。
图3是本发明弱监督学习模块根据所述训练图片包进行训练并生成边界框级别标签图像第一结果集步骤流程图。
图4是本发明连续实例选择器对所述训练图片包中的样本实例进行子集划分步骤流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示,是本发明的一种基于弱监督协同学习算法的安全帽识别方法步骤流程图,包括以下步骤:
步骤1、采用图像级别标签图像对弱监督协同学习算法网络进行训练;
在深度学习和目标识别技术领域,用于训练的图像可以分为图像级别(imagelevel)标签图像以及边界框级别(bounding-box level)标签图像,其中,图像级别(imagelevel)标签图像指的对于用于训练的图像,只知道其包含人或安全帽,而不知道人或安全帽在图像中的具体位置,而边界框级别(bounding-box level)标签图像不仅知道其包含人或安全帽,而且知道每个人或安全帽在图像中的具体位置,因此边界框级别标签图像训练样本通常是由人工标记人或安全帽的位置,这个过程费时费力效率低下。如图2所示,是本发明采用图像级别的标签样本对弱监督协同学习算法网络进行训练步骤图,包括以下步骤:
步骤11、通过卷积层和ROI池化层对图像级别标签图像进行特征提取,得到包含样本实例训练图片包;
将用于训练的图像级别标签图像送入卷积层,卷积层根据输入的图像提取出包含不同目标(人或安全帽)的重要特征的候选区域,再将结果送入池化层,由池化层将不同大小的候选区域转换为固定大小的输出,以便进行后训练。池化层输出的结果即为包含样本实例训练图片包。例如,每一张输入的用于训练的图像级别标签图像都生成一个对应的训练图片包,每个训练图片包中的样本实例都对应图像中一个为人或安全帽的候选区域,也称为样本实例。
步骤12、弱监督学习模块根据所述训练图片包进行训练并生成边界框级别标签图像第一实例子集;如图3所示,是本发明弱监督学习模块根据所述训练图片包进行训练并生成边界框级别标签图像第一结果集步骤流程图,包括以下步骤:
步骤121、连续实例选择器对所述训练图片包中的样本实例进行子集划分;
假设定义T代表所有的训练图片的包,t
步骤1211、连续实例选择器计算所述训练图片包中每个样本实例的得分,这里的得分是针对每个样本实例计算的对象分数,也就是指样本实例属于具体一个对象(人脸或安全帽)的分数,是利用连续实例选择器计算出来的,所述得分的计算公式为:S(t
步骤1212、从所述训练图片包所有样本实例中选取得分最高且不属于任何一个边界框级别标签图像实例子集的样本实例,建立一个新的边界框级别标签图像实例子集;
步骤1213、将与步骤1211中所述得分最高的样本实例图片重叠面积大于或等于τ,且不属于任何一个边界框级别标签图像实例子集的样本实例归入相同的边界框级别标签图像实例子集中,其中,τ表示连续参数,取值范围为[0,1];
步骤1214、根据已经建立的所述边界框级别标签图像实例子集计算连续实例选择器的目标函数值,所述连续实例选择器的目标函数为:
其中,t
步骤1215、判断所述连续实例选择器的目标函数值是否大于预设的阈值;
步骤1216、若所述连续实例选择器的目标函数值小于或等于预设的阈值,则跳转至步骤1212继续执行;
步骤1217、若所述连续实例选择器的目标函数值大于预设的阈值,则子集划分完成。
传统的弱监督深度学习算法,大多采用多实例学习方法,该方法把每张图看成一个包(bag),图中的物体看成一个实例(instance),在训练过程中迭代地从包中选出得分最高的候选区域(proposal)进行网络的训练,由于弱监督的监督信息只是指示图片中是否包含相应类别物体的图像级别信息,因此实例存在定位的随机性,描述候选区域选择的目标函数容易在早期学习阶段出现非凸性,而优化这个目标函数会陷入局部极小值中,使其只检测部分区域,而忽略了完整的范围。
本技术方案的弱监督深度学习算法采用改进的连续多实例学习方法,在传统的多实例学习方法的基础上引入连续优化方法,目的是更好地解决弱监督目标检测问题的非凸性,将图片中的实例候选区域进行有效划分,将空间相关和类别相关的实例划分成一个子集,并在相应的子集上定义对应的平滑目标函数,不同子集的目标函数联合逼近原始目标函数,获得更好的优化结果。它通过平滑多实例学习方法的目标函数并将其转换成多个更容易解决的子问题,从而多个子问题的目标函数联合去逼近最终的目标函数,能更好地解决弱监督目标函数的非凸性,避免模型过早陷入局部极小值,从而获得更好的优化结果。
步骤122、连续评估器根据所述训练图片包样本实例子集划分结果对所述训练图片包中的样本实例进行评估;连续评估器的作用是基于连续实例选择器选择出来的样本实例子集对每个样本实例的正负标志结果进一步做评估,将一些错误或者干扰背景排除,进一步提高训练的准确性,其中,连续评估器采用的评估公式为:
其中,IOU函数表示两个样本实例之间的交并比,t
步骤123、将经过连续评估器评估后的所述训练图片包作为边界框级别标签图像第一结果集。
步骤13、有监督学习模块根据所述训练图片包以及所述边界框级别标签图像第一实例子集进行训练并生成边界框级别标签图像第二实例子集;本申请的所述的有监督学习模块,采用的是常规的Faster R-CNN算法,通过输入边界框级别标签图像第一实例子集,经过训练并输出边界框级别标签图像第二实例子集;
步骤14、有监督学习模块对所述边界框级别标签图像第一实例子集以及所述边界框级别标签图像第二实例子集进行计算一致性损失,并根据计算结果更新所述有监督学习模块的网络参数。其中,所述预测一致性损失计算,计算公式为:
其中,L
另外,有监督学习模块和弱监督学习模块在网络上有一定的相似性,训练的过程中可以共享网络参数,并且可以在卷积层和部分完全连接层共享部分图像特征表示,这也确保了两个算法感知的一致性,提高两个分支的训练效率。
步骤2、将待检测图像输入训练好的所述弱监督协同学习算法网络进行目标检测,得到概率向量;具体地,由有监督学习模块对待检测图像进行目标检测,通常采用的是Faster R-CNN算法得到概率向量,这里的概率向量包括:待检测图像中的物体识别为安全帽的概率值、待检测图像中的物体识别为人的概率值以及待检测图像中的物体位置坐标信息。
步骤3、根据所述概率向量判定所述待检测图像中人物是否正确佩戴安全帽,包括以下步骤:若待检测图像中的物体识别为人的概率值以及物体识别为安全帽的概率值大于固定阈值且安全帽位置在人头顶上,则判定待检测图像中的人物正确佩戴安全帽,否则判定图像中的人物未正确佩戴安全帽。具体地,通过弱监督协同学习算法网络进行图像识别,得出检测结果,再建立人头安全帽联合检测模型:当未出现人时,判断现场无人员;只出现人,或者安全帽和人都出现,但安全帽在人头顶下方,认定未佩戴安全帽;只有当安全帽和人同时出现,并且安全帽出现在人头顶上,才认定佩戴安全帽。
优选地,本申请的技术方案还可以提供一种计算机可读存储介质,所述计算机可读存储介质存储有一个或者多个程序,所述一个或者多个程序可被一个或者多个处理器执行,以实现上述权利要求中任一项基于弱监督协同学习算法的安全帽识别方法的步骤。
本申请的技术方案,通过弱监督算法和有监督的Faster R-CNN算法进行协同学习的技术,提出一种弱监督协同学习的框架,利用两种算法之间的任务相似性即预测一致性来联合训练这两个算法子网络。首先弱监督算法使用连续多实例学习的方法训练学习,这种算法仅需要图像级别的标签样本图片进行训练,对训练样本图片的要求大大降低;将弱监督算法输出的边界框级别标签图像输入给有监督的Faster R-CNN算法进行训练,同时使用预测一致性损失来保持与弱监督算法结果的相似性,以此提供训练学习的准确性,这样,本申请的弱监督协同学习方法既具有弱监督学习方法的高效训练网络的能力,同时具有有监督的学习方法精准的检测精度。
上述具体实施方式只是对本发明的技术方案进行详细解释,本发明并不只仅仅局限于上述实施例,凡是依据本发明原理的任何改进或替换,均应在本发明的保护范围之内。