一种推荐模型的训练方法、介质、电子设备和推荐模型
文献发布时间:2023-06-19 09:27:35
技术领域
本发明涉及数据处理技术领域,具体来说涉及推荐技术领域,更具体地说,涉及一种推荐模型的训练方法、介质、电子设备和推荐模型。
背景技术
推荐系统是互联网发展的重要增长引擎,已被广泛应用于诸如电商推荐、电影推荐、新闻推荐、音乐推荐等众多场景。推荐系统为用户从海量的物品中推荐其可能感兴趣的物品,帮助用户在信息过载的情况下高效地做出决策。
随着推荐系统的广泛应用,推荐系统的公平性逐渐引起关注。由于种种原因,现实中的用户与物品的历史交互数据不可避免地存在不均衡和偏置现象。例如,新用户和中老年人用户因过去在推荐系统中不活跃,商品交互记录数据稀疏;小众爱好者偏好的小众商品在大部分用户的交互记录中都未曾出现过等等。这种情况下,仅依靠一个总体目标损失的数据驱动训练策略,很有可能导致模型牺牲少数群体的推荐准确率以保证总体推荐准确率,从而产生不公平的推荐结果。然而,提升少数群体的用户体验满意度,尤其新用户以及中老年用户的推荐体验,对平台的扩展、用户留存等十分重要。
构建公平的推荐系统有两大关键问题:一是构建合适的准确性损失函数以及公平性损失函数,二是如何形式化地权衡推荐准确性与公平性。
对于关键问题一:从不同的公平性损失定义角度出发,现有的考虑公平性的推荐算法主要可以分为三类方法:第一类方法针对打包推荐(Package-to-Grouprecommendation,即为同一组用户推荐相同的商品)的应用场景,比如一些现有方法中通过定义商品对用户的效用函数,训练公平的推荐策略,使所推荐商品对同一组内不同用户具有公平的效用;第二类方法旨在追求不同平台参与方(用户和商家)之间效用的公平性;第三类方法旨在实现不同的商品之间相对公平的排序。尽管现在有许多方法定义了不同的公平性度量,但目前为止,尚没有工作从不同用户组的推荐准确率方面考虑公平性。其主要限制因素是:推荐算法一般将用户物品预测得分的前K个物品预测为正样本,此排序操作不可导,故基于排序的准确性度量(如精准率、召回率)均不可导,从而无法高效地训练和优化推荐模型。
对于关键问题二,现有方法实现公平推荐主要通过以下两个途径:第一个途径是将推荐问题形式化为一个受限优化问题,求解在一定公平限制条件下,最大化推荐的准确率。其中,一些现有技术采用后处理方法,以单一准确率为目标训练好模型后,提出一些后续处理技术,增加推荐策略的公平性;还有一些现有技术采用传统的受限优化算法求解该问题,或者利用强化学习求解该受限优化问题。第二个途径是将推荐准确性损失与公平性损失进行加权求得到一个总的代理损失,通过最小化代理损失求解模型;但这种方法需要对权重进行网格搜索,耗时耗力。更重要的是,加权求和的形式仅适用于不同目标损失具有一致性的情况。然而,由于不同用户组的历史记录存在不均衡和偏置,公平性目标与总体准确性目标之间存在竞争关系。因此,优化加权求和的代理损失将产生何种性质的解并不为人知。
因此,现有的推荐系统难以在推荐的准确性与公平性之间获得较好的权衡,导致一些少数群体的用户体验不佳。因此,有必要对现有技术进行改进。
发明内容
因此,本发明的目的在于克服上述现有技术的缺陷,尤其是解决在不同用户组的商品交互记录具有偏差时,推荐系统中总体推荐准确性和不同用户组的推荐公平性之间的权衡问题,提供一种推荐模型的训练方法、介质、电子设备和推荐模型。
本发明的目的是通过以下技术方案实现的:
根据本发明的第一方面,提供一种推荐模型的训练方法,包括:A1、构建推荐模型、损失构建模块和多目标优化模块;A2、获取不同用户的商品交互记录,根据用户属性设置不同的用户组;A3、利用商品交互记录对推荐模型进行多次迭代训练至收敛,其中,每次训练包括:A31、用推荐模型从本次获取的商品交互记录中学习用户对商品的决策过程,获取用户对所有商品的偏好概率;A32、基于用户对所有商品的偏好概率,损失构建模块构建第一损失函数用于计算针对不同用户的推荐准确性损失以及构建连续可微的第二损失函数用于计算针对不同的用户组的推荐公平性损失;A33、多目标优化模块根据推荐准确性损失和推荐公平性损失确定推荐模型的参数更新方向并据此更新推荐模型的参数。
在本发明的一些实施例中,所述推荐模型包括信息获取模块、变分自编码器、重参数化模块和解码器,其中,所述步骤A31包括:A311、用信息获取模块获取预先设置的用户的潜在偏好向量的先验分布、商品的簇隶属度矩阵的先验分布;A312、用变分自编码器从本次获取的商品交互记录中学习用户对商品的决策过程,得到对先验分布通过变分推断修正后的用户的潜在偏好向量的后验分布、商品的簇隶属度矩阵的后验分布以及商品的潜在向量;A313、用重参数化模块利用重参数化技巧对用户的潜在偏好向量的后验分布、商品的簇隶属度矩阵的后验分布分别进行采样,得到用户的潜在偏好向量和商品的簇隶属度矩阵;A314、用解码器根据用户的潜在偏好向量和商品的簇隶属度矩阵以及商品的潜在向量获取用户对所有商品的偏好概率。
在本发明的一些实施例中,步骤A33包括:A331、根据推荐准确性损失计算推荐模型参数更新的第一梯度,根据推荐公平性损失计算推荐模型参数更新的第二梯度,基于第一梯度和第二梯度动态确定第一梯度的第一权重和第二梯度的第二权重;A332、获取第一权重乘以第一梯度加上第二权重乘以第二梯度的加权和作为推荐模型的参数更新的方向。
根据权利要求1所述的推荐模型的训练方法,其特征在于,确定推荐模型是否训练至收敛的方式为:如果加权和的范数小于给定误差阈值或者迭代次数超过预定迭代次数上限,则推荐模型已训练至收敛。
在本发明的一些实施例中,第一损失函数为:
在本发明的一些实施例中,第二损失函数为:l
根据本发明的第二方面,提供一种采用第一方面所述的方法训练得到的推荐模型,包括:信息获取模块,用于获取用户的商品交互记录、预先设置的用户的潜在偏好向量的先验分布、商品的簇隶属度矩阵的先验分布;变分自编码器,用于从获取的商品交互记录中学习用户对商品的决策过程,得到对先验分布通过变分推断修正后的用户的潜在偏好向量的后验分布、商品的簇隶属度矩阵的后验分布以及商品的潜在向量;重参数化模块,用于利用重参数化技巧对用户的潜在偏好向量的后验分布、商品的簇隶属度矩阵的后验分布分别进行采样,得到用户的潜在偏好向量和商品的簇隶属度矩阵;解码器,用于根据用户的潜在偏好向量和商品的簇隶属度矩阵以及商品的潜在向量获取用户对所有商品的偏好概率;结果输出模块,用于将用户对所有商品的偏好概率中概率值较高的一个或者多个商品推荐给用户。
根据本发明的第三方面,提供一种在第二方面所述的推荐模型中使用的推荐方法,包括:B1、获取用户的商品交互记录、预先设置的用户的潜在偏好向量的先验分布、商品的簇隶属度矩阵的先验分布;B2、从获取的商品交互记录中学习用户对商品的决策过程,得到对先验分布通过变分推断修正后的用户的潜在偏好向量的后验分布、商品的簇隶属度矩阵的后验分布以及商品的潜在向量;B3、利用重参数化技巧对用户的潜在偏好向量的后验分布、商品的簇隶属度矩阵的后验分布分别进行采样,得到用户的潜在偏好向量和商品的簇隶属度矩阵;B4、根据用户的潜在偏好向量和商品的簇隶属度矩阵以及商品的潜在向量获取用户对所有商品的偏好概率;B5、将用户对所有商品的偏好概率中概率值较高的一个或者多个商品推荐给用户。
根据本发明的第四方面,提供一种电子设备,包括:一个或多个处理器;以及存储器,其中存储器用于存储一个或多个可执行指令;所述一个或多个处理器被配置为经由执行所述一个或多个可执行指令以实现第一方面所述方法的步骤。
与现有技术相比,本发明的优点在于:
本发明训练得到的推荐模型可以在不同用户的推荐准确性损失和不同的用户组的推荐公平性损失获得良好地权衡,从而避免推荐模型仅考虑多数群体的推荐准确性而未考虑到多数群体和少数群体直接的推荐公平性,提升用户组之间的推荐公平性,从而提高整体的用户体验,特别是代表群体的用户体验。
附图说明
以下参照附图对本发明实施例作进一步说明,其中:
图1为根据本发明实施例的训练推荐模型的过程构建的模块示意图;
图2为根据本发明实施例的推荐模型的模块示意图;
图3为根据本发明实施例的推荐模型的原理示意图;
图4为根据本发明实施例的推荐模型的训练方法的示意图;
图5为根据本发明实施例的实验结果的示意图。
具体实施方式
为了使本发明的目的,技术方案及优点更加清楚明白,以下结合附图通过具体实施例对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
如在背景技术部分提到的,当前的推荐系统难以在推荐的准确性与公平性之间获得较好的权衡,导致一些少数群体的用户体验不佳。本发明通过建模用户对商品的决策过程,构建了一个在训练时同时考虑不同用户的推荐准确性损失和不同的用户组的推荐公平性损失进行参数更新的推荐模型,最终得到的推荐模型可以在不同用户的推荐准确性损失和不同的用户组的推荐公平性损失获得良好地权衡,从而避免推荐模型仅考虑多数群体的推荐准确性而未考虑到多数群体和少数群体直接的推荐公平性,提升用户组之间的推荐公平性,从而提高整体的用户体验,特别是代表群体的用户体验。
在对本发明的实施例进行具体介绍之前,先对其中使用到的部分术语作如下解释:
KL散度(Kullback-Leibler Divergence),是衡量两个概率分布差异的非对称性度量。在机器学习领域的物理意义是用来度量两个分布的相似程度或者相近程度。
先验分布(Prior Distribution),又称验前分布或者事前分布,是概率分布的一种;与“后验分布”相对。先验分布与试验结果无关,或与随机抽样无关,反映在进行统计试验之前根据其他有关参数的知识而得到的分布。换言之,先验分布是事先根据已有的知识或者经验的推断
后验分布,是指通过当前训练数据修正的随机变量的分布。后验分布比先验分布更符合当前数据。后验分布往往是基于先验分布和极大似然估计计算出来的。
本发明提供一种推荐模型的训练方法,包括步骤A1、A2、A3。为了更好地理解本发明,下面结合具体的实施例针对每一个步骤分别进行详细说明。
在步骤A1中,参见图1,构建推荐模型100、损失构建模块200和多目标优化模块300。损失构建模块200和多目标优化模块300用于辅助训练推荐模型。
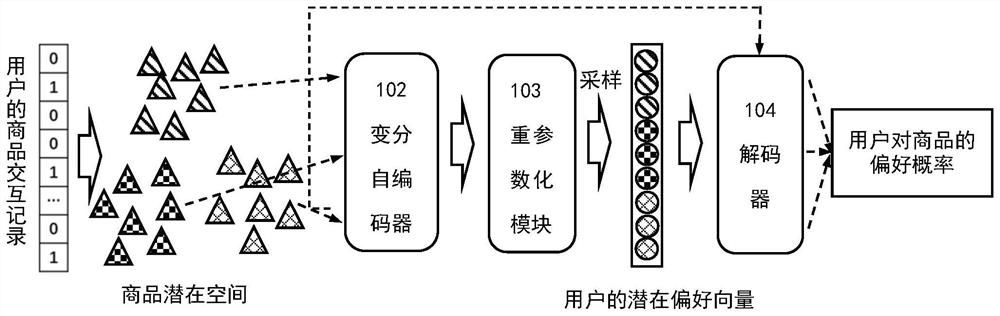
参见图2,根据本发明的一个实施例,推荐模型100包括变分自编码器102和解码器104。变分自编码器102可以采用多层感知机(Multilayer Perceptron,简称MLP)。优选的,变分自编码器102采用的多层感知机的网络层数为3层,其中,1层与2层的连接权重的大小是总商品数乘以商品的潜在向量的维度,即M×D,2层与3层的连接权重的大小是商品的潜在向量的维度乘以商品的潜在向量的维度,即D×D。变分自编码器102的参数初始化采用的是泽维尔初始化法(Xavier Initialize)。损失构建模块用于构建损失函数,在本发明中,损失构建模块200分别构建准确性目标对应的第一损失函数以及公平性目标对应的第二损失函数。多目标优化模块300,用于同时优化推荐准确性损失与推荐公平性损失,求解出一个合适的帕累托最优解,在推荐准确性损失和推荐公平性损失之间获得良好的权衡。
在步骤A2中,获取不同用户的商品交互记录,根据用户属性设置不同的用户组。
根据本发明的一个实施例,步骤A2包括:A21、获取不同用户与不同商品的商品交互记录,其中,用第一交互值表示用户与一商品有正反馈,用第二交互值表示用户与一商品有负反馈或者没有反馈;A22、根据一个或者多个用户属性设置不同的用户组。例如,假设有N个用户,M个商品,x
在步骤A3中,利用商品交互记录对推荐模型进行多次迭代训练至收敛。参见图2和图3,推荐模型包括信息获取模块101、变分自编码器102、重参数化模块103、解码器104、结果输出模块105。步骤A3中每次训练包括:A31、A32、A33、A34。
步骤A31、用推荐模型100从本次获取的商品交互记录中学习用户对商品的决策过程,获取用户对所有商品的偏好概率。
根据本发明的一个实施例,步骤A31包括步骤A311、A312、A313、A314。
步骤A311、用信息获取模块101获取预先设置的用户的潜在偏好向量的先验分布、商品的簇隶属度矩阵的先验分布。
根据本发明的一个实施例,假设每个用户有K个兴趣簇,对每个兴趣簇的商品具有不同的潜在偏好向量,定义用户u对兴趣簇k内商品的潜在偏好向量为
步骤A312、用变分自编码器102从本次获取的商品交互记录中学习用户对商品的决策过程,得到对先验分布通过变分推断修正后的用户的潜在偏好向量的后验分布、商品的簇隶属度矩阵的后验分布以及商品的潜在向量。
根据本发明的一个实施例,由于用户的潜在偏好向量的分布、商品的簇隶属度矩阵的分布未知,训练过程根据已给的用户与不同商品交互记录x
对于KL距离,有以下推导:
其中,
对于用户u的商品交互记录x
其中,x
对于商品的簇隶属度矩阵的分布p(C),假设
对于近似联合变分分布
假设
其中,σ
A313、用重参数化模块103利用重参数化技巧对用户的潜在偏好向量的后验分布、商品的簇隶属度矩阵的后验分布分别进行采样,得到用户的潜在偏好向量和商品的簇隶属度矩阵。
由于采样操作的不连续性质,导致推荐模型100无法利用基于梯度的方法进行端到端训练。为了解决这一问题,在推荐模型100的训练过程中,利用重参数化技巧对两个后验分布分别进行采样,得到用户的潜在偏好向量、商品的簇隶属度矩阵。之后根据得到的用户的潜在偏好向量、商品的簇隶属度矩阵以及商品的潜在向量获取用户对所有商品的偏好概率,从而保证推荐模型100可进行端到端训练。推荐模型100训练完毕后,在测试应用过程中,直接使用两个后验分布的均值获取用户对所有商品的偏好概率。
A314、用解码器104根据用户的潜在偏好向量和商品的簇隶属度矩阵以及商品的潜在向量获取用户对所有商品的偏好概率。步骤A313-A314的过程相当于图4左侧的前两个框图示出的过程,即图4中的标记41和标记42指示的位置。
根据本发明的一个实施例,假设用户潜在偏好向量的分布p(z
假设x
由此,可以按照以下方式计算每个用户u与每个商品i的偏好概率:
A32、基于用户对所有商品的偏好概率,损失构建模块200构建第一损失函数用于计算针对不同用户的推荐准确性损失以及构建连续可微的第二损失函数用于计算针对不同的用户组的推荐公平性损失。
对于第一损失函数:
基于上述对KL距离推导,由于logp(x
即构造目标损失函数为负的证据下界,最小化该损失即可求得最逼近真实后验分布的变分分布。该式花括号内的第一项logp
上式中求期望的操作可通过采样替代,若只采样一次,上述损失可重写为:
由于输入的用户的商品交互记录x
将上式和
其中,u表示用户u,N表示用户数量,i表示商品i,x
对于第二损失函数:
观察证据下界的组成,p
该公式表示推荐模型100在第a个用户组G
l
其中,l
A33、多目标优化模块300根据推荐准确性损失和推荐公平性损失确定推荐模型100的参数更新方向并据此更新推荐模型100的参数。
根据本发明的一个实施例,步骤A33包括:A331、A332、A333、A334。
本发明首次从推荐系统在不同用户组上的推荐准确性角度考虑推荐系统的推荐公平性,开创性地将公平性与准确性的权衡问题形式化为一个多目标优化问题。并且,本发明设计利用基于梯度更新的多目标优化算法进行求解,得到的解具有良好的帕累托最优性。基于模型给出的推荐准确性目标和模型公平性目标对应的损失,本发明从求解多目标优化问题角度同时求解两个目标损失,同时最小化推荐准确性目标对应的推荐准确性损失和推荐公平性目标对应的推荐公平性损失,即多目标优化模块300的总体目标为:
A331、根据推荐准确性损失计算推荐模型100参数更新的第一梯度,根据推荐公平性损失计算推荐模型100参数更新的第二梯度,基于第一梯度和第二梯度动态确定第一梯度的第一权重和第二梯度的第二权重。
根据本发明的一个实施例,假设梯度更新方向d表示为:
上式表示动态确定ω
其中,ω
A332、获取第一权重乘以第一梯度加上第二权重乘以第二梯度的加权和作为推荐模型100的参数更新的方向。
经过转换,得到本发明中模型参数每一步的更新方向:
对于本发明中的推荐公平性—准确性权衡问题,T=2,故可直接采用上述计算第一权重和第二权重的方式进行模型更新。该梯度更新算法每一步根据不同目标损失的梯度,动态确定不同目标的权重ω
优选的,确定推荐模型100是否训练至收敛的方式为:如果加权和的范数小于给定误差阈值或者迭代次数超过预定迭代次数上限,则推荐模型100已训练至收敛。
根据本发明的另一方面,还提供一种推荐方法,包括:B1、获取用户的商品交互记录、预先设置的用户的潜在偏好向量的先验分布、商品的簇隶属度矩阵的先验分布;B2、从获取的商品交互记录中学习用户对商品的决策过程,得到对先验分布通过变分推断修正后的用户的潜在偏好向量的后验分布、商品的簇隶属度矩阵的后验分布以及商品的潜在向量,B3、利用重参数化技巧对用户的潜在偏好向量的后验分布、商品的簇隶属度矩阵的后验分布分别进行采样,得到用户的潜在偏好向量和商品的簇隶属度矩阵,B4、根据用户的潜在偏好向量和商品的簇隶属度矩阵以及商品的潜在向量获取用户对所有商品的偏好概率;B5、将用户对所有商品的偏好概率中概率值较高的一个或者多个商品推荐给用户。
根据本发明的另一方面,还提供一种推荐方法,包括:B1、获取用户的商品交互记录、预先设置的用户的潜在偏好向量的先验分布、商品的簇隶属度矩阵的先验分布;B2、用前述实施例的训练方法得到的推荐模型执行以下步骤:从获取的商品交互记录中学习用户对商品的决策过程,得到对先验分布通过变分推断修正后的用户的潜在偏好向量的后验分布、商品的簇隶属度矩阵的后验分布以及商品的潜在向量;利用重参数化技巧对用户的潜在偏好向量的后验分布、商品的簇隶属度矩阵的后验分布分别进行采样,得到用户的潜在偏好向量和商品的簇隶属度矩阵;根据用户的潜在偏好向量和商品的簇隶属度矩阵以及商品的潜在向量获取用户对所有商品的偏好概率;B3、将用户对所有商品的偏好概率中概率值较高的一个或者多个商品推荐给用户。应当理解的是,为避免赘述,前述训练方法中的一些对应步骤可作为推荐方法的步骤的实施方式。
根据本发明的一个实施例,获取偏好概率的方式为:根据用户的潜在偏好向量和商品的簇隶属度矩阵以及商品的潜在向量获取用户对所有商品的偏好概率:
根据本发明的再一个方面,还提供一种采用前述实施例的训练方法得到的推荐模型,包括:信息获取模块101,用于获取用户的商品交互记录、预先设置的用户的潜在偏好向量的先验分布、商品的簇隶属度矩阵的先验分布;变分自编码器102,用于从获取的商品交互记录中学习用户对商品的决策过程,得到对先验分布通过变分推断修正后的用户的潜在偏好向量的后验分布、商品的簇隶属度矩阵的后验分布以及商品的潜在向量;重参数化模块103,用于利用重参数化技巧对用户的潜在偏好向量的后验分布、商品的簇隶属度矩阵的后验分布分别进行采样,得到用户的潜在偏好向量和商品的簇隶属度矩阵;解码器104,用于根据用户的潜在偏好向量和商品的簇隶属度矩阵以及商品的潜在向量获取用户对所有商品的偏好概率;结果输出模块105,用于将用户对所有商品的偏好概率中概率值较高的一个或者多个商品推荐给用户。
根据本发明的一个示例,本发明中的推荐系统流程可总结为如下步骤:T1、输入一批用户商品交互记录数据x
根据本发明的一个示例,本发明在常用推荐数据集MovieLens-100k(简写为ML-100k)和MovieLens-1m(简写为ML-1m)上均获得较好结果,结果见图5。对于不同类型(簇)的电影,例如对于纪实、历史类影片,用户的潜在偏好因子可能是真实、经典老片,对于科幻、喜剧等类型影片,用户的潜在偏好可能是戏剧化(没有那么真实)、最新影片,因此只建模一组用户潜在偏好或许无法满足用户对属于不同类型(簇)的商品的偏好预测。在ML-100k和ML-1m数据集上,发明人采用性别与年龄两个属性,对用户进行分组,具体为:男性且小于18岁、女性且小于18岁、男性且年龄18~50岁、女性且年龄18~50岁、男性且年龄大于50岁,女性且年龄大于50岁,这6组用户。推荐模型100的准确性评价指标为推荐领域常见的基于排序的推荐指标:Recall@k和HitRate@k(k取20),即图5a和图5c中的Recall@20和图5b和图5d中的HitRate@20。同时采用上述两指标在6个用户组之间表现的标准均方差:Recall@k-std和HitRate@k-std(k取20),即图5a和图5c中的Recall@20-std和图5b和图5cHitRate@20-std,用于衡量不同用户组之间的推荐公平性。此处引用三篇现有技术对应的文献:[1]X.He,L.Liao,H.Zhang,L.Nie,X.Hu,and T.Chua.Neural collaborative filtering.InInternational World Wide Web Conferences,pages 173–182,2017.;[2]D.Liang,R.G.Krishnan,M.D.Hoffman,and T.Jebara.Variational autoencoders forcollaborative filtering.In International World Wide Web Conferences,pages689–698,2018.;[3]J.Ma,C.Zhou,P.Cui,H.Yang,and W.Zhu.Learning disentangledrepresentations for recommendation.In Advances in Neural InformationProcessing Systems,pages 5712–5723,2019.。该示例中采用三篇文献中给出不同的推荐模型100:GMF模型
根据本发明的一个方面,还提供一种电子设备,包括:一个或多个处理器;以及存储器,其中存储器用于存储一个或多个可执行指令;所述一个或多个处理器被配置为经由执行所述一个或多个可执行指令以实现前述实施例的方法的步骤。
需要说明的是,虽然上文按照特定顺序描述了各个步骤,但是并不意味着必须按照上述特定顺序来执行各个步骤,实际上,这些步骤中的一些可以并发执行,甚至改变顺序,只要能够实现所需要的功能即可。
本发明可以是系统、方法和/或计算机程序产品。计算机程序产品可以包括计算机可读存储介质,其上载有用于使处理器实现本发明的各个方面的计算机可读程序指令。
计算机可读存储介质可以是保持和存储由指令执行设备使用的指令的有形设备。计算机可读存储介质例如可以包括但不限于电存储设备、磁存储设备、光存储设备、电磁存储设备、半导体存储设备或者上述的任意合适的组合。计算机可读存储介质的更具体的例子(非穷举的列表)包括:便携式计算机盘、硬盘、随机存取存储器(RAM)、只读存储器(ROM)、可擦式可编程只读存储器(EPROM或闪存)、静态随机存取存储器(SRAM)、便携式压缩盘只读存储器(CD-ROM)、数字多功能盘(DVD)、记忆棒、软盘、机械编码设备、例如其上存储有指令的打孔卡或凹槽内凸起结构、以及上述的任意合适的组合。
以上已经描述了本发明的各实施例,上述说明是示例性的,并非穷尽性的,并且也不限于所披露的各实施例。在不偏离所说明的各实施例的范围和精神的情况下,对于本技术领域的普通技术人员来说许多修改和变更都是显而易见的。本文中所用术语的选择,旨在最好地解释各实施例的原理、实际应用或对市场中的技术改进,或者使本技术领域的其它普通技术人员能理解本文披露的各实施例。
- 一种推荐模型的训练方法、介质、电子设备和推荐模型
- 一种推荐模型训练方法、装置、电子设备及存储介质