一种口语评测系统及其方法
文献发布时间:2023-06-19 10:27:30
技术领域
本发明涉及语音识别及评价技术领域,尤其是涉及一种口语评测系统及其方法。
背景技术
随着网络课堂、云教学等新兴教学方式的流行,使得学生能够随时进行课程学习,但在进行口语教学时,受到设备、地点以及教学时长的影响,难以进行可靠有效的口语测试,教师也不能及时、完整、准确获取并管理所有学生的口语学习成果,教师与学生之间的互动性较差,大大限制了网络口语教学的应用、不能良好开展口语教学。
目前已有许多支持用户自主进行口语练习的客户端软件,但这些软件大多只支持语音识别,并不能对用户语音的准确度、完整度和流畅度进行评测。
发明内容
本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种口语评测系统及其方法,能够对学生用户口语进行全面评测,且能使教师及时、完整、准确获取并管理所有学生的口语评测结果,以便后续开展良好的口语教学。
本发明的目的可以通过以下技术方案来实现:一种口语评测系统,包括教师客户端、学生客户端以及服务器,所述教师客户端、学生客户端分别与服务器相互连接,所述教师客户端用于教师用户管理学生信息、上传语料数据、上传教师用户信息、上传教学计划信息以及查看所有学生口语分数;
所述学生客户端用于学生用户上传学生用户信息、获取语料数据及教学计划信息、上传待测语音以及查看当前用户口语分数;
所述服务器用于存储教师用户信息以及学生用户信息、存储语料数据、对待测语音进行准确度、完整度和流畅度评测、得到对应于学生用户的口语分数。
进一步地,所述服务器内设置有通信模块、数据库以及语音评价模块,所述教师客户端和学生客户端均通过通信模块与数据库相互连接,所述语音评价模块的输入端通过通信模块与学生客户端连接,所述语音评价模块的输出端与数据库连接,所述语音评价模块用于对来自学生客户端的待测语音进行准确度、完整度和流畅度评测,得到对应的口语分数;
所述数据库用于存储教师用户信息及学生用户信息、存储来自教师客户端的语料数据及教学计划信息、存储与学生用户信息对应的口语分数。
进一步地,所述通信模块具体采用两层C/S架构、Serverless架构或混合架构,所述混合架构包括C/S架构和Serverless架构。
进一步地,所述语音评价模块包括依次连接预处理单元、特征提取单元、模式匹配单元和后处理单元,所述预处理单元与学生客户端连接,所述后处理单元与数据库连接,所述预处理单元用于对待测语音进行滤波及分帧处理;
所述特征提取单元用于从预处理后的待测语音信号中提取特征向量;
所述模式匹配单元用于识别出待测语音对应的语句信息;
所述后处理单元根据待测语音及其对应的语句信息、语料数据,得到待测语音对应的准确度、完整度和流畅度分数,即为口语分数。
进一步地,所述模式匹配单元内设置有与特征提取单元连接的训练模型,所述训练模型用于根据待测语音的特征向量,识别输出对应的语句信息。
进一步地,所述训练模型具体选用隐马尔可夫结合神经网络的模型结构。
进一步地,所述训练模型包括声学模型和语言模型,所述声学模型通过对大量语音数据进行训练获得,其输入是语音特征向量,其输出为音素信息;
所述语言模型通过对大量文本信息进行训练获得,其输出为单个字或词相互关联的概率。
一种口语评测方法,包括以下步骤:
S1、教师客户端获取教师用户信息、学生名单、教学计划信息以及语料数据,并将获取的信息数据传输给服务器进行存储;
S2、学生客户端获取学生用户信息,并传输给服务器进行存储;
S3、学生客户端从服务器获取语料数据,并将获取的语料数据输出给学生用户;
S4、学生客户端接收来自学生用户的待测语音,并传输给服务器;
S5、服务器对待测语音进行准确度、完整度及流畅度评测,得到口语分数,并将该口语分数与学生用户信息对应进行存储、将该口语分数输出给学生客户端;
S6、教师客户端从服务器获取学生名单中已有学生对应的口语分数,以便教师用户查看其学生的口语学习成果。
进一步地,所述语料数据包括测试语句信息及对应的语音数据。
进一步地,所述步骤S5中服务器对待测语音进行准确度、完整度及流畅度评测的具体过程为:
S51、对待测语音进行预处理,具体是采用滤波方法对待测语音数字信号进行去噪处理,并对待测语音数字信号进行端点检测、音段切分,以得到有效语音的起始点及结束点;
S52、从预处理后的有效语音中提取能够表征语音特性的特征向量;
S53、将特征向量输入声学模型,得到对应的音素串,基于动态时间规整法,找到每个音素的起止时间及各音素之间的分界点,通过字典匹配的方式,得到各音素对应的文本信息;
S54、将各音素对应的文本信息输入语言模型,得到待测语音对应概率最高的语句信息;
S55、将待测语音对应概率最高的语句信息与测试语句信息进行对比,生成准确度评分;
统计待测语音的发音间隔、发音起始点及结束点,生成完整度评分以及流畅度评分。
与现有技术相比,本发明具有以下优点:
一、本发明通过设置与服务器分别连接的教师客户端和学生客户端,教师用户及学生用户能够双端访问服务器,提高了教师用户与学生用户之间的互动性,使得学生用户能够从服务器获取教师用户上传的测试语料数据、教师用户能够从服务器及时、完整、准确获取所有学生的口语评测分数,大大提高了网络口语教学测试的有效性及可靠性,不再受到时间、地点及设备的限制,教师用户和学生用户均可自主地在各自客户端完成相应操作。
二、本发明通过在服务器内设置通信模块、数据库以及语音评测模块,使得服务器不仅能够实现与教师客户端、学生客户端之间的数据传输,能够对教师客户端以及学生客户端上传的数据信息进行相应存储,同时能够对待测语音进行准确度、完整度以及流畅度的全面评测,保证了口语评测的全面性。
三、本发明通过对待测语音依次进行预处理、特征提取、模式匹配及后处理,并基于训练好的声学模型以及语言模型进行模式匹配,以识别得到待测语音对应的语句信息,最后将识别得到的语句信息与测试语料数据进行比较,能够得到准确的准确度评分,此外,本发明通过统计待测语音的发音间隔、发音起始点及结束点,能够进一步得到准确的完整度评分及流畅度评分,以此保证了本发明口语评测结果的准确性。
附图说明
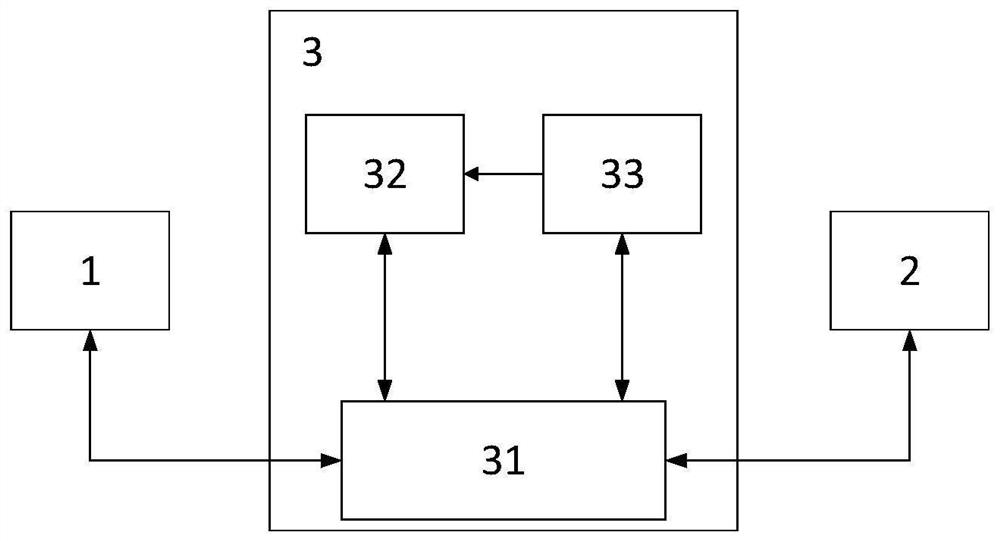
图1为本发明的系统结构示意图;
图2为实施例中教师客户端的工作流程示意图;
图3为实施例中学生客户端的工作流程示意图;
图4为实施例中语音评测模块的工作流程示意图;
图5为通信模块采用C/S架构的示意图;
图6为通信模块采用Serverless架构的示意图;
图7为通信模块采用混合架构的示意图;
图8为C/S架构与Serverless架构的页面加载速度对比示意图;
图9为本发明的方法流程示意图;
图中标记说明:1、教师客户端,2、学生客户端,3、服务器,31、通信模块,32、数据库,33、语音评价模块。
具体实施方式
下面结合附图和具体实施例对本发明进行详细说明。
实施例
如图1所示,一种口语评测系统,包括教师客户端1、学生客户端2以及服务器3,教师客户端1、学生客户端2分别与服务器3相互连接,服务器3内设置有通信模块31、数据库32以及语音评价模块33,教师客户端1和学生客户端2均通过通信模块31与数据库32相互连接,语音评价模块33的输入端通过通信模块31与学生客户端2连接,语音评价模块33的输出端与数据库32连接。
教师客户端1用于教师用户管理学生信息、上传语料数据、上传教师用户信息、上传教学计划信息以及查看所有学生口语分数,如图2所示,教师客户端1主要涉及的功能有教师登录、创建班级、管理班级、添加学生信息、管理学生信息、语料库管理、制定教学计划和查看学生成绩等功能,涉及数据库32中的用户信息数据库,语音语料库以及计划信息数据库,以与学生客户端2的数据进行良好互通,达到高效、省时、省力;
学生客户端2用于学生用户上传学生用户信息、获取语料数据及教学计划信息、上传待测语音以及查看当前用户口语分数,如图3所示,学生客户端2主要涉及到功能有:用户登陆、语言类型的选择、选择测试的类型和等级、试听朗读信息、语音录制与测试、回听录制语音、结果页面展示、查看计划以及查看历史成绩功能,涉及数据库32中的用户信息数据库记忆语音语料库;
服务器3用于存储教师用户信息以及学生用户信息、存储语料数据、对待测语音进行准确度、完整度和流畅度评测、得到对应于学生用户的口语分数,服务器3中的数据库32用于存储教师用户信息及学生用户信息、存储来自教师客户端1的语料数据及教学计划信息、存储与学生用户信息对应的口语分数;
服务器3中的语音评价模块33用于对来自学生客户端2的待测语音进行准确度、完整度和流畅度评测,得到对应的口语分数,语音评价模块33包括依次连接预处理单元、特征提取单元、模式匹配单元和后处理单元,预处理单元与学生客户端2连接,后处理单元与数据库32连接,预处理单元用于对待测语音进行滤波及分帧处理;
特征提取单元用于从预处理后的待测语音信号中提取特征向量;
模式匹配单元用于识别出待测语音对应的语句信息,模式匹配单元内设置有与特征提取单元连接的训练模型,训练模型用于根据待测语音的特征向量,识别输出对应的语句信息,训练模型具体选用隐马尔可夫结合神经网络的模型结构,训练模型包括声学模型和语言模型,声学模型通过对大量语音数据进行训练获得,其输入是语音特征向量,其输出为音素信息,语言模型通过对大量文本信息进行训练获得,其输出为单个字或词相互关联的概率;
后处理单元根据待测语音及其对应的语句信息、语料数据,得到待测语音对应的准确度、完整度和流畅度分数,即为口语分数;
具体的,如图4所示,语音评测模块33对从硬件采集到的语音信号进行处理,在经过去噪、特征提取、声学模型和语言模型的构建、模式匹配等处理过后得到识别出的文字信息以及相关的评测分数,主要包含了:预处理阶段,模型构建阶段以及解码部分,在预处理阶段,主要进行声音信号进行滤波、分帧、可用语音的端点检测以及特征提取,特征提取工作将声音信号从时域转换到频域,为声学模型提供合适的特征向量,声学模型中再根据声学特性计算每一个特征向量在声学特征上的得分;而语言模型则根据语言学相关的理论,计算该声音信号对应可能词组序列的概率;最后根据已有的字典,对词组序列进行解码,得到概率最高的文本信息,再进行拼接和合成,评分部分则结合了预处理和识别文本对应的信息,进行进一步的数据分析,得到准确度、完整度和流畅度的得分。
在实际应用中,服务器3中的通信模块31可以采用两层C/S架构、Serverless架构或混合架构(包括C/S架构和Serverless架构),如图5所示,采用两层C/S架构时,服务器负责数据的管理,客户机负责完成与用户的交互任务,客户机通过局域网与服务器相连,接受用户的请求,并通过网络向服务器提出请求,对数据库进行操作;服务器接受客户机的请求,将数据提交给客户机,客户机将数据进行计算并将结果呈现给用户,服务器还要提供完善安全保护及对数据完整性的处理等操作,并允许多个客户机同时访问服务器,双端CS架构能够在手机端及网页端分别对服务器进行访问,最大化的利用服务器的性能。
如图6所示,采用Serverless架构时,即无服务器架构,不用购买服务器,不用配置虚拟机或者物理机,它使用计算托管的方式,用户在使用的时候不用担心它的安全性,也不用担心可能服务器宕机导致的故障,Serverless架构的运行方式有一个特点,业务逻辑是触发式运行的,云函数在和各个云产品或云服务打通以后,各个产品或服务产生的事件,都能触发业务逻辑的运行,Serverless架构在手机端应用开发完成后只需在手机端进行所有操作,并不需要额外搭建服务器。
如图7所示,采用混合架构时,将C/S架构和Serverless架构进行融合,利用双端互联的特性,进行数据库数据的自动同步,也能够防止其中一种架构在维护时能够无间断的部署系统的运行。
本实施例通过将C/S架构和Serverless架构对应的页面加载速度进行分析对比,如图8所示,Serverless架构的响应速度较C/S架构相比因触发机制的原因有一定的速度差距,Serverless架构的业务逻辑是触发式运行的,这导致了系统在进行数据传输的过程中,必须依照业务逻辑的顺序传输变量,在同样的页面加载容量的前提下,数据库交互程度越高,架构的延时越明显,C/S架构较Serverless架构,主要页面加载速度快了41.6%,整体响应速度快了20%,因此建议使用以C/S架构为主、Serverless架构作为辅助手段的混合架构,能够在最大限度保证性能的同时拥有应急反应机制。
将上述系统应用于实际,其具体的口语评测过程如图9所示,包括以下步骤:
S1、教师客户端获取教师用户信息、学生名单、教学计划信息以及语料数据,并将获取的信息数据传输给服务器进行存储;
S2、学生客户端获取学生用户信息,并传输给服务器进行存储;
S3、学生客户端从服务器获取语料数据,并将获取的语料数据输出给学生用户,其中,语料数据包括测试语句信息及对应的语音数据;
S4、学生客户端接收来自学生用户的待测语音,并传输给服务器;
S5、服务器对待测语音进行准确度、完整度及流畅度评测,得到口语分数,并将该口语分数与学生用户信息对应进行存储、将该口语分数输出给学生客户端,在进行口语评测时,具体过程为:
S51、对待测语音进行预处理,具体是采用滤波方法对待测语音数字信号进行去噪处理,并对待测语音数字信号进行端点检测、音段切分,以得到有效语音的起始点及结束点;
S52、从预处理后的有效语音中提取能够表征语音特性的特征向量;
S53、将特征向量输入声学模型,得到对应的音素串,基于动态时间规整法,找到每个音素的起止时间及各音素之间的分界点,通过字典匹配的方式,得到各音素对应的文本信息;
S54、将各音素对应的文本信息输入语言模型,得到待测语音对应概率最高的语句信息;
S55、将待测语音对应概率最高的语句信息与测试语句信息进行对比,生成准确度评分;
统计待测语音的发音间隔、发音起始点及结束点,生成完整度评分以及流畅度评分;
S6、教师客户端从服务器获取学生名单中已有学生对应的口语分数,以便教师用户查看其学生的口语学习成果。
本实施例中,在构建学生客户端时,运用服务器和云开发两种部署方式完成相同的功能,考虑手机版本兼容性的问题,运用小程序开发者工具开发小程序的方式,快捷有效地将手机端应用进行快速部署,利用到了云开发所涉及的各种技术,包含云存储、云函数、云数据库等完成了一系列功能,采用数据传输,远程的语音播放,远程数据库访问、读取,文件传输,JSON数据串解析,语音识别,语音测评,音素判别等技术,实现了语音评测模型的应用,系统的语音评测反馈速度达到了实时同步,用户拥有良好的使用体验;
在构建教师客户端时,采用部署在服务器的PHP网页架构,辅以数据库进行数据管理和操作,使用域名解析技术及https协议申请的CA证书部署,确保链接的安全性和适用性,网页部署在PHP为基础的服务器上,确保执行的效率性以及代码维护的简易性,教师主要提供了教学所需的文本信息及音频文件进行上传以及发布,学生能够在程序接受相应练习,有效地进行交互;
考虑教师学生双端访问数据库,使用服务器架设数据库及PHP语言设计访问端口,以程序向端口发送报文的形式,将结果以res字段进行值的返回,采集数据的同时,对数据进行重构,json文件的解析和再拼接,使得页面需求的参数能够正常显示和访问;
为保证口语评测的全面准确性,主要依靠服务器内的语音评测模块对待测语音进行评测:
1)首先输入学习者的语音,采集清晰且完整的语音信息,将从硬件采集到的语音模拟信号转化为数字信号,将语音存为22kHz采样率的mp3格式文件。
2)对采集到的文件进行预处理,将采集到的数字信号去噪,进行端点检测、音段切分,检测有效语音的起始点。
3)特征提取:通过信息预测分析、倒谱分析等信号处理方法从预处理后有效的语音中提取能够表征语音特性的特征参数。
4)训练模型,声学模型(AM)通过对语音数据进行训练获得,输入是特征向量,输出为音素信息,语言模型(LM)通过对大量文本信息进行训练,得到单个字或者词相互关联的概率。
5)模式匹配:
声学模型:得到语音特征到音素的映射,通过‘字典’(中文中就是拼音与汉字的对应,英文中就是音标与单词的对应),根据声学模型识别出来的音素,来找到对应的汉字(词)或者单词,用来在声学模型和语言模型建立桥梁,将两者联系起来,即得出音素对应的文本信息。
语言模型:利用上下文中相邻词间的搭配信息,把声学模型转化出的文本信息转换成句子时,可以计算出具有最大概率的句子,从而实现文字到句子的自动转换,无需用户手动选择,避开了许多文字对应一个相同的发音的重码问题,得到待测语音对应的最高概率识别出的句子信息。
6)后处理:得到最佳的(最高概率)识别结果过后,将用户待测语音生成的句子与标准句子(即测试语料数据)进行对比生成准确度评分,利用采集到的待测语音音频信号,统计发音间隔、发音起始点与结束点,以生成完整度评分和流畅度评分。
7)最后将结果封装,生成json字节流,输出结果。
综上所述,本发明设计了学生教师双系统流程,能够满足学生端双语页面及双语内容需求实现,将语音模块和评价模块融合成语音评测模块,既能对语音进行识别,同时能对语音进行评测。
本发明设计了软件架构方案,以根据用户需求选择适宜的方案,利用双端互联的特性,进行数据库数据的自动同步,也能够防止其中一种架构在维护时能够无间断的部署系统的运行,满足系统维护及检修的需要,对于响应速度进行了分析研究,得出根据用户实际需求选择不同架构的结论。
本发明提出了一种语音评测模块,结合了语音识别及参数评价功能,使流程得以简化,将模块界定,能够获得准确全面的口语评测结果。
- 一种口语评测系统及其方法
- 一种口语对话策略生成方法及口语对话方法