基于半监督学习的主动显著性目标检测方法
文献发布时间:2023-06-19 10:27:30
技术领域
本发明属于计算机视觉与机器学习领域,特别涉及一种显著性目标检测方法,可在训练集标签数据不足的情况下利用全卷积神经网络生成精确完整的显著性图。
背景技术
显著性目标检测旨在从输入图像上识别出最引人注目的对象。在显著性检测算法当中,PiCANet学习每个像素的信息性上下文特征,然后将其嵌入到UNet结构中,整合全局上下文信息和多尺度的局部上下文信息来提升显著性检测性能。
Amulet方法首先将多级特征整合到多个分辨率下,然后在每一个分辨率下进一步进行特征整合得到显著性预测,再进行显著性融合得到最终的显著性图像。
为了更好的多级特征,Zhang等人提出了PAGRNet与通道注意力机制与空间注意力机制,利用多级递归反馈方案,选择性地集成多层特征的上下文信息,逐步增强显著性预测图。在深度卷积网络中,图像经过主干特征提取网络得到一系列不同级别的感知特征。
针对显著性预测的细化方面,Qin等人设计的BASNet网络对网络前端的UNet结构得到的显著性预测利用了残差网络进行优化。
但显著性模型训练往往需要用到大量的像素级标注图像,这些图像需要相当高的标注成本,目前半监督方法是一种减少标注成本较为流行的方法。
Yan等人提出了FGPLG方法,利用视频帧之间的关联,借用部分帧的标注生成伪标签,并用伪标签进行半监督训练的视频显著性算法。
针对数据与设备的多样性问题,Wang等人提出了SaliencyGAN方法,用以解决物联网系统的显著性检测难点,基于具有部分共享参数的新型串联生成对抗网络(GAN)框架,使用只有30%的标注数据的数据集进行训练实现了与全监督训练相近效果。
只使用半监督方法产生的问题是标注数选择据难以尽可能选择对训练有帮助的数据,往往是随机挑选,而主动学习方法则在很大程度上解决了这一问题,能够最大程度上选择对训练最有帮助的数据。
Sener等人提出了核心集选择(Coreset selection)算法,选择出一个子集能够和整个数据集取得接近的性能。提出主动学习问题的关键是核心集误差,即选择出的标注数据得到的模型结果和完整数据训练的模型结果之差,并将降低核心集误差转化为通过贪心算法获得一个二值最优问题的解。
为了更有效地选择对训练最有帮助的图像,Yang等人提出基于主动学习的医学图像分割框架Suggestive annotation方法,将主动学习与全卷积神经网络结合,在2015MICCAI Gland Challenge数据集上使用50%的数据实现了最好的效果。该算法提出了新的网络结构以提高模型的训练速度,并保留了与全卷积网络相似通道数以保证不同尺度的特征图相结合。算法利用自主法(Bootstrapping)计算不确定性,将网络输出的结果当作特征计算与平均输出的相似性,并作为选择最具有代表性的图像作为主动学习策略。
基于深度学习的显著性检测算法作为一种数据驱动型的算法,需要大量的以像素注释形式的训练数据,指示出像素是否属于显著性目标对象类别,这些对象类别通常是由具有密集用户交互的工具手动绘制或描绘的。训练数据采集的大量标注成本阻碍了基于深度学习的显著性检测算法的发展,数据标注成为此领域急需解决的问题。在标签数据量不足时,需要挖掘数据对模型的贡献差异,对数据对于目标任务网络的优化效果进行评估,传统主动学习算法旨在制定选择函数从大量的无标签数据进行数据选择。
目前基于主动学习的目标检测算法多利用传统的选择策略,对获得的输出结果进行价值评估,而输出均为通过训练卷积神经网络获得的,导致选择函数不变,网络输出在变化,因此存在时效性误差。
发明内容
为了克服现有技术的不足,本发明提供一种基于半监督学习的主动显著性目标检测方法,结合现有的主动学习和对抗学习算法,在仅有少量的标签数据的情景下获得与全监督学习算法相近的性能结果。
本发明解决其技术问题所采用的技术方案包括以下步骤:
(1)设计变分自编码器、判决器网络和显著性目标检测网络;
(2)利用无标签数据构成的训练数据集对变分自编码器进行图像重建任务训练,通过卷积操作将图像编码之后得到一个低维的隐空间向量z,并对图像的特征进行分布拟合,然后利用隐空间特征向量通过由反卷积操作和上采样操作组成的解码器部分中对图像进行重建;
(3)在获得有标签数据集和无标签数据集的情况下,对显著性目标检测网络、判决器网络进行联合训练,其中,显著性目标检测网络以RGB图像作为输入,生成像素级的单通道显著性图;判决器网络以显著性图和RGB图像的级联为输入,生成像素级单通道置信图,该置信度图表明网络判断该显著性图为真值结果的概率;所述的显著性图带有人为标定的真值标签或根据显著性目标检测网络的预测结果确定;
(4)对所有的无标签数据得到的显著性预测进行置信度估计,计算置信度图各点值的平均值作为置信度,并根据置信度降序选择若干个数据组成候选数据子集;
(5)根据预训练好的基于变分自编码器的图像重建网络,将有标签数据集和候选数据子集的隐空间特征向量分别定义为z
(6)重复步骤(3)~(5),直至含标签数据量达到预先设定的数字。
所述的变分自编码器网络的隐空间向量维度设置在100-1000范围内。
所述的判决器网络设计为直连的全卷积神经网络,采用直连5个核大小为3的卷积层后做上采样。
所述的显著性目标检测网络使用编码器-解码器结构或U-Net结构。
所述的步骤(3)在初始情况下,从无标签数据集中随机选择若干数据,并给予在该任务中对应的显著性图标签组成有标签数据集。
所述的步骤(3)对于判决器网络的训练,根据网络输入进行监督信号的生成,即如果输入的显著性图为显著性真值标签,设定其真值为与输出同尺寸的全1矩阵,若输入的显著性图为预测结果,其真值设定为全0矩阵。
本发明的有益效果是:提出利用基于深度学习的选择策略,保持任务网络和选择策略网络同步训练的方式,保持了视觉检测任务和主动学习策略的算法一致性。此外,主动学习在每一轮网络训练结束后进行评估,并选择当下最具代表性和信息性的数据样本加入任务网络训练,获得最大化的利用效率和性能提升。
对本发明提出的显著性目标检测算法进行性能验证,利用部分含标签数据和大量无标签数据得到的显著性检测模型性能,采用平均绝对误差(MAE)、F度量值(F-measure)、E度量值(E-measure)、S度量值(S-measure)等多个显著性目标检测领域主流评价准则同其他主流的全监督显著性目标检测算法对比性能。在算法实现过程中使用DUTS训练集进行网络训练。该数据集具有10553个图像和对应的显著性真值标签。模型将完整的图像数据作为无标签数据池,在初始化阶段,从中随机选择300个图像并给定它们的显著性标签组成含标签数据池。此后,根据本发明提出的半监督学习框架进行网络训练。在主动学习算法机制中,在网络训练到一定阶段后,每完成一轮训练,首先根据判决器网络得到的置信度估计,从无标签数据池中选择N=300个图像作为候选数据子集,之后,利用预训练好的图像重建模型,对含标签数据池和候选数据子集中的数据特征进行相似性计算,选择M=50个样本,给予显著性标签,加入到含标签数据池中进行训练。重复此过程,直至含标签数据池中的图像数量达到1400张(占总数据量的13%)。此后固定两个数据集的数据量,训练至显著性目标检测网络收敛。
虽然本发明只使用了其他全监督学习算法13%的标签数据量,仍然能和部分算法保持接近的性能,例如AFNet和MSNet,也能够在多个测试集上优于相对提出时间靠前的算法,如DGRL和PiCANet。
附图说明
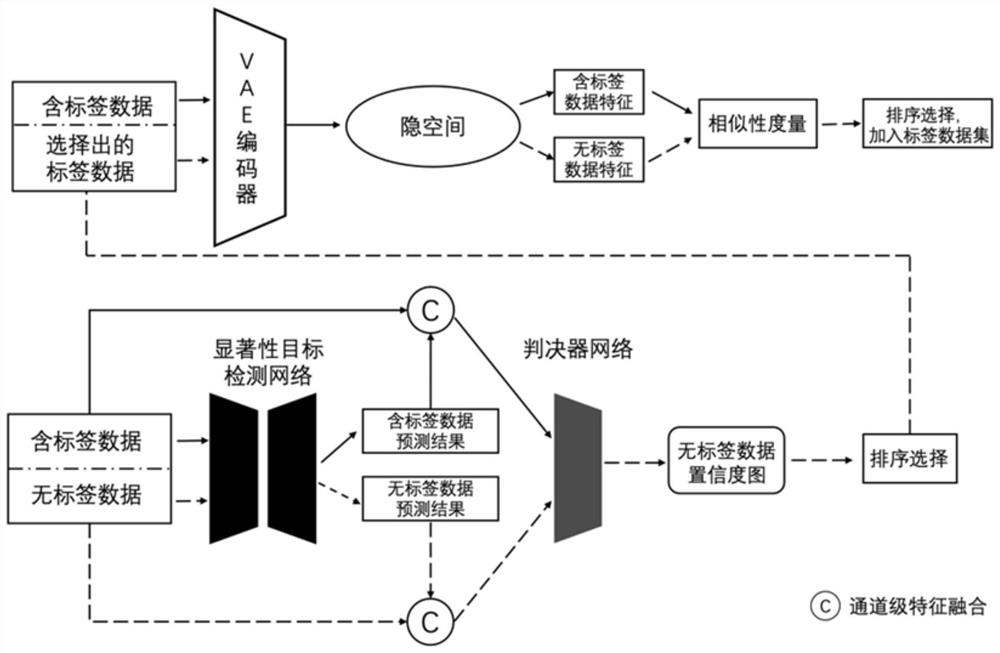
图1是本发明算法总体框架图;
图2是本发明设计的显著性目标检测网络框架图;
图3是本发明与主流全监督显著性目标检测算法结果可视化对比图。
具体实施方式
下面结合附图和实施例对本发明进一步说明,本发明包括但不仅限于下述实施例。
针对标签数据不足的问题,本发明设计了一种基于半监督学习的主动显著性目标检测框架,同时引入判决器网络和变分自编码器网络,通过以上网络的互相作用,从大量的无标签数据中选择兼具信息性和代表性的样本数据并给予标签来训练模型。此外,本发明设计了一种基于对抗学习的网络框架来实现对有标签数据和无标签数据的高效利用,在多个主流的显著性目标检测基准测试集上获得了与目前最领先的全监督显著性目标检测算法相接近的性能水平。
本发明提出了一种半监督学习的主动显著性目标检测网络,给定大量无标签的图像数据,首先,通过设计判决器网络来对样本在显著性目标检测的结果进行不确定性验证,其次,训练了一个变分自动编码器(VAE)进行图像重建任务,通过比较无标签数据在其隐空间中的特征向量之间的相似性,从中选择最具代表性的数据并给予完整的显著性标注。重复该过程直到获得预先设定好数量的含标签数据,在此过程中利用不同类型的数据分别对显著性目标检测网络进行训练优化。
本发明提出的半监督学习框架模型主要包含:
1)显著性目标检测网络(编码器-解码器结构)
本发明在ResNet50网络的基础上构建了显著性编码器,并引入额外的自顶向下连接,有效融合高层语义和浅层结构信息对特征进行解码,实现精确的显著性目标检测任务。该编码器-解码器结构采用有标签数据池和无标签数据池联合训练的方法,通过设计的判决器网络的输出对无标签数据进行处理获得伪标签。
2)判决器网络
本发明设计了一个全卷积神经网络来产生与输入图像具有相同空间尺寸的置信图(判决器网络的直接输出是原图下采样的16倍,使用最近邻插值将其上采样到与输入图像相同的空间分辨率)。判决器网络包含5个核大小为3的卷积层,实现了对含标签数据的对抗性学习,并获得了网络对未标注池预测的置信度估计。
在本发明提出的框架内,这两个网络是根据彼此的状态逐步优化。
在本发明中,主要需设计三个网络:
1)变分自编码器网络,该网络用于自监督图像重建任务。在本发明,图像重建任务只作为辅助任务用来训练设计的变分自编码器网络,以便后续利用变分自编码器网络中的隐空间特征向量,因此隐空间向量维度可在100-1000范围内自由选择进行设置;
2)判决器网络,该网络输出与输入图像具有相同空间尺寸的单通道置信图,实现对含标签数据的对抗性学习,并获得网络对无标签数据预测的置信度估计。该网络可设计为直连的全卷积神经网络,结构无须复杂,例如直连5个核大小为3的卷积层后做上采样。
3)显著性目标检测网络,该网络输出与输入图像具有相同空间尺寸的单通道显著性图,在网络设计中,可使用目前主流的编码器-解码器结构或U-Net结构,引入注意力机制模块和边缘检测模块,同时利用编码和解码阶段不同层级的特征做特征融合来提升精度。
本发明主要技术步骤包括:
(1)利用大量的无标签数据训练设计的变分自编码器网络实现图像重建任务。变分自编码器可用于对先验数据分布进行建模,整体由编码器和解码器组成。相比较传统的自动编码器,编码器将数据分布的高级特征映射到数据的低级表征。解码器吸收数据的低级表征,然后输出同样数据的高级表征。变分自编码器结构跟自动编码器是类似的,也由编码器和解码器构成。它将图像编码之后得到一个隐空间向量,将图像(整个训练数据集)映射到低维的隐空间特征z,并对整个训练数据集的特征进行分布拟合,例如高斯分布。然后利用隐空间特征向量z在解码器网络中对图像进行重建。该任务可通过自监督学习的方式进行,不需要除图像数据外的标签。
(2)在获得有标签数据集和无标签数据集(分别称之为有标签数据池和无标签数据池)的情况下(初始情况下,从无标签数据集中随机选择微量数据,例如整体数据的1~3%,并给予在该任务中对应的显著性图标签组成有标签数据池,对设计的显著性目标检测网络、判决器网络进行联合训练。其中,显著性目标检测网络以RGB图像作为输入,生成像素级的单通道显著性图;判决器网络以显著性图(人为标定的真值标签或网络的预测结果)和RGB图像的级联为输入,生成像素级单通道置信图,该置信度图表明网络判断该显著性图为真值结果的概率。
对于判决器网络的训练,根据网络输入进行监督信号的生成。即如果输入的显著性图为显著性真值标签,设定其真值为与输出同尺寸的全1矩阵,反之,若输入的显著性图为预测结果,其真值设定为全0矩阵。因此,不需要额外的标注操作,即可获得完整的判决器标签。由于判决器网络同时需要数据的显著性真值和预测结果,只使用含标签数据对判决器网络进行训练。
(3)对于无标签数据中整体置信度越低的数据,即判决器对其在显著性目标检测网络得到的显著性图器最不确定其类别的样本,在经过专家标注后能够对网络训练提供大量丰富的信息,能够有效提升网络对其他数据的预测精度。根据主动学习算法中的信息性准则,对该部分无标签进行选择并组成待选数据子集参与下节设计的多样性选择算法中,可以对所有的无标签数据得到的显著性预测进行置信度估计,计算该置信度图的平均值并进行降序排序,从中选择前N个(N为人自由设定)数据组成候选数据子集。
(4)根据上述步骤可获得候选数据子集,代表了显著性检测网络最不确定的数据,从而为网络训练提升最有效的信息。此外模型仍需考虑所选数据的特征分布性。因此,根据预训练好的基于变分自编码器的图像重建网络,可以将有标签数据池和候选数据子集的隐空间特征向量分别定义为z
(5)重复步骤(2)~(4),直至含标签数据量达到预先设定的数字。
通过在多个显著性检测数据集上的实验验证,本发明设计的算法可以给定低比例的标签数据的情况下,得到接近完整数据集的性能结果,从而大大降低数据的标注成本。
本发明的实施例按照如下步骤进行:
(1)对完整的无标签数据集,预先通过变分自动编码器设计了一个无监督的图像重建网络,该变分自动编码器网络的编码器部分由五个卷积层和一个完全连接层组成。卷积层具有相同的核大小和步长,分别为4和2。每个卷积层的信道尺寸分别为M、2×M、4×M、8×M、8×M,其中M=32。最终的全连通层将特征映射到K=800维的隐空间特征向量z上,定义为图像特征描述子。变分自动编码器网络的解码器部分由6个卷积层组成,将隐变量z映射到与输入图像x空间大小相同的三维特征映射图上,核大小和步长分别为3和1,并采用双线性上采样方法逐步放大生成的特征映射图。
表1图像重建模型网络结构参数
(2)针对显著性目标检测任务特性,构建显著性目标检测网络进行训练。
本发明所设计的显著性目标检测网络包含两个模块,即显著性图像生成模块和辅助边缘检测模块。显著性图像生成模块基于编码器-解码器结构所设计,学习自然图像到显著性图像的映射关系,具体网络结构如图2所示。
该网络的编码器采用ResNet50网络,得到网络不同阶段的输出特征。解码器首先将每层输出特征输入到扩张空间金字塔池化模块中,该模块通过设置扩张率分别为6、12、18、24的扩张卷积以捕获多尺度信息。然后将所得特征分别输出入到双重注意力机制模块中,该模块包含通道注意力模块和位置注意力模块,将二者所得输出特征进行元素级相加,即得到该层所对应的特征输出。由于各层输出特征分辨率不同,因此需要进行不同尺度上采样得到相同分辨率特征,并在通道维度上进行特征融合。最后,再次利用扩张空间金字塔池化模块进行特征提取,利用卷积操作得到单通道显著性图像。
针对显著性目标边界,模型设计辅助边缘检测模块对其进行细化。该辅助模块与显著性生成网络共享ResNet50编码器。在解码器中,该模块从解码器输出中选择对边缘和纹理特征敏感的低层特征,与上述显著性图像生成模块进行相同操作,得到最终边缘检测结果。
对于含标签数据,算法采用结构误差损失函数对网络进行训练:
其中,ω为权重参数。P
L_iou=1-(ω*inter+1)/(ω*union-ω*inter+1)
其中,inter=P
对于有标签数据,对显著性图像真值进行拉普拉斯算子边缘检测,得到显著性边缘真值,以对边缘检测模块的输出进行监督。
其中E
对于无标签数据,由于显著性真值标签不存在,需要利用判决器网络进行伪标签生成(初始情况下,从无标签数据集中随机选择微量数据和其标签组成有标签数据池)。根据来自判决器网络的预测选择精确预测的像素级子集,即“置信图引导显著性学习”。训练判决器将标注池的显著性图像真值映射到所有一个特征映射,并将网络预测映射到所有零特征映射。观察到背景和前景区域内相对一致的预测,而沿着目标边缘的不确定预测。
将无标签数据在显著性目标检测网络得到的预测值和原输入图像进行在通道维度上进行结合,输入到下述的判决器网络中,得到归一化的单通道置信度,该置信度图代表了网络对该预测结果的确定性估计,在每个像素的置信度越接近于1,代表网络认为该位置像素的预测更接近于真值标签,也更加可信,反之,置信度值越低,越接近于0,代表网络认为该位置的预测为预测结果,可信度较低。据此设置一个大小为0.5的阈值,对置信度图进行二值化后和显著性预测结果相乘,之后通过OpenCV的自动二值化函数得到局部伪标签,利用该伪标签对无标签数据的显著性预测结果进行监督。其具体操作如下:
其中,Mask为无标签数据的显著性预测P
(3)利用判决器来比较显著性真值和显著性预测的高阶相似性。同时为无标签的数据池生成置信图,并据此对其进行处理以作为部分伪标签。
判决器网络以显著性图(真值或预测结果)和RGB图像的级联为输入,生成单通道置信图。
表2判决器网络结构参数
对于判决器网络的训练,根据网络输入进行监督信号的生成。即如果输入的显著性图为显著性真值标签,设定其真值为与输出同尺寸的全1矩阵,反之,若输入的显著性图为预测结果,其真值设定为全0矩阵。因此不需要额外的标注操作,即可获得完整的判决器标签。由于判决器网络同时需要数据的显著性真值和预测结果,只使用含标签数据对判决器网络进行训练,其损失函数定义如下:
其中,L
引入对抗学习的策略利用判决器输出对显著性目标检测网络进行监督。即为了迷惑显著性目标检测网络,对含标签数据的显著性预测增加额外的对抗性损失函数,具体做法是将全1矩阵作为该显著性预测在判决器网络输出的监督信号。需要额外注意的是,该对抗性损失函数只参与显著性目标检测网络的训练。其定义如下:
对于无标签数据,由于不存在显著性真值,当模型训练轮次过半后,利用边缘检测模块的输出对显著性目标检测预测结果自监督。
其中,E
对于无标签数据,根据置信度引导的局部伪标签进行监督,其特征信息仍然具有一定的不稳定性。对于其中整体置信度非常低的数据,即判决器网络对该数据的显著性预测具有极强的不确定性,也因此该部分数据对网络训练可以提供大量的信息。根据主动学习算法中的信息性准则,对该部分无标签进行选择并组成待选数据子集参与步骤四设计的多样性准则选择算法中。根据本发明提出的半监督学习框架,可以对所有的无标签数据得到的显著性预测进行置信度估计,计算该置信度度的平均值并进行降序排序,根据任务不同预先按设定好的数据量从中选择数据组成候选数据子集。
(4)在候选数据子集中选择需要标注的数据
在步骤(1)中通过变分自动编码器预训练好了图像重建网络,可用作特征表示网络,从候选数据子集中选择代表性样本进行标注并加入到含标签数据池中。
利用判决器网络对无标签数据的置信度进行排序,选择置信度高的数据构成待选数据集。此外,设计基于VAE的图像重建网络,将图像(整个训练数据集)映射到低维的隐空间特征z,然后利用隐空间特征z对图像进行重构。该重建网络利用自监督学习策略进行训练,即重建图像和原图输入进行误差计算。利用训练好的图像重建网络,可以将含标签数据池和候选数据子集的隐空间特征向量分别定义为z
L=cos(z_l,z_u)=(z_l·z_u)/(||z_l||×z_u||)
根据该值作为度量选择与当前标注池样本的相似性大的数据赋予显著性标签加入到含标签数据池。最后,将所选样本作为代表性样本加入当前标注数据池。
(5)重复步骤(2)~(4),直至含标签数据量达到预先设定的数字。
- 基于半监督学习的主动显著性目标检测方法
- 基于目标显著性的卫星图像对地面弱小运动目标检测方法