基于IMBI指数的大气污染源监测识别方法和系统
文献发布时间:2023-06-19 11:08:20
技术领域
本发明涉及环境监测技术领域,具体涉及基于IMBI指数的大气污染源监测识别方法和系统。
背景技术
当前我们国家虽然PM2.5浓度持续下降,但仍有部分城市PM2.5年均浓度仍未达标,污染治理任务艰巨,同时夏季臭氧污染日益严重,在部分城市已取代PM2.5成为影响优良天数的主要污染因子。NO
NO
由于上述原因,本发明人对现有的大气污染源监测方法做了深入研究,设计出一种能够解决上述问题的基于IMBI指数的大气污染源监测识别方法及系统。
发明内容
为了克服上述问题,本发明人进行了锐意研究,设计出一种基于IMBI指数的大气污染源监测识别方法及系统,该方法及系统中通过设置分析模型来获得监测地区近地面的NO
具体来说,本发明的目的在于提供一种基于IMBI指数的大气污染源监测识别方法,该方法包括
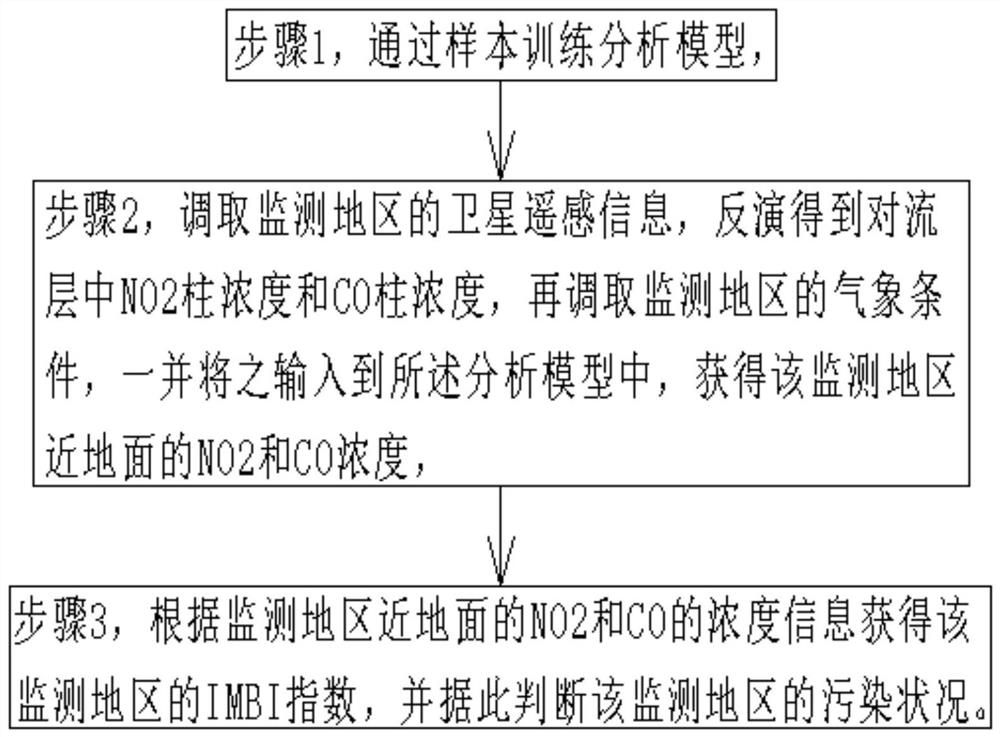
步骤1,通过样本训练分析模型,
步骤2,调取监测地区的卫星遥感信息,反演得到对流层中NO
步骤3,根据监测地区近地面的NO
其中,在步骤1中,所述样本包括:
通过卫星遥感信息反演得到的对流层NO
地面监测站点获得的近地面的NO
气象条件;所述气象条件包括气温、湿度和风速。
其中,在步骤3中,所述IMBI指数通过近地面CO浓度和近地面NO
其中,在步骤3中,判断该监测地区的污染状况包括:
IMBI<200且NO
200≤IMBI<400且CO浓度值处于前20%的规则遥感单元为工业源,
IMBI≥400且CO浓度值处于前20%的规则遥感单元为居民燃煤或生物质燃烧源。
其中,在步骤3中,若所述规则遥感单元为心城区,且IMBI≥400,并且CO值处于前20%,则该规则遥感单元为机动车污染源。
其中,在步骤3中,判断完成该监测地区的污染状况后,用框选的形式突出显示其中的高污染区域。
本发明还提供一种基于IMBI指数的大气污染源监测识别系统,该系统包括:
分析模型,其用于根据监测地区的对流层中NO
判断筛选模块,其用于根据监测地区近地面的NO
其中,所述分析模型通过样本训练得到,所述样本包括:
通过卫星遥感信息反演得到的对流层NO
地面监测站点获得的近地面的NO
气象条件;所述气象条件包括气温、湿度和风速。
其中,在所述判断筛选模块中,通过近地面CO浓度和近地面NO
其中,在所述判断筛选模块中,
IMBI<200且NO
200≤IMBI<400且CO浓度值处于前20%的规则遥感单元为工业源,
IMBI≥400且CO浓度值处于前20%的规则遥感单元为居民燃煤或生物质燃烧源。
本发明所具有的有益效果包括:
(1)根据本发明提供的基于IMBI指数的大气污染源监测识别方法及系统中通过分析模块快速准确地获得监测地区近地面的NO
(2)根据本发明提供的基于IMBI指数的大气污染源监测识别方法及系统能够获得IMBI指数,并根据该IMBI指数所处的数值范围判断监测区域的主要污染源类型,为精确治理污染提供可靠的数据信息基础。
附图说明
图1示出根据本发明一种优选实施方式的基于IMBI指数的大气污染源监测识别方法整体逻辑图;
图2示出实施例中得到的京津冀鲁豫地区近地面NO
图3示出实施例中得到的京津冀鲁豫地区近地面CO浓度分布图;
图4示出实施例中得到的京津冀鲁豫地区近地面IMBI分布图;
图5示出实施例中突出显示的河北唐山国义特钢焦化厂附近区域及其放大图;
图6示出实施例中突出显示的天津市蓟州区上仓镇附近区域及其放大图;
图7示出实施例中突出显示的山东省德州市鲁权屯镇附近区域及其放大图;
图8示出实施例中突出显示的河南省安阳市八里营镇四街村附近区域及其放大图;
图9示出实施例中突出显示的河山东省菏泽市东明集镇五营村附近区域及其放大图。
具体实施方式
下面通过附图和实施例对本发明进一步详细说明。通过这些说明,本发明的特点和优点将变得更为清楚明确。
在这里专用的词“示例性”意为“用作例子、实施例或说明性”。这里作为“示例性”所说明的任何实施例不必解释为优于或好于其它实施例。尽管在附图中示出了实施例的各种方面,但是除非特别指出,不必按比例绘制附图。
根据本发明提供的基于IMBI指数的大气污染源监测识别方法,如图1中所示,该方法包括如下步骤:
步骤1,通过样本训练分析模型,
步骤2,调取监测地区的卫星遥感信息,反演得到对流层中NO
步骤3,根据监测地区近地面的NO
在一个优选的实施方式中,在步骤1中,所述样本包括:
通过卫星遥感信息反演得到的对流层NO
地面监测站点获得的近地面的NO
气象条件;所述气象条件包括气温、湿度和风速。
通过大量样本冲刷训练,使得该分析模型在接收到对流层NO
所述训练样本可以选择全球范围内任意多个区域对应的NO
在一个优选的实施方式中,所述步骤1包括如下子步骤:
子步骤1,调取基础数据;
子步骤2,判定基础数据是否符合要求;
子步骤3,从符合要求的基础数据中选取可用数据;
子步骤4,根据子步骤3中的可用数据获得分析模型。
具体来说,在子步骤1中,调取一个规则遥感单元所对应区域的近地面NO
所述子步骤2包括如下亚子步骤;
亚子步骤1,将所有基础数据随机地按照预定比例分成两组,即为学习组和检验组;优选地,所述比例可以为15~25:1,更优选地,学习组中数据数量与检验组中数据数量之比为19:1;
亚子步骤2,利用学习组中的数据冲刷模型,再用检验组中的每个数据逐一验证该模型,并分别记录检验组中每个数据的验证结果,优选地,所述验证结果包括验证通过和验证不通过;其中,验证通过是指将检验组中基础数据的对流层NO
验证不通过是指将检验组中基础数据的对流层NO
亚子步骤3,多次重复上述亚子步骤1和亚子步骤2,其中,曾经被分配到检验组中的基础数据不再被分配到检验组中,确保每个基础数据都曾在检验组中对被学习组中数据冲刷过的模型做过验证,直至获得所有基础数据对应的验证结果;
亚子步骤4,解算所有基础数据验证结果的总通过率,所述总通过率为所有基础数据的验证结果为验证通过的数量与所有基础数据的数量之比;当总通过率不大于80%时,认为这些基础数据不符合基本要求,全部放弃,重复子步骤1,重新获得新的基础数据;当亚子步骤4中结果即总通过率大于80%时,认为这些基础数据满足使用要求,即为符合要求的基础数据,可以进行下一步处理。
在一个优选的实施方式中,子步骤3中得到可用数据包括如下子步骤:
亚子步骤a,多次重复子步骤2中的亚子步骤1-3,并且每次重复亚子步骤1时都得到一个由不同的基础数据组成的检验组,即所有的检验组都是不同的;优选地,所述亚子步骤1-3重复20-30次,进而使得每个基础数据都对应有多个验证结果,再分别解算每个基础数据对应的平均通过率;所述基础数据对应的平均通过率为该基础数据对应的验证结果中验证通过的数量与该基础数据对应的验证结果的总数量之比。
亚子步骤b,找到并隐藏5例平均通过率最低的基础数据,当存在6例以上基础数据的平均通过率一致且最低时,任意隐藏其中5例即可,即数据值并列时,随机抽取,被隐藏的数据,在被恢复以前,不再参与任何计算处理;找到并利用剩余的基础数据再次执行亚子步骤1-4,观察总通过率相较于隐藏数据前是否提高,如果总通过率提高,则删除该被隐藏的基础数据,并执行亚子步骤c;如果总通过率未提高,则恢复被隐藏的基础数据,继续挑选并隐藏平均通过率最低的基础数据,其中,曾经被隐藏后又被恢复的数据不会再次被挑选,基础数据恢复后添加特殊标记;重复以上过程,直至总通过率提高;
亚子步骤c,在总通过率提高后,以剩余的基础数据为基础,重复亚子步骤a和亚子步骤b,在重复的过程中,首先消除数据上的特殊标记;发现总通过率提高后再以当前剩余的基础数据为基础,继续重复亚子步骤a和亚子步骤b,直至总通过率达到90%以上,优选为95%以上;或者删除的基础数据达到总的基础数据的20%时为止,此时剩余的基础数据即为可用数据。
优选地,所述子步骤2中的模型包括绝大多数有监督学习的模型,对该模型的冲刷过程包括多个有监督模型的综合判断,其具体冲刷过程包括但不限于采用线性回归、支持向量机、梯度下降法、朴素贝叶斯分类、决策树分类、AdaBoost、XGBoost、多层神经网络等冲刷方法。优选地,利用3-4层结构的神经网络、C4.5决策树、XGBoost 3种模型的结果中彼此较为接近的2个结果的平均值作为每次冲刷的输出值,即将3-4层结构的神经网络、C4.5决策树、XGBoost组合为最优选的模型,即高生态效用的模型。
在子步骤4中,获得分析模型的过程中,将每个可用数据中的对流层NO
在一个优选的实施方式中,在步骤4中,利用可用数据获得分析模型学习过程为中,同时使用综合神经活动指标和标签数据建立3-4层结构的神经网络、C4.5决策树和XGBoost三种模型,将这三种模型的组合作为分析模型,该分析模型的输出为三种模型输出中最为接近的两个输出值的平均值。例如,针对一组数据,三个模型分别给出的输出结果为一个是6,一个是15,一个是7,输出结果7和输出结果6彼此接近,则最终分析模型的输出结果为6,即7和6的平均值,并向下取整,其中NO
本申请中所述的近地面是指高度在50至100m左右的空间区域。
所述地面监测站点为联合国世界气象组织统一协调管控的观测场地,其中包括测量气温、湿度和风速的相关设备。
在一个优选的实施方式中,在步骤3中,所述IMBI指数通过近地面CO浓度和近地面NO
即:
在一个优选的实施方式中,在步骤3中,判断该监测地区的污染状况包括:
IMBI<200且NO
200≤IMBI<400且CO浓度值处于前20%的规则遥感单元为工业源,
IMBI≥400且CO浓度值处于前20%的规则遥感单元为居民燃煤或生物质燃烧源。
在一个优选的实施方式中,在步骤3中,若所述规则遥感单元为心城区,且IMBI≥400,并且CO值处于前20%,则该规则遥感单元为机动车污染源。
本申请中优选地,当该监测地区的PM2.5浓度大于75μg/m
进一步优选地,在步骤3中,判断完成该监测地区的污染状况后,用框选的形式突出显示其中的高污染区域,即用线框选中高污染区域,并对高污染区域做局部放大处理,以便于准确获知高污染区域的具体坐标及地貌信息。
优选地,所述监测地区的一般区域为地级市的行政覆盖范围。
本发明还提供一种基于IMBI指数的大气污染源监测识别系统,该系统包括分析模型和判断筛选模块。
分析模型用于根据监测地区的对流层中NO
判断筛选模块用于根据监测地区近地面的NO
优选地,所述分析模型通过样本训练得到,所述样本包括:
通过卫星遥感信息反演得到的对流层NO
地面监测站点获得的近地面的NO
气象条件;所述气象条件包括气温、湿度和风速。
优选地,在所述判断筛选模块中,通过近地面CO浓度和近地面NO
优选地,在所述判断筛选模块中,
IMBI<200且NO
200≤IMBI<400且CO浓度值处于前20%的规则遥感单元为工业源,
IMBI≥400且CO浓度值处于前20%的规则遥感单元为居民燃煤或生物质燃烧源。
进一步地,判断完成该监测地区的污染状况后,用框选的形式突出显示其中的高污染区域。
实施例
从国控监测站点数据库调取近地面NO
将全部3000条基础数据随机分为20份,其中一份作为检验组,其他份作为学习组,通过学习组冲刷模型,再用检验组中的数据验证该模型,得到每个检验组数据的验证结果;再用其他份中的数据作为检验组,重复上述步骤,共重复循环150次,确保每个基础数据都曾分配到过检验组中,即每个基础数据都得到对应的验证结果,求得总通过率为88%,高于80%,可以进行下一步处理。
剔除该基础数据中的异常数据,即得到可用数据,具体来说,
求取平均通过率,将全部3000条基础数据随机分为20份,其中一份作为检验组,其他份作为学习组,通过学习组冲刷模型,再用检验组中的数据验证该模型,得到每个数据的验证结果;再重新分配检验组和学习组,至少重复1500次上述过程,确保每个基础数据都至少10次被分入到检验组中,即每个基础数据都得到了10个对应的验证结果,进而获得每个基础数据的平均通过率;
找到并隐藏5例平均通过率最低的基础数据,利用剩余的2995例基础数据再次执行上述求取总通过率的过程,观察总通过率相较于隐藏数据前是否提高,如果总通过率提高,则删除该被隐藏的基础数据;如果总通过率未提高,则恢复被隐藏的基础数据,对恢复的基础数据做特殊标记,不可再次被挑选/隐藏,再从剩余基础数据中挑选平均通过率最低的5个基础数据,重复上述求取总通过率的过程,直至总通过率提高;
在命中率有所上升后,删除隐藏数据,以剩余的基础数据为基础,继续执行上述求取平均通过率的过程,在此过程中,曾经被特殊标记的数据取消特殊标记,在重新被标记以前,可以被挑选/隐藏。解算每个基础数据对应的平均通过率,寻找并隐藏平均通过率最低的5个基础数据,再在隐藏平均通过率最低的数据的基础上求取总通过率,持续重复上述剔除过程,最终总通过率达到95%。
此时剩余的数据都称之为可用数据。
根据可用数据训练分析模型,具体来说,
利用可用数据冲刷3-4层结构的神经网络、C4.5决策树、XGBoost计算模块,得到该三个模型组合的分析模型,该分析模型的输出值为三个模型给出的3个模型输出中2个较为接近的值的均值,从而得到分析模型。
在获得了分析模型以后,调取京津冀鲁豫地区的2019年2月的卫星遥感信息,反演得到对流层中NO
根据下述的判断条件,
IMBI<200且NO
200≤IMBI<400且CO浓度值处于前20%的规则遥感单元为工业源,
IMBI≥400且CO浓度值处于前20%的规则遥感单元为居民燃煤或生物质燃烧源;
框选出京津冀鲁豫地区中的高污染区域,如图5、图6、图7、图8和图9中所示。
其中,图5示出通过框选的形式突出显示了河北唐山国义特钢焦化厂附近区域为高污染区域,该规则遥感单元中近地面NO
图6示出通过框选的形式突出显示了天津市蓟州区上仓镇附近区域为高污染区域,该规则遥感单元中近地面NO
图7示出通过框选的形式突出显示了山东省德州市鲁权屯镇附近区域为高污染区域,该规则遥感单元中近地面NO
图8示出通过框选的形式突出显示了河南省安阳市八里营镇四街村附近区域为高污染区域,该规则遥感单元中近地面NO
图9示出通过框选的形式突出显示了山东省菏泽市东明集镇五营村附近区域为高污染区域,该规则遥感单元中近地面NO
以上结合了优选的实施方式对本发明进行了说明,不过这些实施方式仅是范例性的,仅起到说明性的作用。在此基础上,可以对本发明进行多种替换和改进,这些均落入本发明的保护范围内。
- 基于IMBI指数的大气污染源监测识别方法和系统
- 基于IMBI指数的大气污染源监测识别方法和系统