一种文本纠错方法、系统及电子设备
文献发布时间:2023-06-19 11:06:50
技术领域
本发明涉及智能识别技术领域,尤其涉及一种自然语言处理技术。
背景技术
随着深度学习的普及,在计算机视觉、语音识别、自然语言处理等方面均取得重大突破。以语音识别为例,目前语音识别准确率已达到97%。以上技术的突破,使得语音识别的应用领域越来越广。由于相对于其他人机交互方式,语音交互更为符合人们的日常习惯,更为高效。可以预计,语音识别技术将广泛应用于智能家居、工业生产、通信、医疗、自动驾驶等各个领域。在实际语音交互过程中,由于用户发音不标准、噪音等各因素影响,语音识别错误率较高。而现有技术都集中在提升语音识别准确率上,却缺乏对识别结果的纠错手段。以上原因,极大影响语音交互产品推广。
现有技术中,为提升对识别结果的纠错情况,常通过预先训练的实体词模型找出语音识别文本的实体词,并和用户词库做拼音相似度比对。如现有技术一般包括如下步骤:对语音转化后的文本数据进行分析和预处理,获取样本数据集;利用样本数据训练实体识别模型;构建实体修正数据集;根据语音识别后的文本数据,利用实体识别模型进行预测及实体验证等。
上述类型的技术方案,存在如下缺陷:在对语音识别文本进行纠错前,需要预先标注与训练实体词模型,而不同类型的实体词可能需要额外训练,这导致运算时间及准确率大大的受限于实体词模型。
发明内容
为解决现有技术存在的问题,本发明提供了一种文本纠错方法、系统及电子设备。
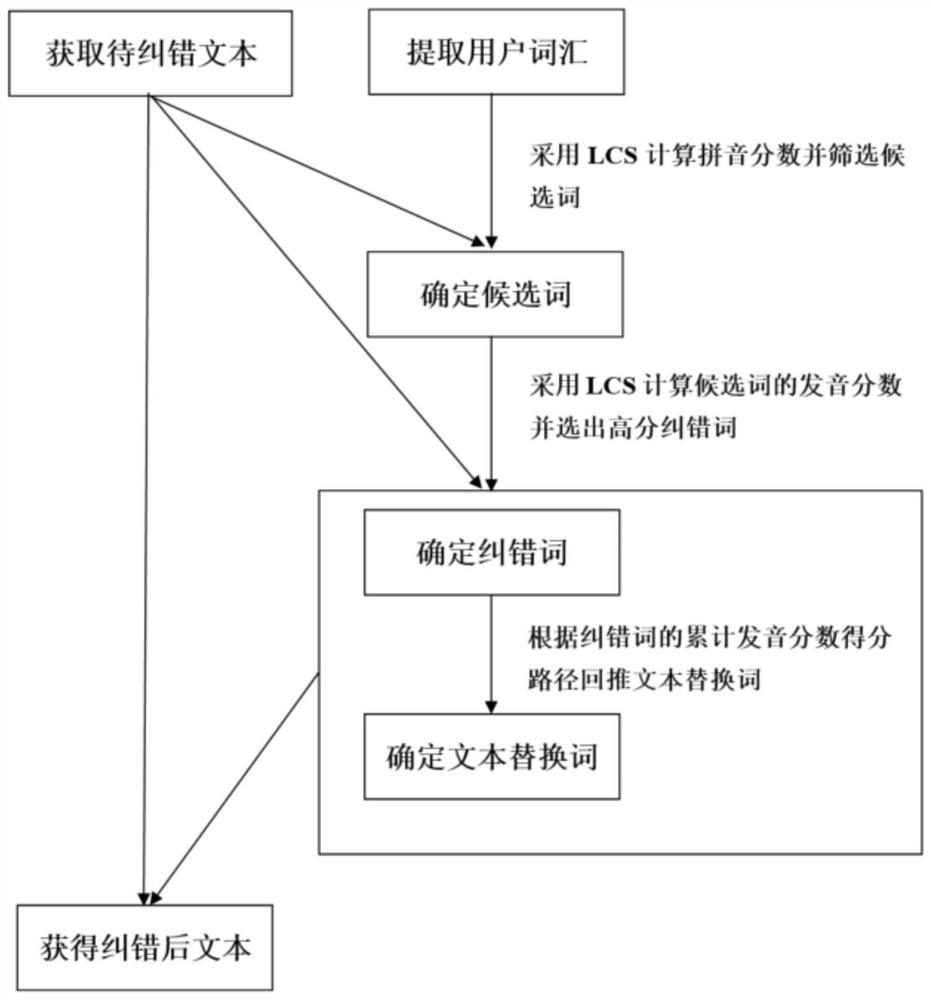
第一方面,本发明提供了一种文本纠错方法,包括如下步骤:获取待纠错文本并识别待纠错文本拼音,从用户词库中提取用户词汇及用户词汇拼音;将待纠错文本拼音与各用户词汇拼音直接进行比对,根据预设算法,从用户词库中选取出纠错词;根据纠错词的选取路径,反推待纠错文本中的替换词,将替换词替换为纠错词,获得纠错后文本。
结合第一方面实施例,在一种可能的实施方式中,所述待纠错文本为语音识别文本。
结合第一方面实施例,在一种可能的实施方式中,所述预设算法包括发音分数算法,所述发音分数算法包括:计算待纠错文本拼音与每个用户词汇拼音之间所有任两个拼音的发音相似度分数,以最长公共子序列LCS算法对待纠错文本拼音与用户词汇拼音的发音相似度分数进行累加,得到每个用户词汇的累计发音分数,并记录发音分数的得分路径;用户词汇的累计发音分数除以该用户词汇的拼音个数,得到该用户词汇的发音分数,选取发音分数最高的用户词汇作为纠错词。
结合第一方面实施例,在一种可能的实施方式中,所述预设算法包括拼音分数算法和发音分数算法,所述拼音分数算法包括:计算待纠错文本拼音与每个用户词汇拼音的LCS,得到每个用户词汇的累计拼音分数,用户词汇的累计拼音分数除以该用户词汇的拼音个数,得到该用户词汇的拼音分数,筛选拼音分数排在前K位的用户词汇作为候选词,其中K小于等于用户词汇的总数量。所述发音算法包括:计算待纠错文本拼音与每个候选词拼音之间所有任两个拼音的发音相似度分数,以最长公共子序列LCS算法对待纠错文本拼音与候选词拼音的发音相似度分数进行累加,得到每个候选词的累计发音分数,并记录发音分数的得分路径;候选词的累计发音分数除以该候选词的拼音个数,得到该候选词的发音分数,选取发音分数最高的候选词作为纠错词。
结合第一方面实施例,在一种可能的实施方式中,若存在多个发音分数相同的候选词,则按照如下顺序挑选纠错词:拼音分数最高的候选词为纠错词;与待纠错文本相同字数最多的候选词为纠错词;与待纠错文本字数长度最接近的候选词为纠错词;随机选择候选词为纠错词。
结合第一方面实施例,在一种可能的实施方式中,拼音的发音相似度分数直接由发音相似度算法计算后得出,发音相似度算法包括DIMSIM算法。
结合第一方面实施例,在一种可能的实施方式中,将纠错词的发音分数与预设阈值比对,若:纠错词的发音分数低于预设阈值,则不再执行将替换词替换为纠错词步骤,直接输出待纠错文本;纠错词的发音分数高于或等于预设阈值,将替换词替换为纠错词后输出纠错后文本。
结合第一方面实施例,在一种可能的实施方式中,所述预设阈值的取值范围为0.5~1。
第二方面,本发明提供了一种文本纠错系统,包括以下模块:语音识别模块,用于从用户处接收用户的语音输入,获取语音识别文本及待纠错文本拼音;用户词库存储模块,用于储存、提取用户词汇及用户词汇拼音,计算用户词汇拼音个数,计算用户词汇数量;发音分数计算模块,用于计算候选词拼音的发音分数以及累计发音分数得分路径;文本替换模块,用于文本替换。
结合第二方面实施例,在一种可能的实施方式中,还包括拼音分数计算模块,用于计算每个用户词汇的拼音分数。
第三方面,本发明提供了一种电子设备,包括存储器和处理器,所述存储器和所述处理器连接;所述存储器用于存储程序;所述处理器调用存储于所述存储器中的程序,以执行上述第一方面实施例和/或结合第一方面实施例的任一种可能的实施方式提供的方法。
本发明的有益效果包括:不受限于实体词模型,无需事先标注与训练实体词模型,减少工作量,提高工作效率及准确率;可快速比对文本的每个位置,同时找出需要替换的位置以及最匹配的纠错词,缩短运算时间同时提高了准确率;本发明在比对时不仅仅是考虑拼音字面上的相似度,还考虑了发音的相似度,进一步提高了准确率。
附图说明
构成本申请的一部分的附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对发明的不当限定。在附图中:
图1是本发明所涉一种文本纠错方法的流程示意图;
图2是“车牌号码是酷ABC966”和“沪ADD966”的累计发音分数得分图;
图3是“车牌号码是酷ABC966”和“沪ADD966”的累计发音分数得分路径图;
图4是“叫车到尾家医院好吗”和“微甲医院”的累计发音分数得分图;
图5是“叫车到尾家医院好吗”和“微甲医院”的累计发音分数得分路径图;
图6是本发明所涉一种文本纠错系统的示意图。
具体实施方式
为使本发明要解决的技术问题、技术方案和达到的技术效果更加清楚,下面将结合附图对本发明实施例的技术方案作详细的说明。显然,所描述的实施例仅仅是本发明一部分的实施例,而不是全部。基于本发明的实施例,本领域技术人员在没有作出创造性劳动的前提下,所获得的所有其他实施例也属于本发明的保护范围。
本发明实施例改善了现有技术在对语音识别文本进行纠错前,需要预先标注与训练实体词模型,而不同类型的实体词可能需要额外训练,这导致运算时间及准确率大大的受限于实体词模型的缺陷,其核心思想在于,直接将待纠错文本拼音与各用户词汇拼音进行比对,根据预设算法,从用户词库中选取出纠错词并根据纠错词反推替换词。
根据本发明提供的一种文本纠错方法,包括:获取待纠错文本并识别待纠错文本拼音,从用户词库中提取用户词汇及用户词汇拼音;将待纠错文本拼音与各用户词汇拼音直接进行比对,根据预设算法,从用户词库中选取出纠错词;根据纠错词的选取路径,反推待纠错文本中的替换词,将替换词替换为纠错词,获得纠错后文本。
进一步地,所述待纠错文本为语音识别文本
进一步地,其中预设算法可以采用如下两种方案的任意一种:
第一,预设算法包括发音分数算法,所述发音分数算法包括:计算待纠错文本拼音与每个用户词汇拼音之间所有任两个拼音的发音相似度分数,以最长公共子序列LCS算法对待纠错文本拼音与用户词汇拼音的发音相似度分数进行累加,得到每个用户词汇的累计发音分数,并记录发音分数的得分路径;用户词汇的累计发音分数除以该用户词汇的拼音个数,得到该用户词汇的发音分数,选取发音分数最高的用户词汇作为纠错词。
第二,为进一步提高纠错效率,预设算法包括拼音分数算法和发音分数算法,所述拼音分数算法包括:计算待纠错文本拼音与每个用户词汇拼音的LCS,得到每个用户词汇的累计拼音分数,用户词汇的累计拼音分数除以该用户词汇的拼音个数,得到该用户词汇的拼音分数,筛选拼音分数排在前K位的用户词汇作为候选词,其中K小于等于用户词汇的总数量。所述发音分数算法包括:计算待纠错文本拼音与每个候选词拼音之间所有任两个拼音的发音相似度分数,以最长公共子序列LCS算法对待纠错文本拼音与候选词拼音的发音相似度分数进行累加,得到每个候选词的累计发音分数,并记录发音分数的得分路径;候选词的累计发音分数除以该候选词的拼音个数,得到该候选词的发音分数,选取发音分数最高的候选词作为纠错词。
进一步地,若存在多个发音分数相同的候选词,则按照如下顺序挑选纠错词:拼音分数最高的候选词为纠错词;与待纠错文本相同字数最多的候选词为纠错词;与待纠错文本字数长度最接近的候选词为纠错词;随机选择候选词为纠错词。
进一步地,拼音的发音相似度分数直接由发音相似度算法如DIMSIM算法计算后得出。
进一步地,为进一步提高纠错精度,预设阈值,将纠错词的发音分数与预设阈值比对,若:纠错词的发音分数低于预设阈值,则不再执行将替换词替换为纠错词步骤,直接输出待纠错文本;纠错词的发音分数高于或等于预设阈值,将替换词替换为纠错词后输出纠错后文本。
进一步地,根据不同纠错精度的要求,所述预设阈值的取值范围为0.5~1。
此外,本发明提还供了一种文本纠错系统,包括以下模块:语音识别模块,用于从用户处接收用户的语音输入,获取语音识别文本及待纠错文本拼音;用户词库存储模块,用于储存、提取用户词汇及用户词汇拼音,计算用户词汇拼音个数,计算用户词汇数量;发音分数计算模块,用于计算候选词拼音的发音分数以及累计发音分数得分路径;文本替换模块,用于文本替换。
进一步地,还包括拼音分数计算模块,用于计算每个用户词汇的拼音分数。
此外,本发明提供了一种电子设备,包括存储器和处理器,所述存储器和所述处理器连接;所述存储器用于存储程序;所述处理器调用存储于所述存储器中的程序,以执行上述第一方面实施例和/或结合第一方面实施例的任一种可能的实施方式提供的方法。
下面通过多个实施例来进一步说明本申请的技术方案。
实施例一
步骤1:
通过语音识别方式获取待纠错文本:“车牌号码是酷ABC966”,对应拼音为:['che','pai','hao','ma','shi','ku','ei','bi','xi','jiu','liu','liu'];
提取用户词库中的用户词汇:“赣A7C976”、“沪ADD966”、“皖DPC966”、“浙EY7966”……用户词汇对应拼音分别为:['gan','ei','qi','xi','jiu','qi','liu']、['hu','ei','di','di','jiu','liu','liu']、['wan','di','pi','xi','jiu','liu','liu']、['zhe','yi','wai','qi','jiu','liu','liu']……
步骤2:
计算待纠错文本拼音和用户词汇拼音的LCS并除以用户词汇拼音个数得出每个用户词汇的拼音分数,具体计算方式如下:
LCS(车牌号码是酷ABC966拼音,赣A7C976拼音)/7=LCS(['che','pai','hao','ma','shi','ku','ei','bi','xi','jiu','liu','liu'],['gan','ei','qi','xi','jiu','qi','liu'])/7=0.57
LCS(车牌号码是酷ABC966拼音,沪ADD966拼音)/7=LCS(['che','pai','hao','ma','shi','ku','ei','bi','xi','jiu','liu','liu'],['hu','ei','di','di','jiu','liu','liu'])/7=0.57
LCS(车牌号码是酷ABC966拼音,皖DPC966拼音))/7=LCS(['che','pai','hao','ma','shi','ku','ei','bi','xi','jiu','liu','liu'],['wan','di','pi','xi','jiu','liu','liu'])/7=0.57
LCS(车牌号码是酷ABC966拼音,浙EY7966拼音)/7=LCS(['che','pai','hao','ma','shi','ku','ei','bi','xi','jiu','liu','liu'],['zhe','yi','wai','qi','jiu','liu','liu'])/7=0.43
……
将K设置为3时,即筛选出拼音分数在前3位的用户词汇作为候选词:“赣A7C976”、“沪ADD966”、“皖DPC966”。
步骤3:
采用发音相似度算法如DIMSIM算法计算待纠错文本与每个候选词之间所有任两个音的发音相似度分数,例如“酷(ku)”和“沪(hu)”的发音相似度为0.583,“酷(ku)”和“赣(gan)”的发音相似度为0.013,9(jiu)和9(jiu)的发音相似度为1……以最长公共子序列LCS算法对待纠错文本拼音与候选词拼音的发音相似度分数进行累加,得到每个候选词的累计发音分数,并记录发音分数的得分路径,候选词的累计发音分数除以该候选词拼音个数得出该候选词的发音分数,具体计算方式如下:
LCS(车牌号码是酷ABC966拼音,赣A7C976拼音|DIMSIM发音相似度算法)/7=0.59
LCS(车牌号码是酷ABC966拼音,沪ADD966拼音|DIMSIM发音相似度算法)/7=0.69
LCS(车牌号码是酷ABC966拼音,皖DPC966拼音|DIMSIM发音相似度算法)/7=0.67
如图2所示为“沪ADD966”的累计发音分数得分图,图3所示为其累计发音分数得分路径图。
步骤4:
选择发音分数最高的“沪ADD966”作为纠错词,如图3所示根据其累计发音分数对应的累计得分路径回推文本替换词为“酷ABC966”。
步骤5-1:
将预设阈值设置为0.8时,纠错词“沪ADD966”的发音分数为0.69小于预设阈值,则不再执行将替换词替换为纠错词步骤,直接输出待纠错文本,即纠错后文本仍为“车牌号码是酷ABC966”。
步骤5-2:
将预设阈值设置为0.6时,纠错词“沪ADD966”的发音分数为0.69大于预设阈值,则用纠错词“沪ADD966”替换文本替换词“酷ABC966”,即将待纠错文本“车牌号码是酷ABC966”修改为“车牌号码是沪ADD966”。
实施例二
步骤1:
通过语音识别方式获取待纠错文本:“叫车到尾家医院好吗”,对应拼音为:['jiao','che','dao','wei','jia','yi','yuan','hao','ma'];
提取用户词库中的用户词汇:“微甲医院”、“石岩医院”、“明豪国际酒店”……用户词汇对应拼音分别为:['wei','jia','yi','yuan']、['shi','yan','yi','yuan']、['ming','hao','guo','ji','jiu','dian']……
步骤2:
计算待纠错文本拼音和用户词汇拼音的LCS并除以用户词汇拼音个数得出每个用户词汇的拼音分数,具体计算方式如下:
LCS(叫车到尾家医院好吗拼音,微甲医院拼音)/4=LCS(['jiao','che','dao','wei','jia','yi','yuan','hao','ma'],['wei','jia','yi','yuan'])/4=4/4=1
LCS(叫车到尾家医院好吗拼音,石岩医院拼音)/4=LCS(['jiao','che','dao','wei','jia','yi','yuan','hao','ma'],['wei','jia','yi','yuan'])/4=2/4=0.5
LCS(叫车到尾家医院好吗拼音,明豪国际酒店拼音)/6=LCS(['jiao','che','dao','wei','jia','yi','yuan','hao','ma'],['wei','jia','yi','yuan'])/6=1/6=0.17
……
将K设置为2时,即筛选出拼音分数在前2位的用户词汇作为候选词:“微甲医院”、“石岩医院”。
步骤3:
采用发音相似度算法如DIMSIM算法计算待纠错文本与每个候选词之间所有任两个音的发音相似度分数,例如“尾(wei)”和“微(wei)”的发音相似度为1,以最长公共子序列LCS算法对待纠错文本拼音与候选词拼音的发音相似度分数进行累加,得到每个候选词的累计发音分数,并记录发音分数的得分路径,候选词的累计发音分数除以该候选词拼音个数得出该候选词的发音分数,具体计算方式如下:
LCS(叫车到尾家医院好吗拼音,微甲医院拼音|DIMSIM发音相似度算法)/4=1
LCS(叫车到尾家医院好吗拼音,石岩医院拼音|DIMSIM发音相似度算法)/4=0.52
如图4所示为“微甲医院”的累计发音分数得分图,图5所示为其累计发音分数得分路径图。
步骤4:
选择发音分数最高的“微甲医院”作为纠错词,如图5所示根据其最高累计发音分数对应的累计得分路径回推文本替换词为“尾家医院”。
步骤5:
将门槛值设置为0.8时,纠错词“微甲医院”的发音分数为1大于门槛值,则用纠错词“微甲医院”替换文本替换词“尾家医院”,即将待纠错文本“叫车到尾家医院好吗”修改为“叫车到微甲医院好吗”。
以上仅是本发明的优选实施方式,本发明的保护范围并不仅局限于实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和变换,应视为本发明的保护范围。
- 文本纠错方法、文本纠错装置、存储介质和电子设备
- 一种基于智能终端的文本纠错方法及文本纠错系统