一种基于时空视觉词组和分层匹配的视频拷贝检测方法
文献发布时间:2023-06-19 09:26:02
技术领域
本发明属于信息安全领域。
背景技术
由于互联网技术和视频处理技术,尤其是目前新兴的基于人工智能的视频处理技术的发展,视频拷贝成本越来越低。为了防止视频内容被未经授权地非法使用和隐私侵犯,检测具有版权视频的非法拷贝版本已成为迫切的问题。因此,视频拷贝检测技术在信息安全领域起着非常重要的作用。
实际上,无论对原视频使用何种拷贝攻击方式,拷贝后的视频仍会保留有与原视频相同内容。通过设计合适的特征提取算法,可以提取视频内容的独一无二紧凑特征,并进行特征匹配,从而可以实现拷贝检测。在图像检索领域,通常使用传统词袋模型来描述图像,然后建立倒排索引结构实现快速检索。传统词袋模型通常从图像中提取一组局部特征,将高维特征向量量化为紧凑的视觉词,来描述图像内容。词袋模型能大大压缩图像局部特征向量,从而以更加紧凑的方式描述图像。倒排索引主要应用于多媒体搜索领域,可以实现对大规模数据的快速检索。类似于文本检索中基于关键词的倒排索引结构,图像检索方法通常将视觉词作为索引,建立倒排索引结构,可以在大规模图像数据库中进行快速检索。
类似于图像检索,现有的视频拷贝检测研究大多数都是基于传统的词袋模型,将视频帧看作图像,提取视觉词来描述视频内容。现有的视频拷贝检测方法仍然有以下几个技术难题:
1)对于一个视频片段,传统的词袋模型的视觉词只考虑其空间域特征而忽视了时间域特征,因此现有的视频拷贝检测方法检测精度不高。
2)现有的视频拷贝检测方法,对于视频的空间域特征和时间域特征单独进行处理,并没有建立统一的倒排索引结构,这导致占用内存空间大,检测效率不够理想,不适合在大规模数据集上应用。
3)现有的视频拷贝检测方法,对于视频之间特征匹配和相似度度量方式比较单一,没有充分考虑到空间域与时间域不同特征之间匹配结果和相似度计算,因而在视频相似度准确度量方面需要进一步提高。
发明内容
发明目的:为解决背景技术中存在的问题,本发明提供过了一种基于时空视觉词组和分层匹配的视频拷贝检测方法。
技术方案:本发明提供过一种基于时空视觉词组和分层匹配的视频拷贝检测方法,具体包括如下步骤:
步骤1:以d帧为采样间隔,对视频库中的每个视频进行均匀采样,得到采样帧;
步骤2:在每一个采样帧中提取若干个SURF特征;
步骤3:通过K-means聚类算法,将每个SURF特征量化到相应的视觉词,从而得到第n个SURF特征f
步骤4:针对视频库中的每一个视频的第k个采样帧,k=1,2,…L-1,当1≤k≤L-l时,检测该视频中的第k~第k+l个采样帧中相同的SURF特征,并将相同的SURF特征作为作为一组SURF特征组,当L-l<k≤L-1时,则检测第k~L个采样帧中相同的SURF特征;并将相同的SURF特征作为作为一组SURF特征组;对每一组SURF特征组中的SURF特征轨迹进行量化编码,从而的得到该组中SURF特征对应的时间视觉词;其中1≤l<L,L为该视频中采样帧的总个数,所述相同的SURF特征为具有相同空间视觉词的SURF特征;
步骤5:将步骤4的每一组中的SURF特征对应的空间视觉词和时间视觉词的集合作为该SURF特征的时空视觉词组;
步骤6:根据视频库中所有的时空视觉词组,构建多级倒排索引结构;
步骤7:提取被查询视频的时空视觉词组,并基于多级倒排索引结构在视频库中查找与该被查询图像相互匹配的库视频,并计算被查询视频和每一个与被查询视频相互匹配的库视频之间的相似度。
进一步的,所述步骤4中相同特征的检测具体为:以第k个采样帧中第i个SURF 特征f
进一步的,所述步骤4中对每一组SURF特征组中的SURF特征的进行轨迹进行量化编码具体为:
步骤4.1:基于第k~第k+l个或第k~L个采样帧,针对任意一组SURF特征组中相同的SURF特征f
其中,abs(*)表示取绝对值;
步骤4.2:对差值Δx
其中,
步骤4.3:特征f
若1≤k≤L-l,则该组中SURF特征f
进一步的,所述步骤6具体为:该索引结构共有l+2层,第1层为所有的空间视觉词,第2~l+1层依次设置SURF特征f
进一步的,所述步骤7为:
步骤7.1:查询倒排索引的第1层,在视频库中查找与被查询视频Q存在相同空间视觉词的库视频,记录这些库视频的个数为R,计算被查询视频Q与R个库视频中的第r个库视频的相似度sim
sim
其中NC(w
步骤7.2:查询倒排索引的第d层,d=2,3,…,l+1,判断被查询视频Q与第r个库视频之间是否存在相同的时间视觉词,若是,则计算被查询视频Q与第r个库视频在第 d层的相似度sim
其中,yd表示第d层,
若否,则停止计算被查询视频Q与第r个库视频的相似度,对下一个库视频进行计算;
步骤7.3:若在第l+1层倒排索引层中,被查询视频Q与第r个库视频之间仍然有相同的时间视觉词,则计算被查询视频Q与第r个库视频的最终相似度Sim(Q,r)为:
Sim(Q,r)=∑(ω
其中ω
有益效果:
(1)本发明设计的一种基于时空视觉词组和分层匹配的视频拷贝检测方法。不同于现有的图像和视频检索方法,该方法不仅利用传统词袋模型提取视频帧的空间视觉词,并且考虑视频帧之间相同特征的运动轨迹,从而提取时间视觉词。通过联合空间视觉词和时间视觉词构造时空视觉词组,从而能更加准确地表达视频内容。
(2)本发明设计的一种基于时空视觉词组和分层匹配的视频拷贝检测方法,根据生成的时空视觉词组,构建多级倒排索引,能同时支持粗粒度和细粒度的特征分层匹配,从而大大提高特征匹配的精确度,并保证较高的匹配效率。
(3)本发明设计的一种基于时空视觉词组和分层匹配的视频拷贝检测方法,充分考虑到粗粒度和细粒度的多层次特征匹配和这些特征匹配结果的相似度度量,并对特征相似度融合计算得到最终视频相似度,能更加准确度量视频之间的相似度。
附图说明
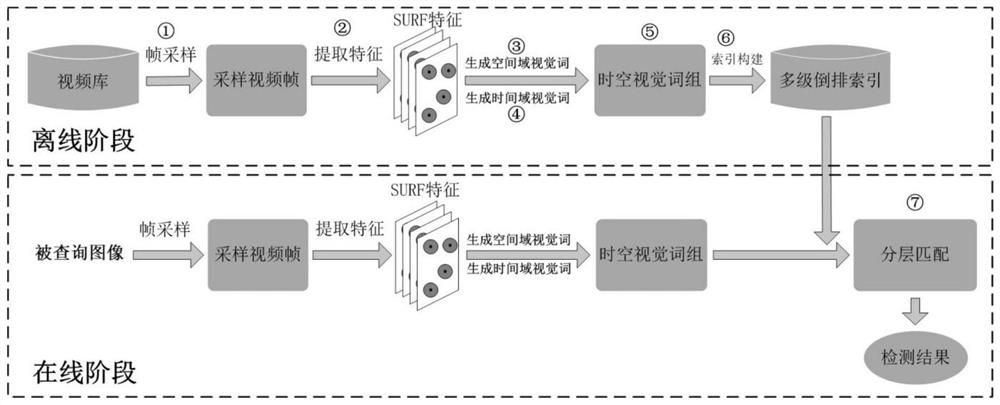
图1为本发明的总体框架示意图;
图2为本发明的时间视觉词生成示意图;
图3为本发明的多级倒排索引结构示意图。
具体实施方式
构成本发明的一部分的附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。
如图1所示,本实施例提供了一种基于时空视觉词组和分层匹配的视频拷贝检测方法,具体为:
步骤1:对视频库中的每个视频以间隔d帧进行均匀采样,得到采样后的视频帧。以下步骤均针对采样视频帧进行处理。为了平衡检测精确度和存储空间占用,在本发明中,设置采样间隔d=2。
步骤2:对每个采样帧当作图像,从中提取上百个SURF特征。其中,每个SURF 特征f
步骤3:对上述提取的SURF特征,使用K-means聚类算法进行聚类,聚类中心数目设定为K,则得到K个聚类中心。将这K个聚类中心看作空间视觉词,这些视觉词的集合称作空间视觉词典
步骤4:针对当前视频帧及之后的若干个相邻帧,检测相同SURF特征的运动轨迹,并进行量化编码,从而得到时间视觉词,具体为:针对视频库中的每一个视频的第k帧采样帧,k=1,2,…L-1,当1≤k≤L-l时,检测该视频中的第k~第k+l个采样帧中相同的SURF特征,并将相同的SURF特征作为作为一组SURF特征组,当L-l<k≤L-1 时,则检测第k~L个采样帧中相同的SURF特征;并将相同的SURF特征作为作为一组SURF特征组;对每一组SURF特征组中的SURF特征进行轨迹进行量化编码,从而的得到该组中SURF特征对应的时间视觉词;其中1≤l<L,L为该视频中采样帧的总个数,所述相同的SURF特征为具有相同视觉词的SURF特征;本实施例中l=2
步骤5:将步骤4的每一组中的SURF特征对应的空间视觉词和时间视觉词的集合作为该SURF特征的时空视觉词组;
步骤6:根据视频库中所有的时空视觉词组,构建多级倒排索引结构;
步骤8:在线检测阶段,提取被查询视频的时空视觉词组,并基于多级倒排索引结构在视频库中查找与该被查询图像相互匹配的库视频,并计算被查询视频和每一个与被查询视频相互匹配的库视频之间的相似度。
优选的,所述步骤4中对每一个SURF特征组中的SURF特征的进行轨迹进行量化编码具体为:将一个任意给定的采样帧作为当前帧,针对当前帧中SURF征点f
优选的,如图2所示,所述步骤4中对每一个SURF特征组中的SURF特征的进行轨迹进行量化编码具体为:
步骤4-1:基于第k~第k+l个或第k~L个采样帧,针对任意一组SURF特征组中相同的SURF特征f
其中,abs(*)表示取绝对值;由于视频帧内SURF特征的位置的横坐标和纵坐标分别不超过视频帧的宽度和高度,那么0≤Δx≤w和0≤Δy≤h,w和h分别是视频帧的宽度和高度。
步骤4-2:对差值Δx
其中,
步骤4-2:针对SURF特征f
具体来说,根据生成的量化值对,将第l′个量化值对串联起来,可以得到第l′采样帧中的时间视觉词为,表示为:
则若1≤k≤L-l,该组中SURF特征f
优选的,步骤5为,结合SURF特征f
优选的,步骤6为该索引结构共有l+2层,第1层为所有的空间视觉词,第2~l+1 层依次设置SURF特征f
优选的,在线检测阶段,对给定的查询视频提取时空视觉词组,然后对多级倒排索引中的第1层到第l+1层每层的视觉词进行分层匹配,计算分层匹配相似度,最后使用相似度融合计算的方式得到最终相似度;具体做法如下:
步骤7-1:查询倒排索引的第一层,在视频库中查找与被查询视频Q存在相同空间视觉词的库视频,记录这些库视频的个数为R个,计算被查询视频Q与R个库视频中的第r个库视频的相似度sim
sim
其中NC(w
步骤7-2:查询倒排索引的第d层,d=2,3,…,l+1统计被查询视频Q与R个库视频中的第r个库视频是否存在相同的时间视觉词,若是,则基于第d层,被查询视频Q与第r个库视频的相似度sim
其中,yd表示第d层,
若否,则停止计算被查询视频Q与第r个库视频的相似度,对下一个库视频进行计算;
步骤7-3:若在第l+1层倒排索引层中,被查询视频Q与第r个库视频之间仍然有相同的时间视觉词,则与第r个库视频为候选库视频,则计算被查询视频Q与第r个库视频的最终相似度Sim(Q,r)为:
Sim(Q,T)=∑(ω
其中ω
Sim(Q,r)=∑(ω
其中,ω
步骤7-4:将查询视频与所有候选库视频之间的相似度进行降序排序,作为拷贝检测结果。
上面结合附图对本发明的实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下做出各种变化。
- 一种基于时空视觉词组和分层匹配的视频拷贝检测方法
- 一种基于时空视觉词组和分层匹配的视频拷贝检测方法