一种交易偏好判别模型自适应方法
文献发布时间:2023-06-19 09:46:20
技术领域
本发明涉及人工智能技术领域,尤其涉及到用户交易偏好判别,具体涉及到一种交易偏好判别模型自适应方法。
背景技术
互联网的飞速发展,催生出了各种电子交易平台,如电商、团购、外卖之类的线上交易平台,同时云闪付、支付宝、微信支付等线上支付的普及也让人们的生活方式发生了改变,电子支付手段不仅打破了线下线上交易的壁垒,还极大的增强了交易的便利性,也加快了支付交易的流转速度。
在各种线上交易平台的应用中,为了更好的捕捉到用户的交易偏好与交易习惯,实现针对用户特征的精准营销或产品推荐,出现了很多的推荐系统的应用。如机器学习领域中常用的基于用户的协同过滤推荐userCF(User-based Collaborative Filtering)和基于物品的协同过滤推荐itemCF(Item-based Collaborative Filtering);强化学习领域中基于用户点击行为的DRN(Deep Reinforcement Learning Networks)等。这些算法都实现了根据用户历史行为来进行相关推荐的应用。
但是,上述推荐算法仅仅是根据用户的历史交易进行推荐,而没有真正的识别用户的交易偏好与习惯,在用户帮别人买了一次物品或偶发性交易后仍然会对用户推荐该类物品,导致推荐精准性不高。在用户数量或者物品数量都是海量的时候,上述推荐方案的时间成本非常高,并且推荐的准确性较差。同时,上述算法忽略了用户行为规律变化的影响。
发明内容
针对现有技术所存在的不足,本发明目的在于提出一种交易偏好判别模型自适应方法,用于根据用户的交易行为、交易内容、交易关联偏好、智能核实反馈进行自适应的优化交易偏好判别模型,提高用户偏好判别的准确性,具体方案如下:
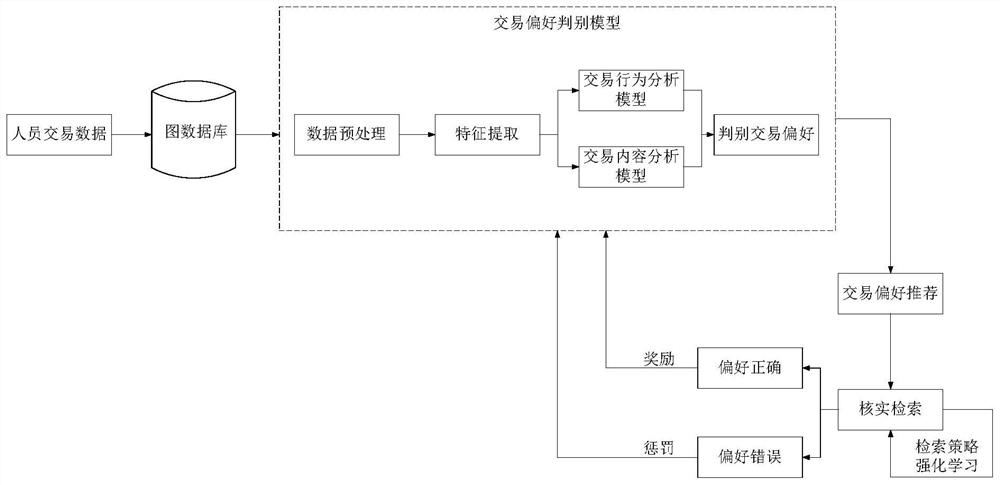
一种交易偏好判别模型自适应方法,包括如下步骤:
建立交易图数据库:收集交易数据并将各类交易数据转换为实体、属性结构,并抽取实体之间的关系和关联属性,构建基于图结构的交易关系数据库,即交易图数据库;
数据预处理:对收集的各类交易数据进行预先的数据转换处理,数据转换处理包括数据清洗、数据集成、数据变换、数据归约;
特征提取:针对用户交易特点对收集的各类交易数据提取相应的静态特征、交易行为特征、交易内容特征、图结构特征等,分析用户交易行为和交易内容;
建立交易行为分析模型,挖掘目标对象的交易行为规律,获得目标交易行为偏好的概率;
建立交易内容分析模型,挖掘目标对象的交易内容模式,获得目标交易内容偏好的置信度;
综合交易行为分析模型和交易内容分析模型进行交易偏好判别:按照用户交易行为偏好概率、交易内容偏好置信度、图结构关联关系偏好及核实反馈结果进行加权计算,得到最终的交易偏好判别结果;
根据交易偏好结果进行核实检索:专业人员定期随机对推荐的用户交易偏好进行核实检索,通过记录检索步骤并对检索步骤进行强化学习来固化核实流程,若核实交易偏好判别正确则以奖励的形式正反馈交易偏好判别模型,若核实交易偏好判别错误则以惩罚的形式负反馈交易偏好判别模型;
根据核实结果动态优化交易偏好判别模型:结合强化学习的核实检索步骤自动进行交易偏好判定结果的核实,根据反馈结果不断优化交易偏好判别模型,形成能够自适应用户行为变化的交易偏好判别模型,进行用户行为偏好的推荐。
进一步的,在建立交易图数据库的步骤中,交易数据包括反查数据、登录日志数据、交易记录数据、提现记录数据、账户明细数据、注册信息数据、转账明细数据。
进一步的,在数据预处理步骤中,处理方式如下:
将各类收集到的数据进行一致性转换,消除同一含义不同表达的差异性;
将能关联得出的缺失数据进行缺失填补,维护数据的完整性;
对关联数据中存在的冗余属性进行剔除;
增补能通过计算得出的属性信息。
进一步的,在所述特征提取步骤中,静态特征包括用户的基本属性信息,交易行为特征包括用户交易过程中的频次、周期性、变化性特征,交易内容特征包括用户交易过程中产生的文本数据中提取的内容特征,图结构特征包括用户交易关系中的相关特征。
进一步的,所述的交易行为分析模型是通过如下步骤建立的:
步骤一:设定时间窗口t划分数据构造行为特征矩阵,按照如权利要求1中所提取的交易行为特征构造时间窗口长度为t的行为特征矩阵X,X中包括x
步骤二:采用时序规律分析方法来构建模型构建交易行为分析模型并训练;步骤三:根据模型权重矩阵和预测结果判别交易行为偏好。
进一步的,所述的交易内容分析模型是通过如下步骤建立的:
步骤一:对用户的交易详情进行分词处理,识别表示交易内容的有价值的信息,并对交易内容进行词频统计;
步骤二:按照所提取的交易内容特征建立用户与交易内容的关系矩阵G,G中包括g
步骤三:根据用户与交易内容的关系矩阵进行聚类分析,进行交易内容的人群划分;
步骤四:根据不同的人群进行关联规则分析,挖掘交易内容的频繁模式;
步骤五:根据频繁模式的置信度和核实结果的奖惩机制综合判别交易内容偏好。
进一步的,所述的交易偏好判别是通过如下步骤进行的:
步骤一:按照所构建的交易行为分析模型权重的降序排列的前n个特征的均值以及预测出下一时刻的交易行为的值作为用户交易行为的偏好;
步骤二:按照所挖掘的频繁项集的置信度降序排列的前n个频繁项集作为用户交易内容的偏好;
步骤三:按照所述的图结构特征反映的密切关联人员的前n个偏好作为用户交易的传播偏好;
步骤四:对前三步的偏好及核实反馈结果进行加权计算,若最终结果高于阈值则进行用户交易偏好推荐,若最终结果低于阈值则不进行推荐,继续进行用户偏好的挖掘。
进一步的,所述的交易偏好结果核实检索是通过如下步骤进行的:
步骤一:按周期随机选择交易偏好结果,由专业人员进行核实检索,若专业人员判别偏好结果正确,则奖惩机制中的R值为1,若专业人员判别偏好结果错误,则奖惩机制中的R值为-1;
步骤二:针对专业人员的检索记录,通过强化学习进行检索策略的学习。
进一步的,所述的动态优化交易偏好判别模型是通过如下方法进行的:
根据强化学习核实检索策略的结果,智能分析判别后续的交易偏好推荐结果,根据核实推荐的正误,更新惩罚机制R的值,并动态自适应的优化交易偏好判别模型的训练过程,实现交易判别模型根据核实反馈的结果动态的更新模型参数,进行动态的交易偏好判别。
与现有技术相比,本发明的有益效果如下:
(1)本发明通过对未知人员的交易数据进行预处理,按照静态特征、交易行为特征、交易内容特征、图结构特征等维度进行特征提取,并对提取后的特征进行交易行为分析和交易内容分析,综合行为、内容、图结构特征以及核实反馈的结果进行交易偏好的判别,然后专业人员通过查询检索核实交易偏好推荐结果,并对专业人员的检索记录进行强化学习以便掌握核实检索流程,核实后对交易偏好推荐结果进行评价反馈,偏好正确的奖励交易偏好判别模型,偏好错误的惩罚交易偏好模型,实现交易偏好模型的动态优化,最后将动态优化模型进行周期性分析,不断根据最新的交易记录和核实检索方法实现交易偏好的推荐;
(2)本发明采用了基于深度学习循环神经网络的交易行为分析模型,综合考虑了多种时间周期、交易频次、交易类型比率等对用户交易行为产生的影响,利用LSTM-R对长短期交易行为的记忆和核实反馈奖惩机制的作用,提高了用户行为偏好预测的准确度;
(3)本发明采用了基于机器学习、深度学习和关联规则的交易内容分析模型,通过对交易文本内容进行分词处理,形成用户与交易内容的关系矩阵,并对其进行聚类分析,根据不同类别的人群进行交易内容关联关系分析,挖掘各类交易人员的交易内容的频繁模式,同时结合频繁模型的置信度与核实反馈奖惩机制进行最终的交易内容偏好判别,提高了用户内容偏好挖掘的深度;
(4)本发明采用了基于强化学习的核实检索规律学习,通过对专业检索人员的核实操作步骤的学习,形成具有操作策略的智能核实检索机制,能够基于少量的操作数据自动分析核实后续海量的用户偏好推荐结果,实现了交易偏好模型的动态自适应优化,能够保持对用户行为变化的敏锐度并提高偏好判别的准确度。
附图说明
图1为本发明根据核实反馈动态优化交易偏好判别模型方法的流程图;
图2为本发明交易行为分析模型图;
图3为本发明交易内容分析模型图;
图4为本发明核实检索强化学习模型图。
具体实施方式
下面结合实施例及附图对本发明作进一步的详细说明,但本发明的实施方式不仅限于此。
本发明所阐述的一种交易偏好判别模型自适应方法,适用于各类线上交易平台,比如淘宝、支付宝、微信等,不做限制。图1为根据核实反馈动态优化交易偏好判别模型方法的流程图。如图1,本发明交易偏好判别模型自适应方法主要包括八个步骤:
一、建立交易图数据库:收集交易数据并将各类交易数据转换为实体、属性结构,并抽取实体之间的关系和关联属性,构建基于图结构的交易关系数据库,即交易图数据库。
具体的,交易数据包括反查数据、登录日志数据、交易记录数据、提现记录数据、账户明细数据、注册信息数据、转账明细数据,这几类数据主要用于收集用户信息、客户端信息以及用户登录客户端进行注册、交易、转账等整个操作过程中所产生的信息。用户信息比如为邮箱、手机号码、登录账号、买家用户ID、卖家用户ID,客户端信息比如为客户端IP、客户端地址,其他还包括交易创建时间、交易状态、交易类型、付款方账号、收款方账号、消费金额等,不做限制。
通过收集交易数据,将以上各类交易数据转换为实体、属性结构,并抽取实体之间的关系和关联属性,从而构建交易图数据库。
二、数据预处理:对收集的各类交易数据存在数据结构不一致、数据质量不高等问题进行预先的数据转换处理,数据转换处理包括数据清洗、数据集成、数据变换、数据归约。
具体的,数据转换处理的方式如下:将各类收集到的数据进行一致性转换,消除同一含义不同表达的差异性,将能关联得出的缺失数据进行缺失填补,维护数据的完整性,对关联数据中存在的冗余属性进行剔除,增补能通过计算得出的属性信息。
三、特征提取:确定要分析的用户偏好模型后,针对用户交易特点对收集的各类交易数据提取相应的静态特征、交易行为特征、交易内容特征、图结构特征等,分析用户交易行为和交易内容。
静态特征包括用户的基本属性信息,比如性别、年龄、用户ID、手机号、银行卡等,不做限制。交易行为特征包括用户交易过程中的频次、周期性、变化性特征,比如最近特定天数的交易金额、交易频次、交易量,转账频次、提现频次等,不做限制。交易内容特征包括用户交易过程中产生的文本数据中提取的内容特征,比如频繁购买的商品类型、商品名称;周期性购买的商品类型、商品名称等,不做限制。图结构特征包括用户交易关系中的相关特征,比如异构交易图的模式结构特征、传播特征、聚类特征等,不做限制。
四、建立交易行为分析模型,挖掘目标对象的交易行为规律,获得目标交易行为偏好的概率。
具体建立的步骤如下:
首先,设定时间窗口t划分数据构造行为特征矩阵,按照如上述步骤三中所提取的交易行为特征构造时间窗口长度为t的行为特征矩阵X,X中包括x
接着采用时序规律分析方法来构建模型构建交易行为分析模型并训练,时序规律分析方法包括但不限于RNN、LSTM、HMMs、ARMA、Holt-winter等。此处以改进的LSTM-R(LongShort-Term Memorywith Reward)奖惩机制的长短期记忆网络模型为例进行介绍。
图2为交易行为分析模型图。如图2,本发明的交易行为分析模型由t个模型单元串联组成,前t-1个模型单元相同,最后一个模型单元在输出的h
由于用户的交易行为会随时间发生变化,所以LSTM-R的第一步就是决定每个模型单元的状态需要丢弃哪些信息,即随着时间的变化用户不在进行的交易操作行为和内容。这部分操作是通过一个称为忘记门的sigmoid单元来处理的。它通过查看h
f
下一步是决定给模型单元状态添加哪些新的信息,即随着时间的变化用户新出现的交易行为和内容。这一步又分为两个步骤,首先,利用h
i
之后将更新旧的模型单元信息C
更新完模型单元状态后需要根据输入的h
o
h
该网络的每个模型单元都由上述步骤组成,最后一层模型单元的输出添加了一个奖惩机制R,第一次训练LSTM的时候R值为0,当优化模型的时候,核实检索交易偏好正确的R值为1,错误的R值为-1,α作为惩罚因子来控制惩罚机制的力度,其取值为0~1,值越大奖惩机制力度越大,值越小奖惩机制力度越小。则最后一层模型单元的计算公式如下:
f
i
o
h
最后,根据模型权重矩阵和预测结果判别交易行为偏好。
五、建立交易内容分析模型,挖掘目标对象的交易内容模式,获得目标交易内容偏好的置信度。
图3为交易内容分析模型图。如图3,本发明的交易内容分析模型具体建立的步骤如下:
首先,对用户的交易详情进行分词处理,识别表示交易内容的有价值的信息,并对交易内容进行词频统计。中文分词有基于词典的机械切分和基于统计模型的序列标注切分两种方式。基于词典的机械切分本质上就是字符串匹配的方法,将一串文本中的文字片段和已有的词典进行匹配,如果匹配到,则此文字片段就作为一个分词结果。基于统计模型的分词方法,简单来讲就是一个序列标注问题,常用的标记有以下四个label:B。Begin,表示这个字是一个词的首字。M,Middle,表示这是一个词中间的字。E,End,表示这是一个词的尾字。S,Single,表示这是单字成词。分词的过程就是将一段字符输入模型,然后得到相应的标记序列,再根据标记序列进行分词。分词方法包括但不限于正向最大匹配算法、逆向最大匹配算法、双向最大匹配算法、基于规则的分词、隐马尔可夫算法、条件随机场模算法、Bi-LSTM-CRF等。
接着根据提取的交易内容特征建立用户与交易内容的关系矩阵G,G中包括g
然后根据用户与交易内容的关系矩阵进行聚类分析,进行交易内容的人群划分。聚类算法包括但不限于K均值聚类、Dbscan聚类、高斯混合模型聚类、期望最大化聚类、Canopy聚类等,不做限制;
之后根据不同的人群进行关联规则分析,挖掘交易内容的频繁模式;频繁模式挖掘算法包括但不限于Apriori、FP-growth等,不做限制;
最后,根据频繁模式的置信度和核实结果的奖惩机制综合判别交易内容偏好。
六、综合交易行为分析模型和交易内容分析模型进行交易偏好判别:按照用户交易行为偏好概率、交易内容偏好置信度、图结构关联关系偏好及核实反馈结果进行加权计算,得到最终的交易偏好判别结果。
具体判别的步骤如下:
首先,按照步骤四中所构建的交易行为分析模型权重的降序排列的前n个特征的均值以及预测出下一时刻的交易行为的值作为用户交易行为的偏好;
接着,按照步骤五中所挖掘的频繁项集的置信度降序排列的前n个频繁项集作为用户交易内容的偏好;
然后,按照步骤三中的图结构特征反映的密切关联人员的前n个偏好作为用户交易的传播偏好;
最后,对前三步的偏好及核实反馈结果进行加权计算,若最终结果高于阈值则进行用户交易偏好推荐,若最终结果低于阈值则不进行推荐,继续进行用户偏好的挖掘。
七、根据交易偏好结果进行核实检索:专业人员定期随机对推荐的用户交易偏好进行核实检索,通过记录检索步骤并对检索步骤进行强化学习来固化核实流程,若核实交易偏好判别正确则以奖励的形式正反馈交易偏好判别模型,若核实交易偏好判别错误则以惩罚的形式负反馈交易偏好判别模型。
具体的,核实检索的步骤如下:
首先按周期随机选择交易偏好结果,由专业人员进行具有先验知识的核实检索,若专业人员判别偏好结果正确,则奖惩机制中的R值为1,若专业人员判别偏好结果错误,则奖惩机制中的R值为-1;
之后,针对专业人员的检索记录,通过强化学习进行检索策略的学习。强化学习算法包括但不限于马尔可夫决策过程、动态规划、蒙特卡洛法、时序差分法、SARSA算法、Q-Learning算法、DeepQ-Learning算法、Nature DQN算法、DoubleDQN算法、PrioritizedReplay DQN算法、DuelingDQN算法、策略梯度算法、Actor-Critic算法、AsynchronousAdvantage Actor-critic算法、Deep Deterministic Policy Gradient算法等,不做限制。
图4为核实检索强化学习模型图。如图4,本发明的核实检索强化学习模型由环境、状态、策略模型三部分组成,其中环境包括交易偏好和核实检索过程,交易偏好体现了用户的交易习惯和感兴趣的内容,核实检索过程体现了专业人员根据偏好进行核实检索的策略过程;状态包括了专业人员的所有检索动作,一次完整的检索由多个检索动作组成;策略模型包括由交易偏好特征、核实检索特征、新交易偏好特征、新核实检索特征训练而得出的检索策略,有效的策略则作为奖励,无效的策略则作为惩罚,不断优化模型生成智能核实检索策略,对每次的用户交易偏好结果进行自动核实反馈。
此处以Deep Q-Learning为例进行核实策略强化学习的介绍。Deep Q-Learning的输入是我们的状态S对应的状态向量
首先设定迭代轮数T,状态特征维度n,动作集A,步长α,衰减因子γ,探索率∈,Q网络结构,批量梯度下降的样本数m;
然后随机初始化Q网络的所有参数w,基于w初始化所有的状态和动作对应的价值Q。清空经验回放的集合D;
最后进行迭代训练直至完成迭代轮数,迭代具体过程如下:
a)初始化S为当前状态序列的第一个状态,拿到其特征向量
b)在Q网络中使用
c)在状态S执行当前动作A,得到新状态S′对应的特征向量
d)将
e)S=S′
f)从经验回放集合D中采样m个样本
g)使用均方差损失函数
h)如果S′是终止状态,当前轮迭代完毕,否则转到步骤b)。
八、根据核实结果动态优化交易偏好判别模型:结合强化学习的核实检索步骤自动进行交易偏好判定结果的核实,根据反馈结果不断优化交易偏好判别模型,形成能够自适应用户行为变化的交易偏好判别模型,进行用户行为偏好的推荐。
具体的,动态优化交易偏好判别模型是通过如下方法进行的:
根据强化学习核实检索策略的结果,智能分析判别后续的交易偏好推荐结果,根据核实推荐的正误,更新惩罚机制R的值,并动态自适应的优化交易偏好判别模型的训练过程,实现交易判别模型根据核实反馈的结果动态的更新模型参数,进行动态的交易偏好判别。
以上所述仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 一种交易偏好判别模型自适应方法
- 一种交易偏好判别模型自适应方法