一种具有自适应配置生成器的调参方法和系统
文献发布时间:2023-06-19 10:11:51
技术领域
本发明涉及大数据处理技术领域,尤其涉及一种具有自适应配置生成器的调参方法和系统。
背景技术
大数据处理框架诸如Spark、Flink等在大数据分析、计算具有很广泛的应用场景,它们都提供了上百个配置项以满足灵活性的需求。美国加州大学圣地亚哥分校周源源教授研究表明有60%的云计算或大数据系统崩溃是由配置不当导致的。配置参数的设定不仅关乎大数据处理框架的稳定性,更和大数据处理框架的性能直接相关,通常将这类和性能息息相关的配置项记作关键配置项。最近的研究DAC表明,通过调整这些关键配置可以达到89倍的优化效果(相对于默认配置下的性能),这说明大数据处理框架的配置具有很大的优化空间和效益空间。但是调参优化是一个极具挑战性的工作,这是由于:1)配置空间极其庞大,难以全部覆盖;2)配置项间以非线性的方式相互影响,增加了沿最短路径的方向寻找优化配置的难度。
目前,主要有4类主流的调参方法:
1)基于规则的调参方法,这类方法主要是依赖官方给出的调参指南或者专家的经验和知识进行调参,不需要建立性能模型,可以快速地给出一组配置方案。这种基于规则的调参方法过于依赖人的主观认识,优化效果往往不是很突出。
2)基于机器学习方法的调参方法,该类方法利用机器学习算法构建性能分析模型用于捕捉配置项和集群性能的相关性与特征,往往可以达到很好的优化效果,如DAC、RFHOC等。这种基于机器学习算法的调参方法需要收集大量的训练数据,这样的时间开销在流式处理框架是难以接受的。
3)基于模拟器的调参方法,这类方法可以捕捉目标大数据框架的内部行为特征和外部观测到的程序间的相关性,不需要对大数据框架有深入的认识和项目经验,如Hsim、MEPerf。
4)基于搜索的调参方法,该类方法将调参问题当成一个黑盒优化问题并利用搜索算法找出近似最优解,这类方法容易部署到各大数据框架且时间开销往往比较少,如CherryPick、Selecta、BestConfig,但没有考虑配置层面的优化。
总之,基于搜索的方法只是在算法层面进行优化,并没有考虑配置层面的优化,即配置样本集的质量是两极化、不稳定的。而基于模拟器的调参方法需要多次探测系统内部特征,收集性能模型中所需的原始数据,并且难以覆盖可能影响集群性能的所有因素;基于搜索的调参算法往往容易陷入探索-开发困境。
发明内容
本发明的目的在于克服上述现有技术的缺陷,提供一种具有自适应配置生成器的调参方法和系统。
根据本发明的第一方面,提供了一种具有自适应配置生成器的调参方法。该方法包括以下步骤:
步骤S1:从需要进行优化的配置项中随机产生多个配置;
步骤S2:验证所述多个配置对应的性能,获得配置与性能对应关系的配置-性能样本数据集;
步骤S3:基于所述配置-性能样本数据集构建高斯过程预测模型,以预测配置和性能的对应关系;
步骤S4:构建配置候选集,并以性能提升程度可能性为目标,利用所述高斯过程预测模型从所述配置候选集中选择待验证的目标配置;
步骤S5:验证所述目标配置对应的性能,并更新所述配置-性能样本数据集,重复执行步骤S3至S5,直到达到预定的优化目标。
在一个实施例中,在步骤S4中,基于随机产生的配置和生成式对抗网络产生的配置构建所述配置候选集。
在一个实施例中,步骤S4中,利用期望改进的采集函数衡量所述配置候选集中各配置的性能提升程度可能性的EI值,并选择EI值最大的配置作为所述待验证的目标配置。
在一个实施例中,步骤S4还包括:判断EI值最大的配置是否已经验证过,如果该配置已验证过,则记作重复推荐,重复推荐次数加1,如果重复推荐次数没有超过设置的容忍度阈值,则重新构建所述配置候选集;如果重复推荐次数超过设置的容忍度阈值,则配置候选集直接基于生成式对抗网络产生,并将重复推荐次数重置为0。
在一个实施例中,所述性能包括执行时间、吞吐量和延迟中的一项或多项。
在一个实施例中,所述预定的优化目标包括迭代次数和/或优化效果。
根据本发明的第二方面,提供一种具有自适应配置生成器的调参系统。该系统包括:
配置生成器:包括随机配置生成器,其用于从需要进行优化的配置项中随机产生多个配置;
配置分析器:用于验证所述多个配置对应的性能,获得配置和性能对应关系的配置-性能样本数据集;
高斯过程构建器:用于基于所述配置-性能样本数据集构建高斯过程预测模型,以预测配置和性能的对应关系;
配置仲裁器:用于构建配置候选集,以性能提升程度可能性为目标,利用所述高斯过程预测模型从所述配置候选集中选择待验证的目标配置发送给所述配置分析器,直到达到预定的优化目标。
在一个实施例中,所述配置生成器还包括基于生成式对抗网络的配置生成器。
在一个实施例中,所述配置候选集包含所述随机配置生成器产生的配置和/或所述基于生成式对抗网络的配置生成器所产生的配置。
与现有技术相比,本发明的优点在于:本发明设计的具有自适应配置生成器的调参方法,其中配置生成器利用对抗式生成网络(GAN)来定制化地产生指定性能区间的配置样本,从而有更大的可能性验证质量更好的配置(即配置对应的程序性能表现很好),同时可以保证在同一时间对配置空间进行探索和开发。本发明能够实现只进行少量的采样和验证就可以获得近似最优配置的愿景。相比现有技术只考虑调参算法上的优化,本发明又从配置层面优化了配置的质量,达到只进行少量的采样验证就可以获得数十倍的性能优化效果。
附图说明
以下附图仅对本发明作示意性的说明和解释,并不用于限定本发明的范围,其中:
图1示出了根据本发明一个实施例的具有自适应配置生成器的调参系统的框架图;
图2示出了根据本发明一个实施例的配置仲裁器的流程图;
图3示出了根据本发明一个实施例的具有自适应配置生成器的调参方法的流程图。
具体实施方式
为了使本发明的目的、技术方案、设计方法及优点更加清楚明了,以下结合附图通过具体实施例对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅用于解释本发明,并不用于限定本发明。
在本文示出和讨论的所有例子中,任何具体值应被解释为仅仅是示例性的,而不是作为限制。因此,示例性实施例的其它例子可以具有不同的值。
对于相关领域普通技术人员已知的技术、方法和设备可能不作详细讨论,但在适当情况下,所述技术、方法和设备应当被视为说明书的一部分。
为清楚的理解本发明的过程,以图1所示的具有自适应配置生成器的调参系统为例进行介绍。该系统包括:配置生成器、配置分析器、高斯过程构建器和配置仲裁器,简言之,该系统依据已有的配置和相应的性能信息,推测下一观测配置的取值,做到一次迭代过程可以验证一个可能为近似最优配置的配置样本。
一、关于配置生成器
配置生成器用于从待进行优化的配置项中产生配置,可采用多种类型的配置生成器,例如,随机配置生成器(记作RCG),由随机函数产生给定维度的配置;又如,基于GAN(对抗式生成网络)的配置生成器(记作GCG),其利用GAN捕捉指定配置的分布特征进而产生类似分布特征的配置,通常一个配置向量对应一个程序的性能值域,且该性能值域是相对稳定的,因此如果GCG能够捕捉指定配置的分布特征,则由GCG产生的配置所对应的性能值域也会落在指定配置对应的性能值域附近。
具体地,基于GAN的配置生成器的输入例如是一组配置,标记为conf1,输出则为N组类似conf1分布特征的配置,这些配置都具有一个特征,即理论上,这些配置对应的性能落在conf1对应的性能值域附近。
配置生成器产生的配置(即输出)可以作为配置分析器的输入和/或作为配置仲裁器的输入。
需说明的是,在本文所涉及的配置或称配置项是指影响大数据处理框架性能的参数,例如,包括但不限于:参数num-executors/spark.executor.instances,其用于设置Spark作业总共要用多少个Executor(执行器)进程来执行;又如,参数executor-memory/spark.executor.memory用于设置每个Executor进程的内存。
二、关于配置分析器
配置分析器用于验证配置对应的性能,收集和保存相应的性能指标。例如,配置分析器用于将某组特定的配置部署在大数据集群中,执行指定的程序并收集相应的性能指标,性能指标和该组配置组成一个配置-性能向量(或称配置-性能样本数据集),这样的向量可以作为后续高斯过程构建器的输入样本数据集。其中性能指标可以为(批处理框架的)程序执行时间、(流处理框架的)吞吐量和延迟等。
配置分析器的输入源可以来自于配置生成器所产生的配置或来自于配置仲裁器挑选出的配置。
三、关于高斯过程构建器
高斯过程构建器的作用是依据配置分析器维护的“配置-性能”样本数据集建立或更新高斯模型,该高斯模型用于分析配置与性能间的对应关系,将配置输入到高斯模型,可获得预测的性能。
假设配置分析器收集的每组配置-性能向量都服从高斯分布,同时它们的联合概率分布都服从高斯分布,即高斯过程构建器利用配置-性能向量构建高斯过程模型,并且在每次新的配置-性能向量加入时都会更新高斯过程模型,以满足上述假设。
在建立或更新高斯模型过程中,可采用均值函数或协方差函数衡量模型精度,在本文中将高斯模型也称为高斯性能预测模型。
四、关于配置仲裁器
配置仲裁器用于挑选出最大可能性获得更好性能的配置作为下一组配置分析器要验证的配置。
在一个实施例中,如图2所示,配置仲裁器首先会构建一个配置候选集,该配置候选集有GCG和RCG产生的配置构成,下一个观测配置样本将在该配置候选集中选出,其中GCG产生的是同当前最优配置性能区间相仿的配置(标记为CONFcurrent_best)。然后,利用EI(预期改进,exception of improvement,)采集函数衡量配置候选集中各配置可能获得的性能提升空间(用EI值衡量),并选择EI值最大的配置(标记为CONFpotential)。接着,验证EI值最大的配置是否已经验证过(即是否在已验证配置集),如果该配置已验证过,则记作重复推荐,重复推荐次数(标记为re_com)加1,如果重复推荐次数没有超过容忍度tolerance(表示能接受的累积重复推荐次数),则重新构建候选集和往后的操作流程;如果重复推荐次数超过容忍度,则候选集直接由GCG产生的配置构成,重复推荐次数re_com重置为0,此时GCG产生的配置是类似当前具有最大EI值的配置的分布;如果该配置还未验证过,则该配置为下一个将要观测的配置样本(CONFnext_evaluate)。设置容忍度的原因是为了减少重复推荐的时间的开销。
配置仲裁器将最终找到的具有最大可能的性能提升空间的配置,返回给配置分析器(图1未示出配置仲裁器和配置分析器之间的关联),重复配置分析、高斯过程构建器、配置仲裁器的过程,直到迭代次数超过设置值或者优化效果已经满足要求,并将此时获得的待观测的配置样本作为优化后的配置。
配置仲裁器有两个输入:由配置分析器产生的配置构成的配置候选集以及高斯过程构建器构建的配置-性能的对应关系;配置仲裁器利用这个对应关系和EI函数计算配置候选集中每组配置的性能提升程度(相对于当前最优配置性能),输出提升程度最大的配置,该组配置作为下一次迭代中配置分析器的输入。
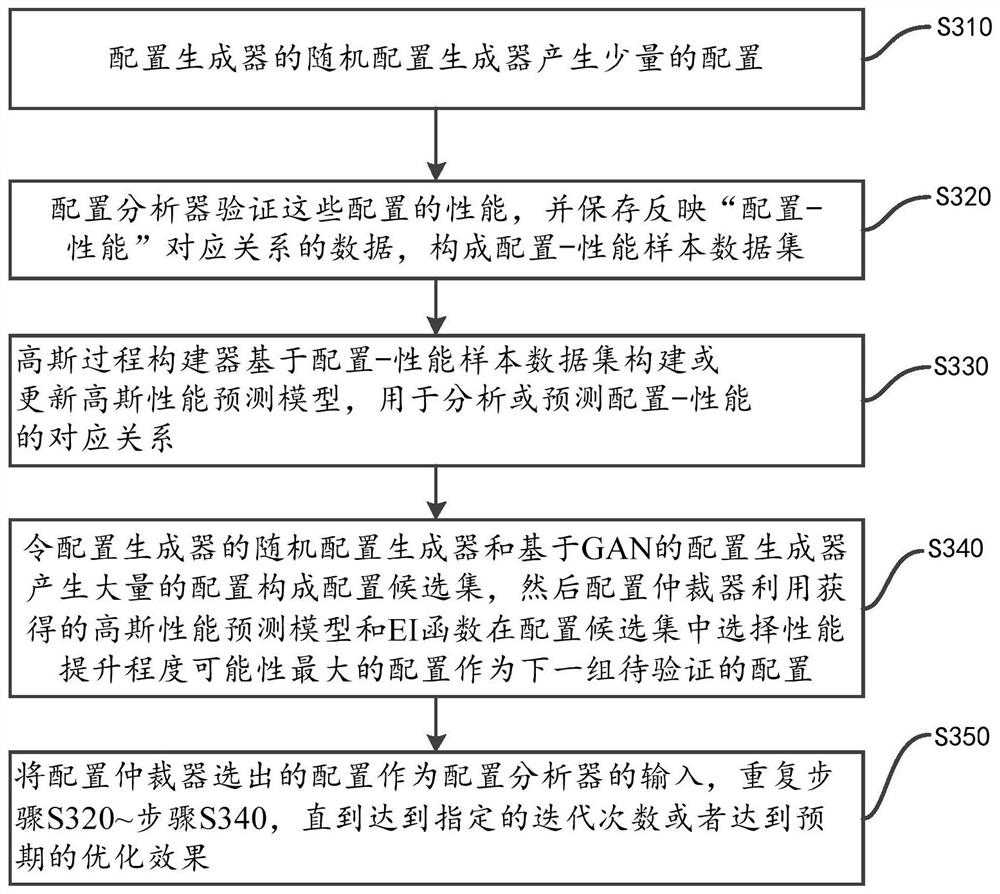
具体地,在一个实施例中,涉及配置生成器、配置分析器、高斯过程构建器和配置仲裁器的调参方法的流程参见图3所示,包括:
步骤S310,配置生成器的随机配置生成器产生少量的配置;
例如,产生10个配置或20个配置等。
步骤S320,配置分析器验证这些配置的性能,并保存反映“配置-性能”对应关系的数据,构成配置-性能样本数据集;
步骤S330,高斯过程构建器基于配置-性能样本数据集构建或更新高斯性能预测模型,用于分析或预测“配置-性能”的对应关系;
例如,初始时,是利用步骤S310中的少量配置构建高斯性能预测模型,当后续获得新验证的配置-性能对应关系时,将新的验证结果加入到配置-性能样本数据集,以进一步更新高斯性能预测模型。
步骤S340,令配置生成器的随机配置生成器和基于GAN的配置生成器产生大量的配置构成配置候选集,然后配置仲裁器利用获得的高斯性能预测模型和EI函数在配置候选集中选择性能提升程度可能性最大的配置作为下一组待验证的配置;
步骤S350:将配置仲裁器选出的配置作为配置分析器的输入,重复步骤S320~步骤S340,直到达到指定的迭代次数或者达到预期的优化效果时,结束循环。
在本发明实施例中,为依据已有的配置和相应的性能信息,推测下一观测配置的取值,做到一次迭代过程可以验证一个可能为近似最优配置的配置样本。
为了验证效果,将本发明应用在Spark和Flink两个主流的数据处理框架上,Spark上的优化效果如表1和表2所示,其中仅列举了Spark集群上4个程序在单个数据集下的优化效果和时间开销,其中例如WordCount-80G的形式表示程序和对应的输入数据集大小,表2的时间单位为小时。Flink上的优化效果如表3所示。另外,将本发明部署到京东的线上环境中,在京东原有的优化效果的基础上又进一步提高了2.3倍的吞吐量,降低了2.8倍的第99百分位延迟。实验表明,本发明只用了很少的时间开销就可以达到当前主流调参方法的优化效果甚至更好的性能表现。
表1:在Spark实验室环境的优化效果对比
其中,DAC、cherryPick、Selecta是现有技术的方法,swift是本发明的方法,取值表示采用优化后的配置的执行时间与默认配置执行时间之比。
表2:在Spark实验室环境的时间开销对比
在表2中,取值表示时间开销(单位小时数),可见本发明相对于现有技术的调参方法,时间开销显著降低。
表3:在Flink实验室环境的优化效果
在表3中,取值表示利用优化的配置获得的吞吐量/延时相对于默认配置下获得的吞吐量/延时之间的倍数,并同时列出了利用的样本数,例如,25samples表示验证中采用了25个样本。可见,本发明的方法仅利用较少的样本即可实现吞吐量/延时(吞吐量与延时的比)方面的较佳效果。
应理解的是,本发明设计的自适应配置生成器不仅可应用于调参优化,它应属于数据采集的样本空间质量优化范畴。对本领域普通技术人员来说,可以根据上述说明加以改进或变换应用于不同的系统,或者进行相关参数的调节和选取。所有这些改进和变换,及参数相关的调节和选取都应属于本发明所附权利要求的保护范围。
综上所述,本发明结合对抗式生成网络GAN设计的自适应配置生成器可以定制化地产生指定性能区间的配置样本,从配置层面上优化配置样本质量,同时可以保证在同一时间对配置空间进行探索和开发,进而实现只进行少量的采样和验证就可以获得近似最优配置的愿景。本发明所提供的自适应配置生成器的调参系统和方法,利用贝叶斯优化和对抗生成网络,实现配置层面的优化控制,在每次采样验证的过程中提高了当前最优配置在配置候选集的影响力。本发明实施例能够解决大数据处理框架的调参优化的两大问题,即:参数与优化目标间复杂的相关性导致的参数搜索方向难以确定;调参优化效果与时间开销难以平衡的问题。
需要说明的是,虽然上文按照特定顺序描述了各个步骤,但是并不意味着必须按照上述特定顺序来执行各个步骤,实际上,这些步骤中的一些可以并发执行,甚至改变顺序,只要能够实现所需要的功能即可。
本发明可以是系统、方法和/或计算机程序产品。计算机程序产品可以包括计算机可读存储介质,其上载有用于使处理器实现本发明的各个方面的计算机可读程序指令。
计算机可读存储介质可以是保持和存储由指令执行设备使用的指令的有形设备。计算机可读存储介质例如可以包括但不限于电存储设备、磁存储设备、光存储设备、电磁存储设备、半导体存储设备或者上述的任意合适的组合。计算机可读存储介质的更具体的例子(非穷举的列表)包括:便携式计算机盘、硬盘、随机存取存储器(RAM)、只读存储器(ROM)、可擦式可编程只读存储器(EPROM或闪存)、静态随机存取存储器(SRAM)、便携式压缩盘只读存储器(CD-ROM)、数字多功能盘(DVD)、记忆棒、软盘、机械编码设备、例如其上存储有指令的打孔卡或凹槽内凸起结构、以及上述的任意合适的组合。
以上已经描述了本发明的各实施例,上述说明是示例性的,并非穷尽性的,并且也不限于所披露的各实施例。在不偏离所说明的各实施例的范围和精神的情况下,对于本技术领域的普通技术人员来说许多修改和变更都是显而易见的。本文中所用术语的选择,旨在最好地解释各实施例的原理、实际应用或对市场中的技术改进,或者使本技术领域的其它普通技术人员能理解本文披露的各实施例。
- 一种具有自适应配置生成器的调参方法和系统
- 具有自适应调参功能的光纤安防信号双重识别方法与系统