一种基于协同注意力的芯片管壳缺陷检测方法
文献发布时间:2024-04-18 20:01:55
技术领域
本发明涉及基于深度学习的单图像缺陷检测技术领域,具体为一种基于协同注意力的芯片管壳缺陷检测方法。
背景技术
随着科技的迅猛发展,芯片制造行业如火如荼,同时,芯片管壳缺陷使用人工识别的方法会消耗大量时间;随着深度学习神经网络的兴盛,可以设计一种算法,来自动检测芯片管壳缺陷,通过这种神经网络算法可以帮助相关人员进行管壳缺陷地快速检测,极大地提高检验效率。
目前已有的管壳缺陷图像检测主要有两种,方法1:利用VGG等神经网络在网络后端利用线性回归判断出整张图片是否属于缺陷图像等,方法2:利用神经网络回归mask图的方法;以上基于深度学习的管壳缺陷检测方法中,方法1均存在有一定的局限性,不能画出管壳缺陷在图片中的分布,于是我们利用方法2的架构并进行了网络设计的改进,来得到更好的效果,因此,提供了一种基于协同注意力的芯片管壳缺陷检测方法。
发明内容
本发明的目的在于提供一种基于协同注意力的芯片管壳缺陷检测方法,以解决上述背景技术中提出的问题。
为实现上述目的,本发明提供如下技术方案:一种基于协同注意力的芯片管壳缺陷检测方法,其中,包括:制作并处理图像样本数据集;构建协同注意力神经网络;利用所述图像样本数据集训练并调试所述协同注意力的神经网络;获取待检测的芯片管壳图像,利用训练调试好的所述神经网络对所述待检测的芯片管壳图像进行测试,得到预测分割图和预测缺陷的种类。
本技术方案中优选的,其制作并处理图像样本数据集,包括:收集多个芯片管壳缺陷的图像样本数据并对所述图像样本数据进行标注;将多个标注后的所述图像样本数据集分为训练集和验证集;将所述图像样本数据的宽高像素补充为8的倍数,并按比例调整标注形成的标签。
本技术方案中优选的,其构建协同注意力神经网络,包括:构建前端网络,所述前端网络用于提取特征;构建后端网络,所述后端网络用于输出预测分割图和预测缺陷的种类,所述后端网络具有后端网络主干和协同注意力模块,其所述后端网络主干与所述前端网络连接,所述协同注意模块与所述前端网络和所述后端网络主干连接。
本技术方案中优选的,其所述协同注意模块的数量为三个,三个所述协同注意力模块分别为:第一协同注意力模块、第二协同注意力模块和第三协同注意力模块;并且,其所述前端网络包括:第一网络层序列,所述第一网络层序列的支路输出作为所述第一协同注意力模块的输入,所述第一网络层序列的结构包括若干个第一卷积块和最大池化层;第二网络层序列,所述第二网络层序列的支路输出作为所述第二协同注意力模块的输入,所述第二网络层序列的结构包括若干个第二卷积块和最大池化层;第三网络层序列,所述第三网络层序列的支路输出作为所述第三协同注意力模块的输入,所述第三网络层序列的结构包括若干个第三卷积块和最大池化层;第四网络层序列,所述第四网络层序列的结构包括若干个第四卷积块。
本技术方案中优选的,其所述第一网络层序列的结构中,所述第一卷积块的数量为两个,所述第一卷积块包括卷积层和Relu激活函数;所述第二网络层序列的结构中,所述第二卷积块的数量为两个,所述第二卷积块包括卷积层和Relu激活函数;所述第三网络层序列的结构中,所述第三卷积块的数量为三个,所述第三卷积块包括卷积层和Relu激活函数;所述第四网络层序列的结构中,所述第四卷积块的数量为三个,所述第四卷积块包括卷积层和Relu激活函数。
本技术方案中优选的,其所述第一卷积块包括卷积核大小为3,个数为64的卷积层和Relu激活函数;所述第二卷积块包括卷积核大小为3,个数为128的卷积层和Relu激活函数;所述第三卷积块包括卷积核大小为3,个数为256的卷积层和Relu激活函数;所述第四卷积块包括卷积核大小为3,个数为512的卷积层和Relu激活函数。
本技术方案中优选的,其所述后端网络主干包括:第五网络层序列,所述第五网络层序列的输入为所述第四网络层序列的输出,所述第五网络层序列的结构包括若干个第五卷积块;第六网络层序列,所述第六网络层序列的输入为所述第五网络层序列的输出与所述第三协同注意力模块的输出的相加结果,所述第六网络层序列的结构包括若干个第六卷积块和上采样;第七网络层序列,所述第七网络层序列的的输入为所述第六网络层序列的输出与所述第二协同注意力模块的输出的相加结果,所述第七网络层序列的结构包括若干个第七卷积块和上采样;第八网络层序列,所述第八网络层序列的的输入为所述第七网络层序列的输出与所述第一协同注意力模块的输出的相加结果,所述第八网络层序列的结构包括若干个第八卷积块和上采样;第九网络层序列,所述第九网络层序列的输入为对所述第八网络层序列、所述第七网络层序列和所述第六网络层序列输出的相加结果进行拼接处理后的结果,所述第九网络层序列的结构包括若干个第九卷积块;第十网络层序列,所述第十网络层序列的输入为所述第九网络层序列的输出,所述第十网络层序列的结构包括若干个第十卷积块;第十一网络层序列,所述第十一网络层序列的输入为所述第十网络层序列的输出,所述第十一网络层序列的结构包括若干个第十一卷积块。
本技术方案中优选的,其所述第五卷积块的数量为三个,所述第五卷积块包括卷积核大小为3,个数为512的卷积层和Relu激活函数;所述第六卷积块的数量为三个,三个所述第六卷积块均包括卷积核大小为3,个数为256的卷积层和Relu激活函数;所述第七卷积块的数量为三个,三个所述第七卷积块环氧板包括卷积核大小为3,个数为128的卷积层和Relu激活函数;所述第八卷积块的数量为三个,三个所述第八卷积块均包括卷积核大小为3,个数为64的卷积层和Relu激活函数;所述第九卷积块的数量为二个,二个所述第五卷积块均包括卷积核大小为3,个数为448的卷积层和Relu激活函数;所述第十卷积块的数量为二个,二个所述第六卷积块均包括卷积核大小为3,个数为256的卷积层和Relu激活函数;所述第十一卷积块的数量为二个,二个所述第十一卷积块分别包括卷积核大小为3,个数为64的卷积层和Relu激活函数。
本技术方案中优选的,其所述协同注意力模块包括:将所述协同注意模块的输入分别进行平均池化和最大池化处理,经过池化处理后的结果再依次分别经过卷积、激活函数、卷积处理后相加,经过相加得到的结果再经过一个激活函数处理后,再乘第一学习权重系数后得到第一输出结果;将所述协同注意模块的输入分别进行平均化和最大化处理,然后再对处理得到的结果进行拼接,拼接得到的结果再依次经过卷积、激活函数处理后,再乘第二学习权重系数后得到第二输出结果;将所述协同注意模块的输入依次经过卷积、激活函数处理后,再乘第三学习权重系数后得到第三输出结果;将得到的所述第一输出结果、第二输出结果及第三输出结果相加后与所述协同注意模块的输入相乘后得到所述协同注意模块的输出;其中,所述第一学习权重系数、第二学习权重系数及第三学习权重系数相加之和为1。
本技术方案中优选的,其所述训练并调试所述协同注意力的神经网络包括:损失函数及参数设定;将待检测的芯片管壳图像与真值输入到神经网络中进行训练;加载经过训练后得到的网络参数,使用验证集估算训练后得到的所述神经网络的性能。
与现有技术相比,本发明的有益效果是:
1:本发明可以对芯片管壳缺陷进行更加准确的分割,可以实现基于分类的神经网络所不具备的预测缺陷区域的功能;
2:本发明设计的协同注意力的神经网络模型相比无注意力或单一注意力的神经网络模型,通过将不同的注意力分配一个可学习的权重系数,使其协同作用于特征的学习,因此,本发明能够获得更好的注意力效果,增强对缺陷特征的提取,提高分割网络的性能。
附图说明
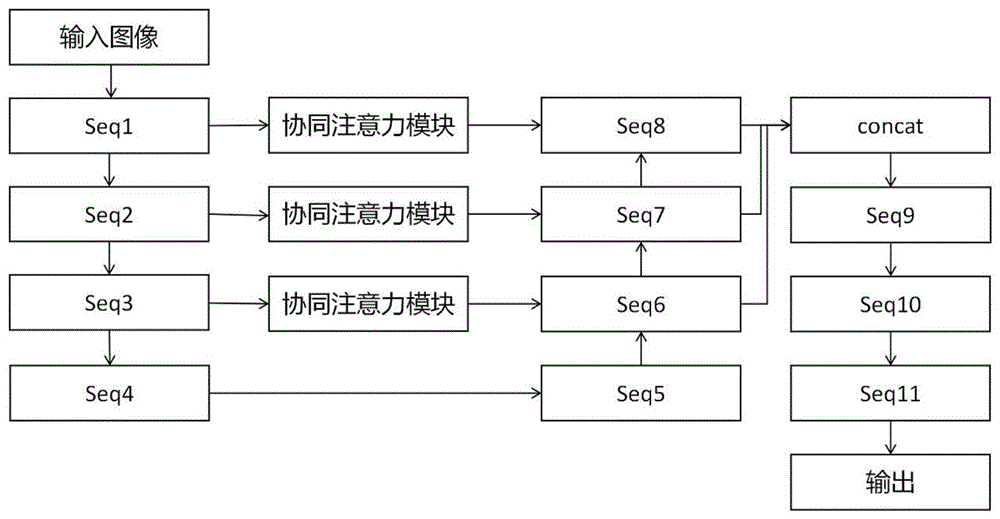
图1为本发明实施例中的一种基于协同注意力的芯片管壳缺陷检测方法的主流程结构示意图;
图2为本发明实施例中的一种基于协同注意力的芯片管壳缺陷检测方法的神经网络结构示意图;
图3为本发明实施例的协同注意力模块结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
需要说明的是,在本发明的描述中,术语“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,并不是指示或暗示所指的装置或元件所必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
应注意的是,相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义或说明,则在随后的附图的说明中将不需要再对其进行进一步的具体讨论和描述。
如图1所示,本发明提供了一种技术方案:一种基于协同注意力的芯片管壳缺陷检测方法,本发明包括有如下步骤:
步骤S1:制作并处理图像样本数据集。
进一步的说,步骤S1包括有三个子步骤,分别为:
步骤S11:制作图像数据集,其图像数据集为收集多个芯片管壳缺陷的图像样本数据并对所述图像样本数据进行标注。
步骤S12:将多个标注后的所述图像样本数据集分为训练集和验证集。
步骤S13:将所述图像样本数据的宽高像素补充为8的倍数,并按比例调整标注形成的标签。
进一步的,其中包括利用专业相机获取图像数据,若为灰度图像则转换为RGB三通道图像,若图像的宽高不能被8整除则在图像最外层像素上增加像素使宽高可以被8整除为止。
步骤S2:构建协同注意力神经网络。
进一步的说,步骤S2包括有三个子步骤,分别为:
步骤S21:构建前端网络,其前端网络用于提取特征;其以VGG16中的特征层(feature层)作为特征提取层的模板,每个特征提取层的结构为卷积核的尺寸为3*3(kernel=3),二维卷积层(Conv2d),其基本操作为在卷积层卷积后接Relu激活函数以及最大池化层(Maxpooling),同时,用这些全部操作或部分操作后可组成一组网络层序列(Sequential),一共组成了四组网络层序列(Sequential),四组网络层序列(Sequential)分别记为第一网络层序列(Seq1)、第二网络层序列(Seq2)、第三网络层序列(Seq3)、第四网络层序列(Seq4)。
更进一步的说,步骤S21还包括有两个子步骤,分别为:
步骤S211:构建前端网络,其前端网络包括第一网络层序列,其第一网络层序列的结构包括若干个第一卷积块和最大池化层;第二网络层序列,其第二网络层序列的结构包括若干个第二卷积块和最大池化层;第三网络层序列,其第三网络层序列的结构包括若干个第三卷积块和最大池化层;第四网络层序列,其第四网络层序列的结构包括若干个第四卷积块。
进一步的,第一网络层序列的结构中,第一卷积块的数量为两个,第一卷积块包括卷积层和Relu激活函数,第二网络层序列的结构中,第二卷积块的数量为两个,第二卷积块包括卷积层和Relu激活函数,第三网络层序列的结构中,第三卷积块的数量为三个,第三卷积块包括卷积层和Relu激活函数,第四网络层序列的结构中,第四卷积块的数量为三个,第四卷积块包括卷积层和Relu激活函数;并且,第一卷积块包括卷积核大小为3,个数为64的卷积层和Relu激活函数,第二卷积块包括卷积核大小为3,个数为128的卷积层和Relu激活函数,第三卷积块包括卷积核大小为3,个数为256的卷积层和Relu激活函数,第四卷积块包括卷积核大小为3,个数为512的卷积层和Relu激活函数。
其构建前端网络更具体的,如图2所示,即构建四组Sequential,分别记为Seq1、Seq2、Seq3、Seq4,其中,Seq1包括卷积核大小为3,个数为64的卷积层,后接Relu激活函数,最后再接卷积核大小为3,个数为64的卷积层、Relu激活函数以及Maxpooling;Seq2包括卷积核大小为3,个数为128的卷积层,后接Relu激活函数,最后再接卷积核大小为3,个数为128的卷积层、Relu激活函数以及Maxpooling;Seq3包括卷积核大小为3,个数为256的卷积层,后接Relu激活函数,卷积核大小为3,个数为256的卷积层,后接Relu激活函数,最后再接卷积核大小为3,个数为256的卷积层、Relu激活函数以及Maxpooling;Seq4包括卷积核大小为3,个数为512的卷积层,后接Relu激活函数,卷积核大小为3,个数为512的卷积层,后接Relu激活函数,最后再接卷积核大小为3,个数为512的卷积层以及Relu激活函数。其中,Seq1的输入为初始输入图像的数据输入,Seq2的输入为前端网络中Seq1的主路输出,Seq3的输入为前端网络中Seq2的主路输出,Seq4的输入为前端网络中Seq3的主路输出。
步骤S212:增加前端网络的支路输出,第一网络层序列的支路输出作为第一协同注意力模块的输入,第二网络层序列的支路输出作为第二协同注意力模块的输入,第三网络层序列的支路输出作为所述第三协同注意力模块的输入。
其增加前端网络的支路输出更具体的,如图2所示,将Seq1、Seq2、Seq3增加支路输出,作为后端神经网络的部分输入,即Seq1的支路输出作为第一协同注意力模块的输入,Seq2的支路输出作为第二协同注意力模块的输入,Seq3的支路输出作为第三协同注意力模块的输入。
步骤S22:构建后端网络,其后端网络用于输出预测分割图和预测缺陷的种类,后端网络具有后端网络主干和协同注意力模块,其后端网络主干与前端网络连接,协同注意模块与前端网络和后端网络主干连接;并且协同注意模块的数量为三个,三个协同注意力模块分别记为第一协同注意力模块、第二协同注意力模块和第三协同注意力模块。
更进一步的说,步骤S22还包括有两个子步骤,分别为:
步骤S221:构建后端网络主干,其后端网络主干包括第五网络层序列,第五网络层序列的输入为第四网络层序列的输出,第五网络层序列的结构包括若干个第五卷积块;第六网络层序列,第六网络层序列的输入为第五网络层序列的输出与第三协同注意力模块的输出的相加结果,第六网络层序列的结构包括若干个第六卷积块和上采样;第七网络层序列,第七网络层序列的的输入为第六网络层序列的输出与第二协同注意力模块的输出的相加结果,第七网络层序列的结构包括若干个第七卷积块和上采样;第八网络层序列,第八网络层序列的的输入为第七网络层序列的输出与第一协同注意力模块的输出的相加结果,第八网络层序列的结构包括若干个第八卷积块和上采样;第九网络层序列,第九网络层序列的输入为对第八网络层序列、第七网络层序列和第六网络层序列输出的相加结果进行拼接处理后的结果,第九网络层序列的结构包括若干个第九卷积块;第十网络层序列,第十网络层序列的输入为第九网络层序列的输出,第十网络层序列的结构包括若干个第十卷积块;第十一网络层序列,第十一网络层序列的输入为第十网络层序列的输出,第十一网络层序列的结构包括若干个第十一卷积块。
进一步的,第五卷积块的数量为三个,第五卷积块包括卷积核大小为3,个数为512的卷积层和Relu激活函数;第六卷积块的数量为三个,三个第六卷积块均包括卷积核大小为3,个数为256的卷积层和Relu激活函数;第七卷积块的数量为三个,三个第七卷积块均包括卷积核大小为3,个数为128的卷积层和Relu激活函数;第八卷积块的数量为三个,三个第八卷积块均包括卷积核大小为3,个数为64的卷积层和Relu激活函数;第九卷积块的数量为二个,二个第五卷积块均包括卷积核大小为3,个数为448的卷积层和Relu激活函数;第十卷积块的数量为二个,二个第六卷积块均包括卷积核大小为3,个数为256的卷积层和Relu激活函数;第十一卷积块的数量为二个,二个第十一卷积块分别包括卷积核大小为3,个数为64的卷积层和Relu激活函数。
其构建后端网络更具体的,如图2所示,即构建七组Sequential,分别为Seq5、Seq6、Seq7、Seq8、Seq9、Seq10、Seq11;其中,Seq5包括卷积核大小为3,个数为512的卷积层,后接Relu激活函数,卷积核大小为3,个数为512的卷积层,后接Relu激活函数,最后再接卷积核大小为3,个数为512的卷积层以及Relu激活函数;Seq6包括卷积核大小为3,个数为256的卷积层,后接Relu激活函数,卷积核大小为3,个数为256的卷积层,后接Relu激活函数,最后再接卷积核大小为3,个数为256的卷积层、Relu激活函数和以及上采样层(upsampling);Seq7包括卷积核大小为3,个数为128的卷积层,后接Relu激活函数,卷积核大小为3,个数为128的卷积层,后接Relu激活函数,最后再接卷积核大小为3,个数为128的卷积层、Relu激活函数和以及上采样层(upsampling);Seq8包括卷积核大小为3,个数为64的卷积层,后接Relu激活函数,卷积核大小为3,个数为64的卷积层,后接Relu激活函数,最后再接卷积核大小为3,个数为64的卷积层、Relu激活函数和以及上采样层(upsampling);Seq9包括卷积核大小为3,个数为448的卷积层,后接Relu激活函数,最后再接卷积核大小为3,个数为448的卷积层和Relu激活函数;Seq10包括卷积核大小为3,个数为256的卷积层,后接Relu激活函数,最后再接卷积核大小为3,个数为256的卷积层和Relu激活函数;Seq11包括卷积核大小为3,个数为64的卷积层,后接Relu激活函数,最后再接卷积核大小为3,个数为1的卷积层和Relu激活函数,最终输出结果为单通道,与原始图像的大小相同。如图2所示,Seq5的输入为前端网络中Seq4的输出,Seq6的输入为前端网络中Seq3的支路输出经过第三协同注意力模块处理后与Seq5的输出相加,Seq7的输入为前端网络中Seq2的支路输出经过第二协同注意力模块处理后与Seq6的输出相加,Seq8的输入为前端网络中Seq1的支路输出经过第一协同注意力模块处理后与Seq7的输出相加,Seq9的输入为前端网络中Seq6、Seq7、Seq8的输出相加后拼接得到的,Seq10的输入为前端网络中Seq9的输出,Seq11的输入为前端网络中Seq10的输出。
需要说明的是,上述上采样层(upsampling)可选用参数为upsize=2,mode=’nearest’,即上述上采样层制定的输出大小为2,采用nearest算法。
步骤S222:构建协同注意力模块,如图3所示,将协同注意模块的输入分别进行平均池化(avepoool)和最大池化(maxpool)处理,经过池化处理后的结果再依次分别经过卷积(conv)、第一激活函数(relu激活函数)以及卷积(conv)处理后相加,经过相加得到的结果经过第二激活函数(Sigmoid激活函数)处理后,再乘第一学习权重系数(W1)后得到第一输出结果;将协同注意模块的输入在空间维度为1(即dim=1)上分别进行平均化(mean)和最大化(max)处理,然后再对处理得到的结果进行拼接(concat),拼接(concat)得到的结果依次经过卷积(conv)和第二激活函数(Sigmoid激活函数)处理后,再乘第二学习权重系数(W2)后得到第二输出结果;将协同注意模块的输入依次经过大小为1的卷积核卷积(conv)和第二激活函数(Sigmoid激活函数)处理后,再乘第三学习权重系数(W3)后得到第三输出结果,其中,所述第一学习权重系数(W1)、第二学习权重系数(W2)及第三学习权重系数(W3)相加之和为1;将得到的所述第一输出结果、第二输出结果及第三输出结果相加,经过相加后得到的输出结果再与协同注意模块的输入相乘后得到协同注意模块的输出,以上通过此种方式将不同维度的注意力加权,协同作用从而提高了精准度。
步骤S23:加载网络中对应的VGG16中部分卷积层的预训练参数。
步骤S3:利用图像样本数据集训练并调试协同注意力神经网络。
进一步的说,步骤S3包括有三个子步骤,分别为:
步骤S31:损失函数及参数设定;损失参数可以使用BCEloss函数来衡量模型输出的概率与真实标签的差异,使用Adam优化器对得到的神经网络模型进行优化,其中batchsize设为1(或设为4、8、16、32),学习率设为0.00001,epoch设为400。
步骤S32:将待检测的芯片管壳图像与真值(即经过人工标注的标签)输入到神经网络中进行训练。
步骤S33:加载经过训练后得到的网络参数,使用验证集评估、评价函数MIOU、Pre、Rec的大小,并估算神经网络性能。
步骤S4:获取待检测的芯片管壳图像,利用训练调试好的神经网络对待检测的芯片管壳图像进行测试,得到预测分割图和输出预测结果,其中,预测结果指预测缺陷的种类,具体为多金、缺金、粘污、色差、划痕、凸点,分割图的作用是显示其缺陷的位置。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。