融合主成分分析与双堆过滤的降维并行图像特征匹配算法
文献发布时间:2024-04-18 19:58:30
技术领域
本发明涉及图像特征匹配技术领域,具体是一种融合主成分分析与双堆过滤的降维并行图像特征匹配算法。
背景技术
车载全景环视系统通过对多个车载摄像点位所捕捉到的局部道路图像进行拼接,实时输出以当前车辆为中心的360°全景环视图像,能够显著提升智能车辆对周围道路环境的感知能力和行车安全。车载全景环视技术的核心在于不同局部道路图像之间高维特征点的高效匹配。考虑到智能驾驶对道路环境感知的实时性要求,如何高效、精准地将局部道路图像之间的海量高维特征点进行匹配已成为当前智能驾驶领域中的热点和难点。
当前已经有部分学者对高维图像的特征匹配展开研究工作,大致可以分为以下三类:
(1)暴力匹配法,即通过将待匹配特征点与参考特征点逐一进行相似性比较,寻找具有最高相似度的参考特征点作为最佳匹配。田嘉禾等采用基于欧氏距离的暴力匹配法,对待匹配特征点进行相似性比较,且根据动态阈值的比值测试判定匹配点对,有效提升了匹配鲁棒性。谢红梅等提出了一种双向暴力匹配策略,针对待匹配的特征点对,计算其各自的最近邻和次近邻之间的距离比值,并依据待匹配点对数量的变化自适应的调整阈值,有效的解决了“一对多的”匹配问题。此类算法在特征数量较少且维度较低时,能快速的获得准确匹配,但在面对高维特征点匹配问题时,此类算法的匹配效率受限。
(2)特征降维法,即通过将图像的高维特征表示转化为低维特征表示,从而减少计算复杂度并去除冗余信息,以实现更有效和精确的图像特征匹配。Zhang T等在SURF算法基础上引入圆形领域描述符提取方法,降低了描述符的维度,并采用最小欧氏距离准则进行匹配,有效提升了匹配速度。李旋等提出了一种基于局部线性嵌入的特征降维方式,在降维的同时保持了特征的局部线性关系,增强了在变形和旋转匹配时的鲁棒性。此类算法虽然能在一定程度上优化特征描述符的维度,提高匹配速度,但降维程度均有限,并不适用于道路图像之间的海量高维特征点。
(3)深度学习匹配算法,即通过大规模数据学习来获取高维特征点之间的匹配规律,实现高效、准确的特征点匹配。段芸杉等采用基于单应性变换的CNN提取特征点,并采用交叉注意力机制的神经网络进行高维特征点匹配,有效地解决了在较大视差和扭曲变换下特征匹配效果差的问题。宋佳璇等结合神经网络融合图像灰度信息形成特征描述网格,并利用同名点约束匹配区域进行分组匹配,有效地解决了图像跨视角特征内容突变所带来的匹配问题。此类算法可以自动学习特征表示、处理高维特征关系,但基于人工智能的特征匹配需要较大的计算资源,实时性较差,且对异常数据较为敏感,易出现过拟合现象。
由此可见,当前针对高维特征匹配的算法均存在匹配效率低、实时性差的问题,距离其在车载全景环视系统上的落地应用还存在较大的提升空间。针对上述问题,为满足车载全景环视系统对局部道路图像拼接在实时性和匹配精度方面的要求,需要提出新的图像特征匹配算法,以提高图像特征点的匹配速度,并保证特征匹配的精度。
发明内容
本发明所要解决的技术问题是针对上述现有技术的不足提供一种融合主成分分析与双堆过滤的降维并行图像特征匹配算法,本算法采用主成分分析法将特征点集投影至低维空间,并采用计算成本更低的平方欧氏距离进行排名估计,以进行特征点匹配;为了消除误匹配现象,使用双堆过滤算法对特征点进行提纯,保证了特征匹配的精度;采用了并行结构,可方便推广至多核系统中,提高了图像特征点的匹配速度,满足全景环视技术对局部道路图像融合的实时性要求。
为实现上述技术目的,本发明采取的技术方案为:
一种融合主成分分析与双堆过滤的降维并行图像特征匹配算法,包括以下步骤:
步骤1、将待匹配的两幅图像分别记为
步骤2、采用主成分分析法将原始空间中的图像
步骤3、判断在参考特征点集合R中,是否存在与查询特征点集合Q中查询特征点q
步骤3.1、在PCA空间中,将参考特征点集合R
步骤3.2、采用双堆过滤算法分别对w个子集中的参考特征点进行过滤,生成每个子集的k最近邻结果;
步骤3.3、将每个子集的k最近邻结果依次添加至最大堆中,调整最大堆使得最大堆内生成k最近邻结果;
步骤3.4、选取最大堆内的k最近邻结果中与查询特征点q
步骤4、按照步骤3的方法,分别判断查询特征点集合Q中每个查询特征点是否存在正确匹配的参考特征点,进而获得所有正确的匹配点对,进而实现图像
作为本发明进一步改进的技术方案,所述的步骤3.2,具体为:
步骤3.2.1、在PCA空间中,计算单个子集中所有参考特征点与查询特征点q′
步骤3.2.2、过滤单个参考特征点:在PCA空间中,计算某个参考特征点与查询特征点q′
步骤3.2.3、返回步骤3.2.2,分别对子集中每个参考特征点进行过滤,得到最新的过滤堆,根据最新的过滤堆中的距离值排序,选取k个最近邻对应的平方欧氏距离值,即为子集的k最近邻结果;
步骤3.3.4、返回步骤3.2.1,按照步骤3.2.1-步骤3.2.3的方法分别对w个子集中的参考特征点进行过滤,生成每个子集的k最近邻结果。
作为本发明进一步改进的技术方案,所述的步骤3.3,具体为:初始的最大堆为空集,将每个子集的k最近邻结果依次添加至最大堆中,比较最大堆中的距离值大小进而不断调整最大堆,使得最终的最大堆内保留有k最近邻结果,即k个最近邻对应的平方欧氏距离值。
作为本发明进一步改进的技术方案,所述的步骤3.4中的预设像素值为1.5个像素。
作为本发明进一步改进的技术方案,还包括:
步骤5:判断在参考特征点集合R中,是否存在与查询特征点集合Q中查询特征点q
步骤5.1、在PCA空间中,将参考特征点集合R′划分为w个子集;查询特征点q
步骤5.2、计算单个子集中的所有参考特征点与查询特征点q
步骤5.3、按照步骤5.2的方法分别判断每个子集中是否存在与查询特征点q
步骤6、按照步骤5的方法,分别判断查询特征点集合Q中每个查询特征点是否存在粗匹配的参考特征点,进而获得所有粗匹配点对;
步骤7:计算匹配准确率,匹配准确率为正确匹配点对数占总匹配点对数的百分比,其中总匹配点对数为粗匹配点对数。
作为本发明进一步改进的技术方案,所述的步骤5.2中,根据最近邻距离与次近邻距离的比值判断该子集中是否存在与查询特征点q
最近邻距离与次近邻距离的比值公式(1)为:
其中,d
作为本发明进一步改进的技术方案,所述的步骤2具体为:
步骤2.1、将原始空间中所有参考特征点和查询特征点的特征描述符组成矩阵S,采用奇异值分解方法求取矩阵S的特征值和特征向量,根据特征值与累计贡献率预设值求取达到累计贡献率时对应的主成分个数c;
步骤2.2、根据主成分个数c选取前c个最大的特征值对应的特征向量,由选取的特征向量组成投影矩阵P;
步骤2.3、根据投影矩阵P,将原始空间中的图像
作为本发明进一步改进的技术方案,步骤2.1中,累计贡献率预设值为累计贡献率预设范围值,求取达到累计贡献率预设范围值时对应的主成分个数c的范围值;
按照步骤3-4的方法并根据不同的主成分个数c的值计算得到待匹配的两幅图像之间的正确匹配点对数;
设定评价指标,根据评价指标评价不同的主成分个数c的值对应的匹配性能,选取匹配性能最优时对应的主成分个数c的值作为最终的主成分个数c的值用于步骤2中来计算投影矩阵P,最终获得两幅图像之间所有正确的匹配点对。
本发明的有益效果为:
本发明提出了一种融合主成分分析和双堆过滤的高性能降维并行匹配算法。通过主成分分析法将特征点集投影至低维空间,并采用平方欧氏距离进行排名估计,有效降低了匹配过程中的计算复杂度。同时,为保证特征匹配的精度,本发明算法采用双堆过滤算法对匹配点对进行提纯。此外,本发明算法还采用了并行结构,充分利用了计算资源,提高了整体算法的匹配速度。从实验结果来看,本发明算法在匹配总时间、匹配准确率和匹配误差均方根等方面相较于传统的图像特征匹配算法具有明显的优势。综上,本发明算法在兼顾匹配准确率的同时具有较好的匹配实时性,能够应用于局部道路图像之间高维特征点的高效匹配。
附图说明
图1为三维特征点及其在PCA空间中的投影示意图。
图2为错误匹配现象示意图。
图3为双堆过滤算法示意图。
图4为多核并行匹配策略图。
图5为参数c和α对算法性能的影响示意图。
图6为被划分的子集个数对算法性能的影响示意图。
图7为不同算法匹配时间对比结果示意图。
图8为不同算法匹配准确率对比结果示意图。
图9中(a)为查询图像示意图。
图9中(b)为参考图像示意图。
图9中(c)为SIFT算法的匹配效果示意图。
图9中(d)为SURF算法的匹配效果示意图。
图9中(e)为SUPD算法的匹配效果示意图。
图10为不同算法匹配误差均方根对比结果示意图。
具体实施方式
下面根据附图对本发明的具体实施方式作出进一步说明:
本文在SURF算法的基础上,提供了一种融合主成分分析与双堆过滤的降维并行图像特征匹配算法,即SUPD(SURF combining PCA and DHF)算法。针对传统SURF算法的高维描述符导致的计算复杂问题,SUPD算法采用主成分分析法(Principal ComponentAnalysis,PCA)将特征点集投影至低维空间,并采用计算成本更低的平方欧氏距离(SquareEuclidean distance,SED)进行排名估计,以进行特征点匹配。同时,为了消除误匹配现象,SUPD算法还使用了双堆过滤算法(Double Heap Filter,DHF)对特征点进行提纯,保证了特征匹配的精度。由于SUPD算法采用了并行结构,可方便推广至多核系统中,以提高图像特征点的匹配速度,满足全景环视技术对局部道路图像融合的实时性要求。
1、系统模型:
考虑近邻车载摄像点位L
定义1(特征点匹配时间):定义σ
其中,
定义2(匹配准确率):定义匹配准确率ξ为满足变换矩阵H的匹配点对数N
定义3(匹配效率):定义匹配效率E为匹配准确率ξ除以特征点匹配时间t。根据以上定义,即可将局部道路图像的匹配过程描述为如式(3)的数学优化问题。
其中,式(3)为局部道路图像匹配过程中完成特征点匹配的目标函数,E的值越高,则证明算法的匹配效率越好。约束条件(4)要求正确匹配的特征点对数
2、SUPD算法:
为了满足全景环视系统在匹配精度和实时性方面的要求,本文提出了一种全新的环视图像特征匹配算法,名为SUPD算法。该算法综合了PCA算法和DHF算法的优势,旨在对高维度的特征点进行降维匹配和过滤提纯。同时,通过并行的匹配策略充分利用计算资源,进一步加快算法的匹配效率。
2.1、基于PCA降维的距离排名:
主成分分析法是一种常用的降维方法,其基本思想是将高维数据投影至低维空间,提取主要特征并减少冗余信息,从而在后续的数据分析和建模过程中提供更简洁、高效的数据表示。将其应用于特征点匹配领域,即利用投影矩阵P,将高维原始空间中的特征点集投影至低维空间(PCA空间)中进行距离估计,进而预测查询特征点和参考特征点的相似程度。
本文采用奇异值分解求取投影矩阵P,对于原始空间中所有参考特征点和查询特征点的特征描述符组成的矩阵S,其奇异值分解式如式(5)所示。
S=UZV
其中,U、V分别为SS
由式(5)可得S的特征值和对应的特征向量,并根据S的特征值计算累计贡献率和达到累计贡献率时对应的主成分个数c,其计算公式如式(6)所示。
其中,m为主成分总数,μ为累计贡献率,一般取μ值为85%~95%。λ
由于在主成分分析中每个主成分对应一个特征值和特征向量,根据达到累计贡献率时的主成分个数c值,根据主成分个数c选取前c个最大的特征值对应的特征向量,由选取的特征向量组成投影矩阵P;投影矩阵P的每一列都是一个主成分的特征向量。
在求得投影矩阵P之后,即可将参考特征点集R={r
完成投影后,即可在PCA空间中计算每个参考特征点r
其中,d为PCA空间的维数。
根据SED的排名即可求得与查询特征点q′
如图1所示,以一个三维向量为例,其中q为查询特征点,A,B,C,D为参考特征点,将所有特征点投影至PCA空间中进行降维,得到投影点分别为q′,A′,B′,C′,D′。距离排名如表1所示,在PCA空间中,基于SED排名的参考特征点顺序为A′-B′-C′-D′,与原始三维空间中的欧氏距离(Euclidean distance,ED)排名A-B-C-D相同。最后通过最近邻与次近邻的距离比确定粗匹配点对。其计算公式如式(9)所示。
其中,d
表1、三维特征点的正确排名估计:
2.2、双堆过滤算法:
虽然可以在低维PCA空间中采用平方欧氏距离排名的方式预测查询特征点和参考特征点的相似程度,但偶尔也会出现错误匹配,如图2和表2所示,在PCA空间中的距离排名为A′-B′-C′-D′,但在原始三维空间中的距离排名为B-A-C-D,若只根据PCA空间中的距离排名进行匹配,则有可能会产生错误的匹配点对。
表2、三维特征点的错误排名估计:
为解决上述问题,本文在PCA排名预测的基础上,提出了一种双堆过滤算法(DHF),即维护了两个筛选堆,在PCA空间中的称为过滤堆,在原始空间中的称为验证堆,两个堆分别保留各自的αk个和k个最近邻距离结果,对投影后的特征点进行过滤。过滤堆和验证堆的结构如图3所示。在PCA空间中,单个集合中,计算所有参考特征点与查询特征点q′
DHF在过滤特征点时,首先,计算PCA空间中参考特征点和查询点投影之间的平方欧氏距离SED,若该距离大于等于过滤堆中的距离最大值,则舍弃该参考特征点,若该距离小于过滤堆中的最大值,则进一步计算在原始空间中该参考特征点和查询特征点之间的欧氏距离ED,若该距离大于等于验证堆中的距离最大值,则舍弃该参考特征点,若小于最大值,则认为判定正确,将该欧氏距离值和投影的平方欧氏距离值分别插入验证堆和过滤堆中替换各自初始的最大值并重新排序。
DHF中的调节因子α与最近邻个数的关系为k′=αk。α用于调节过滤堆的大小,可有效减少只使用部分主成分信息而导致算法过滤性能不佳的现象,后续将通过实验分析确定α与k的值。
经DHF算法过滤后的匹配点对可以有效避免图2中的错误匹配现象。且DHF算法采用了基于KNN的堆结构,能够减少距离计算和比较的次数,提高查询效率,从而进一步提高整体算法的实时性。
2.3、多核并行匹配策略:
传统的匹配算法通常需要按照参考特征点索引顺序进行匹配,且匹配时只能以一个参考点的匹配任务为单位。例如,基于kd树的匹配算法需按照树状索引不断地搜索参考特征点,但由于整体的参考特征点数量庞大,这样的匹配方式会导致单个查询点的匹配过程中计算量巨大,使得系统的负载难以均衡。
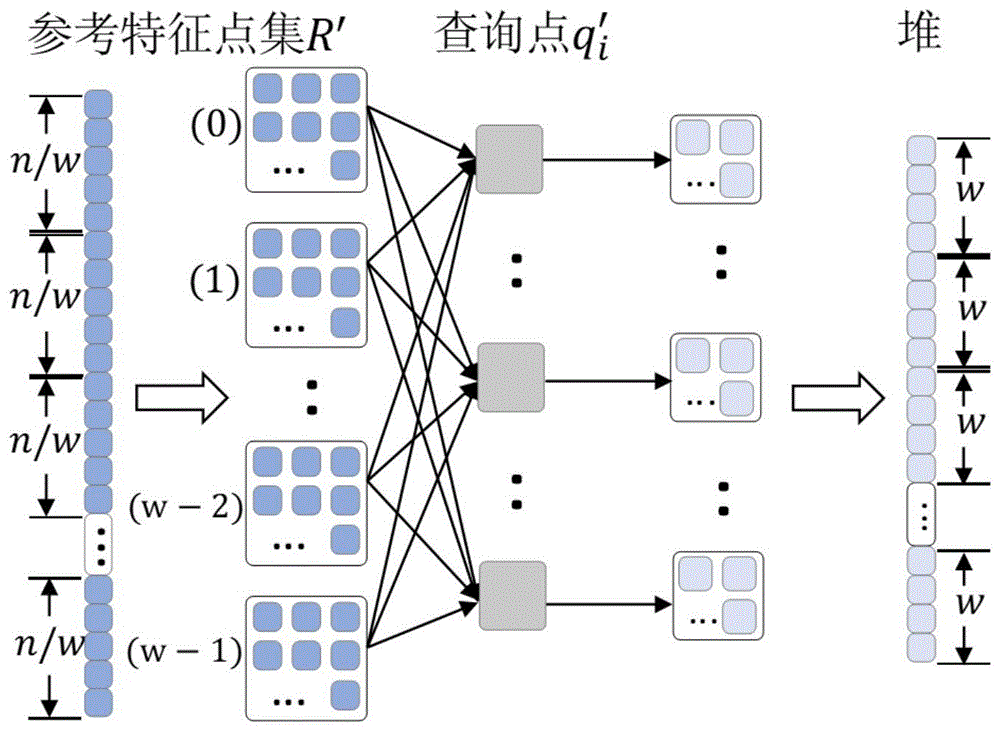
由于本文的匹配算法对每一个参考特征点的匹配任务是相对独立的,所以在处理数量庞大的参考特征点时特别适合并行化处理。为此,本文设计了一种多核并行匹配策略,如图4所示。
在特征点进行匹配时,首先将PCA空间中被投影的参考特征点集R′划分为w个子集。接着在按顺序对每个被投影的查询特征点q′
综上所述,本文提供的融合主成分分析与双堆过滤的降维并行图像特征匹配算法,包括以下步骤:
步骤1、将待匹配的两幅图像分别记为
步骤2、采用主成分分析法将原始空间中的图像
步骤3、判断在参考特征点集合R中,是否存在与查询特征点集合Q中查询特征点q
步骤3.1、在PCA空间中,将参考特征点集合R′划分为w个子集;查询特征点q
步骤3.2、采用双堆过滤算法分别对w个子集中的参考特征点进行过滤,生成每个子集的k最近邻结果:
步骤3.2.1、在PCA空间中,计算单个子集中所有参考特征点与查询特征点q′
步骤3.2.2、过滤单个参考特征点:在PCA空间中,计算某个参考特征点与查询特征点q′
步骤3.2.3、返回步骤3.2.2,分别对子集中每个参考特征点进行过滤,得到最新的过滤堆,根据最新的过滤堆中的距离值排序,选取k个最近邻对应的平方欧氏距离值,即为子集的k最近邻结果;
步骤3.3.4、返回步骤3.2.1,按照步骤3.2.1-步骤3.2.3的方法分别对w个子集中的参考特征点进行过滤,生成每个子集的k最近邻结果;
步骤3.3、将每个子集的k最近邻结果依次添加至最大堆中,比较最大堆中的距离值大小进而不断调整最大堆,使得最终的最大堆内保留有k最近邻结果,即k个最近邻对应的平方欧氏距离值。初始时,最大堆是空的。然后,每个子集生成的k个最近邻结果中的距离值被依次添加到最大堆中。在添加新元素时,最大堆会自动调整,确保距离最大的元素始终位于堆的顶部。如果新的距离度量值小于堆顶的最大值,堆顶最大值将被删除,然后新的距离值将被插入并重新调整堆。这个过程重复进行,直到所有子集的k个最近邻结果都被处理,确保最大堆中的k个距离值一直表示最接近的k个距离。
步骤3.4、选取最大堆内的k最近邻结果中与查询特征点q
步骤4、按照步骤3的方法,分别判断查询特征点集合Q中每个查询特征点是否存在正确匹配的参考特征点,进而获得所有正确的匹配点对,最终可以实现图像
步骤5:判断在参考特征点集合R中,是否存在与查询特征点集合Q中查询特征点q
步骤5.1、在PCA空间中,将参考特征点集合R
步骤5.2、计算单个子集中的所有参考特征点与查询特征点q
最近邻距离与次近邻距离的比值为:
其中,d
步骤5.3、按照步骤5.2的方法分别判断每个子集中是否存在与查询特征点q′
步骤6、按照步骤5的方法,分别判断查询特征点集合Q中每个查询特征点是否存在粗匹配的参考特征点,进而获得所有粗匹配点对。
步骤7:计算匹配准确率,匹配准确率为正确匹配点对数占总匹配点对数的百分比,其中总匹配点对数为粗匹配点对数。
3、性能分析:
3.1、时间和空间复杂度分析:
本节将使用暴力搜索(BF)作为对比算法,分析本文算法的时间和空间复杂度。对于单个查询特征点的匹配,BF算法通过穷举法在原始空间中计算并匹配所有参考特征点的距离。由于原始空间维度较高,BF算法需要遍历所有参考特征点,导致其空间复杂度较高,为O(ND),其中N为参考特征点数量,D为原始高维空间的维度。
然而,在实际匹配过程中如果避免大部分非必要的距离计算,算法性能则会有大幅提升。SUPD算法恰好具备这一特点。该算法将特征点投影至低维PCA空间,并利用基于KNN的DHP算法进行过滤。其中,KNN算法的空间复杂度主要源自kd树的构建,而kd树的搜索过程则不需要额外的存储空间。因此,降维并经过过滤后的空间复杂度为O(Nd),其中d为PCA空间的维度,从后续的实验结果可以得出d远小于D。同时,为充分利用计算资源,本文将参考特征点集分成w个子集,并分配给每个线程进行并行匹配,进一步降低了空间复杂度,仅为O(Nd/w)。
假设BF算法在原始空间中为完成一个查询特征点的所有距离计算需要的总时间为T
3.2、参数分析:
SUPD算法的主要参数包括达到累计贡献率的主成分个数c、双堆过滤的最近邻个数k和调节因子α、投影的参考特征点集被划分的子集个数w。在本节中将分析各个参数的具体取值范围,为后续的参数设置实验做准备。
首先,在使用主成分分析(PCA)进行降维时,需确定保留的主成分个数,即降维后的维度。过多的主成分(c值较大)会导致降维后的数据仍保持较高维度,增加计算和存储开销,同时也可能会带入噪声。而过少的主成分则会导致降维后的数据无法充分表达原始数据的特征,造成信息丢失。因此,选取合适的主成分个数c至关重要。而保留的主成分个数c可以通过计算累计贡献率μ来确定,根据现有文献可得,一般取值范围为85%~95%。本文建议选取μ为65%对应的主成分个数c
接着,使用双堆过滤算法(DHP)来精炼提取的匹配点对。过滤堆的大小为α×k,其中k是验证堆中的最近邻数量。验证堆用于验证过滤堆中初步提纯的匹配点对,因此k值不宜过大。在大多数基于knn的特征匹配算法中,通常将k设为2,因此,本文也将k设定为2。而过滤堆的调节因子α影响初次过滤得到的匹配点对数量。若α设定过大,由于验证堆的计算使用原始高维空间中的欧氏距离,这将导致计算复杂度增加,严重影响算法的实时性。而将α设置的过小,可能会出现错误过滤,即投影空间(PCA空间)中的某个参考特征点与查询点的距离大于过滤堆的最大值,但在原始空间中该点与查询点的距离却小于验证堆的最大值,从而导致在实际匹配时将该点错误的过滤掉。且当α=1时,过滤堆与验证堆大小相同,无法体现过滤堆的作用。因此,本文将α选取范围设定为[2,5],且通过实验确定最合适的α值,实现最佳的过滤效果。
最后,将被投影的参考特征点集划分成w个子集,进行并行匹配。子集划分个数w影响着是否能够最大程度地使用计算资源,从而提高算法性能。子集的划分数量决定了并行任务的粒度,较小的任务粒度使得数据局部性更好,减少内存访问冲突,同时也更容易实现均衡的负载。但也不宜划分过小,任务粒度过小也会导致频繁的通信和同步操作,增加计算开销。同时,在划分子集个数w时,也应该考虑实验平台的内核数。内核数反映了可以并行执行任务的上限。因此,为了最大程度地利用计算资源并实现最佳并行性能,本文将子集划分个数w的范围设定为
4、结果与分析:
4.1、实验准备:
4.1.1、实验平台:
本实验硬件平台为AMD Opteron Processor 6376CPU@2.30GHz,16MB L3缓存,16内核,32逻辑处理器,128GB内存;软件平台为windows10 64位操作系统,Visual StudioCode,Opencv4。
4.1.2、实验数据:
为满足研究需求,本文采用了自行构建的数据集,共100组具有一定重叠度的局部道路图像,这些图像涵盖多种道路情境,且在视角、光照条件以及天气状况等方面呈现出明显的多样性。
4.1.3、实验评价指标:
1)匹配总时间(tota_time):特征提取和特征匹配所消耗时间的总和,其中特征匹配时间又包括剔除错误匹配和进行局部优化等所消耗的时间。其定义如式(10)所示。
tota_time=T
其中,T
2)匹配准确率(matching_accuracy):作为算法精度的评价指标,匹配准确率为正确匹配点对数占总匹配点对数的百分比。其定义如式(11)所示。
其中,N
3)匹配误差均方根(MERD):作为查询图像和参考图像之间的总体匹配点对的匹配评价指标,MERD越小,说明总体的匹配质量越好,反之,则总体匹配质量越差。其定义如式(10)所示。
其中,(x
4.2、参数的确定:
本节将根据第3.2小节中分析的参数范围,通过实验来界定在算法达到最优性能状态时,各个参数的确切取值。在进行实验之前,首先明确参数选择的评价指标,其定义如下。
a)提升比:暴力匹配的匹配时间除以本文算法的匹配时间。
b)加速比:算法的串行匹配时间除以并行匹配时间。
c)综合效能指数:即提升比乘以匹配准确率,综合考虑算法的运行时间和匹配精度。
根据第3.2节的分析计算得出在累计贡献率为65%和95%的情况下,自行构建数据集所对应的主成分个数分别为5和20。因此,本文选取主成分个数c在区间[5,20]内进行分析,评估其对算法性能的影响。此外,鉴于主成分个数c和过滤堆的调节因子α在不同取值范围内可能相互影响,而子集划分个数w则相对独立。因此,在设定w=10的前提下,通过综合实验分析主成分个数c和调节因子α对算法性能的影响。
实验结果如图5所示,在不同的过滤堆调节因子α条件下,综合效能指数与主成分个数之间的变换趋势类似,且在设定的范围内,α的值越小,整体的综合效能指数越大。同时,随着主成分个数c的增加,保留的特征信息也相应增加,匹配准确率也大幅上升,从而使得综合效能指数也增大,但当c值超过某一阈值时,匹配准确率的提升逐渐趋于平稳,而匹配时间却相应的增大,从而导致综合效能指数降低。因此,基于实验结果得出适合本文数据集的最佳(c,α)为(14,2)。
鉴于子集划分个数w具有较高的独立性,不受主成分个数和过滤堆调节因子的影响,本文将对其单独进行实验,分析其对算法性能的影响。
实验结果如图6所示,随着w的增加,加速比呈递增趋势。当w达到实验平台的最大内核数时,加速比达到其极值,这表明此时计算资源得到最优化的利用,进而使匹配时间达到最短。不过,值得注意的是,一旦w超出最大内核数,可能引发调度开销增加和负载不均衡等并行计算问题,从而导致加速比逐渐减小,匹配时间逐步延长。因此,基于实验结果得出最合适的子集划分个数w为16。
4.3、实验结果:
为验证SUPD算法的性能,本文将数据集按照颜色、纹理等复杂度分成5组,实验组从1到5,复杂程度依次上升。每组实验数据取平均值,分别进行了匹配总时间、匹配准确率以及匹配误差均方根的性能测试,同时,还与传统的SIFT和SURF算法进行了对比实验,以获得更全面的性能比较结果。其中SIFT和SURF算法均搭配OpenCV中自带的暴力匹配算法进行特征匹配。
4.3.1、匹配总时间分析:
匹配总时间作为一项重要指标,能够有效衡量算法的实时性。图7展示了SUPD算法与其它两种传统算法的匹配总时间对比结果。从中可以看出SUPD算法在匹配总时间方面明显优于传统的SIFT和SURF算法,缩短了77%~80%的时间。这种实时性的改善源自SUPD算法的特定设计。该算法采用了主成分分析方法对特征描述符进行降维处理,从而有效地降低了计算复杂度。此外,SUPD算法引入了多核并行匹配策略,使得多个处理核心能够同时执行匹配操作。这不仅加速了计算过程,还提升了系统的吞吐能力,从而显著提高了整体算法的运行速度。
因此,相较于传统SIFT和SURF算法,SUPD算法通过主成分分析降维和多核并行匹配策略的引入,实现了在匹配总时间方面的显著性能优势,展现了更为出色的实时性表现。
4.3.2、匹配准确率分析:
匹配准确率能够有效地反映特征匹配算法的精度和鲁棒性。其计算方法如式(11)所示。图8展示了SUPD算法与其它两种传统算法的匹配准确率对比结果。对比可得,与传统的SIFT和SURF算法相比,SUPD算法提升了5%~15%的准确率。为更加直观的展示匹配准确率对比结果,本文以第三组中第一次实验的匹配效果为例,分析SUPD算法与传统SIFT和SURF算法在匹配准确率方面的优劣对比,如图9所示。
从图9中的(c)、图9中的(d)可以看出,传统的SIFT和SURF算法存在较多的交叉匹配、重复匹配等误匹配现象,从而导致较低的匹配准确率。而SUPD算法的匹配效果如图9中的(e)所示,该算法通过DHF算法中的维护的两个筛选堆对匹配点对进行过滤提纯,有效地改善了误匹配现象,保证了较高的匹配准确率。因此,相较于传统SIFT和SURF算法,SUPD算法在匹配精度上具有明显的优势。
4.3.3、匹配误差均方根分析:
为了更加直观的体现整体特征点对之间的匹配质量,本文引入了匹配误差均方根(MERD)作为评价指标,MERD的值越小,代表整体特征点对的匹配质量越高,反之则匹配质量较差。MERD的计算公式见式(12)。图10展示了SUPD算法与其它两种传统算法在MERD上的对比结果。可以看出,SUPD算法的MERD值均低于SIFT和SURF算法,且分别减小了12%~32%。这表明SUPD算法在整体特征点对的匹配方面展现出更出色的性能,从而能更准确地匹配局部道路图像之间的海量高维特征,尤其在面对光照变化和视角变化的局部道路图像时,SUPD算法的表现更加稳健。
本文算法采用主成分分析法将特征点集映射至低维空间,并使用计算成本更低的平方欧氏距离进行特征点匹配,显著降低了计算复杂度。同时,为确保特征匹配的准确性,该算法采用双堆过滤算法对匹配点对进行了过滤和提纯。此外,为进一步提升匹配速度并最大程度地利用计算资源,该算法还引入了多核并行匹配策略,极大提高了特征点匹配效率。相对于传统的SIFT和SURF算法,本文算法将匹配时间缩短了77%~80%,同时将匹配准确率提升了5%~15%。实验结果表明本文算法具有出色的匹配实时性和准确性,能够满足车载全景环视系统对特征匹配的要求。
5、结束语:
针对传统图像特征匹配算法无法满足局部道路图像之间高维特征点的高效匹配,本文提出了一种融合主成分分析和双堆过滤的高性能降维并行匹配算法。通过主成分分析法将特征点集投影至低维空间,并采用平方欧氏距离进行排名估计,有效降低了匹配过程中的计算复杂度。同时,为保证特征匹配的精度,本文算法采用双堆过滤算法对匹配点对进行提纯。此外,本文算法还采用了并行结构,充分利用了计算资源,提高了整体算法的匹配速度。从实验结果来看,本文算法在匹配总时间、匹配准确率和匹配误差均方根等方面相较于传统的图像特征匹配算法具有明显的优势。综上,本文算法在兼顾匹配准确率的同时具有较好的匹配实时性,能够应用于局部道路图像之间高维特征点的高效匹配。
本发明的保护范围包括但不限于以上实施方式,本发明的保护范围以权利要求书为准,任何对本技术做出的本领域的技术人员容易想到的替换、变形、改进均落入本发明的保护范围。
- 一种基于并行化主成分分析算法的数据降维方法
- 基于二维主成分分析法的人脸图像降维分类方法