基于终身机器学习的谣言检测算法
文献发布时间:2023-06-19 11:39:06
技术领域
本发明涉及信息技术领域,特别涉及一种基于终身机器学习的谣言检测算法。
背景技术
随着人类进入互联网时代,越来越多的人开始使用今日头条、新浪微博等在线社交媒体,这些社交媒体充斥着大量的信息,其中有的是虚假信息。逐渐地,在线媒体成为了谣言的新载体。2019年1月17日,中山大学和腾讯公司联合发布了《2018年网络谣言治理报告》。报告指出:2018年微信平台共拦截网络谣言8.4万余条,辟谣文章阅读量近11亿次。其中食品安全、医疗健康、社会民生等领域成为网络谣言重灾区。为了营造一个健康的网络环境,在线谣言检测具有重大的研究价值。
现有的谣言检测模型是在一个给定的数据集上进行训练,这样训练后的模型只能识别出和数据集中相同类型的谣言事件。陈燕方等人表示:谣言并非一成不变,某一时间段的谣言检测结果不能盖棺定论。对于这种“动态”谣言则需要反复检测。而现有谣言检测模型因为不具有持续学习能力,所以可能识别不出“动态”谣言。而新类型谣言的识别,传统谣言检测模型的解决方式是将它们加入到训练集中重新训练,从而产生新的模型。这样做的缺点是重新训练所需的计算代价和存储所有数据所消耗的空间代价很大。
发明内容
本发明所要解决的技术问题是提供一种基于终身机器学习的谣言检测算法,能自动识别微博上的谣言,通过知识来学习新的任务,能解决现有模型存在的不能识别“动态谣言”和识别新类型谣言的问题,模型具有持续学习能力,能持续提升模型的识别准确率。
为实现上述目的,本发明提供以下的技术方案:
该基于终身机器学习的谣言检测算法由一系列学习任务组成,利用从旧任务中获取到的知识来解决新任务中的问题,这些知识存储在知识库(Knowledge Base,KB)中,知识的类型包括训练数据、模型参数和在训练过程中产生的中间模型等,只要有新的任务数据到来,LML就能持续学习,并产生新的知识以供未来任务使用,且积累的知识越多,模型学习的效果越好。当新的任务来临时,即使新任务的训练实例很少,LML模型通过现有知识的传播,新任务也能进行高效地学习。
该基于终身机器学习的谣言检测算法包括如下步骤:
(1)搜集可用于微博谣言检测的公开数据集;
(2)建立谣言检测特征集,并根据这些特征,对数据集进行预处理;
(3)对提取到的特征数据进行归一化处理;
(4)根据终身学习的特性划分为几个任务,每个任务设定一定比例的训练集和测试集,然后将ELLA模型在每个任务中的训练集进行训练,在对应任务中的测试集中进行测试得出每个任务谣言识别的准确率(Acc)和F1评价指标,取这两类指标的平均值作为模型的整体评价指标。
采用以上技术方案的有益效果是:
1、能自动识别微博上的谣言;
2、通过知识来学习新的任务;
3、能解决现有模型存在的不能识别“动态谣言”和识别新类型谣言的问题;
4、模型具有持续学习能力,能持续提升模型的识别准确率。
附图说明
下面结合附图对本发明的具体实施方式作进一步详细的描述。
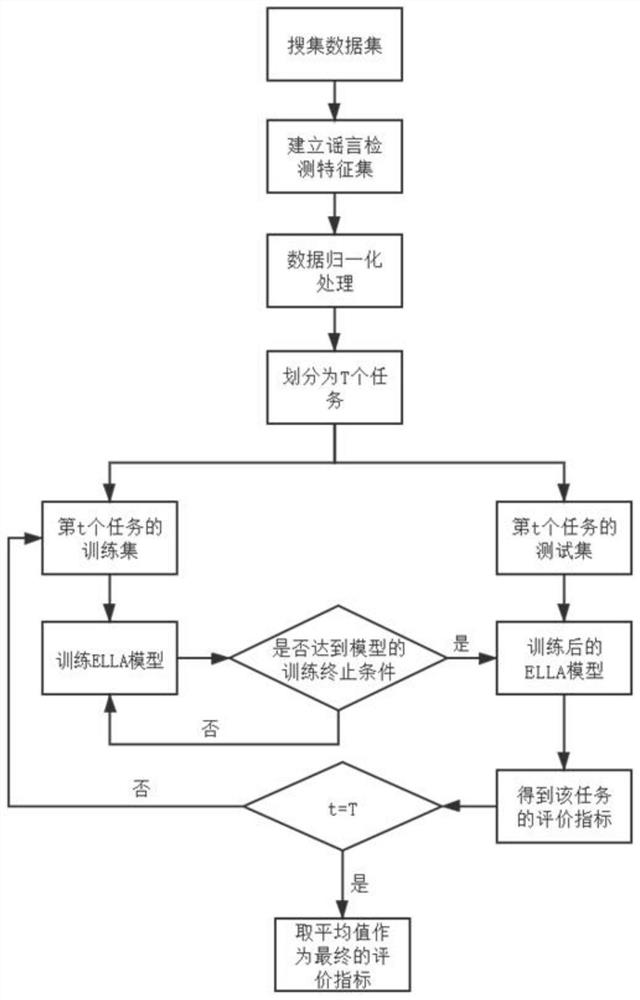
图1是本发明基于终身机器学习的谣言检测算法的技术路线图。
具体实施方式
下面结合附图详细说明本发明基于终身机器学习的谣言检测算法的优选实施方式。
图1出示本发明基于终身机器学习的谣言检测算法的具体实施方式:
如图1所示,该基于终身机器学习的谣言检测算法由一系列学习任务组成,利用从旧任务中获取到的知识来解决新任务中的问题。这些知识存储在知识库(Knowledge Base,KB)中。知识的类型包括训练数据、模型参数和在训练过程中产生的中间模型等。只要有新的任务数据到来,LML就能持续学习,并产生新的知识以供未来任务使用,且积累的知识越多,模型学习的效果越好。当新的任务来临时,即使新任务的训练实例很少,LML模型通过现有知识的传播,新任务也能进行高效地学习。这将节省标注大量数据所付出的时间代价和经济代价。LML像普通机器学习一样分为终身监督、半监督、无监督学习方法。Ruvolo和Eaton提出的ELLA算法是一种终身监督学习算法。该算法是对在线多任务学习算法GO-MTL改进,它解决了GO-MTL存在两个低效问题:(1)计算效率低。若任务数量很多,且每个任务的训练实例的数量也很多,那么迭代计算目标函数效率很低;(2)时空开销大。当有很多任务时,模型对某些参数的计算、优化需要较大的时空开销。ELLA算法使用了二阶泰勒展开等优化策略解决了这两个低效问题,所以把该算法用于构建微博谣言检测模型可以降低计算开销,提高谣言检测的效率。与其他LML算法(如CL-cbsSVM)不同的是,ELLA算法既能进行前向知识传播,来提高新任务的性能,也能进行后向知识传播,提高已学习任务(旧任务)的性能。把ELLA算法应用到谣言检测领域,可以利用其后向知识的传播,时别出之前尚未检测出的“动态谣言”。通过前向知识的传播,识别新的谣言事件,避免因新微博事件的到来,而需要重新训练旧任务数据所付出的计算开销。
该基于终身机器学习的谣言检测算法包括如下步骤:
(1)搜集可用于微博谣言检测的公开数据集;
(2)建立谣言检测特征集,并根据这些特征,对数据集进行预处理;
(3)对提取到的特征数据进行归一化处理;
(4)根据终身学习的特性划分为几个任务,每个任务设定一定比例的训练集和测试集,然后将ELLA模型在每个任务中的训练集进行训练,在对应任务中的测试集中进行测试得出每个任务谣言识别的准确率(Acc)和F1评价指标,取这两类指标的平均值作为模型的整体评价指标。
该基于终身机器学习的谣言检测算法使用的数据为微博谣言检测数据集,它的统计数据表1所示:
表1
为了区分微博上的谣言与非谣言,从之前的研究中寻找到如下18个特征用于模型的训练,特征包含三类:内容,结构和用户,如表2所示。
表2
由于实验涉及4664条微博,所以本文划分了4个任务,即T为4。每个任务包含1166条微博事件。训练集:测试集=5:5。
为了验证ELLA谣言检测模型的有效性,采用多种模型与本文模型进行对比。由于本文模型采用多任务学习,每个任务都会得到一个分类指标,所以将多个任务上的分类指标取平均值作为模型的整体分类指标。本文选取的模型包括SVM-RBF、GBDT、GLAN和NM-DPS。对比结果如表3所示:
表3
以上的仅是本发明的优选实施方式,应当指出,对于本领域的普通技术人员来说,在不脱离本发明创造构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
- 基于终身机器学习的谣言检测算法
- 基于时序切分与融合的谣言早期检测算法