一种用于对金字塔特征图进行预测的算法
文献发布时间:2023-06-19 09:27:35
技术领域
本发明涉及图像处理技术领域,尤其涉及一种用于对金字塔特征图进行预测的算法。
背景技术
近年来,由于卷积神经网络(简称CNN)的发展和应用,许多计算机视觉领域的任务得到了较大的发展,其中目标检测的是计算机视觉中的一项重要的任务。目标检测是计算机视觉和数字图像处理的一个热门方向,广泛应用于机器人导航、智能视频监控、工业检测、航空航天等诸多领域,通过计算机视觉减少对人力资本的消耗,具有重要的现实意义。因此,目标检测也就成为了近年来理论和应用的研究热点,它是图像处理和计算机视觉学科的重要分支,也是智能监控系统的核心部分,同时目标检测也是泛身份识别领域的一个基础性的算法,对后续的人脸识别、步态识别、人群计数、实例分割等任务起着至关重要的作用。由于深度学习的广泛运用,目标检测算法得到了较为快速的发展,基于深度学习的两种目标检测算法思路,分别为One-Stage目标检测算法和Two-Stage目标检测算法。
目前主流的目标检测算法主要是基于深度学习模型,大概可以分成两大类别:(1)One-Stage目标检测算法,这类检测算法不需要产生候选区域框的阶段,可以通过一个Stage直接产生物体的类别概率和位置坐标值,比较典型的算法有YOLO、SSD和CornerNet;(2)Two-Stage目标检测算法,这类检测算法将检测问题划分为两个阶段,第一个阶段首先产生候选区域(Region Proposals),包含目标大概的位置信息,然后第二个阶段对候选区域进行分类和位置精修,这类算法的典型代表有R-CNN,Fast R-CNN,Faster R-CNN等。目标检测模型的主要性能指标是检测准确度和速度,其中准确度主要考虑物体的定位以及分类准确度。一般情况下,Two-Stage算法在准确度上有优势,而One-Stage算法在速度上有优势。不过,随着研究的发展,两类算法都在两个方面做改进,均能在准确度以及速度上取得较好的结果。在申请研究的目标检测算法是基于One-Stage的,它针对近来很热门的密集目标检测器,其准确率比起目前最先进的算法都有所提升。滑动窗口目标检测器,它在密集且规则的网格上生成边界框预测,在现代物体检测中起着至关重要的作用。目前这种检测器大多都是基于限定框的一个点去进行预测的,这样得到的特征可能不具有代表性,所以后面有人提出通过引入更多更强的特征,但很多这些增加的操作会由于引入了背景噪声带来有害的信息。然而这些方法没有显式地提取边界特征,本申请认为边界极限点特征对边界框的定位比较重要,并且在每个边界处选取最有效的特征,用简洁高效的方法来完成特征的提取,因此,现有技术需要进一步改进和完善。
发明内容
本发明的目的在于克服现有技术的不足,提供一种用于对金字塔特征图进行预测的算法。
本发明的目的通过下述技术方案实现:
一种用于对金字塔特征图进行预测的算法,该算法主要包括如下具体步骤:
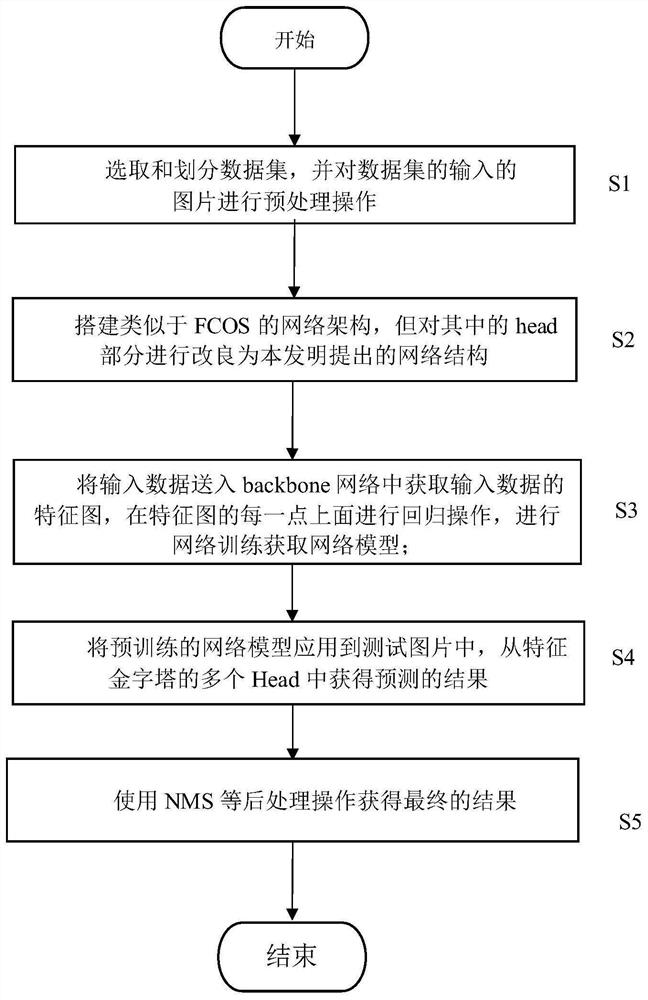
步骤S1:选取和划分数据集,并对数据集的输入的图片进行预处理操作。
进一步的,所述S1步骤还包括:
步骤S11:采用当前较为流行的COCO目标检测类别数据集,按照常规的做法,训练集采用COCO trainval35k set(115K images),验证集采用COCO minival set(5Kimages),测试集采用test-dev set(20K images)。
作为本发明的优选方案,所述步骤S1中,所述预处理操作主要包括均值化、去雾、裁剪等操作。
步骤S2:搭建类似于FCOS的网络架构,但对其中的head部分进行改良为本发明提出的网络结构。
进一步的,所述S2步骤还包括如下具体步骤:
步骤S21:本发明采取的网络结构是目前目标检测领域较为流行的FCOS网络架构,该网络由三部分组成,分别是主干网络(backbone network),特征金字塔网络FPN(FeaturePyramid Networks),以及本发明提出的预测网络组成。
步骤S22:主干网络的选取采用残差网络(ResNet-50)来提取特征,它由摒弃了ResNet50中的conv1、conv2之后的卷积模块来组成。每层卷积模块结构类似,都是采用多个bottleneck残差块组成,每层模块中的第一层都要做下采样,通过用3*3的卷积核步长为2,作最大池化的操作。选取ResNet-5最后三个卷积模块,分别记为conv3、conv4、conv5,得到的特征图记为C3、C4、C5。
步骤S23:FPN特征金字塔网络是由主干网络提取特征后的不同维度的特征图经过相加操作得到的,对于该部分的网络也可以分为两部分,上采样部分和下采样部分。FPN特征金字塔的主要思路是结合了网络的浅层特征和深层特征,然后在多个分支同时输出不同大小的目标。充分的使用了网络的浅层特征和深层特征,浅层特征更关注一些细节信息,适合用来定位;而深层特征更关注于语义信息,适合用来分类等。
步骤S24,预测网络是对不同层级的特征层进行预测。不同特征层共享head网络,可以有效地提升检测器参数的效率,提升检测的性能。但是不同的特征层对应不同的回归尺寸范围(P3是[0,64],P4是[64,128]),因此没有理由使用完全相同的head网络作用在不同的特征层上。每个head网络结构都相同,都包含有回归分支和分类分支。并且每条分支经过四个卷积层后再分为两支,一支经过边界对齐模块,一个不作处理。对比起FCOS的检测器的head部分,我们新加入了两条连有边界对齐模块的支路,得到经过边界信息提取的边界特征图,然后根据这些新的分类得分和边框位置和旧的相结合,得到更新后的分类得分和边框位置。这一点点的改进,能够突出边框的边界信息,并且能有效提升预测的性能。虽说加入了一些步骤和时间花费,但是这些计算量几乎是微乎其微的,可以忽略其时间损耗。
进一步的,所述步骤S24还包括如下具体步骤:
步骤S241:对于预测网络中的边界对齐模块,它包含一个边界对齐操作器和两层1*1卷积层。它的作用是用来对特征图的信息增加其边界的敏感度。对于C个通道里表示着限定框的单点特征的特征图,先对其进行1*1的卷积改变通道数,后跟着一个实例正则化的操作,生成五倍于原先通道的特征图,4C通道中每C通道都表示着一条边界的信息,还有C通道表示着原来单点特征的信息。对于5C通道特征图,通过操作器进行边界对齐操作,然后再降维,还原为输入模块前的C通道特征图。
步骤S242:对于边界对齐操作器,这是本工作最核心的一个操作,用来显式、自适应的提取物体边界的特征。对于一个特征图,通道个数为5C,这是一个边界敏感的特征图,分别对应物体4个边界特征和原始锚点位置的特征。对于一个锚点预测的一个框,我们把这个框的4个边界对应在特征图上的特征分别做池化操作。且由于框的位置是小数,所以该操作使用双线性插值取出每个边界上的特征。关于该操作,我们每条边会先选出N个待采样点,再对这N个待采样点取最大的值,作为该条边的特征,即每条边最后只会选出一个采样点作为输出。那么每个锚点都会采样5个点的特征作为输出,即输出的通道数也为5C个。
步骤S3:将输入数据送入backbone网络中获取输入数据的特征图,在特征图的每一点上面进行回归操作,进行网络训练获取网络模型。
步骤S4:将预训练的网络模型应用到测试图片中,从特征金字塔的多个Head中获得预测的结果。
步骤S5:使用NMS等后处理操作获得最终的结果。用测试集对选出的模型进行测试,评估模型性能。将本模型的实验结果和SOTA的一些模型进行准确率和速度的比较,权衡下来得到本发明的网络结构能够在速度和性能上完成很好的平衡,有很不错的效果。
本发明的工作过程和原理是:本发明提供的一种用于对金字塔特征图进行预测的算法,基于前人的网络架构FCOS,通过对其中预测网络部分的head网络采用轻量级简易的模型改进,得到不同层次上特征图的预测结果。再对金字塔特征图不同层次上的预测结果进行结合,得到最后预测结果,其准确率比起当前目标检测领域的SOAT方法都要有所提升。
与现有技术相比,本发明还具有以下优点:
(1)本发明所提供的用于对金字塔特征图进行预测的算法对单步骤的目标检测算法FCOS进行改进,通过简单地改进head网络的结构,加入了边界对齐操作器,能够显式地提取特征图限定框的边界信息,而且由于只关注边界的特征点,减少了很多计算量,高效的方法实现更高的性能,只需要多耗费一点点的计算量就能达到很好的效果,是一个很有效的特征增强的方法。
(2)本发明所提供的用于对金字塔特征图进行预测的算法的网络结构朴素、简单且高效,能够有很好的表现,准确率能媲美SOAT。
(3)本发明提供了简洁明了又权衡了精度和速度的预测网络,在很多单阶段的目标检测算法中都有速度的优势,随着越来越多人对单阶段算法的改进,其精度也有很大的提升。
(4)本发明所提供的用于对金字塔特征图进行预测的算法加入了边界对齐的网络结构,提出了一个关于边界对齐的操作,能够更好的对特征信息增强,且只增加了很少的时间开销就能对FCOS的准确率有较为明显的提升。
附图说明
图1是本发明的目标检测算法的流程图。
图2是本发明的主干网络部分的瓶颈残差网络结构图。
图3是本发明参考的FCOS网络结构图。
图4是本发明的预测网络部分head网络的结构图。
图5是本发明的边界区域对齐模块的结构图。
具体实施方式
为使本发明的目的、技术方案及优点更加清楚、明确,以下参照附图并举实施例对本发明作进一步说明。
实施例1:
如图1和图2所示,本实施例公开了一种基于语义分割的人脸图像的分割网络的方法,该方法主要包括以下步骤:
步骤S1,一种用于对金字塔特征图进行预测的算法。
进一步,所述的S1步骤包括:
步骤S11:采用当前较为流行的COCO目标检测类别数据集,按照常规的做法,训练集采用COCO trainval35k set(115K images),验证集采用COCO minival set(5Kimages),测试集采用test-dev set(20K images)。在初始学习率为0.01的情况下,分别在60k次迭代和80k次迭代后将其降低10倍。使用水平图像翻转作为数据增强的唯一形式。使用0.0001的重量衰减和0.9的动量。我们使用ImageNet上预训练的权重来初始化骨干网络。将调整输入图像的大小,以确保其较短边缘为800,而较长边缘小于1333。使用的输入图片尺寸为800*1024,等待模型的训练。
步骤S2,搭建类似于FCOS的网络架构,但对其中的head部分进行改良为本发明提出的网络结构。本发明采取的网络结构是当前目标检测领域较为流行的FCOS网络架构,该网络由三部分组成,分别是主干网络(backbone network),特征金字塔网络FPN(FeaturePyramid Networks),以及本发明提出的预测网络组成。
进一步,所述的S2步骤包括:
步骤S21,如图3所示,主干网络的选取采用残差网络(ResNet-50)来提取特征,摒弃了ResNet50中的conv1,由于conv1占用大量内存,因此我们不将其包含在金字塔中。每层卷积模块结构类似,都是采用多个bottleneck残差块组成,残差块是由三个卷积层组成,分别为1*1卷积层、3*3卷积层、1*1卷积层。每层模块中的第一层都要做下采样,通过用3*3的卷积核的最大池化操作。主干网络选取ResNet-5最后三个卷积模块,分别记为conv3、conv4、conv5,提取得到特征图记为C3、C4、C5。对于conv3层模块,先经过3*3,步长为8的最大池化层,然后是3个由[1*1,64],[3*3,64],[1*1,256]组成的瓶颈块,4个由[1*1,128],[3*3,128],[1*1,512]组成的瓶颈块构成。对于conv4,经过,先经过3*3,步长为2的最大池化层,然后是6个由[1*1,256],[3*3,256],[1*1,1024]组成的瓶颈块构成。对于conv5,经过,先经过3*3,步长为2的最大池化层,然后是6个由[1*1,512],[3*3,512],[1*1,2048]组成的瓶颈块构成。对于输入为800*1024的图片,经过conv3后得到分辨率为100*128的特征图C3,经过conv4得到50*64的特征图C4,经过conv5得到25*32的特征图C5。
步骤S22,FPN特征金字塔网络的输入是由主干网络提取特征后的不同维度的特征图经过一系列卷积和相加操作得到。对于特征图C5,直接进行1*1的卷积来降低通道数得到P5。然后对于C4,要经过一个相加的模块。该模块分别由P5经过上采样得到的特征图和C4经过的1*1卷积降维后得到的特征图,由于它们两个尺寸大小都是一样的,可以进行逐像素的相加,相加完之后还需要进行一个3*3的卷积才能得到P4。关于这个3*3卷积,其目的主要是为了消除上采样产生的混叠效应。同理,P3也是通过本层的特征图1*1卷积和上一层得到的上采样特征图相加后进行3*3卷积得到的。P6、P7分别是对P5、P6进行步长为2的卷积得到的。金字塔所有层的输出维度都被统一为256,在金字塔特征网络里进行的卷积的通道选取都为256。而且所有层都共享分类器和回归器。
步骤S23,预测网络中是对特征金字塔的每一层通过head网络进行预测。每个head网络结构都相同,都包含有回归分支和分类分支。如图4所示,它是对FCOs中的head进行改进后的网络结构,将金字塔特征图作为输入,分别经过回归和分类分支的四个卷积层得到原始的限定框的位置L1和分类得分S1。这是原本FCOS的head网络中得到的分类和回归预测结果。然后第二步,将在两条分支的四个卷积层之后加入一个边界对齐模块,得到的是经过边界特征提取后的结果,它将会包含更多显式的边界信息。对于分类分支,原先的分类得分S1,和原始边框位置L1喂给边界模块后得到的新的边界分类得分S2相乘,就能得到更新后的分类得分S*。对于回归分支,将原来的边框位置L1和新的边界边框位置L2相结合就能得到更新后的边框位置L*。对于分类和回归的损失函数选择,分类损失函数就是focal_loss,超参和FCOS完全一致,回归就是最简单的smoothl1,精修FCOS预测框的位置。
进一步,步骤23包括:
步骤S231,对于head网络中的边界对齐模块,如图5所示,它包含一个边界对齐操作器和两层1*1卷积层。它的作用是用来对特征图的信息增加其边界的敏感度。对于C个通道里表示着限定框的单点特征的特征图,先对其进行1*1的卷积改变通道数,后跟着一个实例正则化的操作,生成五倍于原先通道的特征图,4C通道中每C通道都表示着一条边界的信息,还有C通道表示着原来单点特征的信息。对于5C通道特征图,通过操作器进行边界对齐操作,然后再降维,还原为输入模块前的C通道特征图。
步骤S232,对于边界对齐操作器,对于一个特征图,通道个数为5C,这是一个边界敏感的特征图,分别对应物体4个边界特征和原始锚点位置的特征。对于一个锚点预测的一个框,我们把这个框的4个边界对应在特征图上的特征分别做最大池化操作。且由于框的位置是小数,所以该操作使用双线性插值取出每个边界上的特征。关于该操作,我们每条边会先选出N个待采样点,再对这N个待采样点取最大的值,作为该条边的特征,即每条边最后只会选出一个采样点作为输出。那么每个锚点都会采样5个点的特征作为输出,即输出的通道数也为5C个。
步骤S3,将输入数据送入backbone网络中获取输入数据的特征图,在特征图的每一点上面进行回归操作,进行网络训练获取网络模型。
步骤S4,将预训练的网络模型应用到测试图片中,从特征金字塔的多个Head中获得预测的结果。
步骤S5,使用NMS等后处理操作获得最终的结果。用测试集对选出的模型进行测试,评估模型性能。将本模型的实验结果和SOTA的一些模型进行准确率和速度的比较,权衡下来得到本发明的网络结构能够在速度和性能上完成很好的平衡,有很不错的效果。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 一种用于对金字塔特征图进行预测的算法
- 一种基于自相关特征金字塔网络的图像复制-粘贴篡改检测算法