一种动态环境下视觉定位与静态地图构建方法及系统
文献发布时间:2023-06-19 11:29:13
技术领域
本发明涉及移动机器人定位与地图构建领域,更具体的说,涉及一种动态环境下视觉定位与静态地图构建方法及系统。
背景技术
随着计算机视觉和硬件计算能力的快速发展,视觉SLAM算法已经应用于无人驾驶、移动机器人和无人机等领域,在环境探测、灾害救援等场景发挥着重要作用。视觉SLAM(Simultaneous Localization and Mapping,定位与建图)是搭载着摄像头等视觉传感器的自主移动机器人在没有任何环境先验信息的情况下,进行自主定位并建立周围环境三维地图的重要技术手段。
不过大部分视觉SLAM算法工作时都存在一个静态假设,然而真实环境往往具有动态性。
尽管目前许多优秀的视觉SLAM系统如ORB-SLAM2、ORB-SLAM3等已对由运动物体引入的离群点进行处理,如随机采样一致性(RANSAC)等,其算法通过使用模型区分局内点和噪声,通过多次迭代选择出表现最好的模型。
但是,当动态物体在图像占据较大面积时,运动物体会导致相邻帧的位姿跟踪出现较大误差,从而,降低视觉SLAM系统定位的精度和算法的鲁棒性。
因此,在动态环境下准确实时的定位,一方面是移动机器人在未知环境中稳定工作的基础,另一方面也是构建静态场景地图也是移动机器人规划导航的基础。
Dyna-SLAM采用Mask R-CNN进行运动物体检测去除,但是该方法运行速度较慢,实时性不足。
SaD-SLAM利用语义信息和深度信息发现动态特征点,并且检测出运动目标的静态特征点并对相机位姿进行微调,提高了动态环境下视觉定位的精度,同样,其实时性不足,且没有恢复出场景的静态点云地图,无法服务于移动机器人更上层的规划任务。
发明内容
本发明的目的是提供一种动态环境下视觉定位与静态地图构建方法及系统,解决现有技术中在动态环境下基于视觉传感器定位的精度和实时性差,且没有构建环境的静态稠密点云地图的问题。
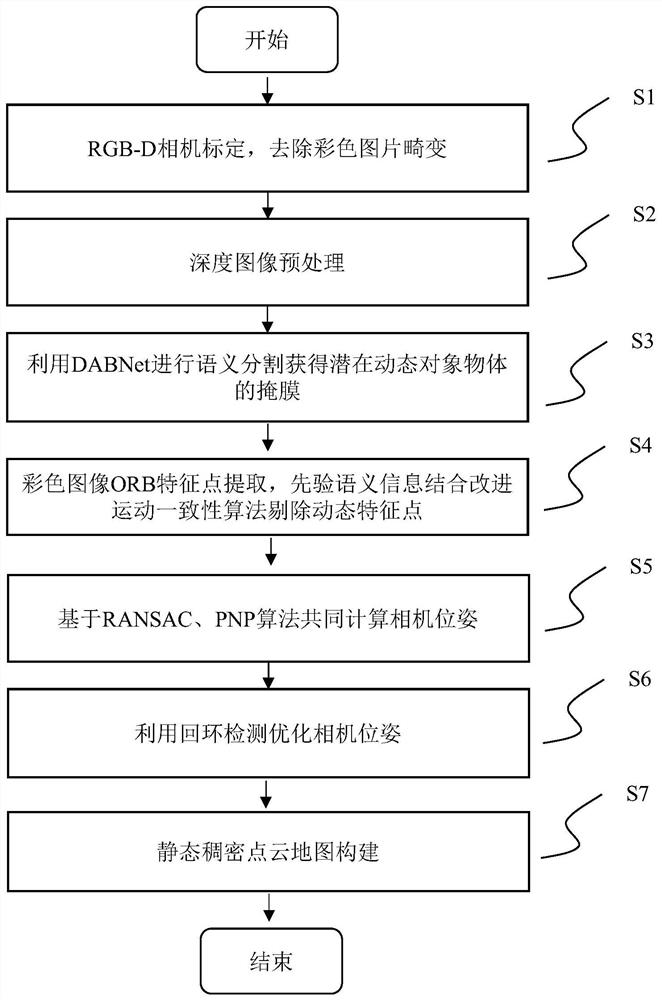
为了实现上述目的,本发明提供了一种动态环境下视觉定位与静态地图构建方法,包括以下步骤:
步骤S1、相机标定,获取相机内参数及畸变参数校正相机畸变;
步骤S2、采用联合双边滤波器进行深度图像预处理;
步骤S3、使用轻量级实时语义分割网络模型分割彩色图像,获得潜在动态对象物体类别,并生成二进制掩膜;
步骤S4、提取彩色图像的ORB特征点,并结合语义先验知识和改进运动一致性判定算法获取真正动态对象上所属的动态特征点并剔除动态特征点,保留剩余静态点;
步骤S5、采用在RANSAC算法框架下通过迭代使用EPnP算法进行位姿跟踪计算,获得最优的位姿估计值;
步骤S6、利用回环检测优化相机位姿;
步骤S7、结合语义先验知识与深度信息构建包含动态对象掩膜的深度图像,选取合适的关键帧,利用彩色图像、基于语义信息去除动态对象后的深度图像以及相机的位姿信息进行空间点云拼接并滤波,构建场景的静态稠密点云地图。
在一实施例中,所述步骤S1,进一步包括:
S11、将相机坐标系的三维空间点P(X,Y,Z),投影到归一化图像平面形成该点的归一化坐标为[x,y]
S12、对归一化平面上的点[x,y]
其中,[x
S13、将校正后的点[x
其中,f
在一实施例中,所述步骤S2,进一步包括:
使用彩色图像来引导深度图像进行加权引导滤波,利用灰度图像中邻域像素灰度值的信息进行加权平均,利用彩色图像中邻域像素的颜色差异表示像素强度,生成滤波后的深度图像;
深度图像滤波后的深度值I
其中,(x,y)为像素点位置的坐标值,I
在一实施例中,所述步骤S3,进一步包括:
轻量级实时语义分割网络模型为DABNet模型,在PASCAL VOC2012数据集上将图片分割成行人和背景在内的2个类别进行训练;
对于每一帧输入的彩色图像,通过训练生成的轻量级实时语义分割网络模型,输出包含动态对象行人的二进制掩膜。
在一实施例中,所述步骤S3,进一步包括:
对输入的彩色图像使用3*3的卷积提取初始特征;
通过采用下采样模块进行三次下采样操作,输出特征图为输入彩色图像的1/8,下采样模块连接3*3卷积模块和步长为2的最大池化模块;
使用连续的DAB模块来提取稠密特征,得到动态对象语义掩码。
在一实施例中,所述步骤S4,进一步包括:
如果语义分割得到的潜在的运动目标范围内存在的动态特征点的数量超过预设阈值,则认为目标是运动的,将其区域内的全部特征点作为局外点去除,使用剩下的静态特征点用于位姿跟踪计算;
否则视为目标是静止的,保留其区域内的特征点,其范围内的特征点和剩下的静态特征点一起全部用于位姿跟踪计算。
在一实施例中,所述步骤S4中改进运动一致性判定算法,进一步包括:
对于当前帧中匹配点P1的齐次坐标和参考帧中匹配点P2的齐次坐标,通过基础矩阵F计算极线L1;
判断匹配点P1与极线L1的位置关系;
如果匹配点P1在极线L1外,则计算匹配点P1到极线L1的距离D,如果D大于预设阈值,则认为该匹配点为动态特征点;
如果匹配点P1在极线L1上,则认为该匹配点为静态特征点。
在一实施例中,匹配点P1到极线L1的距离D,对应的计算公式如下:
其中,P
在一实施例中,所述步骤S4,进一步包括以下步骤:
使用去均值的归一化互相关系数NCC,计算匹配点P1和P2周围大小2×2的像素块之间的相似度,NCC系数的计算公式为,
其中,A、B分别为点P1和P2周围2*2区域内的像素块,Am、Bm分别为其像素块内的均值;
如果两个像素块之间相似度超过设定阈值则认为该匹配点是静态特征点,否则认为该匹配点是动态特征点。
在一实施例中,所述步骤S5,进一步包括:
S51、随机选取4个3D-2D匹配点对,使用EPnP算法求解位姿;
S52、根据求解的相机位姿,将所有3D点重投影为2D点,并计算相机的重投影误差,根据重投影误差阈值大小将点分为局内点和局外点;
S53、判断局内点的数量,如果小于预设阈值,则返回步骤S51重新选取4个匹配点对,如果大于预设阈值,则使用EPnP算法再次计算位姿。
在一实施例中,所述步骤S53,进一步包括:
根据最初的局内点,第一次使用EPnP算法求得位姿T1,根据T1求得一簇新的局内点;
根据所求得的新的局内点,再次使用EPnP算法求解位姿,直至局内点数量大于匹配点对总数量的预设倍数,则认为位姿求解成功,如果位姿求解失败,则返回到S51。
在一实施例中,所述步骤S6,进一步包括:
利用词袋模型来检测是否产生回环,如果产生回环,则进行全局位姿图优化和全局BA优化,完成回环优化。
在一实施例中,所述步骤S7,进一步包括:
将先验的语义掩膜结合到深度图像当中,构建包含语义掩膜的深度图像;
将其掩膜区域内的深度值置为0。
在一实施例中,所述步骤S7,进一步包括:
当新的关键帧生成后,如果该关键帧观测到的地图点信息记录在地图点信息数据库中,则舍弃该关键帧,否则保留为关键帧。
在一实施例中,所述步骤S7,进一步包括:
利用选取的关键帧图像以及对应的包含语义掩膜的深度图像,通过相机模型以及深度信息,将所选取的关键帧图像上的像素点投影到世界坐标系中;
对各点云信息的孤点、异常深度点进行滤除和降采样,对剩余的点云进行拼接操作,完成静态稠密点云地图构建。
为了实现上述目的,本发明提供了一种动态环境下视觉定位与静态地图构建系统,包括:
存储器,用于存储可由处理器执行的指令;
处理器,用于执行所述指令以实现如上述任一项所述的方法。
为了实现上述目的,本发明提供了一种计算机可读介质,其上存储有计算机指令,其中当计算机指令被处理器执行时,执行如上述任一项所述的方法。
本发明提出的一种动态环境下视觉定位与静态地图构建方法及系统,实现移动机器人在动态环境下完成自主定位与地图构建,提高了动态环境中基于视觉定位的精度和实时性,并且为机器人规划导航提供了可用的静态场景稠密点云地图。
附图说明
本发明上述的以及其他的特征、性质和优势将通过下面结合附图和实施例的描述而变的更加明显,在附图中相同的附图标记始终表示相同的特征,其中:
图1揭示了根据本发明一实施例的动态环境下视觉定位与静态地图构建方法流程图;
图2揭示了根据本发明一实施例的轻量级实时语义分割网络模型的网络框架图;
图3揭示了根据本发明一实施例的构建场景的静态稠密点云地图的工作流程图;
图4揭示了根据本发明一实施例的慕尼黑工业大学高动态数据集下的定位轨迹结果图;
图5揭示了根据本发明一实施例的动态环境下视觉定位与静态地图构建系统原理图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释发明,并不用于限定发明。
本发明提出的一种动态环境下视觉定位与静态地图构建方法及系统,主要应用于服务机器人、搜救机器人和无人驾驶等领域,用于移动机器人自主定位与地图构建,对移动机器人在未知环境下的环境感知具有推动意义。
本发明提出的一种动态环境下视觉定位与静态地图构建方法及系统,采用轻量级实时语义分割网络与改进运动一致性方法相结合的方式,去除动态对象所属的动态特征点,提高了动态环境下视觉传感器定位的精度。
由于采用轻量级实时语义分割网络,兼顾定位精度的同时提高了算法的实时性。
另一方面,本发明构建了包含语义掩膜信息的深度图像,通过选取合适的关键帧,进行空间点云拼接和滤波,构建环境场景的静态稠密点云地图,服务于规划导航更上层的任务。
图1揭示了根据本发明一实施例的动态环境下视觉定位与静态地图构建方法流程图,如图1所示,本发明提出的一种动态环境下的视觉定位与静态地图构建方法,包括以下步骤:
步骤S1、相机标定,获取相机内参数及畸变参数校正相机畸变;
步骤S2、采用联合双边滤波器进行深度图像预处理;
步骤S3、使用轻量级实时语义分割网络模型分割彩色图像,获得潜在动态对象物体类别,并生成二进制掩膜;
步骤S4、提取彩色图像的ORB特征点,并结合语义先验知识和改进运动一致性判定算法获取真正动态对象上所属的动态特征点并剔除动态特征点,保留剩余静态点;
步骤S5、采用在RANSAC算法框架下通过迭代使用EPnP算法进行位姿跟踪计算,获得最优的位姿估计值;
步骤S6、利用回环检测优化相机位姿;
步骤S7、结合语义先验知识与深度信息构建包含动态对象掩膜的深度图像,选取合适的关键帧,利用彩色图像、基于语义信息去除动态对象后的深度图像以及相机的位姿信息进行空间点云拼接并滤波,构建场景的静态稠密点云地图。
下面对每一步骤进行详细的说明。
步骤S1、相机标定,获取相机内参数及畸变参数校正相机畸变。
RGB-D相机标定,获取相机内参数,相机径向畸变参数和切向畸变参数k1,k2,k3,p1,p2,从而去除彩色图像畸变。
采用ROS中开源的相机标定工具包获取相机内参数以及相机畸变参数,包括相机内参数f
S11、将相机坐标系的三维空间点P(X,Y,Z),投影到归一化图像平面形成该点的归一化坐标为[x,y]
S12、对归一化平面上的点[x,y]
其中,[x
S13、将相机坐标系下的校正后的点[x
其中,f
步骤S2:采用联合双边滤波器进行深度图像预处理。
在使用联合双边滤波器修复深度图像时,使用彩色图像来引导深度图像进行加权引导滤波,利用灰度图像中邻域像素灰度值的信息进行加权平均,利用彩色图像中邻域像素的颜色差异来表示像素强度,生成滤波后的深度图像。
深度图像滤波后的深度值I
其中,(x,y)为像素点位置的坐标值,I
其中,φ、σ
本实施例中,设置φ=5、σ
步骤S3:使用轻量级实时语义分割网络模型分割彩色图像,获得潜在动态对象物体类别,并生成二进制掩膜。
在本实施例中,轻量级实时语义分割网络模型为DABNet模型。
DABNet模型,通过HDB块连接1x1的卷积来减少模型大小,且DAB结构能同时提取局部和上下文信息,降低了网络模型参数,在相同硬件环境下,比其他的网络结构图像处理速度快30%左右,且有相当的准确性和推理速度。
在本实施例中,通过使用DABNet模型,分割出彩色图像中的先验语义知识库中潜在动态对象,并生成图像的二进制掩膜。
在室内动态环境下仅考虑行人作为潜在动态对象,因此,本发明采用的DABNet模型在PASCAL VOC2012数据集上进行训练,将图片分割成行人和背景在内的2个类别,这种训练方式有利于提高网络训练的精度。
DABNet网络的输入是原始RGB图像,输入是m×n×3大小的RGB图像,输出则是m×n×l大小的矩阵,其中l是图像中物体的个数,对于每个输出通道i∈l,获得一个对象的二进制掩码。
对于每一帧输入的彩色图像通过此训练好的网络模型输出一个包含动态对象行人的二进制掩码。
图2揭示了根据本发明一实施例的轻量级实时语义分割网络模型的网络框架图,如图2所示的轻量级实时语义分割网络模型,
对输入的RGB图像使用3*3的卷积提取初始特征;
采取与ENet相似的下采样模块,下采样模块连接3*3卷积模块和步长为2的最大池化模块。
通过采用三次下采样操作,最终输出的特征图为输入彩色图像的1/8,并且使用连续的DAB模块来提取稠密特征,最终得到动态对象语义掩码。
所述DAB模块(Depth-wise Asymmetric Bottleneck module)是指一种深度非对称瓶颈模块,其利用深度的非对称卷积和空洞卷积来建立一个瓶颈结构。利用DAB模块可以构造充足的感受野并密集的利用上下文信息。
所述ENet是指,2016年学术界提出的一种轻量级语义分割网络,具有较高的实时性能。
步骤S4:提取彩色图像的ORB(Oriented FAST and Rotated BRIEF,快速导向与简要旋转)特征点,并结合语义先验知识和改进运动一致性判定算法获取真正动态对象上所属的动态特征点并剔除动态特征点,保留剩余静态点。
提取彩色图像中的ORB特征点,并结合语义先验知识和改进运动一致性的方法获取真正动态对象上所属的动态特征点。
为了进一步判断潜在的运动物体是否在运动,采用语义先验知识结合改进运动一致性判定算法来判断潜在的运动目标是否真的在运动。
如果语义分割得到的潜在的运动目标范围内存在的动态特征点的数量超过预设的一定阈值,则认为目标是运动的,将其区域内的全部特征点作为局外点去除,使用剩下的静态特征点用于后续的位姿跟踪计算。
否则视为目标是静止的,保留其区域内的特征点,其范围内的特征点和剩下的静态特征点一起全部参与后续的位姿跟踪计算。
改进运动一致性判定算法的基本原理是静态点满足对极几何约束,即物体静止的特征点重投影在参考帧上的匹配点一定落在参考帧与极平面的交线上。
P
其中,当前帧中匹配点P1的齐次坐标和参考帧中匹配点P2的齐次坐标,u
计算极线L1,可通过RANSAC算法和归一化的八点法计算得到。
其中,F为基础矩阵,u
判断匹配点P1与极线L1的位置关系,匹配点P1与极线L1的位置关系有两种:在极线L1上和极线L1外。
如果匹配点P1在极线L1外,则计算匹配点P1到极线L1的距离D,如果D大于预设阈值,则该匹配点为动态特征点。
如果匹配点P1在极线L1上,则认为该匹配点为静态特征点。
匹配点P1到极线L1的距离D,计算公式如下所示:
其中,P
考虑到L1上可能存在着很多和P2相似的点,取P1和P2周围大小为2×2的像素块,来进行块匹配并判断像素块之间的相似度。
在本实施例中,使用去均值的归一化互相关系数NCC来计算匹配点P1和P2周围的像素块之间的相似度。
NCC系数的计算公式为:
其中,A、B分别为点P1和P2周围2×2区域内的像素块,Am、Bm分别为其像素块内的均值;
如果两个像素块之间相似度够高,超过设定阈值则认为是静态特征点,否则认为该匹配点为动态特征点。
步骤S5:采用在RANSAC算法框架下通过迭代使用EPnP算法进行位姿跟踪计算,获得最优的位姿估计值。
为了得到更加准确的位姿估计值,在RANSAC算法框架下迭代使用EPnP算法求解相机位姿,获得误差最小的相机位姿。
随机抽样一致算法(RANdom SAmple Consensus,RANSAC)算法,采用迭代的方式从一组包含离群的被观测数据中估算出数学模型的参数。RANSAC算法被广泛应用在计算机视觉领域和数学领域,例如直线拟合、平面拟合、计算图像或点云间的变换矩阵、计算基础矩阵等方面。
大多数非迭代的PnP算法会首先求解特征点的深度,以获得特征点在相机坐标系中的3D坐标,而EPnP算法将世界坐标系中的3D坐标表示为一组虚拟的控制点的加权和。对于一般情形,EPnP算法要求控制点的数目为4,且这4个控制点不能共面。
所述步骤S5,进一步包括以下步骤:
S51、粗略求解相机位姿。
随机选取4个3D-2D匹配点对,使用EPnP算法粗略求解位姿。
S52、求局内点。
根据粗略求解的相机位姿,将所有3D点重投影为2D点,并计算相机的重投影误差,根据重投影误差阈值大小可将点分为局内点和局外点。
S53、精确求解位姿。
首先判断局内点的数量,如果小于预设阈值,则返回S51重新选取4个匹配点对;
如果大于预设阈值,则使用EPnP算法再次计算位姿。
更进一步的,根据最初的局内点,第一次使用EPnP算法求得位姿T1,根据T1求得一簇新的局内点;
再根据所求得的新的局内点,再次使用EPnP算法求解位姿,如果位姿求解失败,则返回到S51。
如果局内点数量大于匹配点对总数量的预设倍数,则认为位姿求解成功。
在本实施例中,预设倍数为0.4倍。
步骤S6:利用回环检测优化相机位姿。
利用词袋模型来检测是否产生回环,如果产生回环,则进行全局位姿图优化和全局BA优化,完成回环优化,以此来优化相机位姿。
词袋模型是个在自然语言处理和信息检索(IR)下被简化的表达模型。词袋模型下,像是句子或是文件这样的文字可以用一个袋子装着这些词的方式表现,这种表现方式不考虑文法以及词的顺序。
所述回环检测,又称闭环检测,是指机器人识别曾到达某场景,使得地图闭环的能力。
所述全局位姿图优化,将路标点作为对位姿节点的约束,仅优化相机位姿,通过求解最优的相机位姿使路标点在相机平面上的投影误差最小。
所述全局BA优化,根据每一个匹配好的特征点建立方程,联立形成超定方程并求解得到最优的位姿矩阵和三维空间点坐标。
步骤S7:结合语义先验知识与深度信息构建包含动态对象掩膜的深度图像,选取合适的关键帧,利用彩色图像、基于语义信息去除动态对象后的深度图像以及相机的位姿信息进行空间点云拼接并滤波,构建场景的静态稠密点云地图。
图3揭示了根据本发明一实施例的构建场景的静态稠密点云地图的工作流程图,如图3所示的静态稠密点云地图的构建过程,具体包括以下步骤:
步骤S71、参与点云拼接的关键帧选取。
构建地图点的信息数据库,将所有绘图关键帧观测到的地图点信息存入该数据库。
当新的关键帧生成后,如果该关键帧观测到的地图点信息大部分记录在地图点信息数据库中,则舍弃该关键帧,否则保留为绘图关键帧。
步骤S72、语义掩膜深度图像构建。
利用先验的语义掩膜将其结合到深度图像当中,构建包含语义掩膜信息的深度图像。
步骤S73、动态信息去除。
将深度图像的掩膜区域内的深度值置为0,从而去除动态对象信息。
步骤S74、降采样,噪声信息去除。
利用选取的关键帧图像以及对应的包含语义掩膜的深度图像,通过相机模型以及深度信息将所选取的关键帧图像上的像素点投影到世界坐标系中。
对各点云信息的孤点、异常深度点进行滤除和降采样。
步骤S75、静态稠密点云地图。
对剩余的点云进行拼接操作,最终完成静态稠密点云地图构建。
图4揭示了根据本发明一实施例的慕尼黑工业大学高动态数据集下的定位轨迹结果图,如图4所示,本发明提出的动态环境下视觉定位与静态地图构建方法,在慕尼黑工业大学高动态数据集下经过测试,实验结果表明,本发明提出的方法,在兼顾实时性的同时,仍具有较高的定位精度。
图5揭示了根据本发明一实施例的动态环境下视觉定位与静态地图构建系统框图。动态环境下视觉定位与静态地图构建系统可包括内部通信总线501、处理器(processor)502、只读存储器(ROM)503、随机存取存储器(RAM)504、通信端口505、以及硬盘507。内部通信总线501可以实现动态环境下视觉定位与静态地图构建系统组件间的数据通信。处理器502可以进行判断和发出提示。在一些实施例中,处理器502可以由一个或多个处理器组成。
通信端口505可以实现动态环境下视觉定位与静态地图构建系统与外部的输入/输出设备之间进行数据传输与通信。在一些实施例中,动态环境下视觉定位与静态地图构建系统可以通过通信端口505从网络发送和接收信息及数据。在一些实施例中,动态环境下视觉定位与静态地图构建系统可以通过输入/输出端506以有线的形式与外部的输入/输出设备之间进行数据传输与通信。
动态环境下视觉定位与静态地图构建系统还可以包括不同形式的程序储存单元以及数据储存单元,例如硬盘507,只读存储器(ROM)503和随机存取存储器(RAM)504,能够存储计算机处理和/或通信使用的各种数据文件,以及处理器502所执行的可能的程序指令。处理器502执行这些指令以实现方法的主要部分。处理器502处理的结果通过通信端口505传给外部的输出设备,在输出设备的用户界面上显示。
举例来说,上述的动态环境下视觉定位与静态地图构建方法的实施过程文件可以为计算机程序,保存在硬盘507中,并可记载到处理器502中执行,以实施本申请的方法。
动态环境下视觉定位与静态地图构建方法的实施过程文件为计算机程序时,也可以存储在计算机可读存储介质中作为制品。例如,计算机可读存储介质可以包括但不限于磁存储设备(例如,硬盘、软盘、磁条)、光盘(例如,压缩盘(CD)、数字多功能盘(DVD))、智能卡和闪存设备(例如,电可擦除可编程只读存储器(EPROM)、卡、棒、键驱动)。此外,本文描述的各种存储介质能代表用于存储信息的一个或多个设备和/或其它机器可读介质。术语“机器可读介质”可以包括但不限于能存储、包含和/或承载代码和/或指令和/或数据的无线信道和各种其它介质(和/或存储介质)。
本发明提供的一种动态环境下视觉定位与静态地图构建方法及系统,具体具有以下有益效果:
1)用语义分割与改进运动一致性相结合的方式,去除动态对象所属的特征点,提高了动态环境下视觉定位的精度;
2)使用轻量级实时语义分割网络可以减少系统存储资源,并且提高了算法的实时性,便于在高性能嵌入式处理器上运行,满足了室内移动机器人对环境感知的需求;
3)利用语义先验知识结合深度信息,构建包含动态对象掩膜的深度图像,并结合彩色图像和深度图像,位姿信息进行空间点云拼接并滤波,构建场景的静态稠密点云地图,能够服务于机器人运动规划导航更上层的任务。
尽管为使解释简单化将上述方法图示并描述为一系列动作,但是应理解并领会,这些方法不受动作的次序所限,因为根据一个或多个实施例,一些动作可按不同次序发生和/或与来自本文中图示和描述或本文中未图示和描述但本领域技术人员可以理解的其他动作并发地发生。
如本申请和权利要求书中所示,除非上下文明确提示例外情形,“一”、“一个”、“一种”和/或“该”等词并非特指单数,也可包括复数。一般说来,术语“包括”与“包含”仅提示包括已明确标识的步骤和元素,而这些步骤和元素不构成一个排它性的罗列,方法或者设备也可能包含其他的步骤或元素。
本领域技术人员将可理解,信息、信号和数据可使用各种不同技术和技艺中的任何技术和技艺来表示。例如,以上描述通篇引述的数据、指令、命令、信息、信号、位(比特)、码元、和码片可由电压、电流、电磁波、磁场或磁粒子、光场或光学粒子、或其任何组合来表示。
本领域技术人员将进一步领会,结合本文中所公开的实施例来描述的各种解说性逻辑板块、模块、电路、和算法步骤可实现为电子硬件、计算机软件、或这两者的组合。为清楚地解说硬件与软件的这一可互换性,各种解说性组件、框、模块、电路、和步骤在上面是以其功能性的形式作一般化描述的。此类功能性是被实现为硬件还是软件取决于具体应用和施加于整体系统的设计约束。技术人员对于每种特定应用可用不同的方式来实现所描述的功能性,但这样的实现决策不应被解读成导致脱离了本发明的范围。
结合本文所公开的实施例描述的各种解说性逻辑模块、和电路可用通用处理器、数字信号处理器(DSP)、专用集成电路(ASIC)、现场可编程门阵列(FPGA)或其它可编程逻辑器件、分立的门或晶体管逻辑、分立的硬件组件、或其设计成执行本文所描述功能的任何组合来实现或执行。通用处理器可以是微处理器,但在替换方案中,该处理器可以是任何常规的处理器、控制器、微控制器、或状态机。处理器还可以被实现为计算设备的组合,例如DSP与微处理器的组合、多个微处理器、与DSP核心协作的一个或多个微处理器、或任何其他此类配置。
上述实施例是提供给熟悉本领域内的人员来实现或使用本发明的,熟悉本领域的人员可在不脱离本发明的发明思想的情况下,对上述实施例做出种种修改或变化,因而本发明的保护范围并不被上述实施例所限,而应该是符合权利要求书提到的创新性特征的最大范围。
- 一种动态环境下视觉定位与静态地图构建方法及系统
- 一种动态环境下结合语义的视觉定位系统和方法