一种基于扰动压缩感知的稀疏表示分类方法
文献发布时间:2023-06-19 09:36:59
技术领域
本发明涉及感知技术领域,尤其涉及一种基于扰动压缩感知的稀疏表示分类方法。
背景技术
稀疏表示分类(Sparse Representation Classification,SRC)的基本思想是:使用训练样本对测试样本进行表示,并采用L0稀疏范数或L1凸范数对表示稀疏进行约束。目前稀疏表示分类方案被广泛应用于手写识别、人脸识别等场景中,并被扩展至半监督分类、维数约简等机器学习技术。稀疏表示分类方法的数学模型为
y=Dα
其中,y∈R
在实际的稀疏表示分类系统中,系统使用的训练样本和测试样本不可避免的会受到各种非理想因素的影响,例如,样本中必然会包含的高斯噪声,图像样本中的光线,灰尘和遮挡物,甚至硬件问题所导致的样本轻微畸变。如果在稀疏表示分类系统设计中不考虑这些因素的影响,会导致稀疏表示分类系统在实际应用中的准确率降低。
发明内容
为解决现有技术存在的局限和缺陷,本发明提供一种基于扰动压缩感知的稀疏表示分类方法,包括:
根据系统输入的测试样本,获得稀疏表示模型,所述稀疏表示模型的计算公式如下:
y=(D+E)α
其中,E是扰动矩阵,表示已知矩阵D与理想字典矩阵
获得每个类别的测试样本对应的扰动字典,计算公式如下:
H
其中,y
求解如下的优化问题获得稀疏向量:
其中,
获得各个类别测试样本对应的残差,计算公式如下:
获得具有最小残差的类别min||r
具体而言,其对应的求解步骤包括:
步骤101:初始化r
步骤102:获得相关性最高的训练样本
步骤103:对于每个候选的类别j,选出支撑集中所有属于第j 类的训练样本T
步骤104:获得具有最小残差的类别
步骤105:获得具有最小残差的类别对应的修正参数,计算公式如下:
步骤106:获得具有最小残差的类别的优化字典,计算公式如下:
步骤107:更新残差
步骤108:若k=K,执行步骤109,否则重新设置k=k+1返回步骤102;
步骤109:获得支撑集位置的系数
可选的,所述步骤102包括:
获得相关性最高的S个训练样本集合
可选的,还包括:
步骤201:初始化r
步骤202:获得相关性最高的K个训练样本集合
步骤203:计算系数
步骤204:对每个候选的类别j,选出支撑集中所有属于第j类的训练样本T
步骤205:获得具有最小残差的类别
步骤206:计算第j类的训练样本T
步骤207:计算第j类的训练样本T
步骤208:更新残差
步骤209:若||r
步骤2010:计算支撑集位置的系数
本发明具有下述有益效果:
本实施例提供的基于扰动压缩感知的稀疏表示分类方法,包括:获得稀疏表示模型,获得每个类别的测试样本对应的扰动字典,求解优化问题获得稀疏向量,获得各个类别测试样本对应的残差,获得具有最小残差的类别。
本实施例通过求解扰动重建问题获得更优的字典矩阵和稀疏系数向量,从而提升分类准确率。即使在所使用的训练样本中存在扰动的情况下,本实施例提供的技术方案亦能获得优良的性能,鲁棒性好,应用范围广。
附图说明
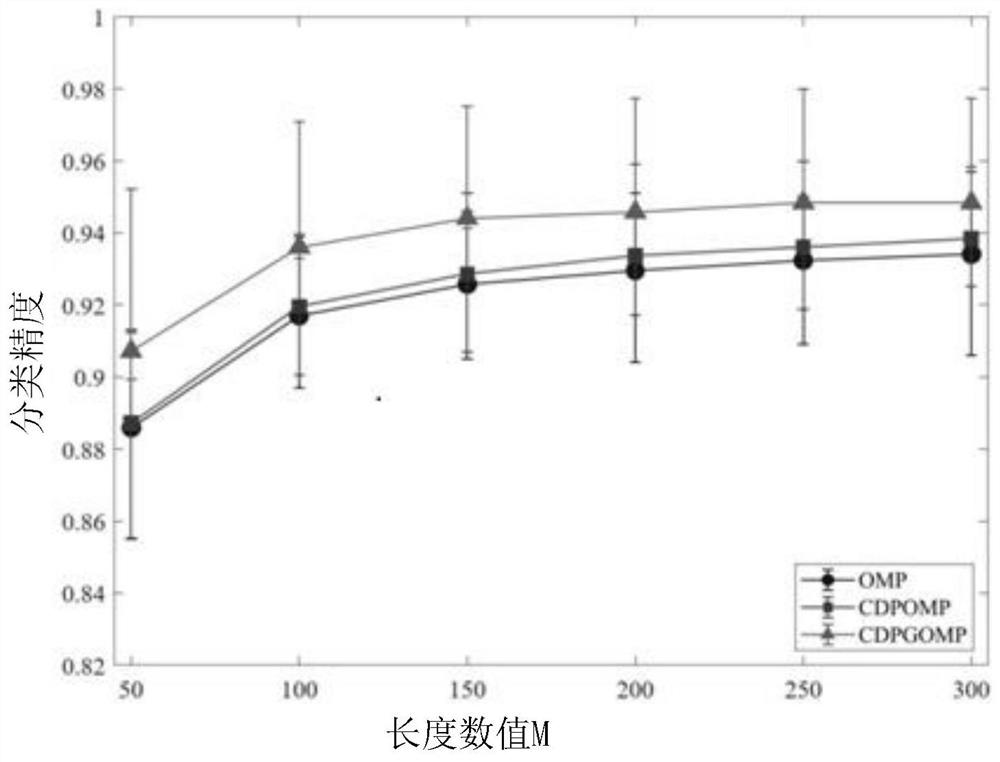
图1为本发明实施例一提供的CDPGOMP的分类精度与样本长度的关系示意图。
图2为本发明实施例一提供的CDPSP算法与OMP算法和SP算法相比的分类精度图。
具体实施方式
为使本领域的技术人员更好地理解本发明的技术方案,下面结合附图对本发明提供的基于扰动压缩感知的稀疏表示分类方法进行详细描述。
实施例一
由于本实施例提供技术方案基于扰动压缩感知技术来进行设计,因此需要介绍扰动压缩感知的相关背景。压缩感知是一个里程碑式的应用于信号处理的理论,其允许在对信号进行采集的同时完成压缩。具体而言,压缩感知技术通过使用随机测量矩阵对信号进行投影的方式得到压缩后的低维度数据,并保证能够从这些低维压缩数据中正确地重建出原始信号。
在某种意义上,压缩感知理论是对信息而不是对数据进行采样,在保证能够重建出原始信号的前提下,压缩样本的维度将由信号中信息的结构和内容决定。压缩感知技术在实际应用中面临着如下问题。由于压缩感知技术使用特制硬件直接获得压缩数据,而硬件系统中往往包含着某些未知的非理想因素,因此压缩数据所经历的信号过程往往与系统的原始设计之间存在微小差异。
也就是说,系统预先设定的测量矩阵和实际使用的未知测量矩阵之间往往存在不一致,这就是测量矩阵的扰动问题。而扰动情况下的压缩感知问题也就被称为扰动压缩感知问题。
基于稀疏表示分类方案的理论基础是属于同一类别的样本之间具有高度相似性。因此,测试样本应该可以由属于同一类别的训练样本线性表示。假设在给定的训练集D=[D
传统稀疏表示分类方案尝试通过选择K个训练样本构成的组合来线性地(稀疏地)表示测试样本。而这K个训练样本则来自属于不同类别的所有训练样本组成的训练字典D。测试样本y的类别标签由能够产生最低重构误差(残差)的样本组D
在理想情况下,如果已知测试样本y的类别为j,则y可以被近似表示为
其中,α
y≈Dα (1)
其中,
其中,L0范数定义为向量α中非零元素的个数。
然而,在实际场景中,系统得到的稀疏向量α往往包含属于多个不同类别的训练样本的非零元素。因此,稀疏表示分类系统中会针对每个类别构造出对应的只包含该类别训练样本的非零元素的稀疏向量。即,对于第j类仅保留属于该类别的H≤Q个训练样本的元素,对应的稀疏系数向量形式为
标记α
r
最后,测试样本y的类别则被定为具有最小残差的类别,即
label(y)=arg min
由此可见,稀疏表示分类方案的核心在于公式(1)构成的稀疏表示模型及其对应的优化问题(公式(2))和求解算法。目前已有多种方法可以找到该问题的近似解,例如基于正交匹配追踪算法,广义正交匹配追踪算法,子空间追踪算法等重建算法。
传统稀疏表示分类方案假设测试样本位于由属于同一类别的训练样本组成的子空间中,即任何测试样本都能由同一类别中的训练样本线性表示。但是,在实际应用中,由于样本中的噪声等非理想因素的影响,大部分测试样本其实并不能由训练样本完全地线性表示,这导致稀疏系数向量α与测试样本y之间的相关性下降,进而导致稀疏表示分类方案的分类性能较差。
本实施例正是基于此问题,设计使用更优的字典矩阵用于表示测试样本。本实施例使用的字典矩阵
为了更准确地表示测试样本,本实施例将使用一个经过优化的字典矩阵
本实施例提供一种基于扰动压缩感知的稀疏表示分类方法,包括:获得稀疏表示模型,获得每个类别的测试样本对应的扰动字典,求解优化问题获得稀疏向量,获得各个类别测试样本对应的残差,获得具有最小残差的类别。
现有稀疏表示方法大都假设训练样本能够线性表示测试样本,然而实际系统中该假设往往不成立。针对这一问题,本实施例将稀疏表示分类建模为扰动压缩感知模型,并通过求解扰动重建问题获得更优的字典矩阵和稀疏系数向量,从而提升分类准确率。
由于在实际应用中,大部分测试样本其实并不能由训练样本完全地线性表示,因此相比公式(1),更为准确的模型应该为
y=Dα+y
其中,y
由于矩阵D无法完全对测试样本进行线性表示,这一问题必然对分类产生影响。对此,本实施例使用一个更优的字典矩阵
y=(D+E)α (3)
基于该模型求解稀疏表示向量α,能有效提升分类的准确性。可以发现,上式中的模型与扰动压缩感知的模型完全一致。因此,本实施例将基于扰动压缩感知理论,设计分类框架和相应的稀疏求解算法。为了与扰动压缩感知保持一致,后面将称矩阵E为扰动矩阵。
字典
H
基于以上观点,为了得到矩阵E
其中,
表1:基于扰动压缩感知的稀疏表示分类框架
针对上述分类框架,本实施例提出了多种求解算法。首先,本实施例根据扰动正交匹配追踪(Perturbed Orthogonal Matching Pursuit,POMP)算法提出了基于类别的扰动正交匹配追踪 (Class-Depend Perturbed Orthogonal Matching Pursuit,CDPOMP) 算法,如表2所示,该算法在每次循环中寻找合适的候选支撑集,并对每个类的字典矩阵进行独立优化。接下来,本实施例将详细说明CDPOMP算法中的字典优化机制。
根据公式(4)中给出的模型,各个类别所对应的扰动应该是不同的。为了实现这一点,本实施例以扰动正交匹配追踪(Perturbed Orthogonal Matching Pursuit,POMP)算法中的字典修正机制为基础,设计了算法中的字典优化机制。
原有的机制使用了由多个类别的训练样本组成的完整支撑集。在本实施例改进的机制中,仅基于属于支撑集中对应类别的训练样本来计算每个类别中的修正参数。由于每个类别的训练样本与其他类别的训练样本不同,因此针对不同类别计算得到的优化字典也不同。改进后的字典修正机制需要对每个可能的类进行分别计算,以在每次迭代中为每个类生成不同的修正字典。
为了降低计算复杂度,本实施例对该机制进行了进一步优化。在每次迭代中,仅对测试样本最有可能属于的类所对应的训练样本和残差来生成对应修正参数(即下述表2中的步骤3-6)。以此,本实施例提出的算法就可以确保每个类别中的优化字典互不相同,并以较低的复杂度提高分类性能。
表2:基于类别的扰动正交匹配追踪算法
更进一步,本实施例根据表1的框架,基于广义正交匹配追踪 (GeneralizedOrthogonal Matching Pursuit,GOMP)算法提出了性能更好的基于类别的扰动广义正交匹配追踪(Class-Depend Perturbed Generalized Orthogonal Matching Pursuit,CDPGOMP),如表3所示。该算法中,本实施例优化了支撑集选择机制,提升了选择正确非零位置的速度,从而进一步提高分类性能。表2中所描述的CDPOMP 算法的性能受限于字典优化机制计算中的误差。在CDPOMP算法的每次循环中,仅有一个非零位置被添加到支撑集中。因此,支撑集中的所有训练样本可能全都属于错误的类别,这导致字典修正机制不可避免地以错误的方式工作。作为改良算法的CDPGOMP算法中,由于支撑集的拓展速度得到显著提升,其包含训练样本更多。因此,支撑集中存在属于正确类别的训练样本的可能性更高,字典修正机制基于正确类别工作的可能性也高。也就是说,本实施例有效避免了字典修正机制以错误方式工作的情况的出现,从而降低了错误分类的比率。
表3:基于类别的扰动广义正交匹配追踪算法
最后,本实施例根据表1的框架,基于子空间追踪(Subspace Pursuit,SP)算法提出了基于类别的扰动子空间追踪(Class-Depend Perturbed Subspace Pursuit,CDPSP)算法,如表4所示。CDPSP算法在一次循环中同样选择并添加多个幅度相关性最大的训练样本进入支撑集(表4中的步骤2)。在这之后,引入支撑集精炼机制,通过对应的投影系数对支撑集进行修剪操作(表4中的步骤3)。该机制可以有效排除支撑集中属于错误类别的一部分训练样本,从而进一步降低了字典修正机制运行不正确的可能性。同时,为了降低复杂度,CDPSP算法对各个类别的残差计算方式(表4中的步骤4) 进行了优化,其复用了步骤3中的投影系数,避免了多次进行伪逆运算,以降低CDPSP算法的复杂性。
表4:基于类别的扰动子空间追踪算法
本实施例将以传统稀疏表示分类方法(使用OMP/SP算法求解优化问题)为基准,评估本实施例提出的稀疏表示分类方案。图1 为本发明实施例一提供的CDPGOMP的分类精度与样本长度的关系示意图,图2为本发明实施例一提供的CDPSP算法与OMP算法和 SP算法相比的分类精度图。如图1和图2所示,实验的样本数据集为MNIST手写数字数据集,其包含70000张28*28像素的手写数字图像。在实验中,训练集包含60000个样本,测试集包含10000个样本。实验结果进行1000次平均,每次实验均通过根据标准随机生成的测量矩阵将这些原始数据压缩为长度M的压缩样本,每个类别均随机选出500个训练样本和100个测试样本。
通过实验可以看出,本实施例提出的CDPSP方案的性能远优于 OMP方案和SP方案,因此本实施例提出的基于扰动压缩感知的稀疏表示分类方法,通过求解扰动重建问题获得更优的字典矩阵和稀疏系数向量,从而提升分类准确率。
可以理解的是,以上实施方式仅仅是为了说明本发明的原理而采用的示例性实施方式,然而本发明并不局限于此。对于本领域内的普通技术人员而言,在不脱离本发明的精神和实质的情况下,可以做出各种变型和改进,这些变型和改进也视为本发明的保护范围。
- 一种基于扰动压缩感知的稀疏表示分类方法
- 基于稀疏表示分类器的分布式压缩感知数据分类方法