一种日志文件快速解析方法及装置
文献发布时间:2023-06-19 10:29:05
技术领域
本发明涉及日志解析技术领域,尤其涉及一种日志文件快速解析方法、装置及计算机存储介质。
背景技术
各行业的各类设备、系统中都会产生大量日志文件。日志文件的解析是可以为各类设备、系统提供有价值的、可靠的各类指标参数,用于支撑各类设备、系统的运行、改进和发展。例如,银行、企业、政府单位都有很多防火墙设备,每个防火墙设备在运作过程中产生的日志数据都是海量,这些日志以天为单位或者类别为单位存储形成日志文件;基于这些日志文件进行大数据分析,可以提供多维度、不同颗粒度的安全防护数据,为网络安全提供重量级的数据支撑。另外,传统制造业、电商平台、金融、物流、航空、社交平台使用的业务系统或生产管理系统,在运作过程中会产生大量的日志数据,形成日志文件;这些日志文件在大数据分析的场景下,可以挖掘出有价值的数据,产生可靠的、可利用参考的各种指数和报表,用于支撑后期业务快速发展;还可以基于日志解析找到业务发展的瓶颈、限制、增长空间等有用的数据指数。
目前,日志解析可以采用正则解析、使用xml配置实现日志解析等方案。这些方案大多不够完善,在进行较大日志文件解析时,尤其是超大日志文件(日志文件大小超过10G、日志文件行数大于或等于200万)解析时,解析速度过慢,对内存和处理器的消耗较大。而且,解析时会长久占用内存不释放,CPU使用率居高不下,导致其它软件运行效率低下,操作系统响应延迟,影响客户操作体验;在日志文件稍大一点的情况下可能出现卡死、丢失数据的情况,对于超大日志文件解析时卡死的情况就更加严重。
发明内容
有鉴于此,有必要提供一种日志文件快速解析方法及装置,用以解决较大日志文件解析效率低、对内存和处理器的消耗大、容易卡死的问题。
本发明提供一种日志文件快速解析方法,应用于分布式系统,包括以下步骤:
获取并存储正则解析对象集合,获取待解析的日志文件;
将所述日志文件切割为多个子文件,读取并加载各所述子文件;
将读取加载的子文件并行分发至多个处理单元;
各处理单元分别在所述正则解析对象集合中匹配相应子文件的正则解析对象,并进行相应子文件的解析;
对各处理单元的解析结果进行入库操作。
进一步的,还包括:
完成一个所述日志文件的所有子文件的解析处理后,休眠设定时间,再进行下一个日志文件的解析处理。
进一步的,获取并存储正则解析对象集合,具体为:
设置专用存储空间,通过activeMq消息队列接收java组件发送的正则解析对象集合,并存储至所述专用存储空间。
进一步的,将所述日志文件切割为多个子文件,读取并加载各所述子文件之前,还包括:
判断所述日志文件是否为压缩文件,如果是,则对所述日志文件进行解压缩,然后将解压缩后的日志文件移动至解析临时目录中,否则直接将所述日志文件移动至解析临时目录中。
进一步的,将所述日志文件切割为多个子文件,读取并加载各所述子文件,具体为:
判断所述日志文件的总行数是否大于设定行数,如果是,则将所述日志文件切割为多个设定行数的子文件,否则不进行切割;
获取各所述子文件的路径地址;
基于所述路径地址并行或串行读取各所述子文件,并加载至内存缓冲区。
进一步的,根据分布式系统的配置参数设置所述设定行数以及内存缓冲区的大小。
进一步的,将读取加载的子文件并行分发至多个处理单元,还包括:
各所述处理单元将相应子文件中日志数据分发至同级处理单元或下一级处理单元。
进一步的,各处理单元分别在所述正则解析对象集合中匹配相应子文件的正则解析对象,并进行相应子文件的解析,具体为:
各处理单元初步解析相应子文件,获取日志头部ip,通过所述日志头部ip在所述正则解析对象集合中匹配相应的正则解析对象;
各处理单元根据匹配得到的正则解析对象对相应子文件进行解析字段匹配,如果匹配成功,则提取相应子文件的解析字段数据;
结合各处理单元匹配得到的解析字段数据,形成解析结果。
本发明还提供一种日志文件快速解析装置,包括处理器以及存储器,所述存储器上存储有计算机程序,所述计算机程序被所述处理器执行时,实现所述日志文件快速解析方法。
本发明还提供一种计算机存储介质,其上存储有计算机程序,所述计算机该程序被处理器执行时,实现所述日志文件快速解析方法。
有益效果:本发明在对日志文件进行解析之前,先对日志文件进行切割,然后采用多个处理单元分别对切割后的子文件进行解析处理。通过分割日志文件提高日志解析速度,同时,使得日志解析过程即使在低CPU和低内存的环境中也可以运行,避免系统因日志文件的解析造成卡死、数据丢失的问题。同时,各处理单元在进行日志解析时,其采用的正则解析对象是在正则解析对象集合中实时匹配得到的,而正则解析对象集合并不是在分布式系统中配置的,而是通过分布式系统以外的其它组件/系统获取配置的,这种正则解析与分布式系统解耦合设计使得解析过程具有较高的扩展性,方便后期的业务扩展。
附图说明
图1为本发明提供的日志文件快速解析方法第一实施例的方法流程图;
图2为本发明提供的日志文件快速解析方法第一实施例的正则解析对象集合加载过程示意图;
图3为本发明提供的日志文件快速解析方法第一实施例的具体流程图;
图4为本发明提供的日志文件快速解析方法第一实施例的处理单元数据流转图;
图5为本发明提供的日志文件快速解析方法第一实施例的正则化解析过程示意图;
图6为本发明提供的日志文件快速解析装置第一实施例的模块化结构示意图。
具体实施方式
下面结合附图来具体描述本发明的优选实施例,其中,附图构成本申请一部分,并与本发明的实施例一起用于阐释本发明的原理,并非用于限定本发明的范围。
实施例1
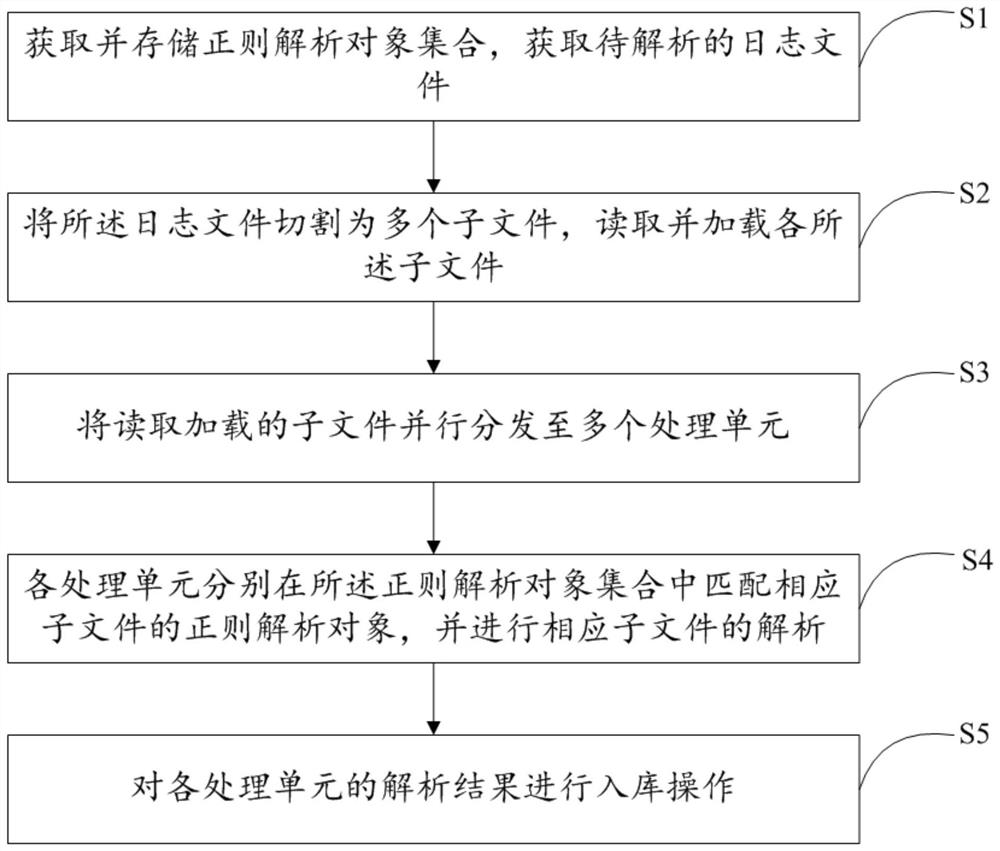
如图1所示,本发明的实施例1提供了日志文件快速解析方法,以下简称本方法,应用于分布式系统,包括以下步骤:
S1、获取并存储正则解析对象集合,获取待解析的日志文件;
S2、将所述日志文件切割为多个子文件,读取并加载各所述子文件;
S3、将读取加载的子文件并行分发至多个处理单元;
S4、各处理单元分别在所述正则解析对象集合中匹配相应子文件的正则解析对象,并进行相应子文件的解析;
S5、对各处理单元的解析结果进行入库操作。
本方法提供的日志文件快速解析方法,部署于分布式系统,本实施例中分布式系统为Apache Storm,Apache Storm是自由开源的分布式实时计算系统,擅长处理海量数据,适用于数据实时处理而非批处理,可以并行地对实时数据执行各种操作、方便快捷的水平扩展,获取更高的解析性能。具体的,S101、首先获取正则解析对象集合,以便后续日志解析时进行正则解析对象的实施配置;S102、其次找出所有需要分析的日志文件;然后将单个超大日志文件切割成小文件,即子文件,获取切割后的子文件的路径地址,并行或串行的对各子文件进行读取加载,用于加载子文件的内存缓冲区大小可以根据分布式系统的配置来设置,以便达到最优性能配置;将读取加载的数据并行的分发给分布式系统的多个分布式处理单元,各处理单元分别获取相应的正则解析对象对相应的子文件进行解析,解析结果集形成待入库的.sgn后缀文件,对.sgn后缀文件进行入库写操作。
本实施例中在对日志文件进行解析之前,先对日志文件进行切割,然后采用多个处理单元分别对切割后的子文件进行解析处理。通过分割日志文件提高日志解析速度,可达15万/s;同时,使得日志解析过程即使在低CPU和低内存的环境中也可以运行,尤其是对于超大日志文件来说,这种处理方式可以大大提高日志解析效率,在低内存、低CPU消耗的情况下,快速准确的读取解析超大日志文件,避免系统因日志文件的解析造成卡死、数据丢失的问题。同时,各处理单元在进行日志解析时,其采用的正则解析对象是在正则解析对象集合中实时匹配得到的,而正则解析对象集合并不是在分布式系统中配置的,而是通过分布式系统以外的其它组件/系统获取配置的,因此正则解析与分布式系统解耦合设计,这种低耦合设计使得解析过程具有较高的扩展性,方便后期的业务扩展。
本实施例提供的日志文件快速解析方法,适用于任意大小的日志文件解析,但是由于其解析效率高,对内存和CPU消耗低,因此尤为适用于超大日志文件。
优选的,还包括:
完成一个所述日志文件的所有子文件的解析处理后,休眠设定时间,再进行下一个日志文件的解析处理。
在日志文件切割以及正则解析对象低耦合配置的基础之上,本实施例还在完成一个完整的日志文件的解析过程后,设置了休眠时间,例如休眠1毫秒,使得内存和CPU得以释放,可以进一步瞬间降低CPU和内存的使用和占用,避免因日志文件的解析长久占用内存不释放、CPU使用率居高不下,导致其它软件运行效率低下,操作系统影响延迟,影响客户操作体验。尤其是对于超大日志文件来说,本方法可以无损、低CPU使用率、低内存消耗、快速地读取解析超大日志文件数据,并且轻量级、低耦合快速适配更多的日志格式。
优选的,获取并存储正则解析对象集合,具体为:
设置专用存储空间,通过activeMq消息队列接收java组件发送的正则解析对象集合,并存储至所述专用存储空间。
具体的,如图2所示,本实施例中正则解析对象集合在java组件中进行配置,java组件是与storm平级的一个组件,是为了实现日志解析而专门设置的一个功能项目组件,为了解耦合设计和方便客户操作,我们把正则配置文件与厂商日志格式的关联绑定关系放在了java组件中实现,可以把正则配置解析文件的工作设置任何java项目的组件中实现。本实施例中实现正则解析配置文件与厂商日志格式的关联绑定的java组件为risk组件,如图2所示,risk组件进行正则解析对象集合的过程具体为:risk组件中映射关系设置单元用于设置设备ip(设备ip用于描述不同日志格式)与正则配置解析文件之间的映射关系,实现设备ip与正则配置解析文件的绑定;risk组件中正则解析对象集合加载单元用于加载所有正则配置解析文件并且将其转换成正则解析对象集合;本实施例中正则解析对象集合为,正则解析对象hash集合,便于后续解析时采用哈希匹配的方式进行正则解析对象的匹配。分布式系统在进行日志文件解析时,通过activeMq消息队列接收java组件发送的正则表达式解析对象集合,分布式系统中有一个专用存储空间用来存储正则解析对象集合,供后续的日志处理单元解析日志时直接使用。
本实施例这种低耦合的结构设置,使得日志解析具有高效率、高扩展性,非常适合对接新的业务场景和产品,可以快速适配不同的日志格式,使用便捷。
获取待解析的日志文件,具体为:
获取所有日志文件的路径地址,通过文件名称对日志文件进行过滤,筛选出待分析的日志文件。
优选的,将所述日志文件切割为多个子文件,读取并加载各所述子文件之前,还包括:
判断所述日志文件是否为压缩文件,如果是,则对所述日志文件进行解压缩,然后将解压缩后的日志文件移动至解析临时目录中,否则直接将所述日志文件移动至解析临时目录中。
在获取到日志文件后,对日志文件进行一些预处理,即解压缩、文件移动等。
优选的,将所述日志文件切割为多个子文件,读取并加载各所述子文件,具体为:
判断所述日志文件的总行数是否大于设定行数,如果是,则将所述日志文件切割为多个设定行数的子文件,否则不进行切割;
获取各所述子文件的路径地址;
基于所述路径地址并行或串行读取各所述子文件,并加载至内存缓冲区。
本实施例中,首先判断日志文件是否大于50万行,如果大于,则将日志文件切割为多个行数为50万行的子文件;然后获取切割后的子文件的路径地址,并行或串行的进行子文件读取加载。
具体的,如图3所示,本方法的具体流程为:S101、从risk组件中获取并存储正则解析对象集合;S102、获取待分析的日志文件;S201、在切割日志文件之前,判断日志是否为压缩文件,如果是,则转步骤S202,否则转步骤S203;S202、对压缩文件进行解压缩;S203、移动日志文件至临时目录中;S204、判断日志文件是否大于设定行数,如果是,则转步骤S205,否则转步骤S206;S205、对日志文件进行切割;S206、加载并读取日志文件;S3、将加载的子文件放入队列,分发至各处理单元;S4、各处理单元进行子文件解析;S501、基于解析结果形成.sgn文件;S502、对.sgn文件进行入库。
优选的,根据分布式系统的配置参数设置所述设定行数以及内存缓冲区的大小。
切割的子文件的大小(即设定行数)以及加载子文件的内存缓冲区大小可以根据分布式系统配置来设置,以便达到最优性能配置。具体的,分布式系统的配置越高,说明其计算处理能力越强,因此设定行数可以设置得越大,内存缓冲区也可以相应的设置得越大。
优选的,将读取加载的子文件并行分发至多个处理单元,还包括:
各所述处理单元将相应子文件中日志数据分发至同级处理单元或下一级处理单元。
具体的,如图4所示,分布式系统中,各处理单元之间也可以进行数据(data)交换,形成数据流(data stream),因此各处理单元在进行日志解析时,如果存在处理时间过长或者日志文件分配不均的情况,可以将处理不了的子文件发送给同级别或下一级别的处理单元进行处理,从而进一步提高日志解析效率,图4中细实线箭头表示同级别处理单元之间的数据流,粗实线箭头表示上下级处理单元之间的数据流。
优选的,各处理单元分别在所述正则解析对象集合中匹配相应子文件的正则解析对象,并进行相应子文件的解析,具体为:
各处理单元初步解析相应子文件,获取日志头部ip,通过所述日志头部ip在所述正则解析对象集合中匹配相应的正则解析对象;
各处理单元根据匹配得到的正则解析对象对相应子文件进行解析字段匹配,如果匹配成功,则提取相应子文件的解析字段数据;
结合各处理单元匹配得到的解析字段数据,形成解析结果。
具体的,如图5所示,本实施例在进行正则解析对象匹配时:S401、首先获取子文件及其日志头部ip;S402、通过头部ip获取子文件的日志来源,进而在正则解析对象集合中匹配与子文件的日志头部ip相对应的正则对象集合,如果匹配成功,则转步骤S404,否则转步骤S403;S403、丢弃当前子文件,记录异常日志;S404、对子文件与相应正则解析对象集合中的正则对象进行循环匹配,如果匹配成功,则转步骤S405,否则转步骤S403;S405、提取匹配成功的正则对象,返回所匹配的解析字段数据;S406、当前子文件解析完毕后,转下一子文件进行解析,直至日志文件的所有子文件解析完毕。
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。正则表达式本身有匹配成功并且捕获所对应的匹配数据(即解析字段数据)的功能;如果正则解析对象中正则表达式匹配日志文件成功,会提取日志文件中预定义的解析字段。
本实施例通过日志头部ip匹配的方式实现,ip匹配的方式匹配效率高。
本实施例中,处理单元的解析过程包括:采用子文件中正则数据,基于正则表达式对所述正则数据进行正则验证,正则验证通过后,对通过验证的正则数据进行下标匹配,将通过验证和下标匹配的正则数据进行类型处理和/或内外网区分;根据数据类型处理和/或内外网区分后的正则数据,生成解析结果集。
具体的,采用子文件中正则数据具体为:使用header ip从全局存在的序列化日志的正则数据中,采集子文件的正则数据。对正则数据进行类型处理具体为:将子文件的ip转换成long型和/或将子文件的协议号对应到相应的协议类型。
应该理解的,本实施例提供的解析方法适用于各类不同设备/系统所产生的日志文件。
实施例2
本发明的实施例2提供了日志文件快速解析装置,包括处理器以及存储器,所述存储器上存储有计算机程序,所述计算机程序被所述处理器执行时,实现实施例1提供的日志文件快速解析方法。
具体的,如图6所示,本实施例中处理器划分为文件获取单元101、文件切割单元102、文件读取单元103、数据分发单元104、多个处理单元105以及入库写单元106几个功能模块。文件获取单元101用于获取所有日志文件路径地址,通过文件名称进行过滤,找出所有需要分析的日志文件;文件切割单元102将单个超大日志文件切割成多个子文件;文件读取单元103获取切割后的子文件的路径地址,并行或串行的进行读取加载;数据分发单元104将文件读取单元103读取加载的数据并行的分发给后面的处理单元105。处理解析单元105输出结果集形成待入库的.sgn后缀文件;入库写单元106将处理解析单元105输出的结果集进行入库写操作,将解析结果写入持久化数据存储器2中,以供使用。
本发明实施例提供的日志文件快速解析装置,用于实现日志文件快速解析方法,因此,日志文件快速解析方法所具备的技术效果,日志文件快速解析装置同样具备,在此不再赘述。
实施例3
本发明的实施例3提供了计算机存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实现实施例1提供的日志文件快速解析方法。
本发明实施例提供的计算机存储介质,用于实现日志文件快速解析方法,因此,日志文件快速解析方法所具备的技术效果,计算机存储介质同样具备,在此不再赘述。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。
- 一种日志文件快速解析方法及装置
- 一种日志文件的生成与解析方法及装置